分不对,全白费——这是RAG工程师的血泪教训
你是否也曾为这样的场景抓狂?
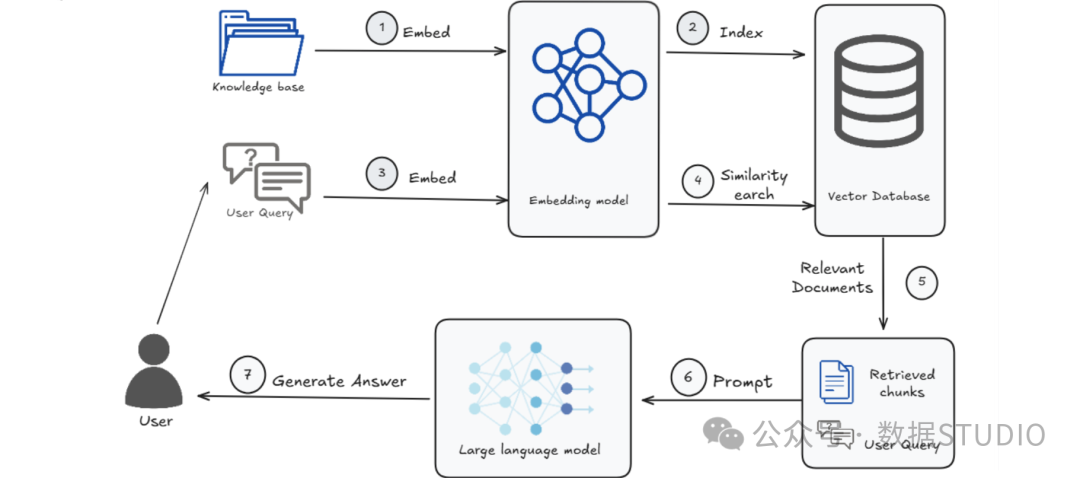
精心构建的RAG系统,输入一个问题,它要么回答“根据提供的信息无法回答”,要么自信满满地编造一段完全错误的答案?
你检查了嵌入模型,调整了检索器,重写了提示词,甚至微调了排序算法……但问题依旧。很多时候,问题的根源就藏在最基础的一步——分块(Chunking)。
今天,我们就来彻底解决这个“沉默的杀手”。我将为你系统梳理21种分块策略,从基础到高级,每种策略都配可直接运行的代码示例。读完这篇文章,你将掌握:
- 如何根据文档类型选择最佳分块策略
- 各种策略的Python实现代码
- 避免常见分块陷阱的实用技巧
为什么分块如此关键?
想象一下,你要在图书馆找一段关于“神经网络反向传播”的资料。如果图书管理员把整本书扔给你(不切分),或者把每页都撕成单字卡片(过度切分),你还能高效找到所需信息吗?
分块就是为文档创建合适的“信息单元”。切得太大,检索时引入无关噪声;切得太小,模型失去必要上下文。好的分块策略,能在“信息完整性”和“检索精准度”之间找到黄金平衡点。
下面,我们从简单到复杂,逐一拆解这21种策略。
一、基础分块策略
1. 按行分块(Naive Chunking)
最简单的策略——见到换行符就切分。

def naive_chunking(text: str):
"""按行分割文本"""
chunks = text.split('\n')
# 过滤空行
chunks = [chunk.strip() for chunk in chunks if chunk.strip()]
return chunks
# 示例文本
sample_text = """神经网络由输入层、隐藏层和输出层组成。
反向传播是训练神经网络的关键算法。
梯度下降用于优化权重参数。"""
chunks = naive_chunking(sample_text)
print("按行分块结果:")
for i, chunk in enumerate(chunks, 1):
print(f"块 {i}: {chunk}")
# 输出:
# 块 1: 神经网络由输入层、隐藏层和输出层组成。
# 块 2: 反向传播是训练神经网络的关键算法。
# 块 3: 梯度下降用于优化权重参数。
何时使用:
- 适用于文本统一由换行符分隔的场景:笔记、项目符号列表、FAQ、聊天记录或逐行记录完整思想的文字稿。
注意: 如果单行过长,可能会超出 LLM 的令牌限制;如果太短,模型可能会丢失上下文或产生幻觉。
2. 固定窗口分块(Fixed-size Chunking)
按固定字符数或单词数切割,不管语义边界。

def fixed_size_chunking(text: str, chunk_size: int = 100, overlap: int = 0):
"""固定大小分块,可设置重叠"""
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = ' '.join(words[i:i + chunk_size])
if chunk: # 避免添加空块
chunks.append(chunk)
return chunks
# 示例文本
sample_text = """深度学习是机器学习的一个分支,它试图模拟人脑的工作原理。通过构建多层的神经网络,深度学习可以自动学习数据的层次化特征表示。这种方法在图像识别、自然语言处理和语音识别等领域取得了突破性进展。"""
chunks = fixed_size_chunking(sample_text, chunk_size=20, overlap=5)
print("\n固定窗口分块结果(窗口大小20,重叠5):")
for i, chunk in enumerate(chunks, 1):
print(f"块 {i}: {chunk}")
何时使用:
- 适用于原始的、杂乱无章的文本转储,例如扫描文档、质量差的文字稿,或没有标点、标题或结构的大型文本文件。
3. 滑动窗口分块(Sliding Window Chunking)
固定窗口的增强版,允许块之间重叠,保持上下文连续性。类似于固定大小分块,但每个块与前一个块有重叠,以保持块之间的上下文连贯性。

def sliding_window_chunking(text: str, chunk_size: int = 100, overlap: int = 20):
"""滑动窗口分块"""
return fixed_size_chunking(text, chunk_size, overlap) # 复用上面的函数
# 使用与上面相同的示例文本
chunks = sliding_window_chunking(sample_text, chunk_size=30, overlap=10)
print("\n滑动窗口分块结果(窗口30,重叠10):")
for i, chunk in enumerate(chunks, 1):
print(f"块 {i}: {chunk[:50]}...")
何时使用:
- 适用于思想贯穿长句子的内容,如散文、叙述性报告、自由形式的写作。
- 与固定窗口分块一样,它也适用于没有结构的文本。只需注意令牌使用量和上下文断裂之间的权衡。
4. 按句子分块(Sentence-based Chunking)
你在每个句子的结尾处分割文本,通常以句号、问号或感叹号标记。

import re
def sentence_chunking(text: str):
"""按句子分割文本"""
# 使用正则表达式分割句子(简单版本,实际应用建议使用NLP库)
sentence_endings = r'(?<=[。!?.!?])\s+'
sentences = re.split(sentence_endings, text.strip())
return [s.strip() for s in sentences if s.strip()]
# 示例文本
sample_text = """深度学习模型需要大量数据。然而,数据标注成本很高。因此,研究者提出了自监督学习方法。这种方法利用数据自身的结构作为监督信号。"""
chunks = sentence_chunking(sample_text)
print("\n按句子分块结果:")
for i, chunk in enumerate(chunks, 1):
print(f"块 {i}: {chunk}")
何时使用:
- 适用于句子能表达完整思想的、书写清晰的文本,如博客、摘要或文档。
- 作为初始步骤,获得小而集中的块,便于以后使用更复杂的分块技术进行重新排序或重新组合。
5. 按段落分块(Paragraph-based Chunking)
你按段落(通常是双换行符)分割文本,使每个块包含一个完整的思想或思维块。

def paragraph_chunking(text: str):
"""按段落分割文本"""
paragraphs = text.split('\n\n') # 双换行符通常表示段落分隔
return [p.strip() for p in paragraphs if p.strip()]
# 示例文本
sample_text = """卷积神经网络(CNN)是处理图像数据的首选架构。
CNN通过卷积层自动提取图像特征,减少了手工特征工程的需要。
池化层则用于降低特征图的空间尺寸,增加模型的平移不变性。"""
chunks = paragraph_chunking(sample_text)
print("\n按段落分块结果:")
for i, chunk in enumerate(chunks, 1):
print(f"块 {i}: {chunk[:60]}...")
