
前段时间,Anthropic宣布将为Claude Cowork增加一项知识库能力,这一更新在RAG和智能体开发者社区里引起了广泛讨论。简单来说,这项功能让模型交互从传统的单次、孤立的对话模式,升级为能够在多轮对话乃至多个任务之间持续复用记忆。
具体来看,模型将能够选择性地记住我们每一次的交互过程和得出的结论。这些数据会被实时写入、快速检索,并以短期记忆、用户属性、长期记忆等形式分类存储,从而主动地在后续会话中复用。举个例子,当你让AI帮你写文章时,它无需你反复强调风格偏好,就能自动掌握你的审美;或者让它撰写公司介绍,它可以直接调取历史讨论内容,自动整合成文。
那么,当模型自身具备了这种深度记忆和主动检索能力后,我们还需要传统的RAG技术和向量数据库吗?同时,我们又该如何借鉴这个思路,用开源技术搭建属于自己的“Claude Cowork记忆”系统呢?
01 如何理解Claude Cowork的记忆功能?
Cowork的记忆功能本质上属于 Agent Memory 的一种实现方式。我们可以将其理解为一种基于模型侧的、更主动、分类更精细、也更接近人脑习惯的架构设计思路。
它与传统RAG最大的区别在于“主动性”。传统RAG是“被动”的:知识库离线构建,用户提问时被动检索。而Agent Memory则是“主动”的,它不仅能读取信息,还会实时写入新的交互记录,并主动管理和复用这些记忆。
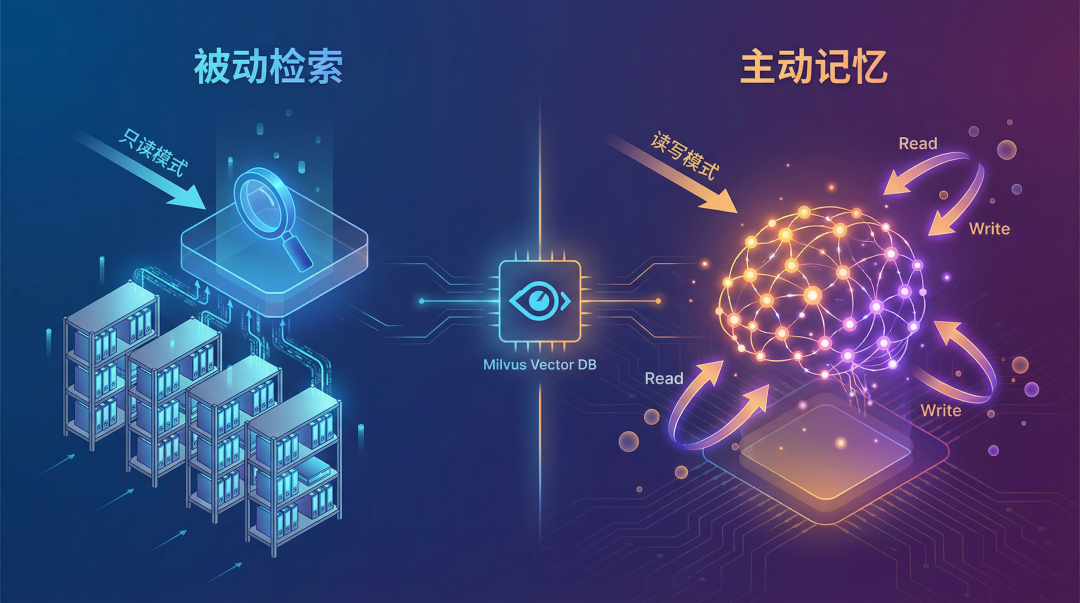
传统的RAG系统遵循“用户提问 → 检索文档 → 生成答案”的流程,其核心是检索,整个过程对知识库是只读的,不会写入新内容。后来出现的Agentic RAG虽然让AI先判断是否需要检索,但其本质仍未改变,依然是只读模式。
而对于Agent Memory来说,系统不只读取信息,还会写入信息。用户每一次有意义的操作都可能产生新的记录,并被系统主动引用。在这个过程中,使用向量数据库来高效管理这些动态生成、需要被快速检索的记忆,依然是不可或缺的一环。
