本系列文章旨在探讨如何增强现代智能体系统的可靠性,我们将以直观的方式逐一介绍各类关键设计模式,拆解其设计目的,并通过实现简单可行的版本来演示它们如何融入现实世界的智能体系统。本系列共包含14篇文章,此为第7篇。原文参考:Building the 14 Key Pillars of Agentic AI。
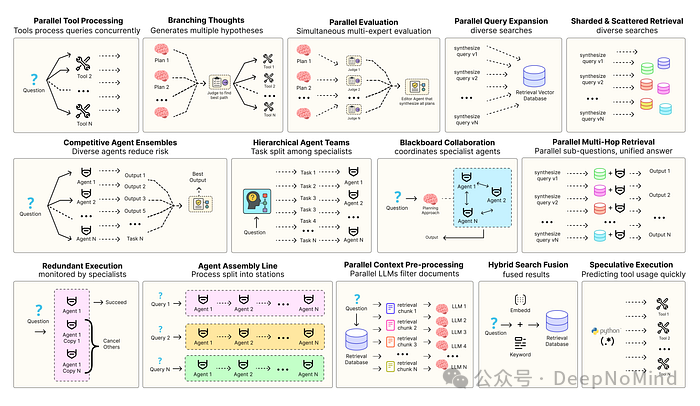
构建一个健壮的智能体解决方案,离不开严谨的软件工程思维,以确保各个组件能够协调、并行运行,并与系统高效交互。例如,预测执行(Speculative Execution) 会尝试预先处理可预见的查询以降低系统时延;而冗余执行(Redundant Execution) 则通过对同一任务启动多个智能体副本来防止单点故障,从而提升系统可靠性。
此外,还有许多其他模式被用于增强现代智能体系统,包括:
- 并行工具调用:智能体同时发起多个独立的API调用,以隐藏I/O等待时间。
- 层级智能体:一个管理者智能体负责将复杂任务拆分为多个小步骤,交由不同的执行智能体处理。
- 竞争性智能体组合:多个智能体针对同一问题提出各自的答案,系统从中选出最佳结果。
- 冗余执行:两个或多个智能体同时解决同一任务,用于错误检测和提升可靠性。
- 并行检索与混合检索:多种检索策略协同运行,以提升上下文的丰富度和质量。
- 多跳检索:智能体通过迭代式的检索步骤,收集更深入、更相关的信息。
本系列的目标是实现这些最常用智能体模式背后的基础概念。所有相关的理论和实践代码都已开源,你可以在GitHub仓库 🤖 Agentic Parallelism: A Practical Guide 🚀 中找到。
该代码库结构清晰,对应本系列的每一篇文章:
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb
支持大吞吐量的代理装配线
到目前为止,我们探讨的并行模式(如并行工具调用、假设生成与评估)主要专注于降低单个复杂任务的时延,目标是让智能体对单个用户查询的响应更快、更智能。
但如果面临的挑战并非单个任务的复杂性,而是需要连续处理大量任务呢?对于许多生产环境中的应用而言,最关键的指标往往不是处理单次请求的速度,而是系统每小时能够处理的总量。
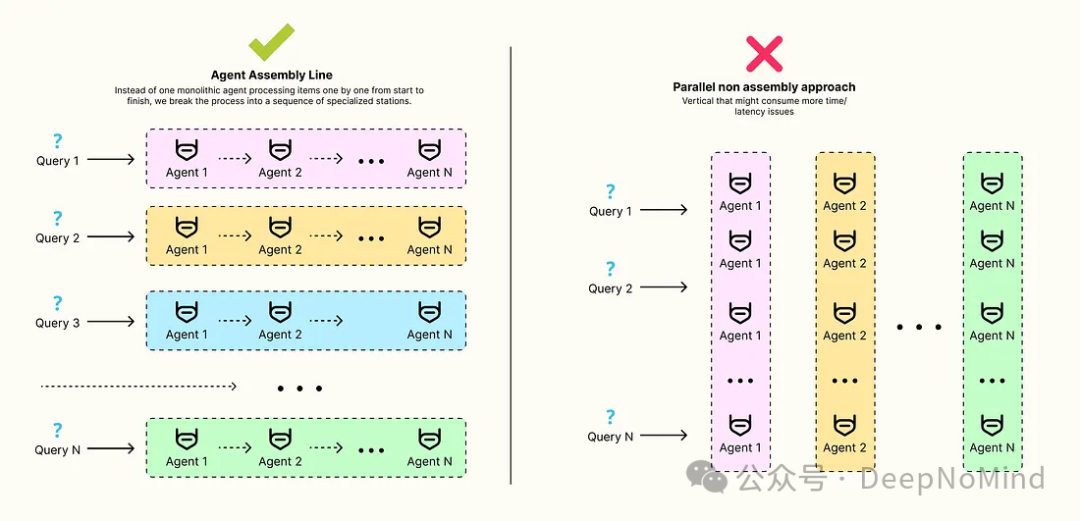
这正是代理装配线(Agent Assembly Line) 架构大显身手的时候。这种设计模式将重点从最小化时延转移到最大化系统吞吐量。其核心思想是:不再让一个庞大的智能体从头到尾逐一处理每个任务项,而是将整个流程分解为一系列专业化的工作站。一旦某个工作站完成对当前任务项的处理,就将其传递给下一站。所有工作站并行工作,同时处理流水线上处于不同阶段的任务项。
接下来,我们将构建一个三阶段流水线,用于处理一批产品评论。我们的目标是:通过严谨的时序分析证明,相较于传统的顺序处理方法,这种并行流水线能显著提升每秒处理的评论数量。
首先,定义代表评论的数据结构。该结构将在装配线上流动,每个工作站都会逐步丰富其内容。
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List, Literal, Optional
class TriageResult(BaseModel):
"""初始分流站的结构化输出"""
category: Literal["Feedback", "Bug Report", "Support Request", "Irrelevant"] = Field(description="The category of the review.")
class Summary(BaseModel):
"""摘要站的结构化输出"""
summary: str = Field(description="A one-sentence summary of the key feedback in the review.")
class ExtractedData(BaseModel):
"""数据提取站的结构化输出"""
product_mentioned: str = Field(description="The specific product the review is about.")
sentiment: Literal["Positive", "Negative", "Neutral"] = Field(description="The overall sentiment of the review.")
