买量不买质?现在还有人在这么想吗?昨天我接到了人生第一个合作,没想到大家的热情直接把阅读量干到了比复现因子还高。这篇继续聊因子,希望同样得到各位的支持,推荐、在看、分享都来一波,没关注的朋友顺手点上。
言归正传。本文接着复现东方证券朱剑涛老师在2021年12月25日发布的研报《因子选股系列研究之八十:收益率的非对称分布与尾部蕴含的Alpha》中的因子。之前我用两篇文章聊过收益率的非对称分布:收益率的不对称性,2007年老外的研究和MMD结合之后,IC居然还挺高! 和 一种超级复杂的衡量不对称性的方法,想法很有意思!。这次聚焦尾部蕴含的Alpha,其中有两个因子,有一个叫CVaR的我已经在 CVaR因子,IC表现不错,分层回测有待提升! 里复现过了。所以,本文专攻 尾部Beta。
计算公式和代码
看到Beta,大家第一反应大多是线性回归的系数。但这里的尾部Beta根本不是那么算的,公式稍显繁琐,下面直接看定义和实现。
1. 计算公式


2. 代码
实现并不复杂,我直接把核心逻辑放在下面(用 Python 完成):
def process_single_day(self, idx):
# 加载当日分钟数据
file_name = self.files[idx]
date_str = file_name.split('.')[0]
cur_time = pd.to_datetime(date_str) + timedelta(hours=15)
