面壁智能 OpenBMB 在 2 月正式开源了新一代全模态旗舰模型 MiniCPM-o 4.5。虽然参数量仅有 9B,但它却在多项任务上对标甚至追平了一些闭源大模型,因此被许多开发者视为端侧设备上的 GPT‑4o 平替。
目前,MiniCPM-o 4.5 开源模型已经登上了 Hugging Face 的热榜第 2 名,受到了开源社区的广泛关注。
这款模型的强大之处在于,它能同时处理图像、视频、文本和音频输入,并输出文本与语音。更重要的是,它支持全双工交互,这意味着它可以一边“看”视频、一边“听”你说话,同时还能主动“说”话或输出文字,打破了传统AI“一问一答”的回合制模式。它的核心目标,就是将接近 GPT‑4o / Gemini 2.5 Flash 水平的多模态能力,成功塞进手机、PC、车机等终端设备本地运行。
01 开源项目简介:是什么让它与众不同?

MiniCPM-o 4.5 = 9B 参数的开源全模态大模型 + 原生全双工实时交互 + 端侧友好部署
这几个技术关键词听起来很炫酷,我们用更直白的话来解释一下:
① 全模态(Omni)
模型能够同时处理图像、视频、文本、音频等多种模态的输入,并生成文本和语音输出。你可以把它想象成一个集成了眼睛、耳朵和嘴巴的AI大脑。
② 全双工(Full Duplex)
这不是对讲机式的轮流对话。MiniCPM‑o 4.5 的设计目标是让 AI 像人一样,能够持续地接收视觉和听觉信息,并实时决定何时做出回应。换句话说,它可以做到“边看、边听、边说”,输入和输出并行不悖。
听起来简单,实现起来却非常复杂。除了要实现输入输出的并行不阻塞,模型在“说话”时,其“视觉”和“听觉”模块仍需保持工作状态,继续处理实时传入的视频和音频流。这意味着你甚至可以随时打断它、插入新话题,它能立刻理解并调整接下来的回应。
③ 端侧优先(Edge-native)
仅凭 9B 参数量,就在视觉理解、文档解析、语音交互等方面做到了接近 Gemini 2.5 Flash 的水平。同时,其轻量化的设计使其非常适合在本地设备上运行,例如手机、车机、机器人、平板等,为真正的边缘计算和 端侧人工智能 应用铺平了道路。
开源地址:https://github.com/OpenBMB/MiniCPM-o
Hugging Face:https://huggingface.co/openbmb/MiniCPM-o-4_5
02 技术解析:如何做到“全能”且“小巧”?
从技术架构上看,MiniCPM-o 4.5 可以粗略地理解为:在强大的 Qwen3‑8B 语言模型底座上,接入了 SigLIP2 视觉编码器、Whisper 语音理解模块以及 CosyVoice2 语音生成模块,然后通过一个统一的全模态架构将它们深度融合,最终形成了一个端到端的全模态AI系统。
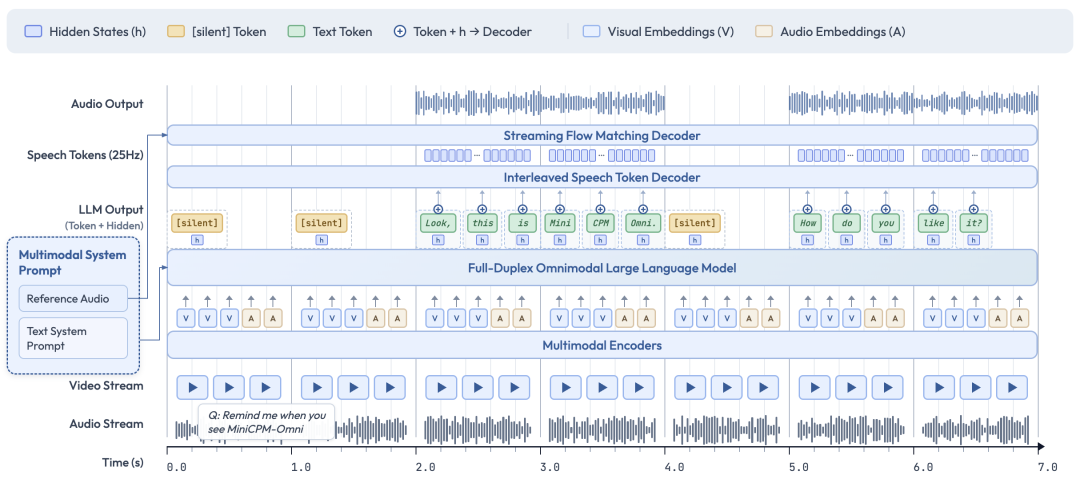
有几个关键技术点值得深入探讨:
① 统一的全模态架构
它不再是“视觉模型处理完扔给语言模型”的松散拼接模式。从输入编码到输出解码,都由一个统一的系统进行协调。文本、语音、图像、视频在一个共享的语义空间里被理解和关联,这使得跨模态推理更加自然和高效。例如,在同时处理视频和音频时,它能综合理解“谁在说话”以及“画面中正在发生什么”,而不是将两者割裂对待。
② 全双工语音解码
其语音解码器采用了文本 token 与语音 token 交错建模的方式。这带来了两个直接好处:首先,在输出语音的过程中,模型仍然可以持续读入新的输入信息,从而实现真正意义上的全双工实时交互;其次,在生成长语音时,能保持更统一的音色和更自然的语气,避免出现“越说越飘”的问题。
③ 高效视觉/视频处理
借鉴了 MiniCPM-V 的优秀设计,它采用了高效的视觉主干网络(backbone)配合 token 压缩策略,能够将高分辨率图像和多帧视频信息压缩到极少量的视觉 token 中。其结果就是,模型进行视频理解的“性价比”极高。在相同的计算预算下,它能处理的视频内容比同类模型多得多,特别适合在端侧设备上进行长视频分析或实时摄像头画面理解。
03 如何快速体验与部署?