key_feature: str = Field(description="The main feature or aspect discussed in the review.")
class ProcessedReview(BaseModel):
"""累积所有站点数据的最终的、经过完全处理的评论对象"""
original_review: str
category: str
summary: Optional[str] = None
extracted_data: Optional[ExtractedData] = None
这些Pydantic模型就像是装配线上的“标准化集装箱”。其中,ProcessedReview 对象是中心数据载体,它在第一个工作站(Triage)被创建,然后在流经后续工作站(summary、extracted_data)时逐渐被丰富。这确保了流水线每个阶段都有明确、一致的数据契约。
接下来,定义整个工作流的状态 PipelineState,它面向批处理操作设计。
from typing import TypedDict, Annotated, List
import operator
class PipelineState(TypedDict):
# ‘initial_reviews‘ 保存传入的原始评论字符串
initial_reviews: List[str]
# ‘processed_reviews‘ 是ProcessedReview对象列表,这些对象是在通过流水线移动时构建的
processed_reviews: List[ProcessedReview]
performance_log: Annotated[List[str], operator.add]
整个装配线工作流将以 initial_reviews 列表作为输入被调用一次,其最终输出将是完整的 processed_reviews 列表。
现在,为装配线上的每个工作站定义处理节点。一个关键实现细节是:每个节点内部都使用 ThreadPoolExecutor 来并行处理分配给它这一阶段的所有任务项。
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
from tqdm import tqdm
MAX_WORKERS = 4 # 控制每个工作站的并行度
# 工作站 1: 分流节点
def triage_node(state: PipelineState):
"""第 1 站:并行的对所有初始评论进行分类"""
print(f"--- [Station 1: Triage] Processing {len(state['initial_reviews'])} reviews... ---")
start_time = time.time()
triaged_reviews = []
# 用 ThreadPoolExecutor 对每个评论进行并行 LLM 调用
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
# We create a future for each review to be triaged.
future_to_review = {executor.submit(triage_chain.invoke, {"review_text": review}): review for review in state['initial_reviews']}
for future in tqdm(as_completed(future_to_review), total=len(state['initial_reviews']), desc="Triage Progress"):
original_review = future_to_review[future]
try:
result = future.result()
# 创建初始 ProcessedReview 对象
triaged_reviews.append(ProcessedReview(original_review=original_review, category=result.category))
except Exception as exc:
print(f'Review generated an exception: {exc}')
execution_time = time.time() - start_time
log = f"[Triage] Processed {len(state['initial_reviews'])} reviews in {execution_time:.2f}s."