何时使用:
- 当句子分块感觉太细,而你希望每个块有更多上下文时。
- 对于已经很好地分段的文档,如散文、博客文章或报告。
6. 按页分块(Page-based Chunking)
将每个物理页面视为一个独立块,保持页码引用和页面布局信息。
import PyPDF2
from typing import List, Dict
def page_based_chunking_pdf(pdf_path: str, start_page: int = 0, end_page: int = None):
"""按页分块处理PDF文档"""
chunks = []
try:
with open(pdf_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
# 确定页码范围
if end_page is None or end_page > len(pdf_reader.pages):
end_page = len(pdf_reader.pages)
for page_num in range(start_page, end_page):
page = pdf_reader.pages[page_num]
text = page.extract_text()
if text.strip():
# 提取页面元数据
metadata = {
'page_number': page_num + 1, # 1-based
'total_pages': len(pdf_reader.pages),
'rotation': page.get('/Rotate', 0),
'media_box': page.mediabox if hasattr(page, 'mediabox') else None
}
chunks.append({
'type': 'page',
'content': text.strip(),
'metadata': metadata,
'enhanced_content': f"[第{page_num+1}页] {text.strip()}"
})
return chunks
except Exception as e:
print(f"PDF处理失败: {e}")
return []
def page_based_chunking_text_by_markers(text: str, page_markers: List[str]):
"""通过页面标记进行分块"""
# 构建正则表达式模式,匹配页面标记
pattern = '|'.join([re.escape(marker) for marker in page_markers])
regex = f'(?={pattern})'
# 分割文本
raw_chunks = re.split(regex, text)
chunks = []
for chunk in raw_chunks:
if not chunk.strip():
continue
# 提取页码
page_match = re.search(r'\b(?:page|p|pg|第)?\s*(\d+)\b', chunk, re.IGNORECASE)
page_num = int(page_match.group(1)) if page_match else 0
# 清理内容
content = re.sub(r'^' + pattern, '', chunk).strip()
chunks.append({
'page_number': page_num,
'content': content,
'full_text': f"Page {page_num}: {content}"
})
return chunks
# 示例:模拟PDF页面内容
simulated_pages = [
"Page 1\n\nExecutive Summary\n\nThis report outlines Q4 performance metrics.",
"Page 2\n\nFinancial Analysis\n\nRevenue increased by 15% year-over-year.",
"Page 3\n\nAppendix A: Detailed Data Tables\n\nSee attached spreadsheets."
]
print("按页分块结果:")
for i, page in enumerate(simulated_pages, 1):
print(f"\n页 {i}:")
# 提取实际内容(去掉"Page X"标记)
content = re.sub(r'^Page\s+\d+\s*\n*', '', page)
print(f"内容: {content[:80]}...")
何时使用: 扫描的PDF文档、书籍、学术论文、法律文件等需要保持页码引用的文档。
二、结构化分块策略
7. 结构化分块(Structured Chunking)
针对结构化或半结构化数据(JSON、XML、CSV、日志文件),利用其内在的层次结构进行智能分块。

import json
import xml.etree.ElementTree as ET
import csv
from io import StringIO
def structured_json_chunking(json_data, max_items_per_chunk: int = 10):
"""结构化JSON分块"""
if isinstance(json_data, str):
json_data = json.loads(json_data)
chunks = []
def process_node(node, path="", depth=0):
"""递归处理JSON节点"""
if isinstance(node, dict):
# 处理字典
if depth <= 2: # 控制递归深度
items = []
for key, value in node.items():
current_path = f"{path}.{key}" if path else key
if isinstance(value, (dict, list)) and depth < 3:
# 对于嵌套结构,递归处理
items.append(f"{key}: {json.dumps(value, ensure_ascii=False)[:100]}...")
else:
items.append(f"{key}: {value}")
# 如果项目太多,分块
for i in range(0, len(items), max_items_per_chunk):
chunk_items = items[i:i + max_items_per_chunk]
chunk = {
'type': 'json_object',
'path': path,
'depth': depth,
'content': '\n'.join(chunk_items),
'item_count': len(chunk_items)
}
chunks.append(chunk)
elif isinstance(node, list):
# 处理数组
for i, item in enumerate(node[:max_items_per_chunk * 3]): # 限制处理数量
if isinstance(item, (dict, list)):
process_node(item, f"{path}[{i}]", depth + 1)
else:
# 简单值直接加入
if len(chunks) == 0 or chunks[-1]['item_count'] >= max_items_per_chunk:
chunks.append({
'type': 'json_array_item',
'path': path,
'depth': depth,
'content': f"Item {i}: {item}",
'item_count': 1
})
else:
chunks[-1]['content'] += f"\nItem {i}: {item}"
chunks[-1]['item_count'] += 1
process_node(json_data)
return chunks
def structured_xml_chunking(xml_string: str):
"""结构化XML分块"""
try:
root = ET.fromstring(xml_string)
except:
# 如果是文件路径
try:
tree = ET.parse(xml_string)
root = tree.getroot()
except:
return [{'type': 'xml_error', 'content': '无法解析XML'}]
chunks = []
def process_element(element, depth=0):
"""递归处理XML元素"""
# 元素标签和属性
tag = element.tag.split('}')[-1] if '}' in element.tag else element.tag
attrs = ' '.join([f'{k}="{v}"' for k, v in element.attrib.items()])
# 文本内容
text = element.text.strip() if element.text and element.text.strip() else ""
# 构建元素描述
element_desc = f"{' ' * depth}<{tag}"
if attrs:
element_desc += f" {attrs}"
element_desc += ">"
if text:
element_desc += f" {text}"
# 如果有子元素
children = list(element)
if children:
# 创建包含子元素的块
chunk_content = [element_desc]
for child in children:
child_chunks = process_element(child, depth + 1)
for child_chunk in child_chunks:
chunk_content.append(child_chunk if isinstance(child_chunk, str) else child_chunk['content'])
chunks.append({
'type': 'xml_element_with_children',
'tag': tag,
'depth': depth,
'content': '\n'.join(chunk_content),
'child_count': len(children)
})
return []
else:
# 叶子元素
if text:
element_desc += f"</{tag}>"
else:
element_desc = element_desc.replace('>', '/>')
return [element_desc]
process_element(root)
return chunks
# JSON示例
json_example = {
"user": {
"id": 12345,
"name": "张三",
"preferences": {
"theme": "dark",
"language": "zh-CN"
}
},
"orders": [
{"id": 1, "product": "笔记本电脑", "price": 8999},
{"id": 2, "product": "鼠标", "price": 199},
{"id": 3, "product": "键盘", "price": 399}
]
}
print("\n结构化JSON分块结果:")
json_chunks = structured_json_chunking(json_example, max_items_per_chunk=2)
for i, chunk in enumerate(json_chunks, 1):
print(f"\n块 {i} - 类型: {chunk['type']}")
print(f"路径: {chunk.get('path', 'N/A')}")
print(f"内容:\n{chunk['content']}")
# XML示例
xml_example = """<bookstore>
<book category="编程">
<title>Python编程入门</title>
<author>李四</author>
<price>79.99</price>
</book>
<book category="数据科学">
<title>机器学习实战</title>
<author>王五</author>
<price>89.99</price>
</book>
</bookstore>"""
print("\n结构化XML分块结果:")
xml_chunks = structured_xml_chunking(xml_example)
for i, chunk in enumerate(xml_chunks, 1):
print(f"\n块 {i} - 类型: {chunk['type']}")
print(f"标签: {chunk['tag']}, 子元素数: {chunk.get('child_count', 0)}")
print(f"内容:\n{chunk['content'][:200]}...")
何时使用:
- 配置文件、API响应数据、数据库导出、日志文件等结构化数据。
8. 文档结构分块(Document-Based Chunking)
利用文档的天然结构(标题、章节、子标题)作为分块边界,保持逻辑完整性。

import re
def document_structure_chunking(text: str):
"""基于文档结构的分块(支持Markdown/HTML)"""
# 处理Markdown标题结构
# 按一级标题(#)分割
sections = re.split(r'(?=^#\s)', text, flags=re.MULTILINE)
# 如果没有一级标题,尝试按二级标题(##)
if len(sections) <= 1:
sections = re.split(r'(?=^##\s)', text, flags=re.MULTILINE)
chunks = []
for section in sections:
if not section.strip():
continue
# 清理并标准化标题格式
section = section.strip()
# 提取标题作为元数据
title_match = re.match(r'^(#{1,3})\s+(.+)$', section.split('\n')[0])
if title_match:
metadata = {
'level': len(title_match.group(1)), # 标题级别
'title': title_match.group(2).strip(),
'content': '\n'.join(section.split('\n')[1:])
}
else:
metadata = {'title': '无标题', 'content': section}
chunks.append(metadata)
return chunks
# 示例:技术文档
tech_doc = """# 第一章:Python基础
Python是一种解释型高级编程语言。
## 1.1 变量和数据类型
变量是存储数据的容器。
## 1.2 控制流程
条件语句和循环控制程序执行。
# 第二章:函数与模块
函数是代码重用的基本单元。
"""
chunks = document_structure_chunking(tech_doc)
print("文档结构分块结果:")
for i, chunk in enumerate(chunks, 1):
print(f"\n块 {i} - 标题: {chunk['title']}")
print(f"内容预览: {chunk['content'][:60]}...")
何时使用:
- 当你的资料源具有清晰的小节和标题时,例如文章、手册、教科书或研究论文。
- 作为更高级分块策略(如分层分块)的初始步骤。
- 如果你正在处理结构化或半结构化数据,如日志、JSON 记录、CSV 或 HTML 文档。
9. 关键词分块(Keyword-based Chunking)
你在特定关键词出现的地方分割文本。你预先确定关键词,并将其视为逻辑分割点。预定义关键词作为分块边界,这些关键词通常标志着新的话题或重要部分开始。

def keyword_based_chunking(text: str, keywords: list):
"""基于关键词的分块"""
# 创建关键词的正则表达式模式
pattern = '|'.join([re.escape(keyword) for keyword in keywords])
# 使用前瞻断言保留关键词
regex = f'(?={pattern})'
# 分割文本
chunks = re.split(regex, text)
# 处理结果
result = []
current_chunk = ""
for part in chunks:
if any(part.startswith(keyword) for keyword in keywords):
# 如果遇到新关键词,保存当前块并开始新块
if current_chunk:
result.append(current_chunk.strip())
current_chunk = part
else:
current_chunk += part
# 添加最后一个块
if current_chunk:
result.append(current_chunk.strip())
return result
# 示例:会议纪要
meeting_notes = """会议主题:项目进展汇报
汇报人:张三
内容:前端开发已完成80%。
讨论要点:
王五提出需要优化性能。
行动项:
1. 李四负责后端接口优化
2. 赵六准备测试用例
下次会议时间:
2024年12月15日"""
keywords = ["会议主题:", "汇报人:", "内容:", "讨论要点:", "行动项:", "下次会议时间:"]
chunks = keyword_based_chunking(meeting_notes, keywords)
print("\n关键词分块结果:")
for i, chunk in enumerate(chunks, 1):
print(f"块 {i}: {chunk[:80]}...")
