什么是分布式自动化测试?
分布式自动化测试 是指将自动化测试任务分发到多个不同的计算节点(可以是物理机、虚拟机或容器)上并行执行,最后再汇总测试结果的过程。
你可以把它想象成两种不同的工作模式:
- 传统方式:就像只有一个工人在一条流水线上,一个一个地顺序执行成千上万个测试用例,耗时极长。
- 分布式方式:一个工头(调度中心)将庞大的任务池拆分成多份,分给一群工人(多个节点)同时干活,从而大大缩短总耗时。
其核心目标在于:缩短测试反馈周期,提升测试执行效率,为实现快速验证和持续交付(CI/CD)提供有力支撑。
分布式自动化测试的应用场景非常广泛,例如多浏览器兼容性测试、跨平台稳定性测试等。它的核心优势在于,可以轻松实现一份自动化测试脚本,驱动部署在不同环境下的多个终端同时执行任务。
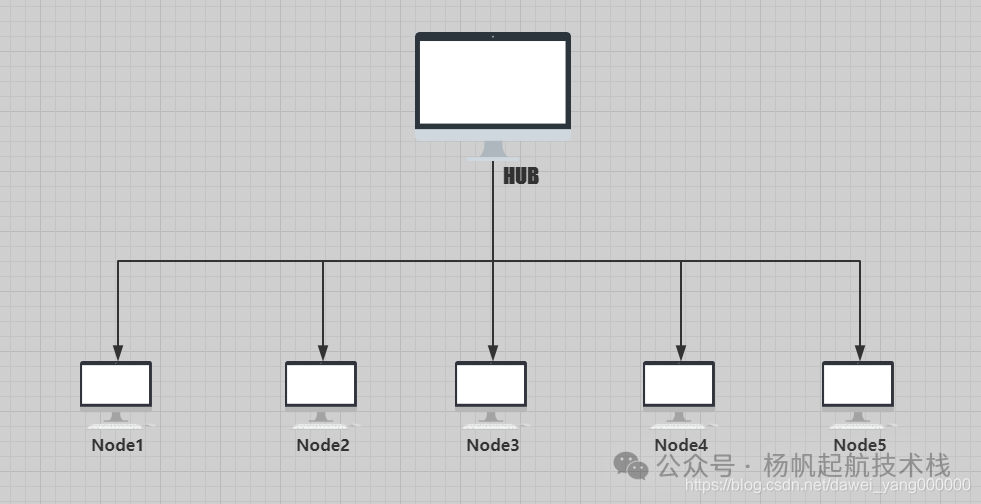
具体来说,在 Selenium Grid 的机制下,我们可以在一台机器(称为 HUB,即调度中心)上执行测试代码,由它来驱动与之关联的多台机器(称为 Node,即工作节点)并行执行相同或不同的测试任务。其基本的星型拓扑结构如下图所示:
环境准备与配置
在开始搭建之前,你需要准备好基础环境。作为技术分享和问题交流的平台,很多开发者会在 云栈社区 的相应板块讨论类似的环境配置问题。
下载与安装 JDK
由于 Selenium Grid 的 selenium-server-standalone 是一个 Jar 包,运行它需要 Java 环境。请确保你的机器上已经安装并配置好了 JDK(Java Development Kit)。具体安装步骤此处省略,你可以根据操作系统版本下载对应的 JDK 并设置好环境变量。
下载 selenium-server-standalone
- 首先,确认你本地用于编写自动化脚本的
Python 环境中 Selenium 库的版本。在命令行中运行:
pip show selenium
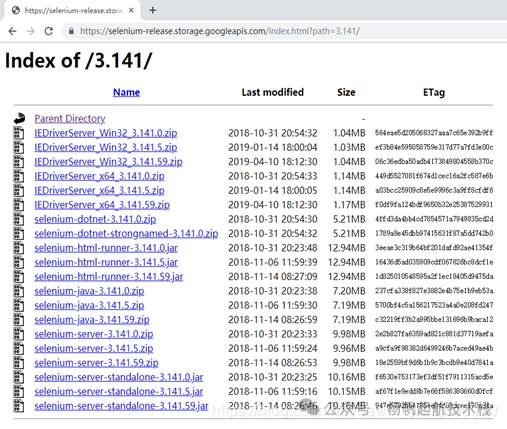
- 根据查看到的 Selenium 版本,前往 Selenium 官方存储库下载对应版本的
selenium-server-standalone Jar 包。下载地址为:https://selenium-release.storage.googleapis.com/index.html 。你需要找到与你本地 Selenium 库版本号匹配的目录(例如 3.141)。
HUB 与 Node 的部署详解
在整个 Selenium Grid 环境中,HUB 机器作为中枢,是所有测试指令的集散地。我们的测试脚本将指令发送给 HUB,再由 HUB 根据策略分发给各个注册的 Node 机器去执行。
启动 HUB (调度中心)
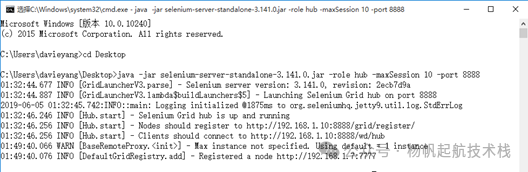
启动命令行终端,切换目录到存放 selenium-server-standalone-3.141.0.jar 的路径下,输入以下命令来启动 HUB:
java -jar selenium-server-standalone-3.141.0.jar -role hub -maxSession 10 -port 8888

命令中几个关键参数的含义:
-role hub:指定当前启动的角色是 HUB。-maxSession 10:设置 HUB 最大并发会话数为 10。-port 8888:指定 HUB 服务运行的端口号。
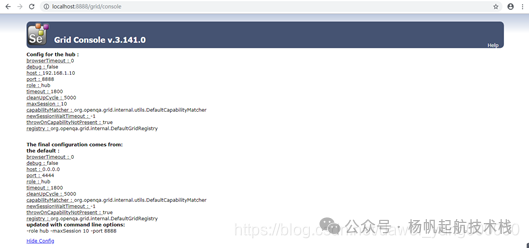
启动成功后,在浏览器中打开地址 http://localhost:8888/grid/console,你将看到 Grid 控制台页面。由于此时还没有任何 Node 注册,页面主要显示 HUB 自身的配置信息。
HUB 端常用启动参数说明
