训练大模型时,注意力层的计算开销往往是个“隐形瓶颈”。尤其当模型规模越来越大、上下文越来越长时,这部分开销会悄悄吃掉大量算力和时间。
自 Qwen3-Next 发布以来,Gated Delta Network (GDN) 已成为 Qwen 全系列的主力注意力层,从 Qwen3-Next-80B-A3B 一路延伸到后续推出的 Qwen3.5 / Qwen3.6 系列。随着模型规模扩展到 397A17B、122A10B、35B、27B,GDN 在端到端训练与推理中的开销也变得不可忽视。
今天我们 开源 FlashQLA —— 一个基于 TileLang 实现的高性能线性注意力算子库。FlashQLA 将 GDN Chunked Prefill 的前向和反向进行了合理的算子融合与性能优化,在 NVIDIA Hopper 上实现多场景相较于 FLA triton Kernel 2-3× 前向加速和 2× 反向加速,对预训练场景和端侧 agentic 推理效率提升明显。
GitHub:https://github.com/QwenLM/FlashQLA
核心亮点
- Gate 驱动的自动化卡内序列并行:利用 GDN gate 的指数衰减性质,在 TP、长序列、小头数等场景下自动开启卡内序列并行,提高 GPU SM 利用率;
- 硬件友好的代数改写:对 GDN Chunked Prefill 的前向和反向流程进行改写,在不影响数值精度的前提下有效降低 Tensor Core、CUDA Core 及 SFU 开销;
- Tilelang fused warp-specialized kernels:基于 TileLang 构建关键 fused kernel,通过手动 warpgroup specialization 实现数据搬运、Tensor Core 计算与 CUDA Core 计算的重叠。
FLA GDN Chunked Prefill 面临的主要问题
先回顾一下 GDN Chunked Prefill 的前向计算流程,以 chunk idx i 为例:
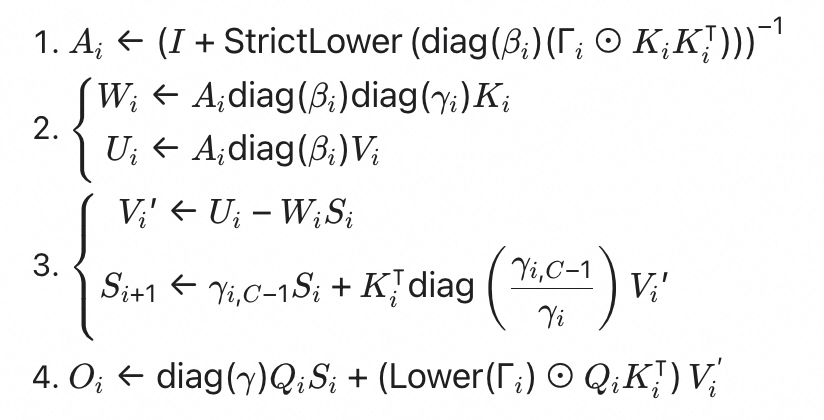
不考虑 gate 的预处理和 CP,该流程在 FLA 中每一步都对应一个 kernel。这带来两个主要问题:
问题一:访存开销较大
以上大多为 memory-bounded kernel,流程中需要反复读取 K、V 等数据,而 W、U、S 作为中间变量也需要写入 HBM 再由下一个 kernel 读取。
