继DeepSeek之后,阿里通义千问团队也带来了重磅更新。2月16日,他们正式发布了Qwen3.5系列的首个开源模型——Qwen3.5-397B-A17B。这个拥有3970亿参数的庞然大物,不仅在架构上采用了创新的混合线性注意力与稀疏MoE(专家混合)设计,更是在推理效率上实现了飞跃,解码吞吐量相较前代Qwen3-Max提升了8.6至19倍。
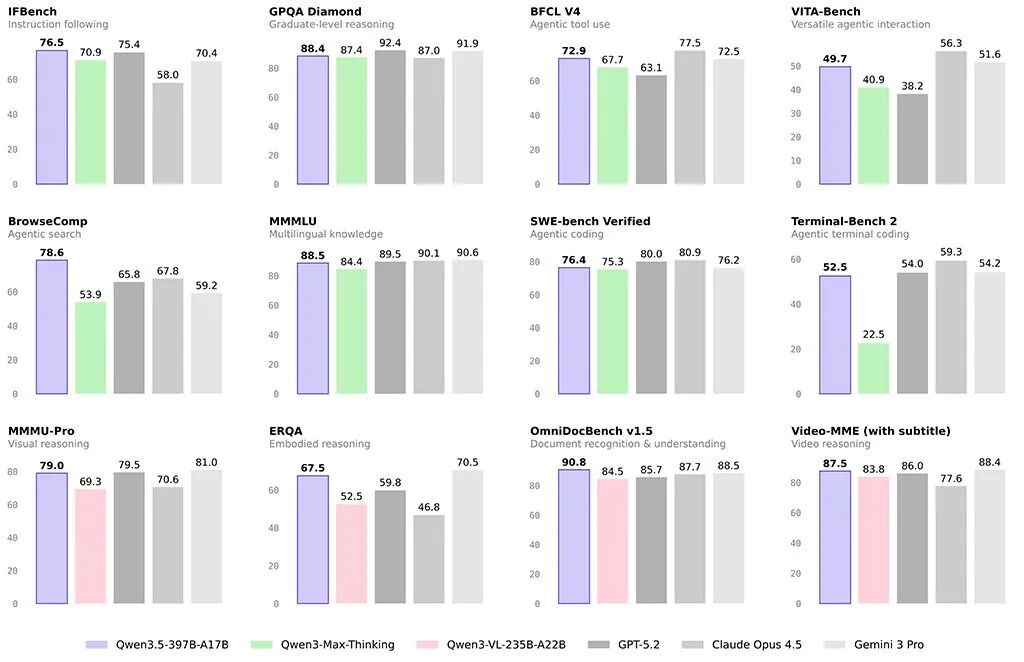
该图展示了Qwen3.5-397B-A17B在IFBench、GPQA Diamond、BFCL V4、MMLU、SWE-bench等12项涵盖指令遵循、推理、编码、视觉理解的核心基准测试中的表现,并与GPT-5.2、Claude Opus 4.5等顶尖闭源模型对比。
技术亮点与核心优势
1. 原生多模态与超高效率
Qwen3.5-397B-A17B原生支持视觉-语言任务,得益于早期融合训练技术,其多模态训练效率已接近纯文本训练。这意味着它无需额外的视觉-语言处理管道,即可直接理解和处理图像与文本的混合输入,在多项视觉理解基准测试中表现优于专精的Qwen3-VL系列。
更引人注目的是其推理效率的巨大提升。模型采用了门控Delta网络与稀疏专家混合架构,结合大规模强化学习进行扩展训练,使得激活参数量从22B优化到了17B。

如图所示,在不同上下文长度下,Qwen3.5-397B-A17B的解码吞吐量分别是Qwen3-Max的8.6倍(32K上下文)和19.0倍(256K上下文),为高并发、长文本应用场景提供了强大支持。
2. 广泛的框架支持与开源协议
模型采用Apache 2.0开源协议,权重已发布在 Hugging Face 和ModelScope平台。它支持通过主流的 Transformers、llama.cpp、MLX 等框架进行本地部署,也可以通过官方的Qwen Chat网页版或阿里云Model Studio的API直接体验。
3. 强大的综合能力
在基准测试中,Qwen3.5-397B-A17B在指令遵循、研究生级推理(GPQA Diamond)、智能体工具使用、代码生成(SWE-bench)等任务上,与GPT-5.2、Claude Opus 4.5、Gemini 3 Pro等顶级闭源模型展开了有力竞争。有开发者测试后反馈,其编程能力甚至在某些方面超过了Gemini 3 Pro。此外,模型支持多达201种语言和方言,展现了卓越的多语言理解和生成能力,这对于构建全球化的AI应用至关重要。
快速部署与配置指南
vLLM项目团队在模型发布后迅速提供了完善的技术支持。以下是通过vLLM部署Qwen3.5-397B-A17B的几种方式。
环境准备与安装
首先,建议创建一个干净的Python虚拟环境并安装vLLM。
# 创建虚拟环境
uv venv
source .venv/bin/activate
# 安装vLLM (推荐使用uv或pip)
uv pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
Docker一键部署
对于追求部署便捷性的用户,可以使用官方提供的Docker镜像。
docker run --gpus all \
-p 8000:8000 \
--ipc=host \
-v ~/.cache/huggingface:/root/.cache/huggingface \
vllm/vllm-openai:qwen3_5 Qwen/Qwen3.5-397B-A17B \
--tensor-parallel-size 8 \
--reasoning-parser qwen3 \
--enable-prefix-caching
针对不同场景的优化配置
根据你的应用需求,可以调整启动参数以获得最佳性能。
1. 纯文本高吞吐场景
适用于文档摘要、批量内容生成等任务,跳过视觉编码器以节省显存。
vllm serve Qwen/Qwen3.5-397B-A17B \
--tensor-parallel-size 8 \
--language-model-only \