print(log)
# 该节点的输出是已处理评论的初始列表
return {"processed_reviews": triaged_reviews, "performance_log": [log]}
triage_node 是装配线的入口。其设计关键在于使用 ThreadPoolExecutor 进行并行化。该节点一次性将所有评论提交给 triage_chain(一个LLM调用链),然后 as_completed 迭代器会在每个调用完成时立即产出结果。这使得我们能高效地构建 triaged_reviews 列表,确保该站点的总耗时由最慢的几个LLM调用决定,而非所有调用耗时的总和。
后续的 summarize_node 和 extract_data_node 遵循相同的并行处理模式:首先从流水线上筛选出自己负责处理的项目,然后进行并行处理。
# 工作站 2: 总结节点
def summarize_node(state: PipelineState):
"""第 2 站:过滤反馈评论并并行总结"""
# 本站只处理“反馈”类评论
feedback_reviews = [r for r in state['processed_reviews'] if r.category == "Feedback"]
if not feedback_reviews:
print("--- [Station 2: Summarizer] No feedback reviews to process. Skipping. ---")
return {}
print(f"--- [Station 2: Summarizer] Processing {len(feedback_reviews)} feedback reviews... ---")
start_time = time.time()
# 用 map 来方便的更新评论
review_map = {r.original_review: r for r in state['processed_reviews']}
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
future_to_review = {executor.submit(summarizer_chain.invoke, {"review_text": r.original_review}): r for r in feedback_reviews}
for future in tqdm(as_completed(future_to_review), total=len(feedback_reviews), desc="Summarizer Progress"):
original_review_obj = future_to_review[future]
try:
result = future.result()
# 在 map 中找到原始评论对象,并用摘要来充实
review_map[original_review_obj.original_review].summary = result.summary
except Exception as exc:
print(f'Review generated an exception: {exc}')
execution_time = time.time() - start_time
log = f"[Summarizer] Processed {len(feedback_reviews)} reviews in {execution_time:.2f}s."
print(log)
# 返回完整的、更新的评论列表
return {"processed_reviews": list(review_map.values()), "performance_log": [log]}
# 工作站 3: 数据提取节点
def extract_data_node(state: PipelineState):
"""最后一站:并行的从总结评论中提取结构化数据"""
# 这个站点只操作带摘要的评论
summarized_reviews = [r for r in state['processed_reviews'] if r.summary is not None]
if not summarized_reviews:
print("--- [Station 3: Extractor] No summarized reviews to process. Skipping. ---")
return {}
print(f"--- [Station 3: Extractor] Processing {len(summarized_reviews)} summarized reviews... ---")
start_time = time.time()
review_map = {r.original_review: r for r in state['processed_reviews']}
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
future_to_review = {executor.submit(extractor_chain.invoke, {"summary_text": r.summary}): r for r in summarized_reviews}
for future in tqdm(as_completed(future_to_review), total=len(summarized_reviews), desc="Extractor Progress"):
original_review_obj = future_to_review[future]
try:
result = future.result()
# 最后一次用提取的数据丰富评论对象
review_map[original_review_obj.original_review].extracted_data = result
except Exception as exc:
print(f'Review generated an exception: {exc}')
execution_time = time.time() - start_time
log = f"[Extractor] Processed {len(summarized_reviews)} reviews in {execution_time:.2f}s."