问题二:GPU 利用率受限
SSM state 的递推性质导致对应第三步 chunk_gated_delta_rule_fwd_kernel 能同时开出的 thread block 数量仅为 batch_size × num_heads。在小模型、小 batch 或 TP 场景下 GPU 利用率较低。
这两个问题的解法是相互矛盾的。
对于问题一,最直观的解法是写一个 fully-fused kernel,所有数据只做一次访存,所有中间变量都收到片上——在 batch_size × num_heads 足够大时这一定是最优的。
但这样的方案会遇到问题二:对于端侧小尺寸模型 batch_size=1 的推理场景,或大模型线上部署开 TP 遇到 coding agent 等长序列输入做 chunked prefill 开不出足够大 batch 的工况,fully-fused kernel 相比 FLA 原版实现的加速是有限的。
兼顾访存开销与序列并行的解法
基于上述两个问题,可以得到一个折中解法:将 GDN Chunked Prefill 前向计算流程拆分为两个 fused kernel,在其中插入 CP 相关的预处理步骤。经过变换和化简,得到如下计算流程:
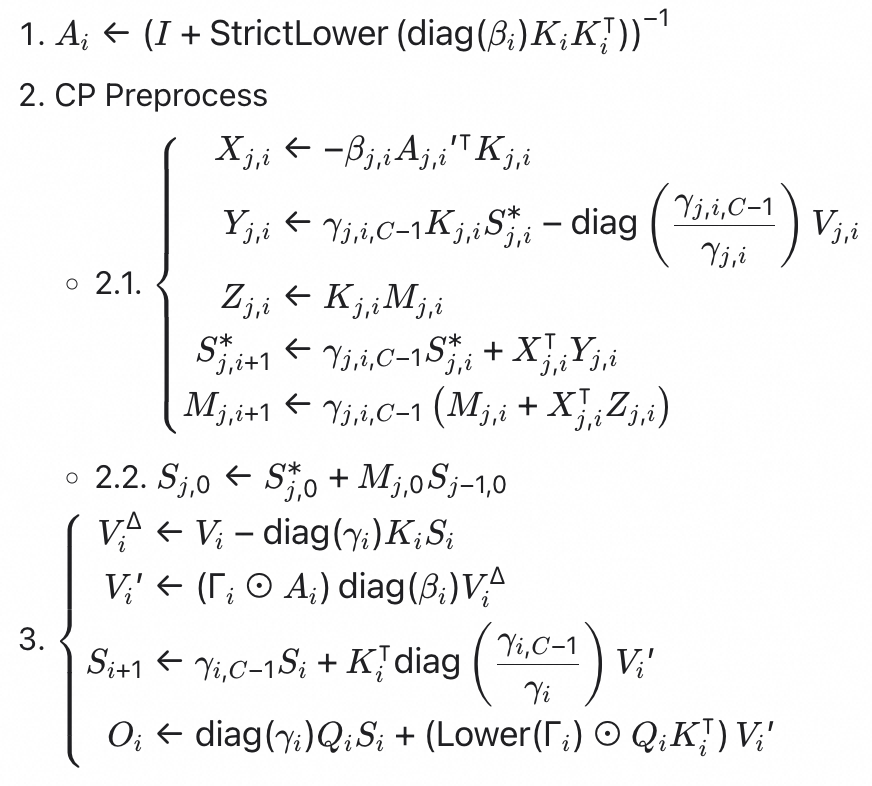
我们还设计了一个简单的数学模型自动计算并行度。设一个序列上的 chunk 数量为 $N$,每个 CP rank 上的 chunk 数量为 $L$。很明显发现,步骤 2.1 和 3 的运行时间正比于 $L$,而步骤 2.2 的运行时间正比于 $N/L$,因此我们可以取 $L = \lambda \sqrt{N}$ 使得总时间最短,其中 $\lambda$ 为 batch_size、num_heads 等其他超参数组成的系数。
实际生产中并不总是需要开启卡内序列并行。参考 FLA 原版实现,步骤 3 也可以通过切分 v_head_dim 增加 2-4× 并行度,代价是对 Q 和 K 的冗余访存。根据实测数据,我们仅在以下两种情况下开启序列并行:
batch_size × num_heads ≤ 40batch_size × num_heads ≤ 56 且 seq_len ≥ 8192
利用 Gate 衰减性质进一步优化
回看 GDN 递推公式:
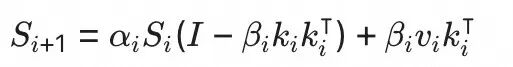