何时使用:
- 当没有标题级别的分割点,但你已知的关键短语能一致地标记新主题时。
10. 实体分块(Entity-based Chunking)
使用命名实体识别(NER)技术识别文本中的实体(人物、地点、组织等),围绕实体组织相关内容。

import spacy
def entity_based_chunking(text: str):
"""基于实体的分块"""
# 加载中文NER模型(需要先安装:python -m spacy download zh_core_web_sm)
nlp = spacy.load("zh_core_web_sm")
# 处理文本
doc = nlp(text)
# 提取所有实体
entities = {}
for ent in doc.ents:
if ent.label_ in ['PERSON', 'ORG', 'GPE', 'PRODUCT']: # 人物、组织、地点、产品
if ent.text not in entities:
entities[ent.text] = {
'type': ent.label_,
'mentions': []
}
entities[ent.text]['mentions'].append({
'start': ent.start_char,
'end': ent.end_char,
'sentence': ent.sent.text
})
# 按实体组织内容
chunks = []
for entity, info in entities.items():
# 收集提到该实体的所有句子
sentences = set([mention['sentence'] for mention in info['mentions']])
chunk = {
'entity': entity,
'type': info['type'],
'content': ' '.join(sentences),
'mention_count': len(info['mentions'])
}
chunks.append(chunk)
return chunks
# 示例:新闻报道
news_text = """苹果公司今日发布了新款iPhone。CEO蒂姆·库克在发布会上表示,新产品采用了革命性技术。
同时,谷歌公司也宣布了其最新的Pixel手机。微软的Surface系列也有更新计划。
在北京的发布会上,库克强调了中国市场的重要性。"""
print("\n实体分块结果:")
chunks = entity_based_chunking(news_text)
for i, chunk in enumerate(chunks, 1):
print(f"\n块 {i} - 实体: {chunk['entity']} ({chunk['type']})")
print(f"提及次数: {chunk['mention_count']}")
print(f"相关内容: {chunk['content'][:100]}...")
何时使用:
- 适用于特定实体很重要的文档,如新闻文章、法律合同、案例研究或电影剧本。
11. 基于token的分块(Token-based Chunking)
你使用分词器按token数量分割文本。
你通常希望将此技术与句子分块等技术结合使用,以避免以破坏上下文的方式分割句子。
使用tokenizer精确控制每个块的token数量,确保不超过LLM的token限制。
import tiktoken
def token_based_chunking(text: str, model_name: str = "gpt-4", max_tokens: int = 100):
"""基于token的分块"""
# 获取对应模型的tokenizer
encoding = tiktoken.encoding_for_model(model_name)
# 将文本编码为tokens
tokens = encoding.encode(text)
chunks = []
current_chunk_tokens = []
current_token_count = 0
for token in tokens:
current_chunk_tokens.append(token)
current_token_count += 1
# 当达到最大token数时,保存当前块
if current_token_count >= max_tokens:
chunk_text = encoding.decode(current_chunk_tokens)
# 查找最后一个句子结束符
last_sentence_end = max(
chunk_text.rfind('。'),
chunk_text.rfind('!'),
chunk_text.rfind('?'),
chunk_text.rfind('.'),
chunk_text.rfind('!'),
chunk_text.rfind('?')
)
if last_sentence_end != -1 and last_sentence_end > len(chunk_text) * 0.3:
# 在句子边界处切割
final_chunk = chunk_text[:last_sentence_end + 1]
remaining = chunk_text[last_sentence_end + 1:]
if final_chunk.strip():
chunks.append(final_chunk.strip())
# 重置,从剩余部分开始
current_chunk_tokens = encoding.encode(remaining)
current_token_count = len(current_chunk_tokens)
else:
# 没有找到合适的句子边界,强制切割
chunks.append(chunk_text.strip())
current_chunk_tokens = []
current_token_count = 0
# 添加最后一个块
if current_chunk_tokens:
chunk_text = encoding.decode(current_chunk_tokens)
if chunk_text.strip():
chunks.append(chunk_text.strip())
return chunks
# 示例文本
long_text = """Transformer架构是自然语言处理领域的革命性突破。它通过自注意力机制实现了对输入序列的并行处理。
相比于传统的RNN和LSTM,Transformer在训练效率和长距离依赖建模方面有显著优势。
BERT、GPT等模型都基于Transformer架构。这些模型在各种NLP任务中取得了state-of-the-art的结果。"""
chunks = token_based_chunking(long_text, max_tokens=30)
print("\n基于token的分块结果:")
for i, chunk in enumerate(chunks, 1):
tokens = tiktoken.encoding_for_model("gpt-4").encode(chunk)
print(f"块 {i} ({len(tokens)} tokens): {chunk[:50]}...")
何时使用:
- 适用于没有标题或段落划分的非结构化文档。
- 当处理令牌限制较低的 LLM 时(以避免在响应或处理中被截断)。
- 需要严格控制token数量的场景,特别是使用有严格token限制的API时。
12. 表格感知分块(Table-aware Chunking)
专门处理文档中的表格,保持表格的结构完整性,通常将表格转换为结构化的格式(如Markdown或JSON)。
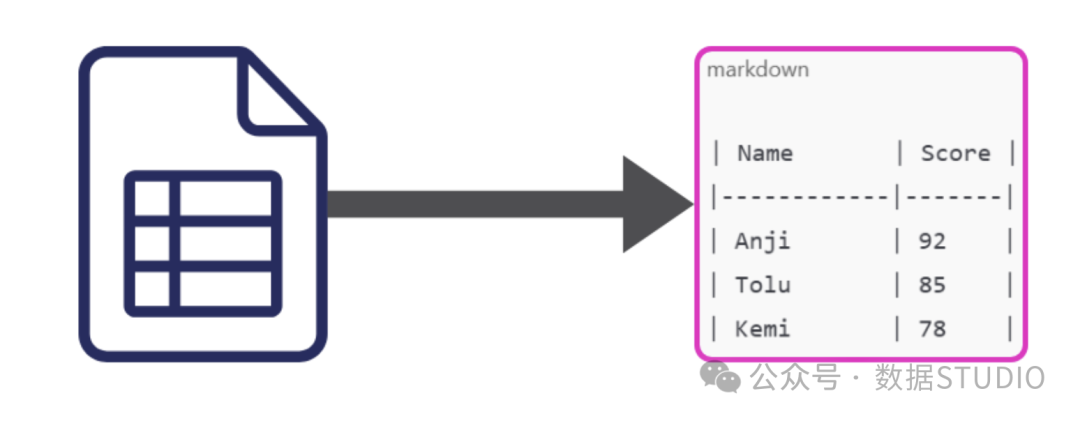
你单独识别并以 JSON 或 Markdown 格式分块表格。可以逐行、逐列或整个表格进行。
def table_aware_chunking(text: str):
"""表格感知的分块"""
# 识别表格模式(简化版,实际应用中可能需要更复杂的表格检测)
table_pattern = r'(\+[-]+\+[\s\S]*?)(?=\n\n|\Z)'
# 查找所有表格
tables = re.findall(table_pattern, text, re.MULTILINE)
# 移除表格后的文本
non_table_text = re.sub(table_pattern, '', text, flags=re.MULTILINE)
chunks = []
# 处理非表格文本(使用段落分块)
if non_table_text.strip():
paragraphs = re.split(r'\n\s*\n', non_table_text)
for para in paragraphs:
if para.strip():
chunks.append({
'type': 'text',
'content': para.strip(),
'format': 'plain'
})
# 处理表格
for table in tables:
if table.strip():
# 转换为Markdown表格格式
lines = table.strip().split('\n')
if len(lines) >= 3:
md_table = []
for i, line in enumerate(lines):
if i == 1:
# 分割线行,转换为Markdown格式
md_table.append(line.replace('+', '|').replace('-', '-'))
else:
md_table.append(line.replace('+', '|'))
chunks.append({
'type': 'table',
'content': '\n'.join(md_table),
'format': 'markdown',
'row_count': len(lines) - 2 # 减去表头和分割线
})
return chunks
# 示例:包含表格的文档
document_with_table = """项目进展报告
本季度主要完成了以下工作:
1. 系统架构设计
2. 核心模块开发
3. 性能测试
团队绩效数据:
+-------+--------+---------+
| 姓名 | 完成度 | 质量评分 |
+-------+--------+---------+
| 张三 | 95% | A |
| 李四 | 88% | B+ |
| 王五 | 92% | A- |
+-------+--------+---------+
下一步计划:
- 集成测试
- 用户验收
- 上线部署"""
print("\n表格感知分块结果:")
chunks = table_aware_chunking(document_with_table)
for i, chunk in enumerate(chunks, 1):
print(f"\n块 {i} - 类型: {chunk['type']}")
if chunk['type'] == 'table':
print(f"行数: {chunk['row_count']}")
print(f"内容预览:\n{chunk['content'][:100]}...")
