今年的 AI 应用开发风向有个明显变化:大家不再只卷模型参数和性能,而是开始琢磨怎么把成本打下来,同时还能让自家的 Agent 别那么“蠢”。
原因很简单。当 Agent 真正跑在生产环境里处理写代码、做客服、分析数据等任务时,一旦上量,账单就成了最扎眼的问题。用最强的模型跑全程,效果稳但费用高;换便宜的小模型,又容易在半路胡言乱语、陷入死循环。这个账,怎么算都肉疼。
你有没有遇到过这种情况?测试时丝滑流畅的 Agent,一遇到稍微复杂的逻辑分支就开始兜圈子,最后要么超时,要么输出一堆答非所问的东西。
我们似乎陷入了一个思维定式:总想找一个智商高、速度快、价格还便宜的“完美模型”。如果找不到,就抱怨模型厂商不给力。但换个角度想:为什么一定要让一个模型扛下所有任务呢?
最近,Anthropic 在官方博客中提出了 The advisor strategy ,为我们提供了一种打破僵局的新思路。我把它理解为一个 “摇人架构” :让一个便宜、高效的模型(如 Sonnet 或 Haiku)作为执行主力(Executor),在遇到棘手难题时,才“摇”一个更聪明但更贵的模型(如 Opus)作为顾问(Advisor)来提供关键指导。
核心理念:这不是任务分派,而是按需求助
常规的 Orchestrator-Worker 模式,是由一个“大脑”(Orchestrator)规划好一切,再交给“手脚”(Worker)去执行。而“摇人架构”恰恰相反。
想象一下,你手下有两个实习生:小K(Sonnet)干活快但有时粗心,大O(Opus)速度慢但经验老道、一眼能看出坑在哪。
“摇人架构”的做法是:直接把活儿交给小K去干,但告诉他:“遇到搞不定的,随时按红色按钮摇人。” 当小K在某个技术细节上卡住时,大O才会介入,快速查看上下文,给出几句关键建议(比如“刷新一下 Token 头”),然后退出。小K得到指点后,继续完成任务。
在这个过程中,昂贵的“专家”只出现在最需要的“决策点”,而大量的“执行流”则由高效的“快手”完成。这极大地优化了成本结构。
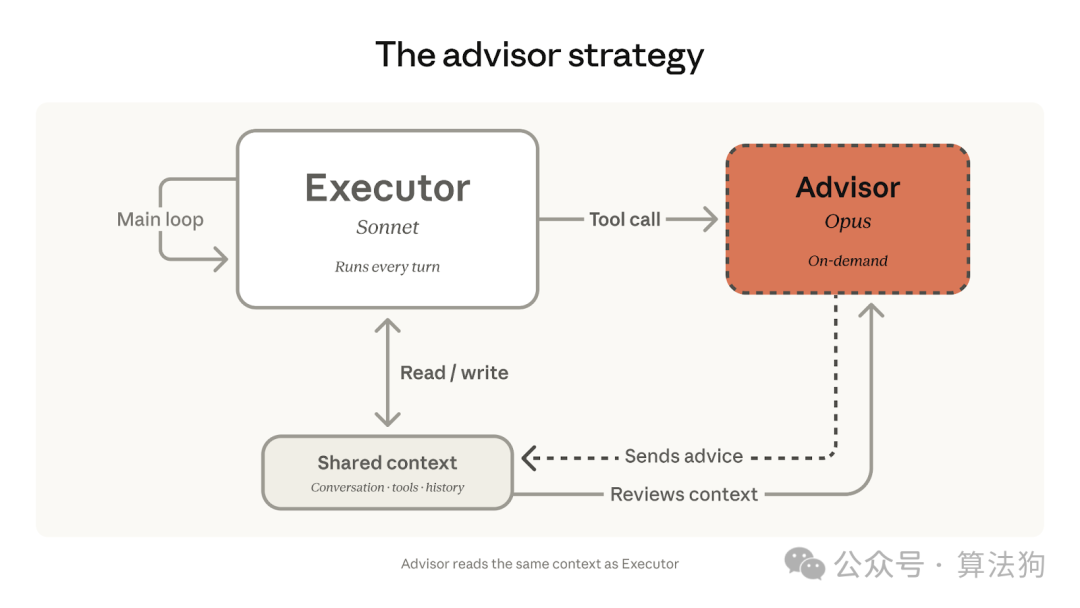
Advisor 策略示意图:Executor(如 Sonnet)负责主循环,仅在需要时通过工具调用(Tool call)咨询 Advisor(如 Opus),两者共享对话上下文。
效果如何?数据说话:智商提升,成本反降
光有理念不够,关键看效果。根据 Anthropic 官方在 SWE-bench Multilingual(一个硬核的软件工程评测集)上的测试:
- 让 Claude 3.5 Sonnet 单独处理任务,已经表现很强。
- 为 Sonnet 配备 Opus 作为顾问后,准确率提升了 2.7 个百分点。 在这个顶尖榜单上,这样的提升意味着从“能用”到“好用”的质变。
更反直觉的是成本:Sonnet + Opus 顾问的组合,任务总成本反而比 Sonnet 单独执行降低了约 12%。
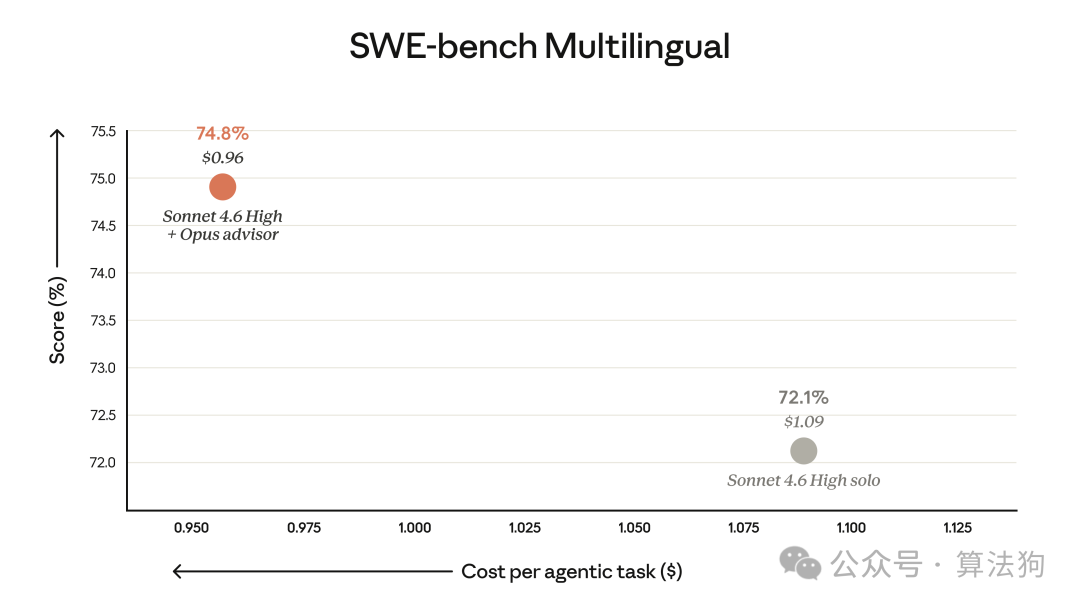
性能对比:Sonnet + Opus 顾问(上图橙点)在取得更高得分的同时,保持了更低的单任务成本。
逻辑在于:Opus 虽然单价高,但它只输出几百个 Token 的关键指导。而 Sonnet 因为有了明确方向,避免了大量试错、死循环和上下文浪费。省下的,正是巨额的“试错成本”。
如果将执行者换成更便宜的 Claude 3.5 Haiku,效果对比更为显著。在 BrowseComp(网页浏览推理)评测中:
- Haiku 单独处理得分仅 19.7%。