对于 $\alpha_i \in (0,1)$,每个 $S_i$ 对后续状态的影响呈指数衰减,因此具备滑动窗口的性质。对于足够长的窗口尺寸 $W$,从 $S_i - W = 0$ 开始递推即可获取精确的 $S_i$,而不必从 $S_0$ 开始递推。我们将这一过程称为 warmup。在真实数据上,我们发现 60-80% 的线性注意力头上 $\alpha_i$ 不恒为 1,6~8 个 chunk 的 warmup 就足以将 $S_i$ 的误差压低到噪声以下。
由此我们可以针对具备滑窗性质的线性注意力头设计一套更轻量级的 CP preprocess 流程,舍弃对修正量 $M$ 的计算,直接通过 warmup 获得同样精确的子序列 $S_0$:

X 表示用零初始状态做 warmup 直到 gate 衰减到足够小之后写出该 CP rank 的 $S_0$,O 表示后续正常的递推计算。每个 rank 的 warmup 长度由一个独立的 kernel 通过统计 gate 决定,该步骤的耗时是可以忽略的。
Tilelang Warp-Specialized Kernel
基于 TileLang,我们采用 warpgroup specialization 的方式实现:同一个 SM 内包含一个生产者 warpgroup 和三个消费者 warpgroup,通过 shared memory 交换数据,并通过 mbarrier 同步。
前向
在前向流程中,三个消费者 warpgroup 分别计算 V'、S 和 O,并通过 ping-pong 结构遮盖计算与访存:
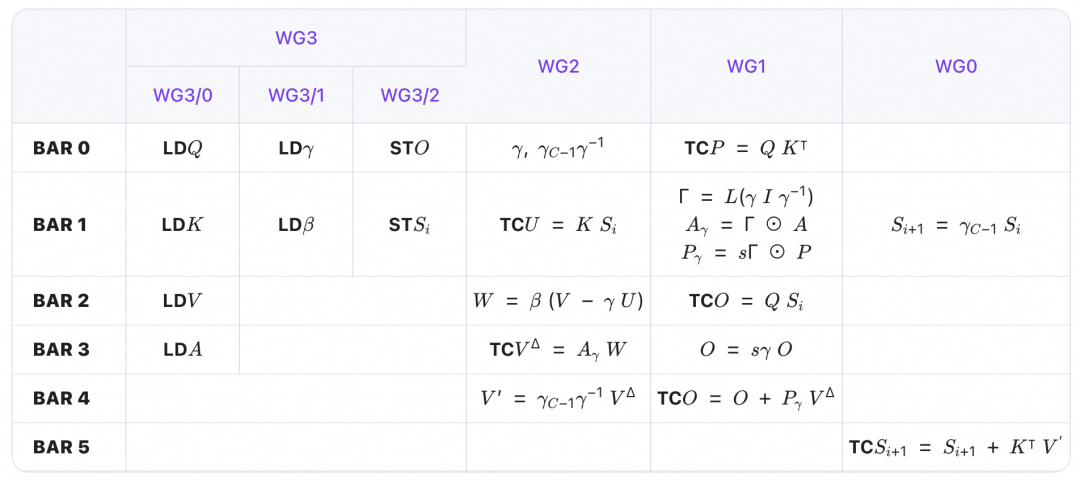
注:每个 chunk 上输出 S 仅作 debug 用,一般只输出 O 和最后一个 chunk 的 S。
序列并行预处理
序列并行预处理分为原始做法(计算 M 和 S)和滑动窗口(仅计算 S)两种情况。我们设计了一个 fused kernel 可以同时处理这两种情况:

注:WG1 和 WG2 的最后两步为计算 M 矩阵的过程,仅在需要时触发。仅反向重算时在每个 chunk 上输出 S。
反向
在反向流程中,可以直接套用序列并行预处理 kernel 重算 S 矩阵;之后把 bwd_dv、bwd_dhu、bwd_dqkwg、bwd_wy 融合到一个 kernel 里,并作相应的代数优化。受片上资源限制,反向 kernel 不设置 multi-stage,而是利用长计算流程遮盖访存。完整的流水线可在 FlashQLA 仓库中查看。