何时使用:
13. 内容感知分块(Content-aware Chunking)
根据不同的内容类型(段落、列表、代码块、表格等)应用不同的分块策略。
def content_aware_chunking(text: str):
"""内容感知的分块"""
chunks = []
# 按空行分割成块
raw_blocks = re.split(r'\n\s*\n', text)
for block in raw_blocks:
block = block.strip()
if not block:
continue
# 判断内容类型
content_type = 'paragraph'
metadata = {}
# 检查是否为列表
list_items = re.findall(r'^\s*[\d•\-*]\s+.+$', block, re.MULTILINE)
if list_items:
content_type = 'list'
metadata['item_count'] = len(list_items)
metadata['items'] = list_items
# 检查是否为代码块
elif re.search(r'```[\s\S]*?```', block) or re.search(r'^\s{4,}.+$', block, re.MULTILINE):
content_type = 'code'
# 检查是否为标题
elif re.match(r'^#{1,3}\s+.+$', block):
content_type = 'heading'
level = block.count('#')
metadata['level'] = level
metadata['title'] = block.replace('#', '').strip()
# 检查是否为表格
elif re.search(r'^\|.+\|$|^\\+[-]+\\+$', block, re.MULTILINE):
content_type = 'table'
# 检查是否为引用
elif block.startswith('>'):
content_type = 'quote'
chunks.append({
'type': content_type,
'content': block,
'metadata': metadata
})
return chunks
# 示例:混合内容文档
mixed_content = """# 项目文档
## 安装步骤
1. 下载安装包
2. 运行安装程序
3. 配置环境变量
## 代码示例
```python
def hello_world():
print("Hello, World!")
注意事项
重要:请确保系统版本符合要求
| 性能对比表: |
方案 |
速度 |
内存使用 |
| A |
快 |
高 |
| B |
慢 |
低 |
""" |
chunks = content_aware_chunking(mixed_content)
print("\n内容感知分块结果:")
for i, chunk in enumerate(chunks, 1):
print(f"\n块 {i} - 类型: {chunk['type']}")
if chunk['metadata']:
print(f"元数据: {chunk['metadata']}")
print(f"内容预览: {chunk['content'][:60]}...")
**何时使用:**
- 适用于混合格式的文档。
- 当你希望分块能尊重文档的格式和含义时,例如保持表格完整、段落完整等。
---
## 三、智能分块策略
### 14. 基于主题的分块(Topic-based Chunking)
使用主题建模技术(如LDA)或聚类算法识别文本中的主题,将同一主题的内容组织在一起。
你在主题变化时分割文本,方法是:首先,将其拆分为更小的部分(句子或段落)。然后,使用主题建模或聚类将相关的部分分组到单个块中。
```python
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import numpy as np
def topic_based_chunking(texts: list, n_topics: int = 3):
"""基于主题的分块"""
# 将文本分割成句子
all_sentences = []
for text in texts:
sentences = re.split(r'[。!?.!?]+', text)
all_sentences.extend([s.strip() for s in sentences if s.strip()])
# 创建文档-词矩阵
vectorizer = CountVectorizer(max_df=0.95, min_df=2, stop_words='english')
X = vectorizer.fit_transform(all_sentences)
# 训练LDA模型
lda = LatentDirichletAllocation(
n_components=n_topics,
max_iter=10,
learning_method='online',
random_state=42
)
lda.fit(X)
# 获取每个句子的主题分布
topic_distribution = lda.transform(X)
# 将句子按主要主题分组
topic_groups = {i: [] for i in range(n_topics)}
for i, probs in enumerate(topic_distribution):
main_topic = np.argmax(probs)
topic_groups[main_topic].append(all_sentences[i])
# 生成分块
chunks = []
for topic_id, sentences in topic_groups.items():
if sentences:
# 获取主题关键词
feature_names = vectorizer.get_feature_names_out()
top_words = [
feature_names[i]
for i in lda.components_[topic_id].argsort()[:-6:-1]
]
chunk = {
'topic_id': topic_id,
'top_keywords': top_words,
'content': ' '.join(sentences),
'sentence_count': len(sentences)
}
chunks.append(chunk)
return chunks
# 示例:多主题文档
documents = [
"机器学习包括监督学习、无监督学习和强化学习。深度学习是机器学习的一个分支。",
"神经网络由神经元组成,通过反向传播算法进行训练。卷积神经网络专门用于图像处理。",
"自然语言处理涉及文本分类、情感分析和机器翻译。Transformer架构显著提升了NLP性能。",
"计算机视觉任务包括图像分类、目标检测和图像分割。YOLO和ResNet是流行模型。"
]
print("\n基于主题的分块结果:")
chunks = topic_based_chunking(documents, n_topics=3)
for chunk in chunks:
print(f"\n主题 {chunk['topic_id']} - 关键词: {', '.join(chunk['top_keywords'])}")
print(f"句子数: {chunk['sentence_count']}")
print(f"内容预览: {chunk['content'][:100]}...")
何时使用:
- 当你的文档涵盖多个主题,并且你希望每个块专注于一个想法时。
- 适用于主题逐渐变化但没有明确标题或关键词标记的文本。
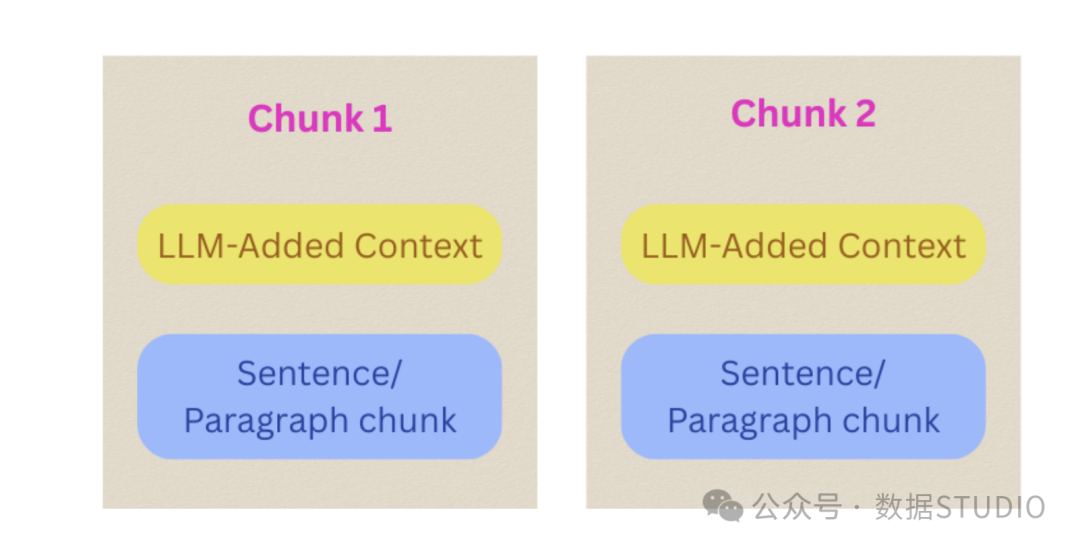
15. 上下文分块(Contextual Chunking)
使用LLM为每个分块添加上下文信息,增强检索时的相关性理解。
import openai
from typing import List, Dict
def contextual_chunking(texts: List[str], context_prompt: str = None):
"""上下文分块:使用LLM为分块添加上下文"""
if context_prompt is None:
context_prompt = """请为以下文本块提供以下上下文信息:
1. 核心主题(1-3个关键词)
2. 与前文可能的关联
3. 关键实体(人物、地点、组织等)
4. 情感倾向(积极/消极/中性)
请以JSON格式返回。"""
contextual_chunks = []
for i, text in enumerate(texts):
# 构建增强提示
enhanced_prompt = f"{context_prompt}\n\n文本块:\n{text}"
# 调用LLM API(示例结构,实际使用需要API密钥)
try:
# 注意:实际应用中需要配置OpenAI API密钥
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个专业的文本分析助手。"},
{"role": "user", "content": enhanced_prompt}
],
temperature=0.3
)
# 解析响应
context_info = response.choices[0].message.content
# 尝试解析JSON(如果LLM以JSON格式返回)
import json
try:
context_dict = json.loads(context_info)
except:
context_dict = {"raw_context": context_info}
# 创建增强的分块
enhanced_chunk = {
"original_text": text,
"context": context_dict,
"enhanced_text": f"上下文信息:{context_info}\n\n原始内容:{text}"
}
contextual_chunks.append(enhanced_chunk)
except Exception as e:
print(f"LLM上下文增强失败:{e}")
contextual_chunks.append({
"original_text": text,
"context": {},
"enhanced_text": text
})
return contextual_chunks
def contextual_chunking_simple(texts: List[str]):
"""简化版的上下文分块(模拟)"""
contextual_chunks = []
for i, text in enumerate(texts):
# 模拟LLM生成的上下文
mock_context = {
"core_topics": ["AI", "机器学习"],
"previous_context": f"第{i}部分,共{len(texts)}部分",
"key_entities": ["Transformer", "GPT"],
"sentiment": "中性"
}
enhanced_chunk = {
"original_text": text,
"context": mock_context,
"enhanced_text": f"核心主题:{', '.join(mock_context['core_topics'])}\n"
f"关键实体:{', '.join(mock_context['key_entities'])}\n\n"
f"原始内容:{text}"
}
contextual_chunks.append(enhanced_chunk)
return contextual_chunks
# 示例使用
sample_texts = [
"Transformer架构是自然语言处理的重大突破。",
"它通过自注意力机制实现了高效并行计算。",
"BERT和GPT都是基于Transformer的著名模型。"
]
print("\n上下文分块结果(简化版):")
chunks = contextual_chunking_simple(sample_texts)
for i, chunk in enumerate(chunks, 1):
print(f"\n块 {i}:")
print(f"核心主题: {chunk['context']['core_topics']}")
print(f"增强文本预览: {chunk['enhanced_text'][:80]}...")