- Haiku + Opus 顾问的得分飙升至 41.2%,翻了一倍多。
虽然绝对性能与 Sonnet 仍有差距,但 这套组合的成本比纯用 Sonnet 便宜了 85%。这意味着,以前因预算不敢碰的大规模并发处理场景(如批量情感分析、日志清洗),现在可以用 Haiku 平推,只在遇到硬骨头时才“摇”一下 Opus。

成本效益对比:Haiku 搭配 Opus 顾问后,在 Agentic search 和 terminal coding 任务上性能大幅提升,而成本增幅相对可控。
如何实现?代码示例与实践要点
这个策略现在就能用起来。核心是在调用 Claude API 时,在 tools 参数中声明一个特殊类型的工具:advisor。以下是具体的 Python 代码示例:
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-3-5-sonnet-20241022", # 执行主力:便宜高效的 Sonnet
max_tokens=4096,
tools=[
{
"type": "advisor_20260301", # 关键:声明顾问工具
"name": "ask_expert",
"model": "claude-3-5-opus-20241022", # 顾问模型:更聪明的 Opus
"max_uses": 3, # 最多咨询3次,防止依赖或死循环
},
# 以下是你的业务自定义工具
{
"type": "custom",
"name": "web_search",
# ... 工具定义
}
],
messages=[
{
"role": "user",
"content": "帮我把这个Python脚本里连接数据库的部分改成异步的,顺便看看有没有SQL注入的风险。"
}
]
)
# 查看使用量,注意 `advisor_tokens` 会被单独统计
print(response.usage)
在实际应用中,有两点需要注意:
- 合理设置
max_uses:建议设为 2-3 次。如果 Opus 顾问几次都无法解决问题,那很可能是你的 Prompt 或工具定义本身存在歧义,需要优化。
- 初期关注日志:上线后,查看 Advisor 具体在什么情况下被触发、给出了什么建议。这能帮你发现指令中的模糊之处,进一步优化 Prompt,减少不必要的“摇人”次数。
更深层的启示:从追求“全能模型”到构建“协作系统”
“摇人架构”不仅是一个省钱的技巧,更代表了一种思维转变。过去,我们开发 AIGC 应用时,潜意识里在追求一个“全知全能的硅基大脑”,不断给模型增加负担。
“摇人架构”则指出另一条路:承认不同模型的能力边界,并通过低成本的、按需的协作来跨越这些边界。 这更像高效的人类组织——架构师不去修打印机,实习生也不贸然做技术选型,各司其职,通过精准沟通对齐目标。
未来的 Agent 开发,竞争重点可能不再是单一的基座模型能力,而是如何更巧妙地进行“排兵布阵”,设计模型间的协作机制。这种思路也为解决复杂 后端 系统的智能体设计提供了新视角。
如果你也正在为 Agent 的成本与效能平衡而头疼,不妨试试这个“摇人”的法子。给它配一个“场外指导”,你会发现,不仅任务完成得更顺畅,月底的账单也会变得友好许多。
对这类 人工智能 与工程实践结合的深度内容感兴趣?欢迎在 云栈社区 交流讨论,共同探索技术落地的更多可能性。
 发表于 2026-4-12 00:52:48
|
查看: 191|
回复: 0
发表于 2026-4-12 00:52:48
|
查看: 191|
回复: 0