Benchmark
我们在 Qwen3.5 / Qwen3.6 系列的 head 配置上——$h_v \in \{64, 48, 32, 24, 16, 8\}$,对应 TP1 至 TP8——与 FLA Triton 和 FlashInfer baseline(FLA 0.5.0,Triton 3.5.1,FlashInfer 0.6.9,TileLang 0.1.8)做了全面对比。
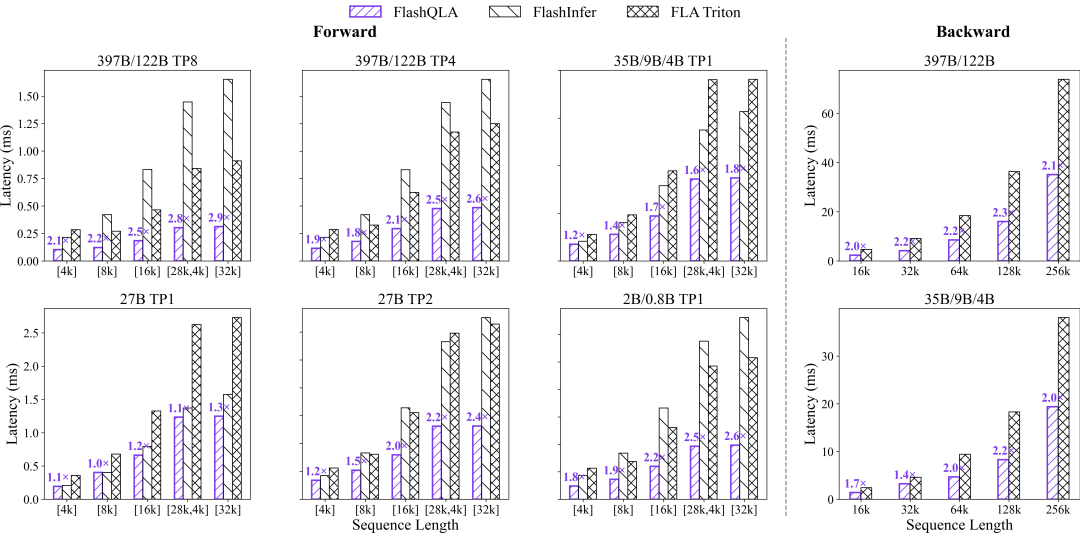
其中 FWD 测试了不同模型、TP setting 下对于不同 batch 长度的单 Kernel latency,BWD 测试了单次更新中 batch 内不同总 token number 与 latency 的关系。
部分 H200 单层前向结果:
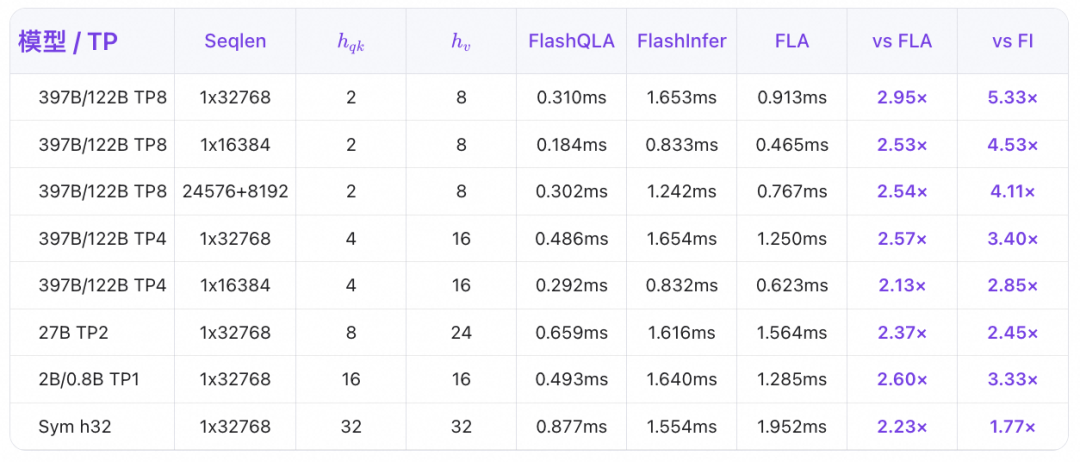
加速比随 TP 增大而提升,这是因为 FlashQLA 能够通过卡内的 AutoCP 提高 TP、小 num_heads 等场景下 SM 利用率。
使用方式
FlashQLA 同时提供了对齐 FLA 签名的 high-level API 与底层 fwd / bwd 入口:
import torch
from qla import chunk_gated_delta_rule
o, final_state = chunk_gated_delta_rule(
q=q, # [B, T, H_q, K]
k=k, # [B, T, H_q, K]
v=v, # [B, T, H_v, V]
g=g, # [B, T, H_v]
beta=beta, # [B, T, H_v]
scale=scale,
initial_state=initial_state, # 可选, [B, H_v, K, V]
output_final_state=True,
cu_seqlens=cu_seqlens, # 可选, varlen 支持
)
环境要求:SM90,CUDA 12.8+,PyTorch 2.8+。安装:
git clone https://github.com/QwenLM/FlashQLA.git
cd FlashQLA && pip install -v .
 发表于 2026-4-30 20:56:29
|
查看: 253|
回复: 0
发表于 2026-4-30 20:56:29
|
查看: 253|
回复: 0