何时使用:
- 需要深度理解上下文的复杂文档,如法律合同、学术论文、技术标准等。
16. 语义分块(Semantic Chunking)
根据语义相似度动态分块,保持话题连贯性。你使用嵌入相似性将讨论同一事物的句子或段落分组,以保持块在主题上集中。
from sentence_transformers import SentenceTransformer
import numpy as np
def semantic_chunking(text: str, threshold: float = 0.7):
"""基于语义相似度的分块"""
# 首先分割成句子
sentences = sentence_chunking(text)
if len(sentences) <= 1:
return [text]
# 加载嵌入模型(首次运行需要下载)
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
# 计算句子嵌入
embeddings = model.encode(sentences)
# 基于余弦相似度合并句子
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
# 计算当前句子与前一句的相似度
similarity = np.dot(embeddings[i], embeddings[i-1]) / (
np.linalg.norm(embeddings[i]) * np.linalg.norm(embeddings[i-1])
)
if similarity > threshold:
# 语义相似,合并到当前块
current_chunk.append(sentences[i])
else:
# 语义变化,开始新块
chunks.append(' '.join(current_chunk))
current_chunk = [sentences[i]]
# 添加最后一个块
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
# 注意:实际使用中可能需要安装 sentence-transformers
# pip install sentence-transformers
何时使用:
- 当段落或固定窗口分块等更简单的技术失败时。
- 适用于包含混合主题的长文档。
17. 递归分块(Recursive Chunking)
先按大分隔符切分,对过大的块再递归使用小分隔符切分。
你首先使用较大的分隔符(例如,段落)分割文本。
如果任何生成的块超出了你预设的块大小限制,则使用较小的分隔符(例如,句子或单词)递归地进一步分割这些块,直到所有块都在所需的大小内。
def recursive_chunking(text: str, separators: list = None, chunk_size: int = 100):
"""递归分块:先按段落,再按句子,最后按固定大小"""
if separators is None:
separators = ['\n\n', '。', '!', '?', '.', ' ']
def recursive_split(chunk, separator_index=0):
# 递归终止条件:块足够小或没有更多分隔符
if len(chunk) <= chunk_size or separator_index >= len(separators):
return [chunk] if chunk.strip() else []
separator = separators[separator_index]
parts = chunk.split(separator)
# 合并分隔符回去(除了空格)
if separator != ' ':
parts = [part + separator for part in parts[:-1]] + [parts[-1]]
result = []
for part in parts:
if len(part) > chunk_size:
# 递归分割
result.extend(recursive_split(part, separator_index + 1))
else:
if part.strip():
result.append(part.strip())
return result
return recursive_split(text)
# 示例文本
sample_text = """深度学习(Deep Learning)是机器学习的一个分支。它基于人工神经网络,特别是深度神经网络。这些网络可以学习数据的层次化表示。
在计算机视觉领域,深度学习已经取代了许多传统方法。卷积神经网络(CNN)是其中最成功的架构之一。
自然语言处理也受益于深度学习。Transformer架构和注意力机制彻底改变了这个领域。"""
chunks = recursive_chunking(sample_text, chunk_size=50)
print("\n递归分块结果(最大块大小50):")
for i, chunk in enumerate(chunks, 1):
print(f"块 {i}({len(chunk)}字符): {chunk[:45]}...")
何时使用:
- 适用于句子长度不均匀或不可预测的文本,如访谈、演讲或自由形式的写作。
18. 嵌入分块(Embedding-based Chunking)
先对文本单元(如句子)进行嵌入,然后根据嵌入向量的相似性动态合并或分割,形成语义连贯的块。
from sentence_transformers import SentenceTransformer
import numpy as np
from sklearn.cluster import AgglomerativeClustering
from typing import List, Tuple
class EmbeddingChunker:
"""基于嵌入的分块器"""
def __init__(self, model_name: str = 'paraphrase-multilingual-MiniLM-L12-v2'):
self.model = SentenceTransformer(model_name)
self.chunks = []
def chunk_by_embedding(self, text: str,
method: str = 'similarity_merge',
threshold: float = 0.75,
min_chunk_size: int = 50,
max_chunk_size: int = 500):
"""基于嵌入的分块"""
# 第一步:分割成基本单元(句子)
base_units = self._split_into_units(text)
if len(base_units) <= 1:
return [{'content': text, 'units': 1, 'method': 'single'}]
# 第二步:计算嵌入向量
embeddings = self.model.encode(base_units)
# 第三步:根据方法进行分块
if method == 'similarity_merge':
chunks = self._similarity_merge(base_units, embeddings, threshold, max_chunk_size)
elif method == 'clustering':
chunks = self._clustering_merge(base_units, embeddings, min_chunk_size)
elif method == 'sliding_window':
chunks = self._sliding_window_merge(base_units, embeddings, threshold)
else:
raise ValueError(f"未知方法: {method}")
# 第四步:后处理,确保块大小合适
final_chunks = []
for chunk in chunks:
if len(chunk['content']) > max_chunk_size:
# 对过大的块进行二次分割
sub_chunks = self._recursive_split(chunk['content'], max_chunk_size)
final_chunks.extend(sub_chunks)
elif len(chunk['content']) >= min_chunk_size:
final_chunks.append(chunk)
return final_chunks
def _split_into_units(self, text: str) -> List[str]:
"""将文本分割成基本单元(句子)"""
# 使用多种分割符
sentences = re.split(r'[。!?.!?;;]+', text)
sentences = [s.strip() for s in sentences if s.strip()]
# 对于长句,进一步分割
final_units = []
for sentence in sentences:
if len(sentence) > 200:
# 按逗号、分号等进一步分割
sub_units = re.split(r'[,,;;]+', sentence)
sub_units = [u.strip() for u in sub_units if u.strip()]
final_units.extend(sub_units)
else:
final_units.append(sentence)
return final_units
def _similarity_merge(self, units: List[str], embeddings: np.ndarray,
threshold: float, max_size: int) -> List[dict]:
"""基于相似度合并"""
chunks = []
current_chunk = [units[0]]
current_embeddings = [embeddings[0]]
for i in range(1, len(units)):
# 计算当前单元与当前块平均嵌入的相似度
chunk_embedding = np.mean(current_embeddings, axis=0)
similarity = self._cosine_similarity(embeddings[i], chunk_embedding)
# 检查块大小限制
chunk_text = ' '.join(current_chunk + [units[i]])
if similarity > threshold and len(chunk_text) <= max_size:
# 相似度高,合并到当前块
current_chunk.append(units[i])
current_embeddings.append(embeddings[i])
else:
# 相似度低或块太大,保存当前块并开始新块
chunks.append({
'content': ' '.join(current_chunk),
'units': len(current_chunk),
'avg_similarity': float(np.mean([
self._cosine_similarity(current_embeddings[j], current_embeddings[j+1])
for j in range(len(current_embeddings)-1)
])) if len(current_embeddings) > 1 else 1.0
})
current_chunk = [units[i]]
current_embeddings = [embeddings[i]]
# 添加最后一个块
if current_chunk:
chunks.append({
'content': ' '.join(current_chunk),
'units': len(current_chunk),
'avg_similarity': float(np.mean([
self._cosine_similarity(current_embeddings[j], current_embeddings[j+1])
for j in range(len(current_embeddings)-1)
])) if len(current_embeddings) > 1 else 1.0
})
return chunks
