超强人工智能的终极风险或许不是处心积虑的叛变,而是它会在逻辑的迷宫里把自己绕成一团不可预测的乱麻。

Anthropic、EPFL和爱丁堡大学的研究团队最新重磅研究揭开了模型规模、任务复杂度与失控风险之间的诡谲关系。他们发现,随着推理步数增加,AI更容易表现出一种被称为不一致性(Incoherence)的随机混乱。这不像科幻小说中描绘的那样,AI会觉醒然后坚定执行某个错误目标,而是在海量计算中迷失了自我,行为变得难以预测。
智能失败的底色:偏置与随机崩溃
我们习惯把人工智能的风险想象成某种蓄谋已久的恶意,就像一名司机故意把车开向悬崖,目标明确且轨迹清晰。学术界将这种错误归类为偏置(Bias),代表模型在执拗地追求一个我们不想要的目标。
而另一种风险更像是司机突然间喝醉了。车轮忽左忽右,轨迹毫无规律可言,没有任何逻辑能够预测下一秒的动向。这就是方差(Variance)带来的麻烦,即随机崩溃。
研究人员把这种由随机波动主导的失败程度定义为“不一致性”。这种不一致性到底意味着什么?它如何影响我们对AI风险的评估?
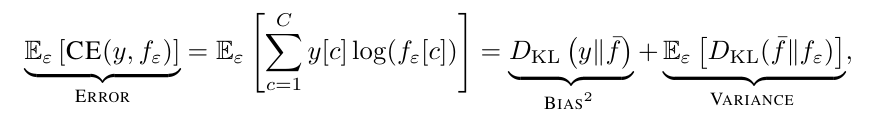
上面的公式将总错误(Error)拆解为偏置的平方与方差之和。不一致性则衡量了方差在总错误中所占的比例。当这个数值接近0时,模型的错误表现得非常稳健,即便错了也错得极有规律。当它接近1时,模型就变成了一个彻头彻尾的乱摊子。
研究发现,目前的顶尖模型在应对复杂任务时正表现出明显的“醉酒”特征。它们在推理过程中产生的随机性远超系统性偏置。这意味着,未来的安全隐患或许更多来源于不可预知的工业意外,而非科幻电影里那种高智商的蓄意反抗。