full_path = os.path.join(self.file_pth, file_name)
data = BaseDataLoader.load_data(full_path, fields=['close']).to_dataframes()
rtn = data['close'].pct_change()
mkt = rtn.mean(axis=1)
var_rtn = rtn.quantile(0.05)
var_mkt = mkt.quantile(0.05)
tao_j = ((rtn < var_rtn) * (mkt < var_mkt).values.reshape(-1, 1)).mean()
mkt = (-mkt).sort_values()
alpha_m, cnt = 0, 0
for i in range(1, len(mkt)):
if mkt.iloc[-i] >= - var_mkt:
cnt += 1
alpha_m += np.log(1 + mkt.iloc[-i]) - np.log(1 - var_mkt)
alpha_m = alpha_m / cnt
tail_beta = tao_j ** alpha_m * var_rtn / var_mkt
tail_beta.name=cur_time
return tail_beta
前7行:数据读取。
第8行:计算分钟收益率。
第9行:市场平均收益率(等权)。
第10-11行:个股VaR与市场VaR(5%分位数)。
第12行:实现公式中的最后一个统计量,注意这里还没取相反数,所以把原公式的大于号换成了小于号。
第14-19行:估算α̂_m,对应公式中倒数第二个式子。
第20行:组装尾部Beta因子值。
因子评价
经过标准差低频化处理后,这个因子的IC和分层回测表现均优于原始值,因此以下仅展示低频化之后的结果。
01 IC分析
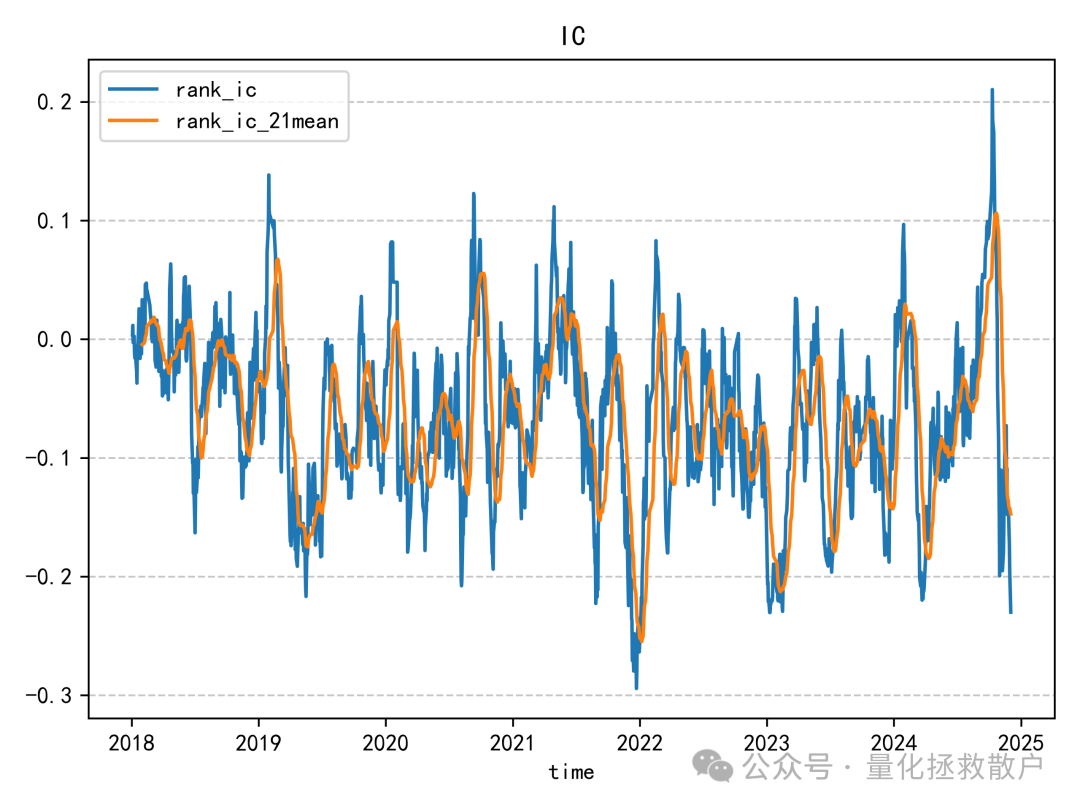