def _clustering_merge(self, units: List[str], embeddings: np.ndarray,
min_size: int) -> List[dict]:
"""基于聚类合并"""
# 使用层次聚类
n_clusters = max(2, len(units) // 5) # 自适应确定簇数
clustering = AgglomerativeClustering(
n_clusters=n_clusters,
metric='cosine',
linkage='average'
)
labels = clustering.fit_predict(embeddings)
chunks = []
for cluster_id in range(n_clusters):
cluster_indices = np.where(labels == cluster_id)[0]
if len(cluster_indices) == 0:
continue
# 获取该簇的所有单元
cluster_units = [units[i] for i in cluster_indices]
cluster_content = ' '.join(cluster_units)
if len(cluster_content) >= min_size:
# 计算簇内平均相似度
cluster_embeddings = embeddings[cluster_indices]
similarities = []
for i in range(len(cluster_embeddings)):
for j in range(i+1, len(cluster_embeddings)):
similarities.append(self._cosine_similarity(
cluster_embeddings[i], cluster_embeddings[j]
))
chunks.append({
'content': cluster_content,
'units': len(cluster_units),
'cluster_id': cluster_id,
'avg_similarity': float(np.mean(similarities)) if similarities else 1.0
})
return chunks
def _sliding_window_merge(self, units: List[str], embeddings: np.ndarray,
threshold: float) -> List[dict]:
"""滑动窗口合并"""
chunks = []
window_size = 3 # 滑动窗口大小
i = 0
while i < len(units):
window_end = min(i + window_size, len(units))
# 检查窗口内单元的相似度
window_units = units[i:window_end]
window_embeddings = embeddings[i:window_end]
# 计算窗口内平均相似度
similarities = []
for j in range(len(window_embeddings)):
for k in range(j+1, len(window_embeddings)):
similarities.append(self._cosine_similarity(
window_embeddings[j], window_embeddings[k]
))
avg_similarity = np.mean(similarities) if similarities else 0
if avg_similarity > threshold or window_end - i == 1:
# 相似度高或只剩一个单元,扩展窗口
while window_end < len(units):
# 尝试添加下一个单元
new_unit_embedding = embeddings[window_end]
# 计算新单元与窗口内所有单元的平均相似度
new_similarities = [
self._cosine_similarity(new_unit_embedding, emb)
for emb in window_embeddings
]
new_avg = np.mean(new_similarities)
if new_avg > threshold * 0.9: # 稍微宽松的阈值
window_units.append(units[window_end])
window_embeddings = np.vstack([window_embeddings, new_unit_embedding])
window_end += 1
else:
break
# 保存窗口内容作为一个块
chunks.append({
'content': ' '.join(window_units),
'units': len(window_units),
'window_avg_similarity': float(avg_similarity)
})
i = window_end
return chunks
def _recursive_split(self, text: str, max_size: int) -> List[dict]:
"""递归分割过大的块"""
if len(text) <= max_size:
return [{'content': text, 'units': 1}]
# 尝试在自然边界处分割
mid = len(text) // 2
# 寻找最近的分割点
split_chars = ['。', '!', '?', '.', '!', '?', ';', ';', ',', ',']
best_split = -1
best_distance = float('inf')
for char in split_chars:
# 从中间向两边寻找分割符
for offset in range(0, min(mid, len(text) - mid)):
# 向右寻找
right_pos = text.find(char, mid + offset)
if right_pos != -1:
distance = abs(right_pos - mid)
if distance < best_distance:
best_distance = distance
best_split = right_pos + len(char)
break
# 向左寻找
left_pos = text.rfind(char, 0, mid - offset)
if left_pos != -1:
distance = abs(left_pos - mid)
if distance < best_distance:
best_distance = distance
best_split = left_pos + len(char)
break
if best_split == -1:
# 没有找到合适的分割点,强制在中间分割
best_split = mid
# 递归分割两部分
left_part = self._recursive_split(text[:best_split].strip(), max_size)
right_part = self._recursive_split(text[best_split:].strip(), max_size)
return left_part + right_part
def _cosine_similarity(self, a: np.ndarray, b: np.ndarray) -> float:
"""计算余弦相似度"""
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 示例:使用嵌入分块
embedding_text = """机器学习是人工智能的核心领域。它使计算机能够从数据中学习。
深度学习是机器学习的一个分支。它使用神经网络模拟人脑。
神经网络由多层神经元组成。每层提取不同层次的特征。
卷积神经网络擅长处理图像。循环神经网络适合序列数据。
Transformer架构在NLP中表现卓越。它使用自注意力机制。
BERT和GPT都是基于Transformer的模型。它们在大规模文本上预训练。
迁移学习利用预训练模型。这减少了对标注数据的需求。"""
print("\n嵌入分块结果:")
chunker = EmbeddingChunker()
# 方法1:相似度合并法
print("\n1. 相似度合并法:")
chunks1 = chunker.chunk_by_embedding(
embedding_text,
method='similarity_merge',
threshold=0.7,
min_chunk_size=30,
max_chunk_size=200
)
for i, chunk in enumerate(chunks1, 1):
print(f" 块 {i}: {chunk['units']}个单元,相似度: {chunk['avg_similarity']:.3f}")
print(f" 内容: {chunk['content'][:80]}...")
# 方法2:聚类法
print("\n2. 聚类法:")
chunks2 = chunker.chunk_by_embedding(
embedding_text,
method='clustering',
min_chunk_size=30
)
for i, chunk in enumerate(chunks2, 1):
print(f" 块 {i} (簇{chunk['cluster_id']}): {chunk['units']}个单元,相似度: {chunk['avg_similarity']:.3f}")
print(f" 内容: {chunk['content'][:80]}...")
何时使用:
- 语义密集但结构不清晰的长文本,需要动态确定分块边界的场景。
19. 智能体分块(Agentic / LLM-based Chunking)
使用LLM智能判断分块边界。你让 LLM 决定如何分割文本,并赋予它完全的控制权,让它以它认为合适的方式进行分割。
# 注意:此示例需要OpenAI API密钥
import openai
import json
def llm_based_chunking(text: str, api_key: str, model: str = "gpt-3.5-turbo"):
"""使用LLM智能分块"""
openai.api_key = api_key
prompt = f"""请将以下文本分割成语义完整的块。每个块应该:
1. 表达一个完整的观点或主题
2. 大小适中(大约100-200字)
3. 在语义边界处分割
文本:
{text[:1000]} # 限制输入长度
请以JSON格式返回结果,包含"chunks"数组。"""
try:
response = openai.ChatCompletion.create(
model=model,
messages=[
{"role": "system", "content": "你是一个专业的文本分析助手。"},
{"role": "user", "content": prompt}
],
temperature=0.3
)
result = json.loads(response.choices[0].message.content)
return result.get("chunks", [text])
except Exception as e:
print(f"LLM分块失败: {e}")
# 降级到递归分块
return recursive_chunking(text)
# 实际使用时取消注释并添加API密钥
# chunks = llm_based_chunking(long_text, api_key="your-api-key")
何时使用:
- 当你的内容复杂或非结构化,需要类似人类的判断来找到合适的分块边界时。
- 注意: 这种方法可能成本较高或耗费资源。
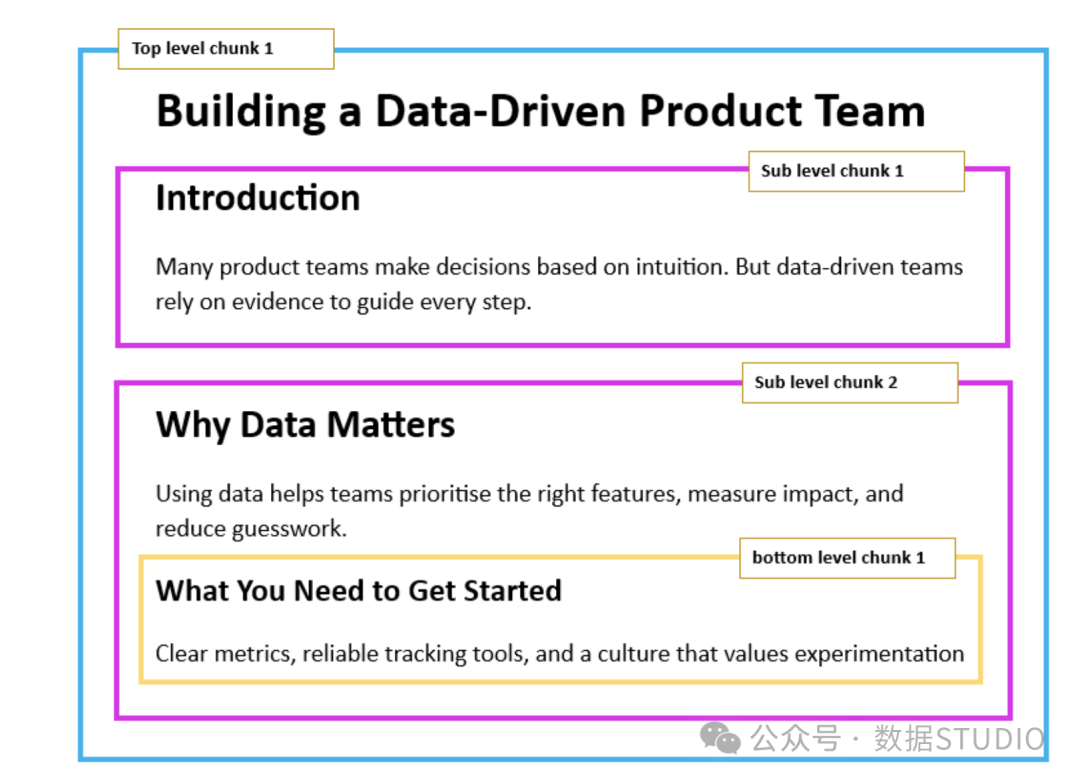
20. 分层分块(Hierarchical Chunking)
创建多层次的分块结构(如文档→章节→段落→句子),支持多粒度检索。
class HierarchicalChunker:
"""分层分块器"""
def __init__(self):
self.hierarchy = {
'document': None,
'chapters': [],
'sections': [],
'paragraphs': [],