最快捷的方式,就是直接在 Hugging Face 上体验官方搭建好的 Demo。你只需要授予网页麦克风和摄像头权限,就能立即与这个会看、会听、会说的 多模态大模型 进行交互。
Demo:https://huggingface.co/spaces/openbmb/MiniCPM-o-4_5-Demo
MiniCPM-o 4.5 之所以在开源社区引发高度讨论,一个重要原因是它并非只存在于论文中的“花瓶模型”,而是从设计之初就充分考虑到了实际部署需求。
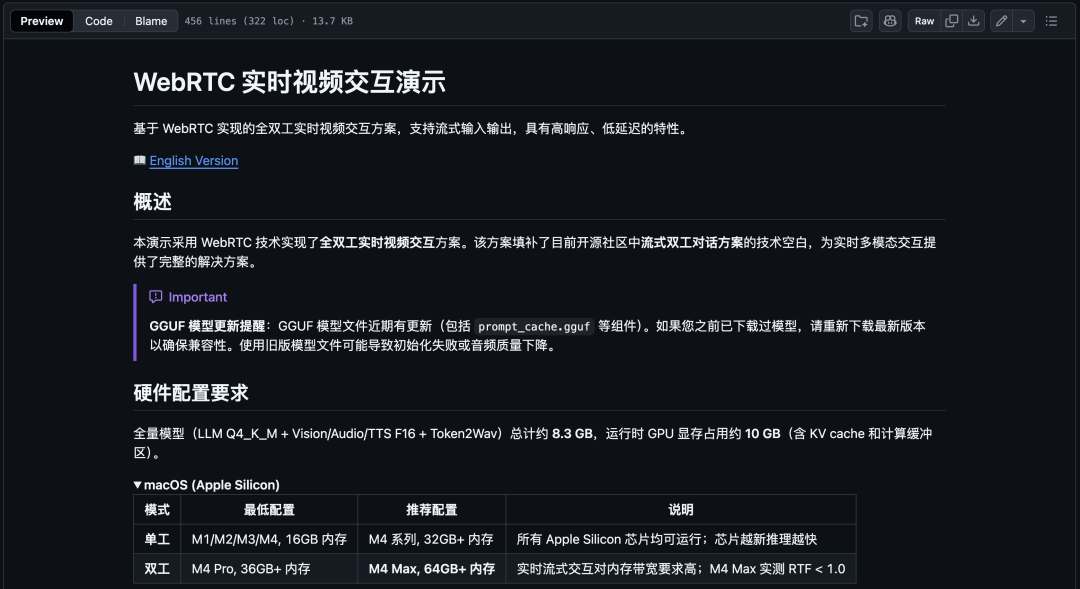
对于想要在本地部署的开发者,官方已经提供了一整套成熟的开源方案,具体部署指引可以参考以下链接:
部署指引:https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/demo/web_demo/WebRTC_Demo/README_zh.md
这套方案包括但不限于:
- llama.cpp-omni:面壁智能自研的开源流式全模态推理框架,主打在端侧/边缘设备上实现低延迟推理,完美支持全双工交互。
- 常见推理框架适配:已支持 vLLM、SGLang、Ollama、LLaMA-Factory 等主流推理框架。
- 多种量化模型:原始 bf16 格式模型约需 19GB 显存;而经过 int4 量化后,内存占用可降至约 11GB 或更低,推理速度可超过 200 tokens/s。这意味着,在一块主流的消费级 GPU 上,你就能跑起一个功能全面的全模态 AI。
此外,在国产算力生态适配方面,MiniCPM-o 4.5 通过 FlagOS 系统软件栈,已经完成了对天数智芯、华为昇腾、平头哥、海光、沐曦等多款国产芯片的适配。对于希望在国产硬件上落地 AI 应用的团队而言,它已经是一个“开箱即用”的成熟选择。
MiniCPM-o 4.5 的发布,展示了 开源社区 在推动尖端 AI 技术民主化和实用化方面的强大力量。将如此强大的多模态能力压缩并优化至可端侧运行的程度,无疑为下一代智能终端应用开启了更多想象空间。无论是对于个人开发者探索创新应用,还是对于企业寻求可靠的国产化AI解决方案,它都提供了一个极具吸引力的起点。
 发表于 2026-2-14 06:37:26
|
查看: 334|
回复: 0
发表于 2026-2-14 06:37:26
|
查看: 334|
回复: 0