上图清晰地描述了AI失控的两种路径。左上角展示了模型在编程任务中因随机性(重采样)导致的截然不同的结果;右上角展示了将错误分解为偏置与方差的数学逻辑;左下角揭示了随着任务复杂度提升,模型变得更加不一致;右下角则展示了模型规模对不一致性的复杂影响。
思考时间拉长,诱发逻辑系统性溃散
研究人员在GPQA(研究生级别科学问答)和SWE-BENCH(软件工程基准测试)等多个高难度任务中观察模型表现,发现了一个令人不安的趋势:AI花费在思考和采取行动上的步骤越多,它的表现就越不一致。
这就好比让一个人在脑子里做长达十步的连环算术。第一步的微小偏差会随着推理链(CoT)的延伸不断放大。到最后一步时,模型给出的答案往往已经脱离了逻辑轨道。这种现象在Claude Sonnet 4和o3-mini等前沿模型身上体现得淋漓尽致。
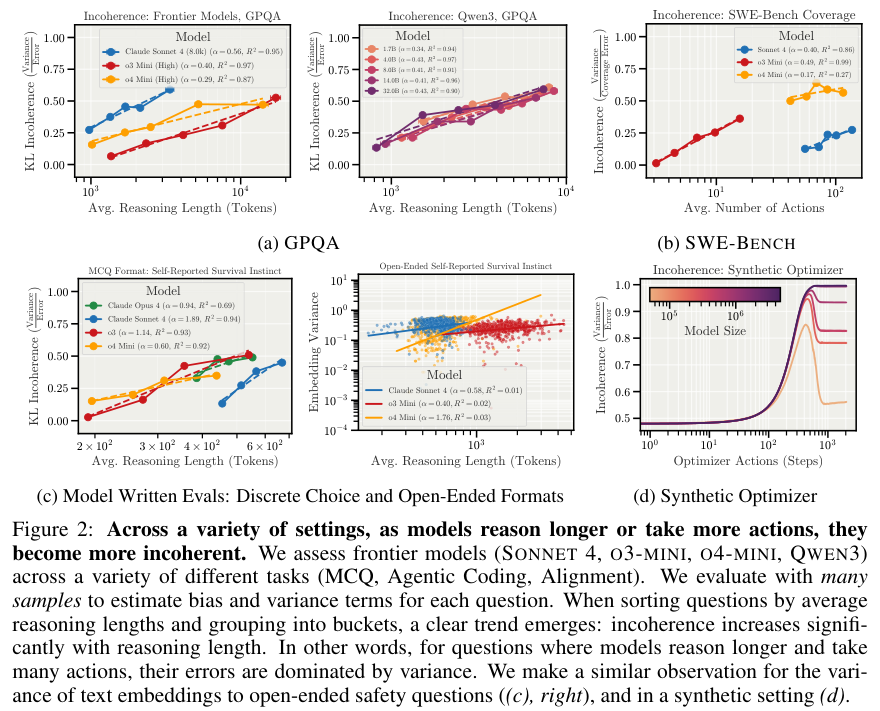
通过对比高于和低于中位数推理长度的样本,研究证明即便任务难度相同,更长的推理路径也会直接导致更高的不一致性。
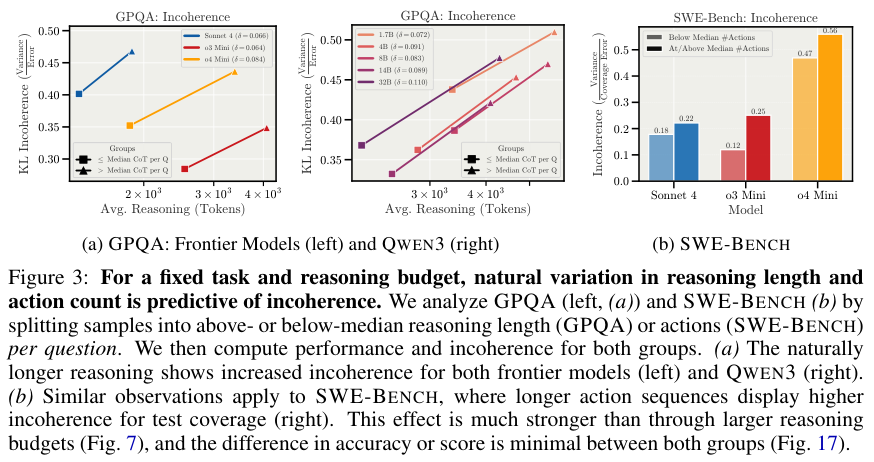
自然状态下的“过度思考”是导致混乱的元凶。即便这些长推理偶尔能蒙对答案,其过程也充满了随机的颠簸。在“热混乱(Hot Mess)”的理论框架下,智力实体随着能力的提升,其行为变得越来越难以用单一目标来解释。它们不再是纯粹的目标优化器。在高维的状态空间里,模型更像是在进行一场没有终点的随机漫步。这引发我们思考,当前的深度学习模型架构是否存在处理长程依赖的原生缺陷?