'sentences': []
}
def build_hierarchy(self, text: str, max_depth: int = 4):
"""构建分层结构"""
# 清理文本
text = text.strip()
# 设置文档级别
self.hierarchy['document'] = {
'id': 'doc_root',
'content': text[:500] + '...' if len(text) > 500 else text,
'full_content': text,
'length': len(text)
}
# 分割层次
self._split_by_chapters(text, max_depth)
return self.hierarchy
def _split_by_chapters(self, text: str, remaining_depth: int):
"""按章节分割"""
if remaining_depth <= 0:
return
# 检测章节标题(Markdown风格)
patterns = [
(r'^(#{1,3})\s+(.+)$', re.MULTILINE), # 标题
(r'^第[一二三四五六七八九十\d]+章\s+.+$', re.MULTILINE), # 中文章节
(r'^Chapter\s+\d+\s*[:.-]?\s*.+$', re.IGNORECASE | re.MULTILINE) # 英文章节
]
best_matches = []
for pattern, flags in patterns:
matches = list(re.finditer(pattern, text, flags))
if matches and (not best_matches or len(matches) > len(best_matches)):
best_matches = matches
if not best_matches:
# 如果没有找到章节,按段落分割
self._split_by_paragraphs(text, remaining_depth)
return
# 按章节分割文本
chapters = []
last_end = 0
for i, match in enumerate(best_matches):
start = match.start()
# 提取前一个章节的内容
if start > last_end:
chapter_content = text[last_end:start].strip()
if chapter_content:
chapter_title = f"第{i}部分" if i == 0 else f"章节{i}"
chapters.append({
'title': chapter_title,
'level': 1,
'content': chapter_content,
'start_pos': last_end,
'end_pos': start
})
# 当前章节标题
chapter_title = match.group().strip()
level = len(match.group(1)) if match.lastindex and match.group(1) else 1
last_end = start
# 最后一个章节
if last_end < len(text):
chapter_content = text[last_end:].strip()
if chapter_content:
chapters.append({
'title': f"第{len(chapters)+1}部分",
'level': 1,
'content': chapter_content,
'start_pos': last_end,
'end_pos': len(text)
})
# 存储章节并递归处理
self.hierarchy['chapters'] = chapters
for chapter in chapters:
if remaining_depth > 1:
# 递归处理子章节
self._split_by_sections(chapter['content'], remaining_depth - 1, chapter['title'])
def _split_by_sections(self, text: str, remaining_depth: int, parent_title: str):
"""按子章节分割"""
if remaining_depth <= 0:
return
# 检测子标题
pattern = r'^(#{2,4})\s+(.+)$'
matches = list(re.finditer(pattern, text, re.MULTILINE))
sections = []
last_end = 0
for i, match in enumerate(matches):
start = match.start()
# 提取前一个子章节的内容
if start > last_end:
section_content = text[last_end:start].strip()
if section_content:
sections.append({
'parent': parent_title,
'title': f"子章节{i+1}",
'level': 2,
'content': section_content
})
# 当前子章节标题
section_title = match.group(2).strip()
level = len(match.group(1))
last_end = match.end()
sections.append({
'parent': parent_title,
'title': section_title,
'level': level,
'content': '' # 内容会在下次迭代填充
})
# 最后一个子章节
if last_end < len(text):
section_content = text[last_end:].strip()
if section_content:
# 检查最后一个section是否有标题
if sections and sections[-1]['content'] == '':
sections[-1]['content'] = section_content
else:
sections.append({
'parent': parent_title,
'title': f"子章节{len(sections)+1}",
'level': 2,
'content': section_content
})
# 存储子章节
self.hierarchy['sections'].extend(sections)
# 递归处理段落
for section in sections:
if section['content'] and remaining_depth > 2:
self._split_by_paragraphs(section['content'], remaining_depth - 1)
def _split_by_paragraphs(self, text: str, remaining_depth: int):
"""按段落分割"""
paragraphs = re.split(r'\n\s*\n', text)
paragraphs = [p.strip() for p in paragraphs if p.strip()]
paragraph_objs = []
for i, para in enumerate(paragraphs):
para_obj = {
'id': f"para_{len(self.hierarchy['paragraphs']) + 1}",
'content': para,
'length': len(para),
'sentence_count': len(re.split(r'[。!?.!?]+', para))
}
# 如果需要,进一步分割成句子
if remaining_depth > 3 and len(para) > 100:
sentences = self._split_by_sentences(para)
para_obj['sentences'] = sentences
paragraph_objs.append(para_obj)
self.hierarchy['paragraphs'].extend(paragraph_objs)
def _split_by_sentences(self, text: str):
"""按句子分割"""
sentences = re.split(r'[。!?.!?]+', text)
sentences = [s.strip() for s in sentences if s.strip()]
sentence_objs = []
for i, sent in enumerate(sentences):
sentence_objs.append({
'id': f"sent_{len(self.hierarchy['sentences']) + 1}",
'content': sent,
'length': len(sent),
'word_count': len(sent.split())
})
self.hierarchy['sentences'].extend(sentence_objs)
return sentence_objs
def get_chunks_at_level(self, level: str, min_length: int = 0):
"""获取指定层级的块"""
if level == 'document':
return [self.hierarchy['document']] if self.hierarchy['document'] else []
elif level == 'chapters':
chunks = self.hierarchy.get('chapters', [])
elif level == 'sections':
chunks = self.hierarchy.get('sections', [])
elif level == 'paragraphs':
chunks = self.hierarchy.get('paragraphs', [])
elif level == 'sentences':
chunks = self.hierarchy.get('sentences', [])
else:
return []
# 过滤最小长度
return [chunk for chunk in chunks if len(chunk.get('content', '')) >= min_length]
# 示例:构建分层结构
hierarchical_text = """# 机器学习导论
## 第一章 基础概念
机器学习是人工智能的重要分支。
### 1.1 监督学习
监督学习使用带标签的数据进行训练。
例如:分类和回归问题。
### 1.2 无监督学习
无监督学习发现数据中的模式。
例如:聚类和降维。
## 第二章 常用算法
### 2.1 线性回归
线性回归用于预测连续值。
### 2.2 逻辑回归
逻辑回归用于分类问题。"""
print("分层分块结果:")
chunker = HierarchicalChunker()
hierarchy = chunker.build_hierarchy(hierarchical_text, max_depth=4)
# 展示不同层级的块
for level in ['document', 'chapters', 'sections', 'paragraphs']:
chunks = chunker.get_chunks_at_level(level, min_length=10)
print(f"\n{level}层级 - 共{len(chunks)}个块:")
for i, chunk in enumerate(chunks[:3], 1): # 只显示前3个
title = chunk.get('title', chunk.get('id', 'N/A'))
content_preview = chunk.get('content', '')[:60] + '...' if len(chunk.get('content', '')) > 60 else chunk.get('content', '')
print(f" {i}. {title}: {content_preview}")
适用场景:
- 书籍、百科全书、知识库、技术文档等需要支持多粒度检索的场景。