-role hub:启动 HUB。-hubConfig jsonFile:可以将所有参数写入一个 JSON 配置文件,并通过此参数引入,方便管理复杂配置。-port:HUB 监听的端口号。-host:HUB 绑定的 IP 地址。-newSessionWaitTimeout:新测试会话等待执行的最长时间(毫秒),默认 -1 表示无限等待。-browserTimeout:浏览器无响应时的超时时间。
启动 Node (工作节点)
Node 可以是另一台独立的机器,也可以和 HUB 部署在同一台机器上(用于本地多浏览器测试)。如果是另一台机器,它需要配置与 HUB 机器相似的基础环境:安装 Python、Selenium 库、JDK 以及相同版本的 selenium-server-standalone Jar 包。
在实际的分布式场景中,Node 通常是新的机器。在 Node 机器上配置好环境后,启动命令行,进入 Jar 包所在目录,执行以下命令来启动一个支持 Chrome 浏览器的 Node:
java -Dwebdriver.chrome.driver=C:/Python37/chromedriver.exe -jar selenium-server-standalone-3.141.0.jar -role webdriver -hub http://192.168.1.10:8888/grid/register -browser browserName=chrome -port 7777
请注意,这里的 -Dwebdriver.chrome.driver 指定了 ChromeDriver 的路径,-hub 参数指向了 HUB 的注册地址(请将 IP 192.168.1.10 替换为你实际的 HUB 机器 IP)。
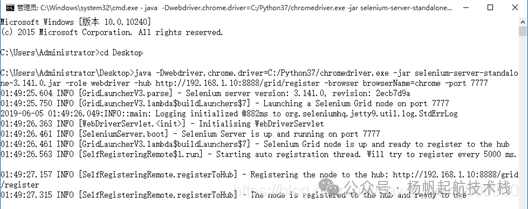
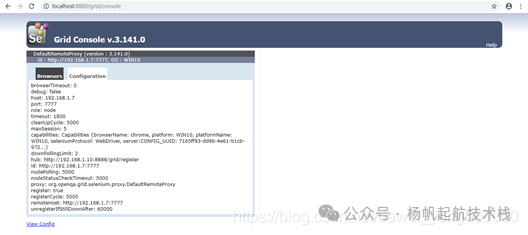
此时,回到 HUB 机器的命令行窗口,你会看到新增了一条 “Registered a node” 的日志信息,表明节点注册成功。
再次刷新 HUB 的控制台页面 http://localhost:8888/grid/console,你会发现页面上新增了刚才注册的 Node 信息。
Node 端常用启动参数说明
-port:Node 端监听的端口号,也是远程连接端口。-role node:支持所有版本的 Selenium(兼容 RC 和 WebDriver)。-role wd 或 -role webdriver:仅支持 WebDriver 协议(Selenium 2+)。-role rc:支持 Selenium 1 (RC) 协议。-timeout:HUB 在无法与 Node 通信时,超过此时间后会释放与该 Node 的连接。-hub:Node 需要连接并注册到的 HUB 地址(URL)。-browser:定义该 Node 提供的浏览器能力,如 browserName, maxInstances 等。-browserTimeout:单个浏览器会话的超时时间。-nodeTimeout:Node 自身的超时时间。-nodeConfig jsonFile:可以将 Node 配置参数写入 JSON 文件,通过此参数引入。
注册更多节点与浏览器
现在,我们尝试在另一台(或同一台)Node 机器上注册一个支持 Firefox 浏览器的节点。执行命令:
java -jar selenium-server-standalone-3.141.0.jar -role node -port 9999 -hub http://192.168.1.10:8888/grid/register -maxSession 5 -browser "browserName=firefox,seleniumProtocol=WebDriver,maxInstances=5"
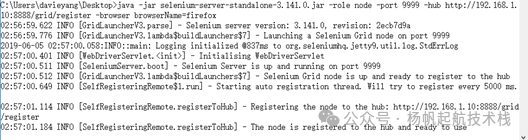