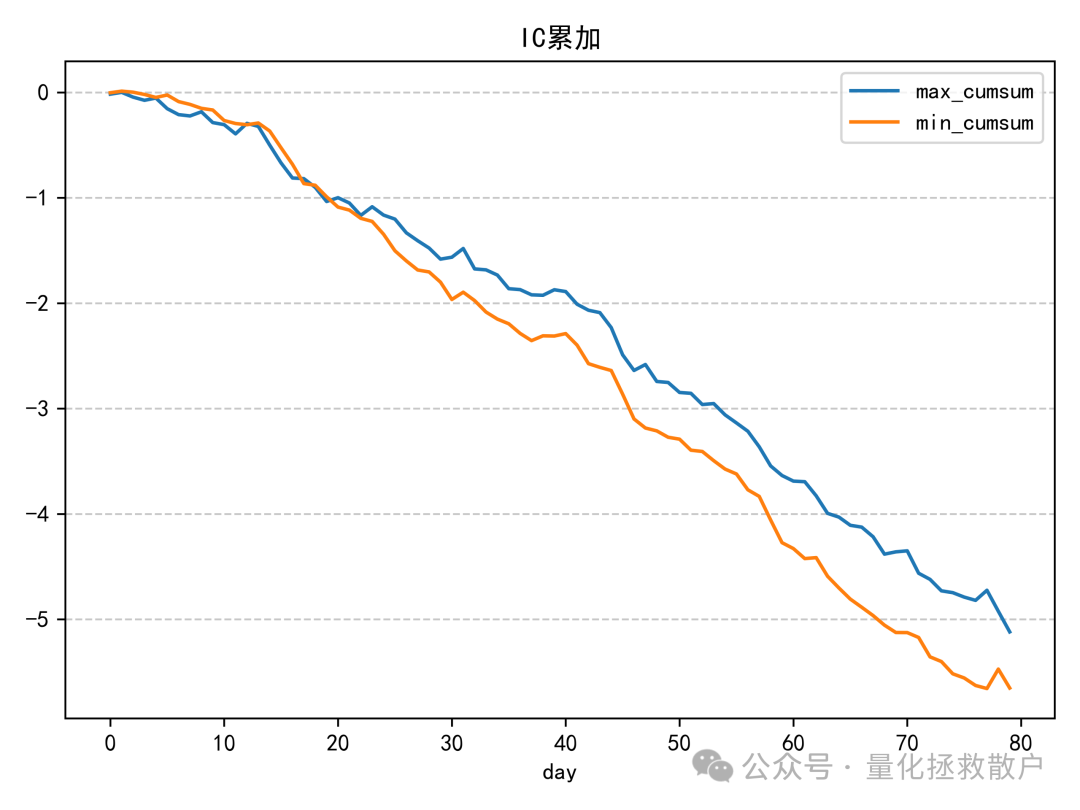
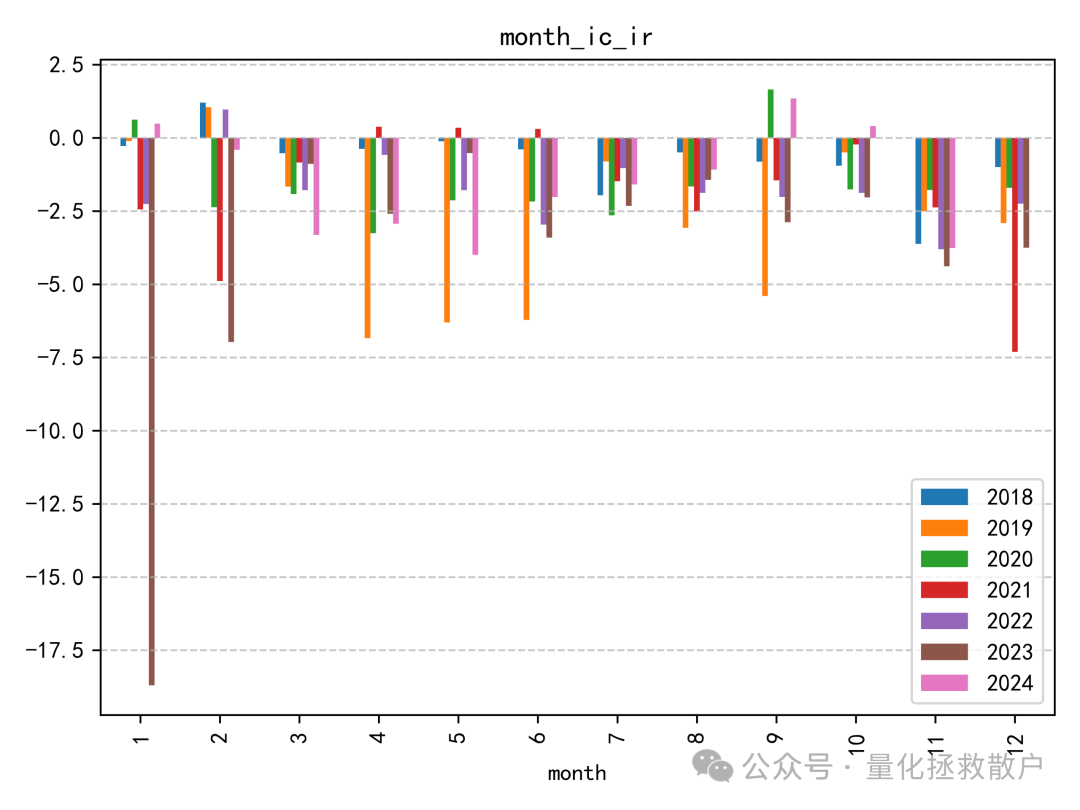
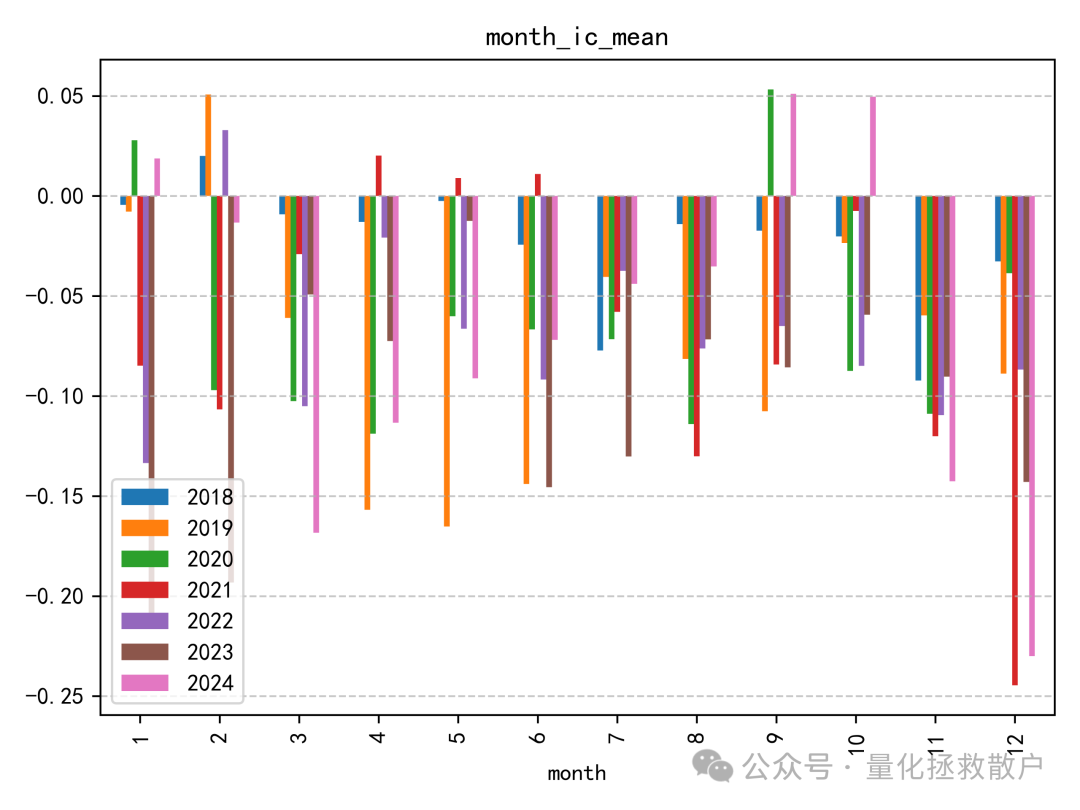
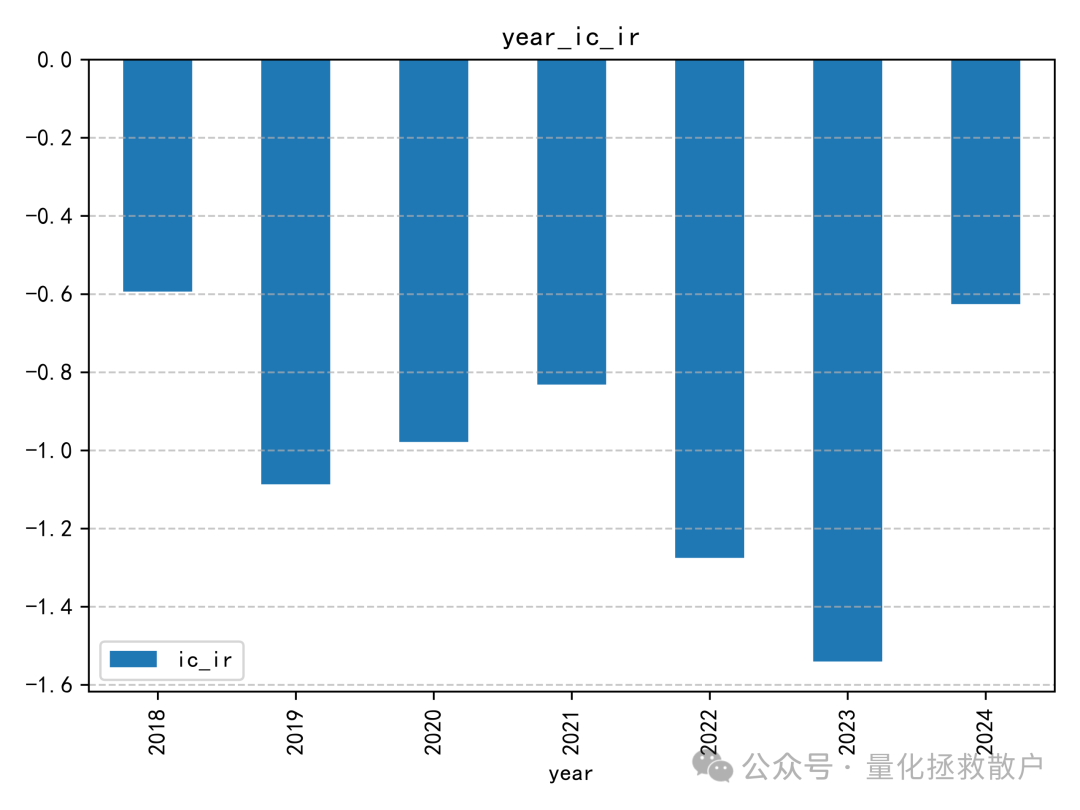
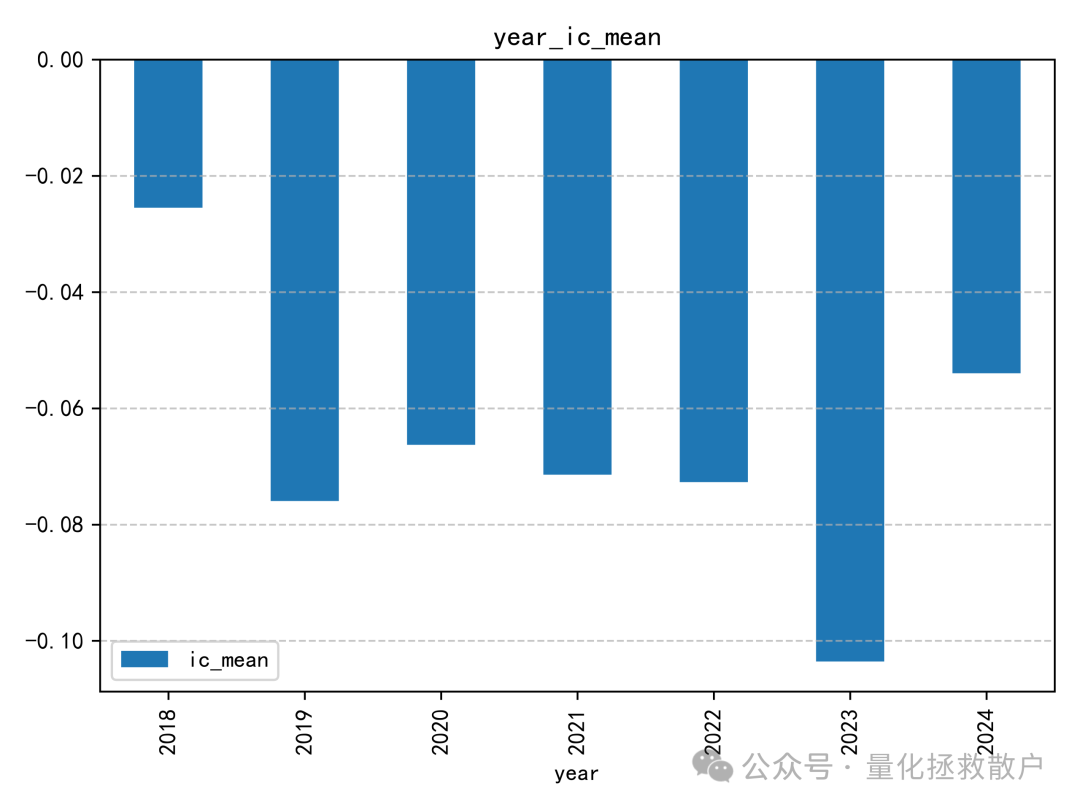
IC表现算是中规中矩,有五年绝对值超过0.06,还有一年超过了0.08。与同研报的其他因子相比,尾部Beta应该排在前列。
02 回归分析
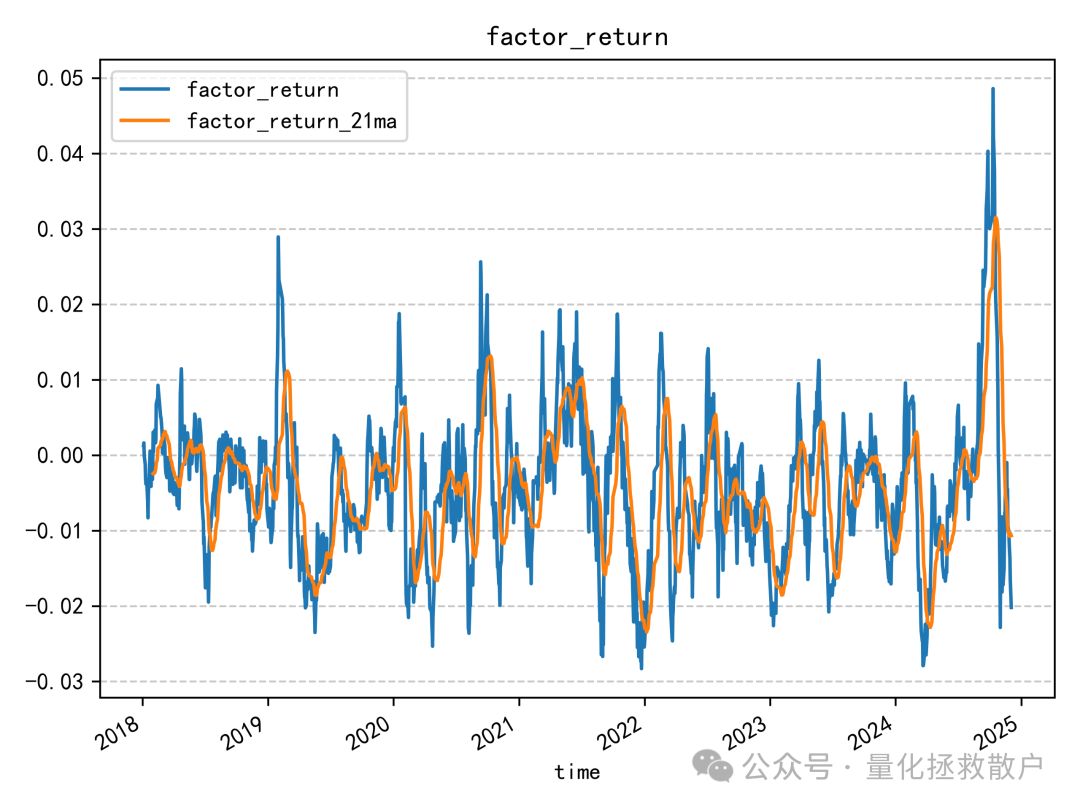