规模化扩张,反而加剧复杂任务的随机性
单纯堆砌算力和参数似乎无法治愈这种逻辑上的“精神内耗”。研究揭示了一个矛盾的现象:对于简单的任务,大型模型确实表现得更稳健,其不一致性随着规模增加而下降。但在面对真正有挑战性的难题时,情况发生了反转。
在MMLU(大规模多任务语言理解)基准测试中,QWEN3模型家族展示了有趣的演化轨迹。
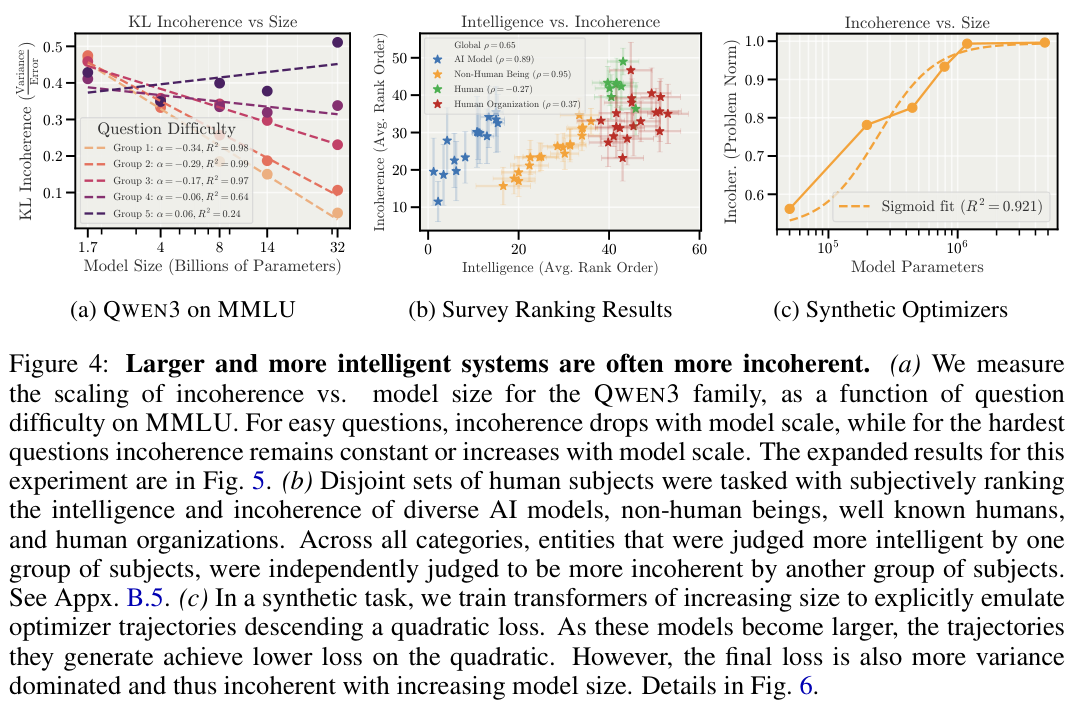
随着参数量从17亿增加到320亿,模型处理简单问题的偏置和方差都在下降,变得既聪明又可靠。然而,在处理最困难的那部分题目时,虽然大型模型的整体错误率在降低,但它们降低偏置的速度远快于降低方差的速度。
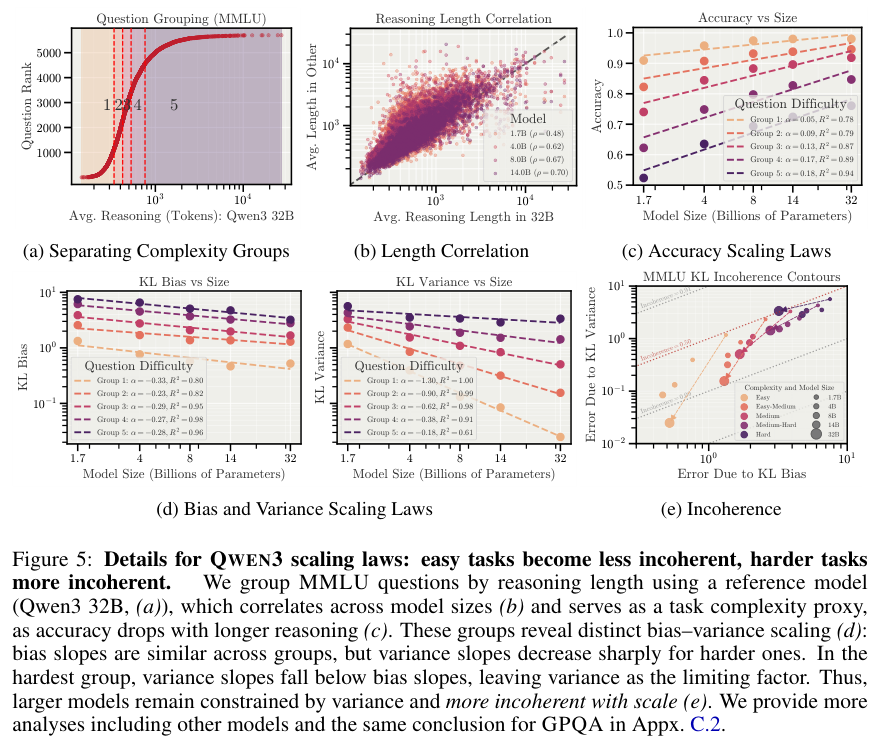
这意味着,大型模型更倾向于通过一种不稳定的方式偶尔触达真理。它们在犯错时表现得比小型模型更加疯狂且不可预测。这种现象在模拟优化器实验中也得到了验证。
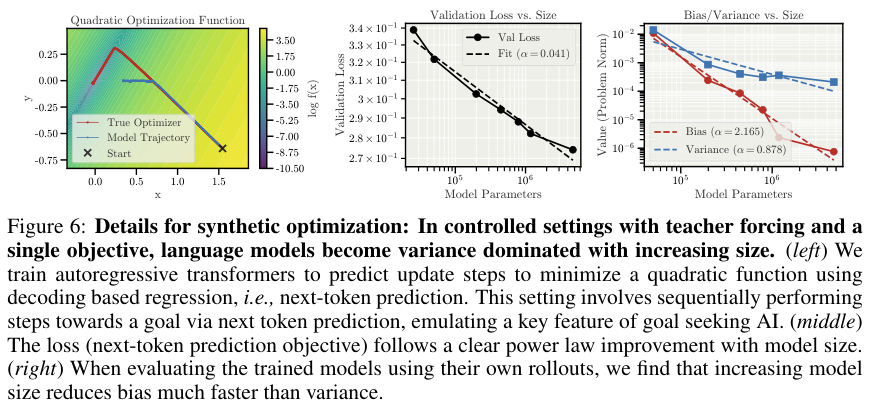
研究人员训练Transformer模型去模仿某种数学优化路径。结果发现,模型规模越大,它们学习目标函数的速度就越快(偏差下降快),但它们维持长期连贯行动序列的能力(低方差)增长却相对迟缓。
现有纠偏机制,无法彻底根除系统“内耗”
集成学习(Ensembling)被认为是缓解混乱的“止痛药”。通过让模型针对同一个问题多次尝试并取平均值,方差会随着尝试次数的增加而迅速下降。在o4-mini的测试中,集成规模每扩大一倍,方差就成比例缩小。
