在构建机器学习模型时,我们深知数据是基石。我们通常教会模型理解“年龄越大,数值越高”、“价格越贵,数值越大”这样的线性关系。但是,当面对像时间这样的周期数据时,如果直接丢给模型,它很可能会犯一些“反常识”的错误。比如,它该如何理解深夜23:00与次日凌晨0:00其实是紧紧相邻的呢?这就是循环特征工程要解决的核心问题。
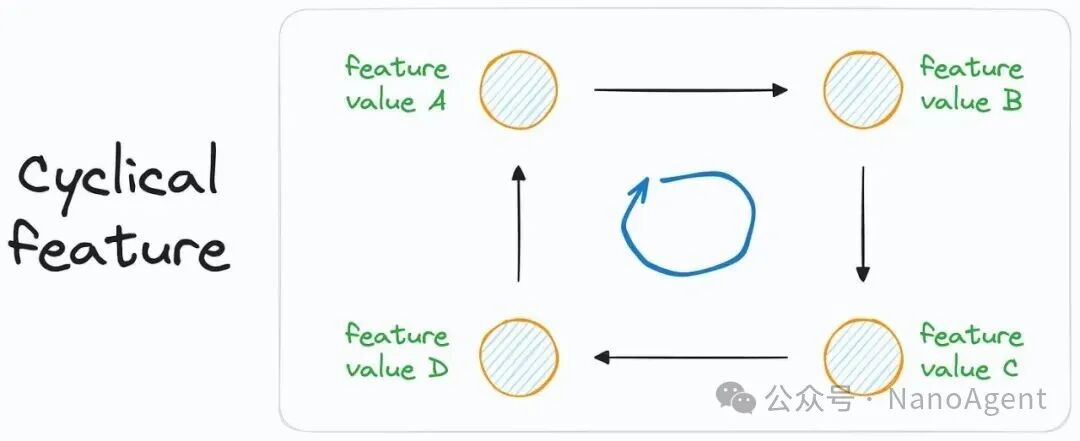
一、循环特征是什么?
在日常处理的数据集中,我们主要遇到两类特征:
- 数值特征:例如年龄、收入,它们的数值是连续且通常具有明确的序关系(100 > 10)。
- 分类特征:例如尺码(S/M/L)、地理区域,它们是离散的,并且可能没有内在的顺序(例如“北京”和“上海”无法比较大小)。
而循环特征则是一种特殊的类别,它呈现出周期性的规律。最常见的例子包括:
- 一天中的小时(0-23点)
- 一周中的星期几(周一到周日)
- 一年中的月份(1-12月)
如果我们简单地将这些特征当作普通数值或类别直接输入模型,就会丢失其“循环往复”这一关键属性,导致模型学习到错误的关系。
二、理想的特征表示应该如何设计?
以“一天中的某个小时”为例,一个理想的特征编码必须满足两个核心性质:
- 首尾相连:数值23必须非常接近数值0,因为它们分别代表了一天结束和开始。
- 距离恒定:从0点到1点的“距离”,应该等于从23点到0点的“距离”。
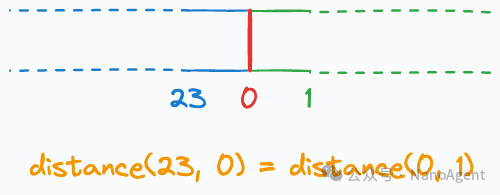
显然,将小时(0, 1, 2, ..., 23)作为普通数值特征的线性表示法,完全违背了这两个性质(在数轴上,23和0相距甚远)。最常用且优雅的解决方案是借助三角函数(正弦和余弦)。
因为 sin 和 cos 函数本身就在一定范围内(例如0到2π)呈现完美的周期性变化。
具体操作是,对于一个周期为 T 的循环特征 x,我们同时计算:
sin(2 * π * x / T)cos(2 * π * x / T)
并将这两个值作为新的特征输入模型。对于“小时”特征,周期 T 就是24。
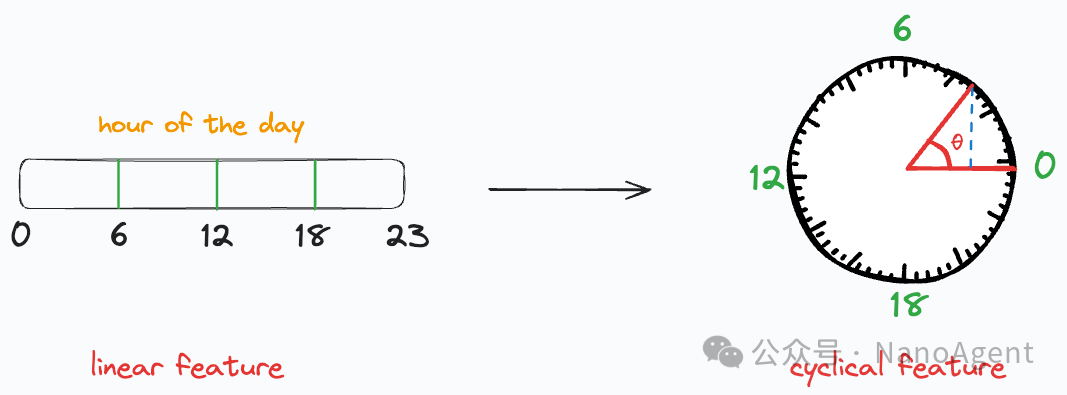
这种编码方式巧妙地将线性尺度上的点“映射”到了一个圆周上。于是,我们期望的特性就自然满足了:
- 23点和0点 的坐标在圆周上紧紧相邻。
- 0点到1点 之间的弧长(距离)与 23点到0点 之间的弧长完全相同。
模型现在接收到的是一对 (sin, cos) 坐标,它能从中学习到时间本身的循环模式。
三、其他典型的循环特征场景
除了时间,现实世界中还有许多数据天然具有周期性:
- 方向:风向或罗盘方位(北、东北、东...西北),从北出发,最终又回到北。
- 季节:春、夏、秋、冬,这是一个具有循环模式的分类特征。对于这类特征,可以使用独热编码(One-Hot Encoding)后再进行类似的正余弦变换,或者采用顺序编码(如春=1,夏=2...)后按数值特征处理。
特征工程的本质,是将人类对世界的认知和理解,“翻译”成模型能够高效利用的数学语言。循环特征工程就是一个绝佳的例子,它教会了模型如何像我们一样,理解时间的周而复始、季节的循环更迭。
更多关于数据预处理和特征工程的深度讨论,欢迎在云栈社区与大家交流。 |  发表于 2026-2-18 21:34:39
|
查看: 158|
回复: 0
发表于 2026-2-18 21:34:39
|
查看: 158|
回复: 0