02 Agent Memory如何搭建?
Claude Cowork的具体实现细节尚未公开,但此前已有开发者对Claude本身的记忆模块进行了逆向分析,我们可以从中窥见一些设计思路。
Claude采用 “长期记忆 + 按需工具检索” 的动态架构,仅在需要时才调取详细的历史上下文,从而在细节深度与效率之间取得平衡。其上下文结构大致为:[0]系统指令(静态)→ [1]用户记忆 → [2]对话历史 → [3]当前消息。这套架构的核心差异体现在“对话历史”的检索方式和“用户记忆”的更新逻辑上。
首先是用户记忆(User Memories),它定位于可智能更新的长期层,类似于ChatGPT的长期记忆功能,但支持更灵活的动态更新,格式通常用XML标签包裹。其更新机制包括:
- 隐式更新:后台定期基于对话内容自动优化记忆(非实时),删除对话会逐步移除相关记忆。
- 显式更新:用户通过
memory_user_edits 工具,使用“记住这个”、“删除这个”等指令直接管理。
相比ChatGPT,Claude在这一环增加了后台自动优化的能力,减少了用户主动干预记忆迭代的需要。
其次是对话历史(Conversation History),Claude并未采用将固定摘要注入上下文的方式,而是通过三个互补的组件来动态调取历史,仅在模型判断需要时才触发,避免了无效的token消耗。

在这套组件中,conversation_search 工具尤为值得研究。它能够在用户使用模糊表述或多语言查询时依然实现精准命中,其背后很可能是基于语义层面的匹配能力(常见的实现方式是结合Embedding检索,或“查询翻译/规范化 + 关键词/混合检索”的组合拳)。
整体来看,Claude这套按需检索系统的特点在于:
- 非自动触发:工具调用由Claude自主判断,例如当用户提到“上次聊的项目”时,才会触发
conversation_search。
- 细节保留:检索结果包含助手回复的片段(而ChatGPT的摘要通常仅包含用户消息),更适合需要深度上下文的场景。
- 效率优势:无需在每次对话时都注入全部历史,显著减少了无关token的消耗。
当然,其缺点也很明显:一旦引入按需检索,系统复杂度会上升(涉及索引构建、查询、排序、可能的重排等),端到端的延迟不如预计算注入那样可控;同时,模型必须学会准确判断何时该检索,一旦判断失误,就会丢失关键上下文。
作为对比,我们可以看看ChatGPT的记忆管理模式。ChatGPT并未采用传统的向量数据库(RAG)或全量对话存储,而是通过四个分层组件将记忆提前注入每次对话的上下文,在保证个性化的同时控制计算成本:
- 用户长期记忆(User Memory):记录用户稳定属性,每次对话强制注入。
- 会话元数据(Session Metadata):短期、非持久化记忆,仅在会话启动时注入,用于适配当前场景。
- 当前会话消息(Current Session Messages):维持会话连贯性的滑动窗口上下文层。
- 近期对话摘要(Recent Conversation Summaries):一个轻量化的跨会话层,仅总结用户消息(不含助手回复),数量有限,无需嵌入计算,显著降低延迟和token消耗。
03 向量数据库如何解决Agent Memory的三个工程问题?
当记忆系统从“只读”变为“可写”,我们会遇到三个具体的工程挑战,而向量数据库是解决这些挑战的关键基础设施。
第一个问题:需要记住什么?
并非所有用户操作都需要被记录。例如,用户创建了一个临时文件,五分钟后又删除了,这个操作要不要存?这涉及到对操作“重要性”的判断。但判断标准往往是多维且冲突的:是按时间(最近的操作更重要)?按频率(被多次访问的更重要)?还是按类型(配置文件比临时缓存更重要)?
向量数据库可以提供一些辅助工具。例如,Milvus支持为数据设置TTL(生存时间),自动删除过期数据;也可以结合衰减函数,让旧数据的权重随时间降低。然而,这些只是辅助手段,关于“重要性”的核心判断标准,仍然需要由应用层来定义。
第二个问题:如何分层存储?
当任务周期变长、数据量增大时,分层存储就成了刚需。难点在于两部分:首先是判断内容的重要性(可以基于小模型或规则,如按时间切分、按访问频率、按用户手动标记),其次才是执行分层存储。
以Milvus为例,它支持冷热数据分层存储。可以将高频访问的热数据以及知识图谱存放在内存中以实现极速检索,而将低频访问的冷数据存储在磁盘或对象存储(如S3)中,以节约成本。
第三个问题:如何确定写入频率与速度?
传统RAG系统的写入是批量的、离线的。例如,今天收集一批文档,晚上跑脚本建索引,明天用户才能检索到。但Agent Memory不行,用户的每一次操作都可能需要被实时记录,如果写入慢了,下一次对话就读不到刚才的历史。
这对向量数据库的实时写入能力提出了很高要求。这里的核心矛盾在于:实时写入和检索精度之间存在权衡。向量索引的构建需要时间,如果每写入一条数据就重建一次索引,成本太高;如果先攒一批再建索引,又会导致新数据无法被立即检索到。
Milvus采用的流式写入和增量索引更新方案可以很好地平衡这一点。新数据先被写入内存缓冲区,使其能在秒级内被检索到,以支持高频实时写入。当数据积累到一定阈值后,再批量更新磁盘上的索引。这种设计在写入速度和检索性能之间找到了一个有效的平衡点。
技术的发展从来不是简单的替代。Claude Cowork展现的主动记忆能力,更像是RAG范式的一种进化,它对我们如何设计更智能、更个性化的AI系统提出了新的思考。而在这个过程中,对于高效管理海量、动态、多模态的记忆数据,向量数据库依然扮演着基石般的角色。对这类前沿技术架构的讨论与实践,也欢迎大家在云栈社区共同交流。
 发表于 2026-1-27 01:04:12
|
查看: 232|
回复: 0
发表于 2026-1-27 01:04:12
|
查看: 232|
回复: 0