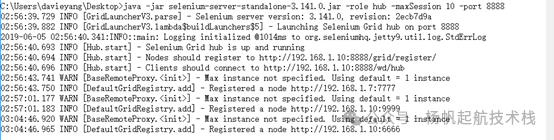
查看 HUB 控制台,日志中又新增了一条注册信息。
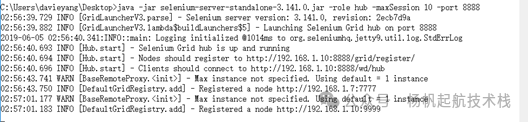
刷新 Grid 控制台页面,可以看到 Firefox 节点的信息也已加入。
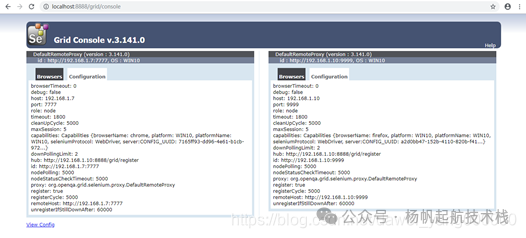
同理,我们可以注册一个支持 IE 浏览器的节点(需要 IEDriverServer):
java -Dwebdriver.ie.driver=C:/Python37/IEDriverServer.exe -jar selenium-server-standalone-3.141.0.jar -role webdriver -hub http://192.168.1.10:8888/grid/register -browser browserName=ie -port 6666
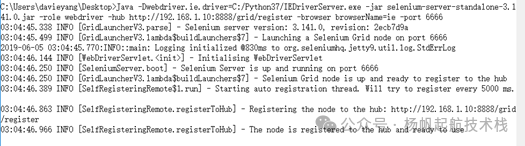
HUB 日志再次更新。
最终,Grid 控制台将展示所有已注册的浏览器节点,便于统一管理和调度。这对于开展全面的自动化测试,尤其是跨浏览器兼容性测试至关重要。
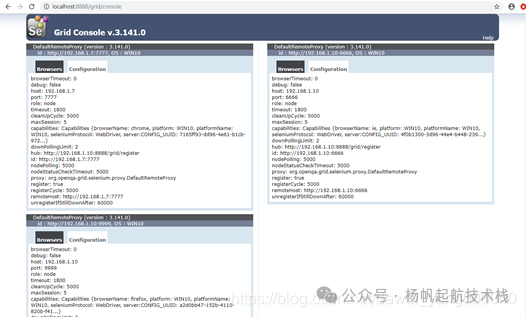
排错提示:无论是在 HUB 端还是 Node 端,如果网络连接或配置出现问题,控制台都会输出相应的错误信息,例如无法连接到 HUB 等,这是诊断问题的重要依据。
编写分布式测试脚本
环境搭建完毕后,我们就可以编写 Python 脚本,指定测试在哪个 Node 上运行了。下面的示例脚本将测试任务发送到我们之前启动的 Chrome Node(端口 7777)上执行。
# coding=utf-8
from selenium import webdriver
# ChromeDriver 的本地路径(在 Node 机器上)
chrome_driver = "C:/Python37/chromedriver.exe"
# 定义所需的能力(Desired Capabilities)
chrome_capabilities = {
# 浏览器名称
"browserName": "chrome",
# 操作系统版本(留空表示任意)
"version": "",
# 平台,可以是 WINDOWS, LINUX, ANY 等
"platform": "ANY",
# 是否启用 JavaScript
"javascriptEnabled": True,
# 指定 chromedriver 路径
"webdriver.chrome.driver": chrome_driver
}
# 关键步骤:使用 Remote 驱动,连接到指定 Node 的地址
driver = webdriver.Remote("http://192.168.1.7:7777/wd/hub", desired_capabilities=chrome_capabilities)
# 后续的自动化操作与本地驱动无异
driver.get("http://www.baidu.com")
print(driver.title)
driver.quit()
当执行此脚本时,HUB 会接收到请求,并将其分配给匹配能力(Chrome 浏览器)且空闲的 Node(这里是 7777 端口的 Node)。你可以在 Node 机器的命令行和 HUB 的控制台中观察到会话创建和执行的详细日志。
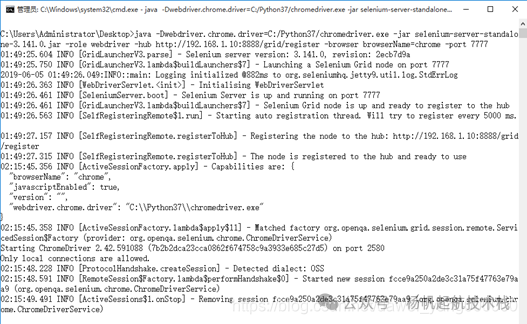
通过这种方式,你可以轻松地将测试用例分发到不同的节点、不同的浏览器上并行执行,从而实现真正意义上的分布式自动化测试,极大提升测试套件的执行效率。
 发表于 2026-2-18 21:02:56
|
查看: 216|
回复: 0
发表于 2026-2-18 21:02:56
|
查看: 216|
回复: 0