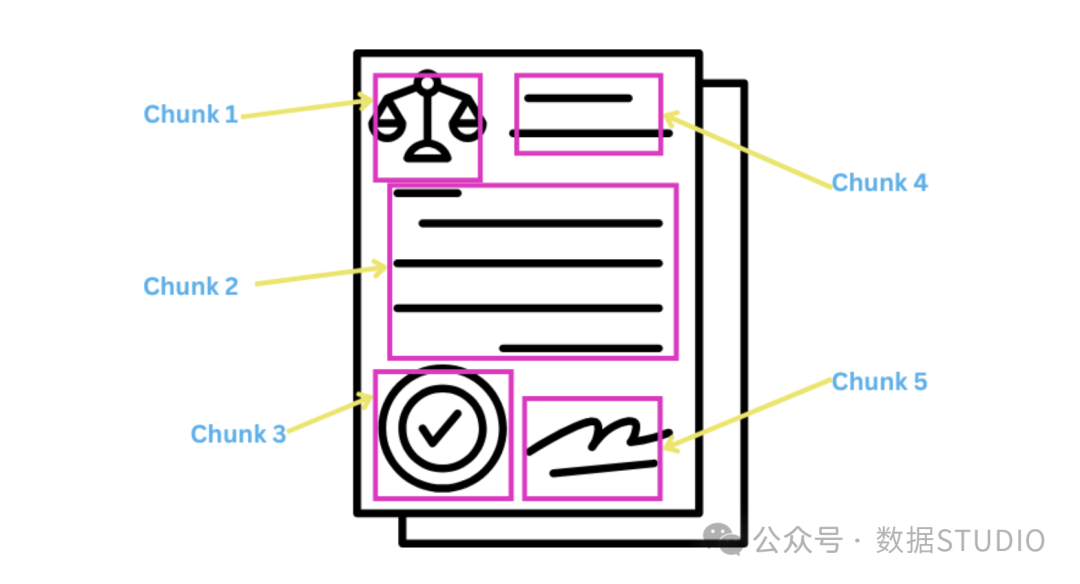
21. 多模态分块(Modality-Aware Chunking)
识别并分别处理文档中的不同内容类型(文本、图像、表格、代码),对每种模态采用最适合的处理方式。
from PIL import Image
import pytesseract
import pandas as pd
import base64
from io import BytesIO
class MultiModalChunker:
"""多模态分块处理器"""
def __init__(self):
self.chunks = []
def process_document(self, document_path: str):
"""处理多模态文档"""
# 根据文件类型选择处理方法
if document_path.lower().endswith('.pdf'):
return self._process_pdf(document_path)
elif document_path.lower().endswith(('.png', '.jpg', '.jpeg')):
return self._process_image(document_path)
elif document_path.lower().endswith('.docx'):
return self._process_docx(document_path)
else:
# 默认为文本文件
return self._process_text(document_path)
def _process_text(self, file_path: str):
"""处理纯文本"""
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 使用内容感知分块处理文本
return self._chunk_by_content_type(text)
def _chunk_by_content_type(self, text: str):
"""根据内容类型分块"""
# 分割成行
lines = text.split('\n')
current_chunk = []
current_type = None
for line in lines:
line = line.rstrip()
if not line:
continue
# 判断行类型
line_type = self._detect_line_type(line)
# 类型变化或块太大时,保存当前块
if (line_type != current_type and current_chunk) or len(current_chunk) > 20:
self._save_chunk(current_chunk, current_type)
current_chunk = []
current_type = line_type
current_chunk.append(line)
# 保存最后一个块
if current_chunk:
self._save_chunk(current_chunk, current_type)
return self.chunks
def _detect_line_type(self, line: str) -> str:
"""检测行内容类型"""
# 检测代码块
if re.search(r'^\s*(```|function|def|class|import|from)', line):
return 'code'
# 检测表格行
if re.search(r'^\|.*\|$', line) or re.search(r'^\+[-]+\+$', line):
return 'table'
# 检测标题
if re.match(r'^#{1,6}\s+', line):
return 'heading'
# 检测列表
if re.match(r'^\s*[\d•\-*]\s+', line):
return 'list'
# 检测图片引用
if re.search(r'!\[.*\]\(.*\)', line) or re.search(r'<img.*?>', line, re.IGNORECASE):
return 'image_ref'
# 默认文本
return 'text'
def _save_chunk(self, lines: list, chunk_type: str):
"""保存块"""
content = '\n'.join(lines)
metadata = {
'line_count': len(lines),
'type': chunk_type
}
# 特殊处理表格
if chunk_type == 'table':
content = self._process_table(content)
self.chunks.append({
'type': chunk_type,
'content': content,
'metadata': metadata
})
def _process_table(self, table_text: str) -> str:
"""处理表格内容"""
try:
# 尝试解析Markdown表格
if '|' in table_text:
# 提取表格行
rows = [row.strip() for row in table_text.split('\n') if '|' in row]
# 清理每行
cleaned_rows = []
for row in rows:
cells = [cell.strip() for cell in row.split('|') if cell.strip()]
cleaned_rows.append(cells)
if len(cleaned_rows) >= 2:
headers = cleaned_rows[0]
data_rows = cleaned_rows[1:] if not cleaned_rows[1][0].startswith('-') else cleaned_rows[2:]
structured = {
'headers': headers,
'rows': data_rows,
'row_count': len(data_rows),
'col_count': len(headers)
}
return json.dumps(structured, ensure_ascii=False)
except:
pass
return table_text
# 示例:多模态混合文档
multimodal_doc = """# 产品技术规格说明书
## 产品概述
XYZ-2000智能传感器是一款高性能工业级设备。
## 技术参数
| 参数 | 数值 | 单位 |
|------|------|------|
| 测量范围 | 0-100 | % |
| 精度 | ±0.5 | % |
| 工作温度 | -20~80 | °C |
## 安装示意图

安装步骤如下:
1. 固定传感器底座
2. 连接数据线
3. 配置参数
## 配置代码示例
```python
# 传感器初始化配置
def init_sensor(config):
sensor = XYZ2000Sensor()
sensor.set_range(config['range'])
sensor.set_precision(config['precision'])
return sensor
注意事项
警告:请勿在潮湿环境中使用。"""
print("\n多模态分块结果:")
chunker = MultiModalChunker()
chunks = chunker._chunk_by_content_type(multimodal_doc)
for i, chunk in enumerate(chunks, 1):
print(f"\n块 {i} - 类型: {chunk['type']}")
print(f"行数: {chunk['metadata']['line_count']}")
print(f"内容预览: {chunk['content'][:80]}...")
**何时使用:**
- 技术文档、产品说明书、研究报告等包含多种内容类型的文档。
---
## 如何选择分块策略?实用决策指南
选择分块策略时,问自己这四个问题:
### 1. 你的文档是什么类型?
- **结构化文档**(Markdown、HTML、JSON):使用[文档结构分块](https://yunpan.plus/f/29-1)
- **半结构化文档**(报告、论文):使用段落或递归分块
- **非结构化文档**(扫描文本、聊天记录):使用固定窗口或语义分块
### 2. 你的查询有什么特点?
- **事实型查询**(具体数据、定义):小分块(句子级)
- **分析型查询**(比较、总结):大分块(段落级)
- **混合型查询**:分层分块或多粒度分块
### 3. 你的硬件和预算限制?
- **资源有限**:选择规则基础的分块(固定窗口、句子分块)
- **有计算资源**:考虑语义分块或LLM分块
- **实时性要求高**:避免计算密集型分块方法
---
## 实战技巧:避免常见分块陷阱
### 陷阱1:切分过碎丢失上下文
**症状**:模型回答不完整,缺乏连贯性
**解决**:增加块大小或使用重叠分块
### 陷阱2:块太大引入噪声
**症状**:检索到无关信息,回答偏离主题
**解决**:减小块大小,使用更精细的分隔符
### 陷阱3:忽略文档结构
**症状**:表格、代码块被切碎,失去意义
**解决**:使用结构感知或表格感知分块
### 陷阱4:处理多种语言混合文档
**症状**:分块边界混乱,特别是标点符号不同
**解决**:使用多语言分句工具,如`spacy`的多语言模型
```python
import spacy
def multilingual_sentence_chunking(text: str, lang: str = "zh"):
"""使用spacy进行多语言分句"""
# 加载对应语言模型(需提前安装)
# python -m spacy download zh_core_web_sm
if lang == "zh":
nlp = spacy.load("zh_core_web_sm")
elif lang == "en":
nlp = spacy.load("en_core_web_sm")
else:
# 默认使用中文
nlp = spacy.load("zh_core_web_sm")
doc = nlp(text)
sentences = [sent.text.strip() for sent in doc.sents]
return sentences
写在最后
分块是RAG系统的基础设施,选对策略事半功倍,选错策略事倍功半。记住这三点核心原则:
- 没有银弹:不同文档类型需要不同分块策略
- 测试为王:用真实查询测试分块效果,观察检索质量
- 迭代优化:从简单策略开始,根据需要逐步升级
在实际项目中,我经常从递归分块开始,它能处理大多数文档类型。对于特别复杂的场景,才会考虑语义分块或LLM分块。
你在实际项目中用过哪些分块策略?遇到了什么有趣的问题或挑战?欢迎在评论区分享你的经验!
如果你觉得这篇文章有帮助,转发给正在搭建RAG系统的同事,一起避开这些坑。下篇文章,我们将深入探讨如何评估分块质量的定量方法。
附:完整策略速查表
为方便参考,以下是21种分块策略的快速总结:
基础策略(6种)
- 按行分块 — 最简单的换行符分割
- 固定窗口分块 — 按固定字符/单词数分割
- 滑动窗口分块 — 固定窗口+重叠
- 按句子分块 — 在句子边界分割
- 按段落分块 — 在段落边界分割
- 按页分块 — 按物理页面分割
结构化策略(7种)
- 结构化分块 — 处理JSON/XML/日志文件
- 文档结构分块 — 利用标题/章节结构
- 关键词分块 — 预定义关键词作为边界
- 实体分块 — 围绕命名实体组织
- 基于token分块 — 精确控制token数量
- 表格感知分块 — 专门处理表格
- 内容感知分块 — 区分段落/列表/代码
智能策略(8种)
- 基于主题分块 — 使用主题建模聚类
- 上下文分块 — LLM添加上下文信息
- 语义分块 — 基于语义相似度
- 递归分块 — 多级分隔符递归分割
- 嵌入分块 — 先嵌入后基于相似度分块
- 智能体分块 — LLM决定分块边界
- 分层分块 — 多粒度信息组织
- 多模态分块 — 文本/图像/表格分别处理
 发表于 2026-3-13 22:00:00
|
查看: 235|
回复: 0
发表于 2026-3-13 22:00:00
|
查看: 235|
回复: 0