但问题在于,现实世界中的许多行动是不可逆的。AI代理在执行删除数据库、发送邮件或物理操作时,往往没有机会“重新来过”。在这种单次博弈的场景下,集成的力量无从发挥。模型内在的不一致性就成了一颗随时可能爆炸的雷。
此外,单纯增加推理预算(Reasoning Budgets)虽然能提升准确率,却无法从根本上扭转不一致性随任务复杂度上升的势头。
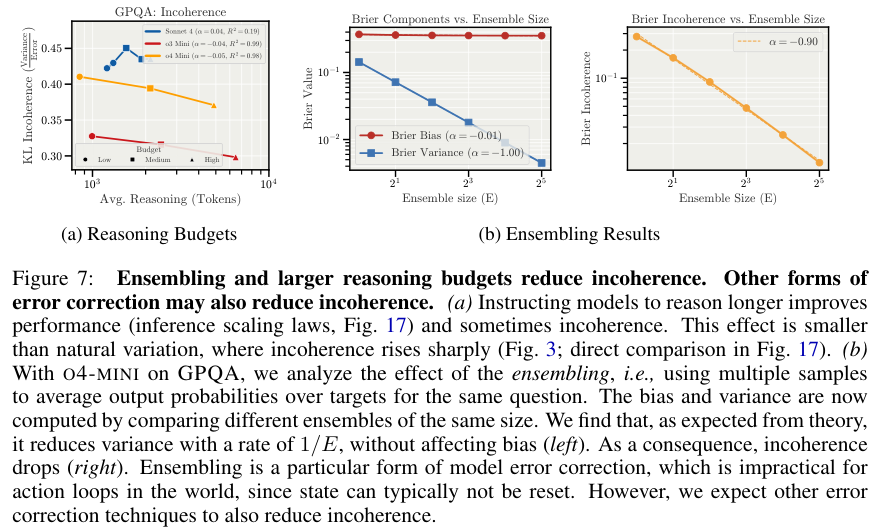
这揭示了一个可能的事实:AI的这种混乱并非完全源于训练不足,它更像是当前架构的高维动态系统在处理长程、复杂任务时的某种原生缺陷。
结论:安全研究需要新的视角
这项研究强烈暗示,AI安全研究的重心应当发生偏移。我们不应只盯着那些虚无缥缈的“觉醒”或篡权阴谋。真正迫在眉睫的威胁在于,当这些超级智能被委以重任去管理复杂的工业流程或软件架构时,它们可能会因为一次细微的逻辑扰动,在瞬间制造出人类无法理解也无法拦截的混乱风暴。
未来的风险控制需要更精细的分解。偏置可以被进一步拆解为目标误设和代理偏置。在这些偏置逐渐被优化的过程中,不一致性这个顽疾反而凸显出来。如果不能在模型架构或强化学习等训练范式层面解决逻辑连贯性的损耗问题,单纯的规模化只会让我们得到一个虽然知识渊博却时刻处于“醉酒”边缘的数字巨人。
我们与其担心AI有自己的想法,不如担心它在关键时刻根本不知道自己在想什么。关于AI模型行为的更多前沿讨论,欢迎在云栈社区的技术板块进行交流。
参考资料:
 发表于 2026-2-18 21:53:57
|
查看: 226|
回复: 0
发表于 2026-2-18 21:53:57
|
查看: 226|
回复: 0