print(log)
return {"processed_reviews": list(review_map.values()), "performance_log": [log]}
这些节点包含了装配线的过滤逻辑。summarize_node 不会处理所有评论,它只从流水线上拉取标记为“反馈”的项;同样,extract_data_node 只处理那些已被成功总结的项。这种专业化是装配线模式的关键特性之一。
接下来,我们可以使用 LangGraph 将这些节点组装成一个线性的工作流图。
from langgraph.graph import StateGraph, END
# 初始化图
workflow = StateGraph(PipelineState)
# 将三个工作站添加为节点
workflow.add_node("triage", triage_node)
workflow.add_node("summarize", summarize_node)
workflow.add_node("extract_data", extract_data_node)
# 定义装配线的线性流
workflow.set_entry_point("triage")
workflow.add_edge("triage", "summarize")
workflow.add_edge("summarize", "extract_data")
workflow.add_edge("extract_data", END)
# 编译图
app = workflow.compile()
现在,进行最终的关键分析:比较装配线与模拟的单一代理顺序处理评论时的性能,以量化吞吐量的提升。
# 流水线工作流程的总时间是每个阶段处理整个批的时间总和
pipelined_total_time = triage_time + summarize_time + extract_time
# 吞吐量是处理的总件数除以总时间
pipelined_throughput = num_reviews / pipelined_total_time
# 现在模拟顺序的单一代理
# 首先,估算一次评论通过一个阶段所需的平均时间
avg_time_per_stage_per_review = (triage_time + summarize_time + extract_time) / num_reviews
# 单个评论从开始到结束的总时延是三个阶段的时间总和
total_latency_per_review = avg_time_per_stage_per_review * 3
# 顺序代理处理 10 条评论的总时间是 1 条评论时延的 10 倍
sequential_total_time = total_latency_per_review * num_reviews
sequential_throughput = num_reviews / sequential_total_time
# 计算吞吐量增加百分比
throughput_increase = ((pipelined_throughput - sequential_throughput) / sequential_throughput) * 100
print("="*60)
print(" PERFORMANCE ANALYSIS")
print("="*60)
print("\n--- Assembly Line (Pipelined) Workflow ---")
print(f"Total Time to Process {num_reviews} Reviews: {pipelined_total_time:.2f} seconds")
print(f"Calculated Throughput: {pipelined_throughput:.2f} reviews/second\n")
print("--- Monolithic (Sequential) Workflow (Simulated) ---")
print(f"Avg. Latency For One Review to Complete All Stages: {total_latency_per_review:.2f} seconds")
print(f"Simulated Total Time to Process {num_reviews} Reviews: {sequential_total_time:.2f} seconds")
print(f"Simulated Throughput: {sequential_throughput:.2f} reviews/second\n")
print("="*60)
print(" CONCLUSION")
print("="*60)
print(f"Throughput Increase: {throughput_increase:.0f}%")
运行上述分析代码后,我们得到类似以下的结果:
============================================================
PERFORMANCE ANALYSIS
============================================================
--- Assembly Line (Pipelined) Workflow ---
Total Time to Process 10 Reviews: 20.40 seconds
Calculated Throughput: 0.49 reviews/second
--- Monolithic (Sequential) Workflow (Simulated) ---
Avg. Latency For One Review to Complete All Stages: 6.12 seconds
Simulated Total Time to Process 10 Reviews: 61.20 seconds
Simulated Throughput: 0.16 reviews/second
============================================================
CONCLUSION
============================================================
Throughput Increase: 206%
分析结果清晰地展示了装配线模式的强大能力。虽然单个评论从开始到结束走完所有阶段的时延(Latency)大约是6秒,但流水线系统在20秒出头的时间里就处理完了整批10条数据。
相比之下,传统的单一代理顺序处理方式需要超过60秒。装配线模式实现了超过200%的吞吐量提升!这是因为当提取器在处理第一条评论时,总结器已经在处理第二条,而分流代理可能已经在处理第三条了。这种并行、流水线的执行方式,是构建具有AI智能体的高吞吐量数据处理系统的关键设计模式。
希望这篇关于代理装配线的实践指南对你有帮助。如果你想进一步探讨Python在构建复杂AI系统中的应用,或者查看更多相关的技术实践与架构思考,欢迎在云栈社区与其他开发者交流。
 发表于 2026-2-15 07:49:56
|
查看: 336|
回复: 0
发表于 2026-2-15 07:49:56
|
查看: 336|
回复: 0