--reasoning-parser qwen3 \
--enable-prefix-caching
2. 多模态工作负载
支持图像描述、视觉问答等需要处理图片的任务,采用数据并行优化多模态编码器。
vllm serve Qwen/Qwen3.5-397B-A17B \
--tensor-parallel-size 8 \
--mm-encoder-tp-mode data \
--mm-processor-cache-type shm \
--reasoning-parser qwen3 \
--enable-prefix-caching
3. 低延迟交互场景
启用MTP-1投机解码,适合聊天机器人、实时助手等对响应速度要求高的应用。
vllm serve Qwen/Qwen3.5-397B-A17B \
--tensor-parallel-size 8 \
--speculative-config '{"method": "mtp", "num_speculative_tokens": 1}' \
--reasoning-parser qwen3
4. 多节点分布式部署
针对GB200等高端硬件集群,可以进行多节点部署以承载更大规模的服务。
主节点配置:
vllm serve Qwen/Qwen3.5-397B-A17B \
--tensor-parallel-size 8 \
--reasoning-parser qwen3 \
--enable-prefix-caching \
--attention-backend FLASH_ATTN \
--nnodes 2 \
--node-rank 0 \
--master-addr <head_node_ip>
工作节点配置:
vllm serve Qwen/Qwen3.5-397B-A17B \
--tensor-parallel-size 8 \
--reasoning-parser qwen3 \
--enable-prefix-caching \
--attention-backend FLASH_ATTN \
--nnodes 2 \
--node-rank 1 \
--master-addr <head_node_ip> \
--headless
其他部署框架
除了vLLM,你也可以选择其他熟悉的框架。
使用 Transformers 直接部署:
# 启动推理服务
transformers serve --port 8000 --continuous-batching
# 或进行命令行交互
transformers chat Qwen/Qwen3.5-397B-A17B
使用 SGLang 部署:
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--port 8000 \
--tp-size 8 \
--context-length 262144 \
--reasoning-parser qwen3
社区反馈与未来展望
模型发布后,开发者社区反响热烈。有开发者关心是否有更小参数(如2B)的版本推出,以降低部署门槛。同时,尽管激活参数从22B降到了17B,但具体的硬件需求(如最低显存)官方尚未详细公布,这成为了许多想进行本地尝试的用户最关心的问题。好消息是,Unsloth AI团队已经发布了GGUF量化版本,方便用户在消费级硬件上运行体验。
此次Qwen3.5-397B的发布,不仅在性能上向顶级闭源模型看齐,其开源的属性、极高的推理效率和原生多模态能力,为AI应用开发者提供了新的强大选择。开源模型在多语言、编程等任务上的持续突破,正在悄然改变由闭源模型主导的市场格局。对于希望深入研究大模型技术、或需要定制化私有部署的企业和开发者来说,这无疑是一个值得深入探索的优质开源实战项目。
相关资源链接
如果你想了解更多关于大模型Transformer架构、性能优化或部署实践的深度技术文档,欢迎持续关注云栈社区的技术动态与分享。
 发表于 2026-2-18 21:25:56
|
查看: 334|
回复: 0
发表于 2026-2-18 21:25:56
|
查看: 334|
回复: 0