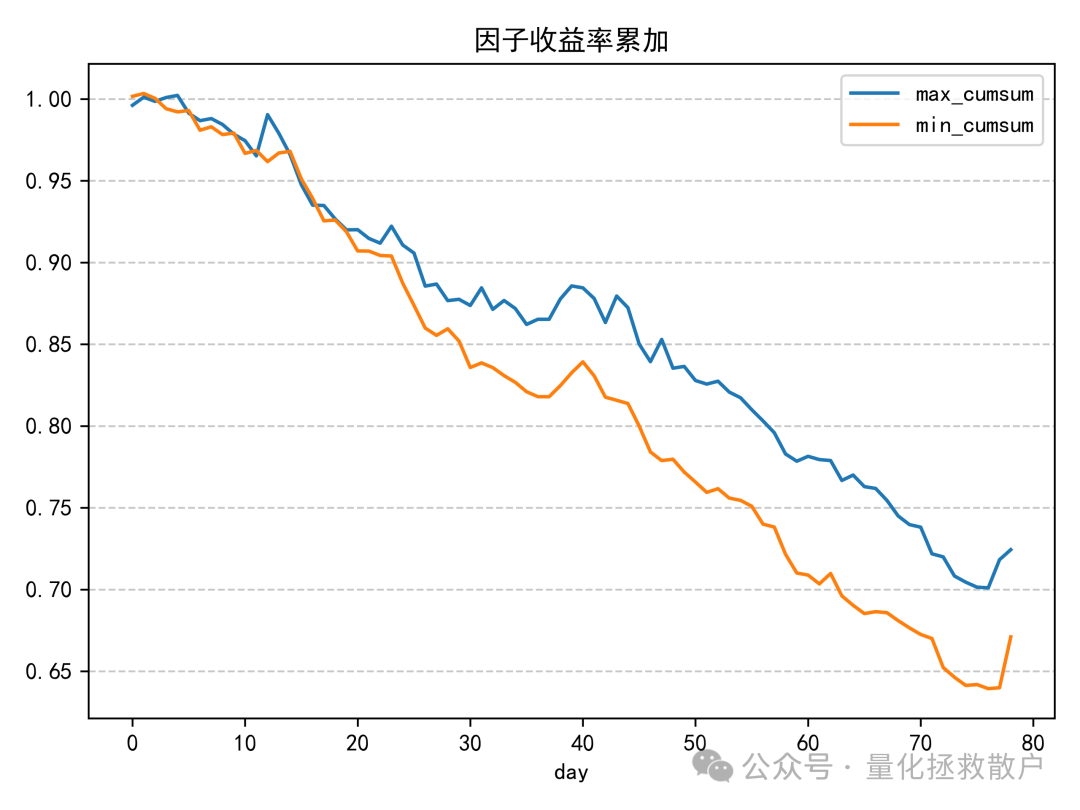
03 换手率分析
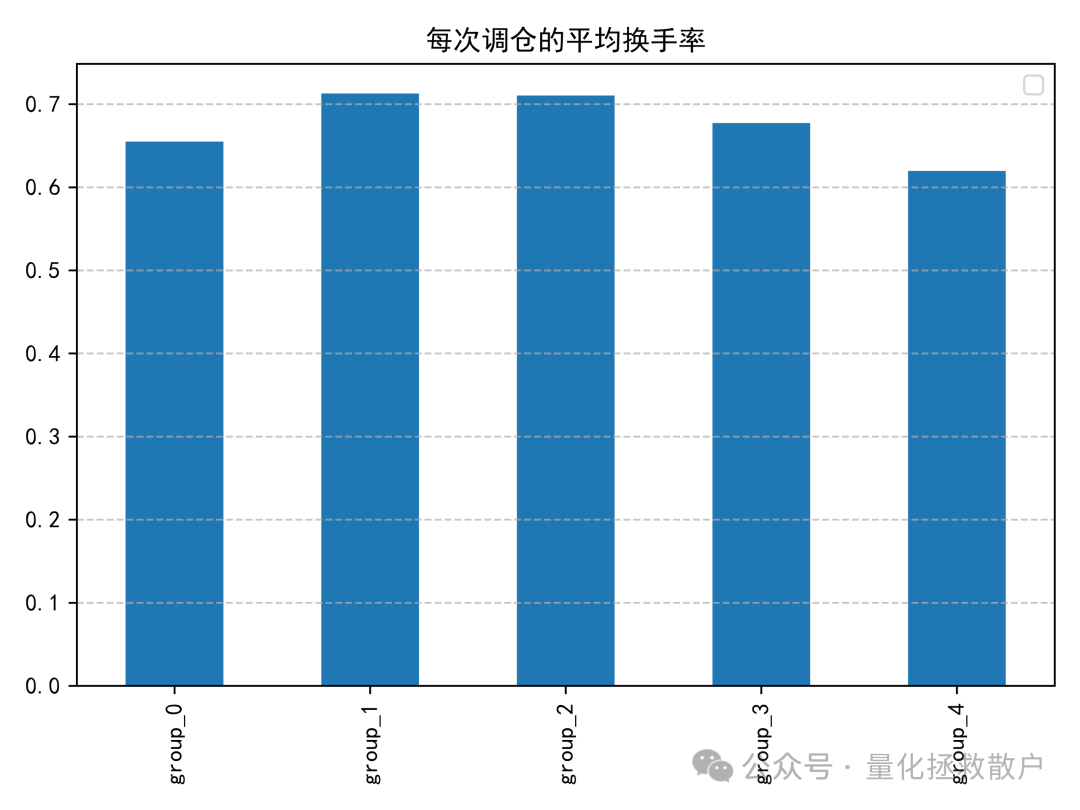
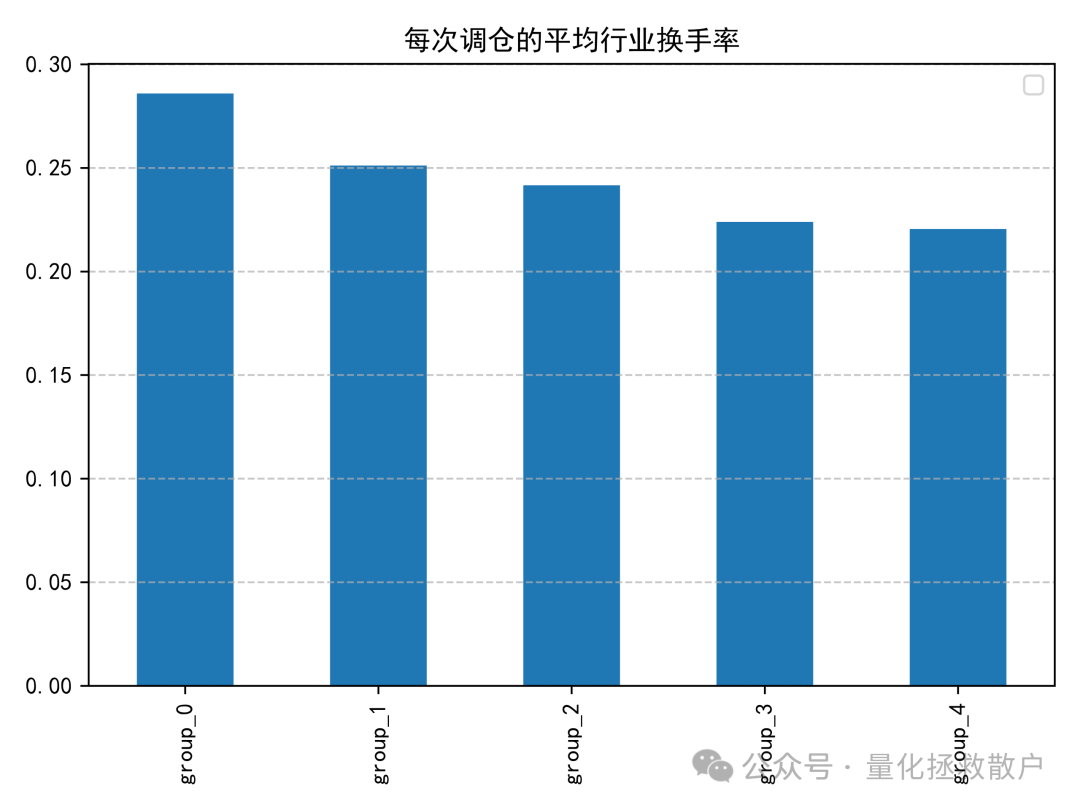
04 收益分析
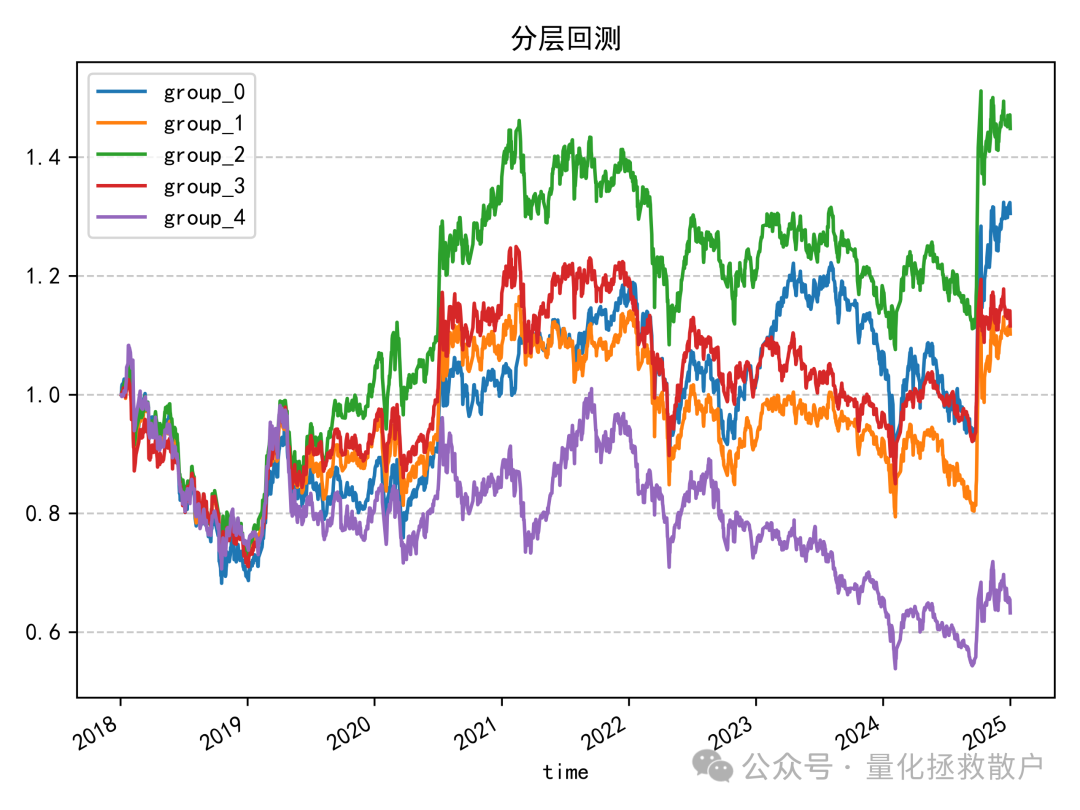
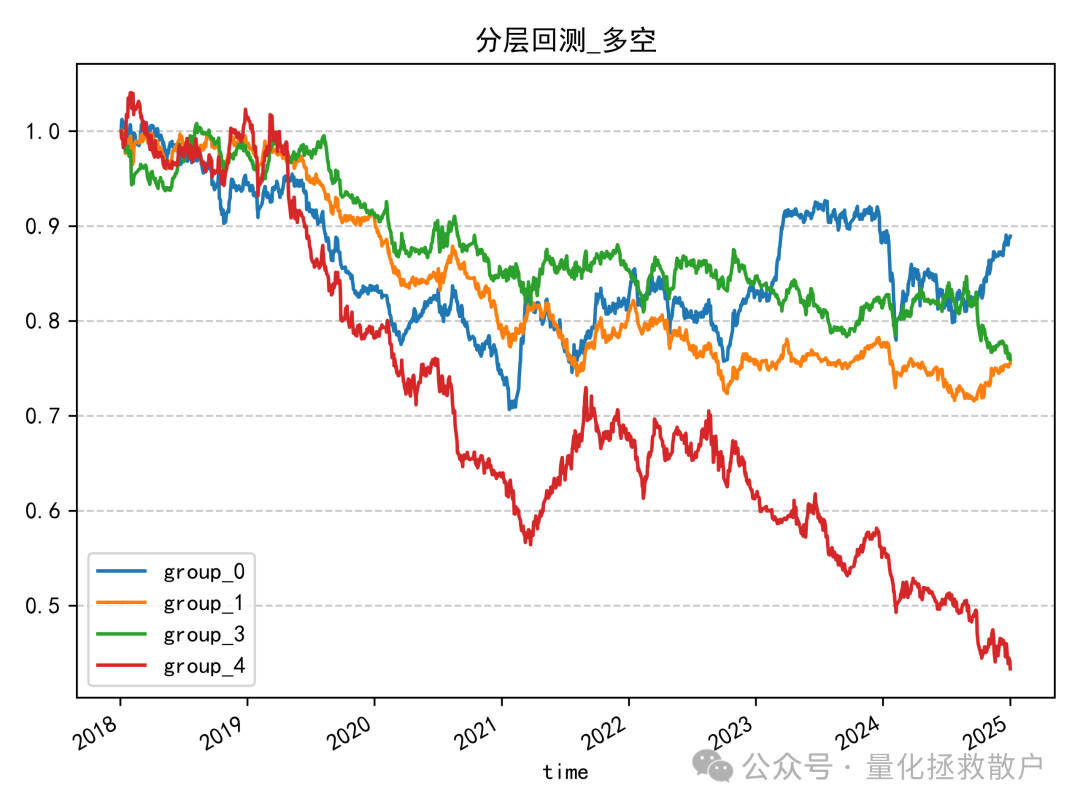
看到这个分层回测结果,我得沉思一会。中间一组表现最亮眼,但又不是那种典型“中间好、两头差”的因子。
有没有办法能改良一下,让它变成教科书级的分层表现?
我用均值/标准差的方式做了尝试,得到下面的结果——说实话,失败了。不过观感上比原始状态好了那么一丢丢。
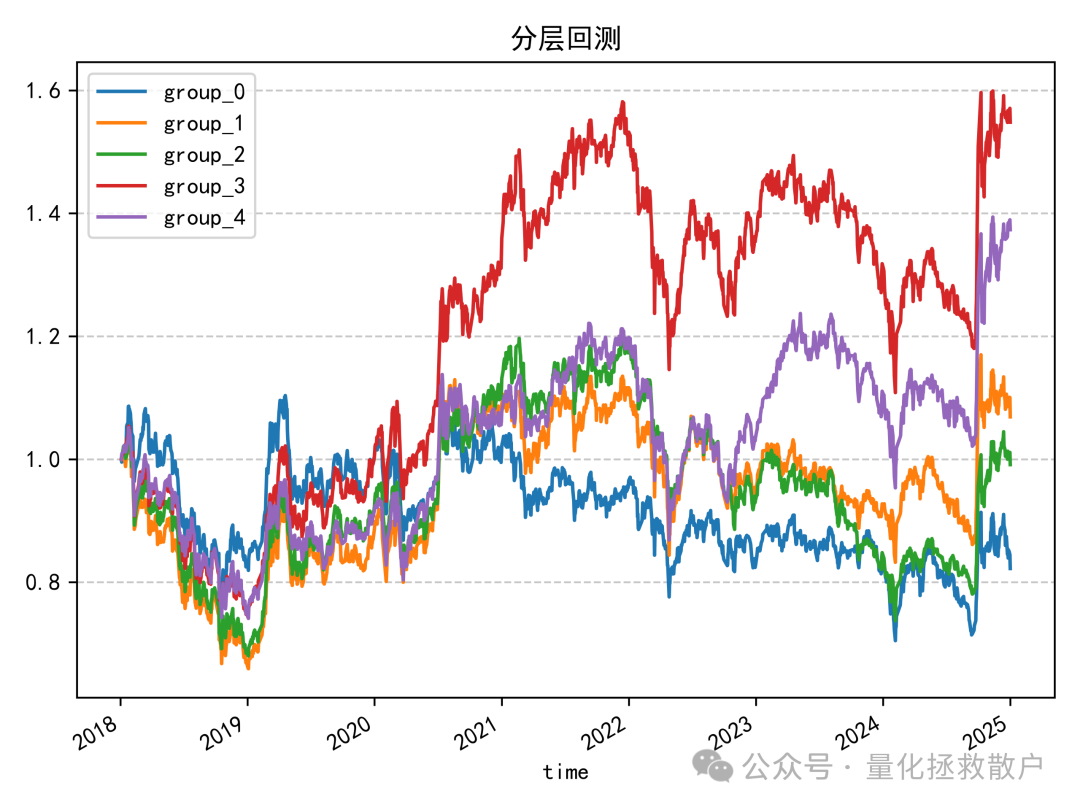
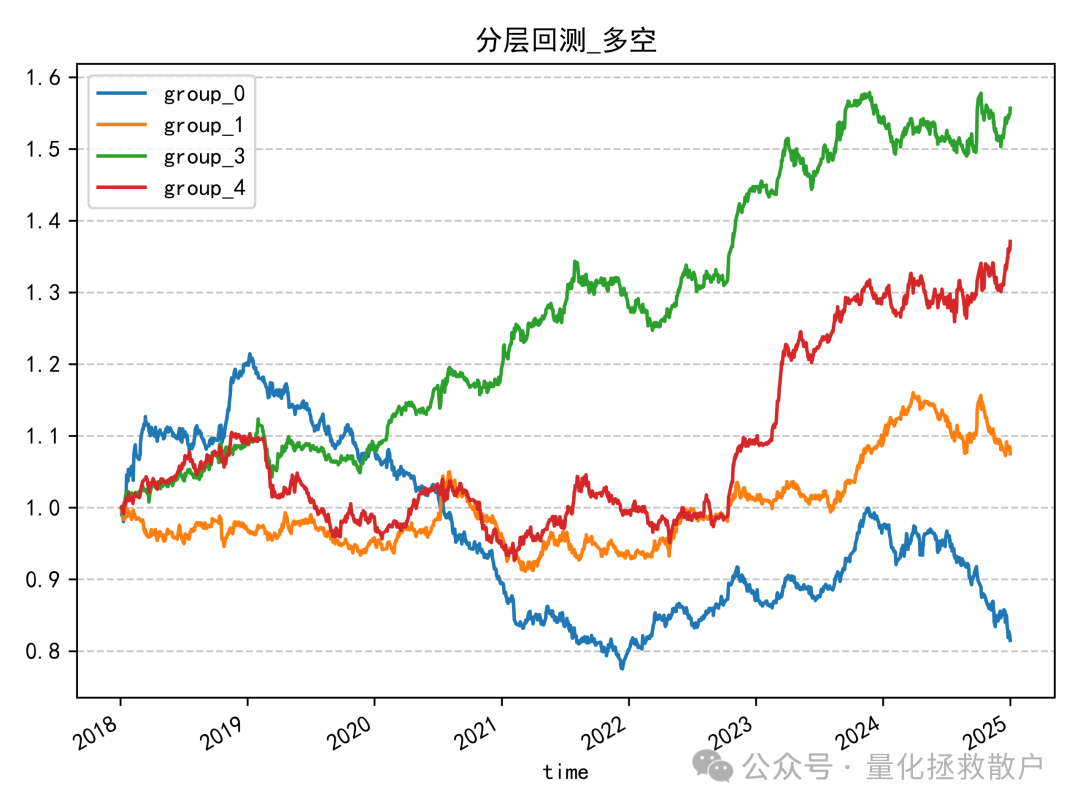
我觉得这个因子还是可以抢救一下的,比如先截面标准化,再低频化处理均值或方差。这活就留给各位大佬去尝试了,不过千万要注意防止过拟合。
嗯,到这里,这个尾部Beta因子的复现基本交代清楚。其实因子研究的乐趣就在于,即便是一个看起来静态的公式,也能通过处理手段撬动出不一样的效果。大家如果在自己的数据上跑出了更好的分层,或者有了新颖的改进方案,也可以到 云栈社区 分享一下,一起打磨更稳健的因子。 |  发表于 2026-4-30 20:47:35
|
查看: 97|
回复: 0
发表于 2026-4-30 20:47:35
|
查看: 97|
回复: 0
