你是否曾遇到过这样的困惑:搭建好了复杂的深度学习模型,满心期待地开始训练,却发现模型损失迟迟不降,或者训练过程直接崩溃?如果排除数据和模型结构的问题,那么“元凶”很可能藏在最容易被忽视的一步——模型初始化。
很多人认为初始化只是随便给参数一个起点,无关紧要。但恰恰相反,一个糟糕的初始化方案,可能会让模型从一开始就陷入“梯度消失”或“梯度爆炸”的泥潭,无论后续的优化算法多强大,都无力回天。本文将通过具体示例,为你彻底揭开模型初始化与数值稳定性的内在联系,并介绍如何通过巧妙的初始化策略来规避这些问题。
核心困境:消失与爆炸的梯度
深度神经网络的训练依赖于反向传播算法,其本质是链式法则的连乘。当一个网络有L层时,输出对某一层参数的梯度,是L-1个矩阵与一个向量的乘积。这种连乘结构,正是数值不稳定的根源。
示例一:直观感受衰减与爆炸
让我们先抛开复杂的公式,用一个简单的标量例子来直观感受。
假设一个30层的网络,每层只有一个权重参数,且激活函数是简单的恒等映射(即输入=输出)。
- 衰减: 如果每层的权重都是0.2,那么输入信号 x 经过30层后,会变成 x * (0.2)^30。计算一下, (0.2)^30 约等于 1.07e-21。这是一个极其接近0的数,意味着信号几乎完全消失。反映在梯度上,就是梯度消失,参数更新微乎其微,模型无法学习。
- 爆炸: 如果每层的权重都是5,那么经过30层后,输出变为 x * (5)^30。 (5)^30 约等于 9.3e+20,这是一个天文数字。这会导致梯度爆炸,参数更新步长过大,模型无法收敛,甚至导致数值溢出(变成NaN)。
这个简单的例子告诉我们,当网络层数加深时,连乘效应会急剧放大微小的初始差异,导致输出要么趋近于0,要么趋向无穷大。
示例二:杀手锏——Sigmoid函数与梯度消失
在深度学习早期,Sigmoid函数因其光滑的S型曲线和概率解释而备受青睐。但它在实践中却是一个导致梯度消失的“经典元凶”。
让我们看看Sigmoid函数的曲线:
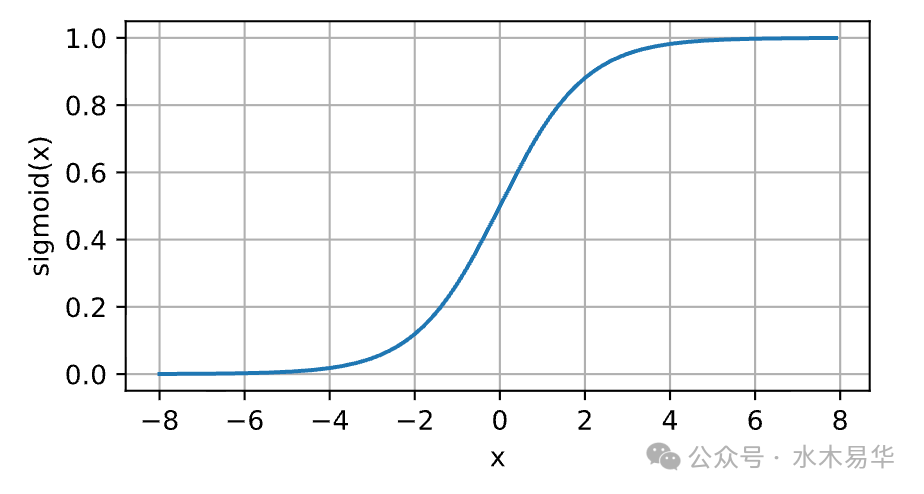
Sigmoid函数的梯度曲线:
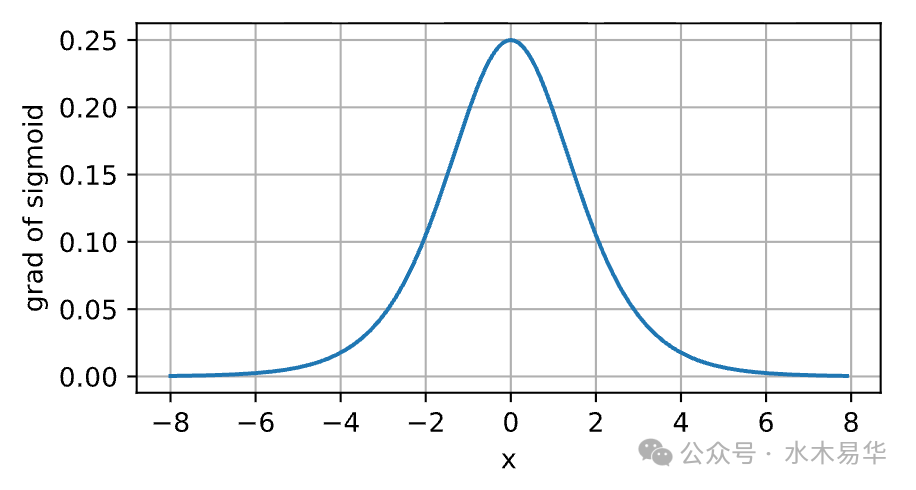
从上图可以清晰地看到:
- 当输入x非常大或非常小时,Sigmoid函数的梯度(即导数)趋近于0。
- 在深层网络中,反向传播的梯度是多层梯度的连乘。只要其中几层的Sigmoid输入落在饱和区(即x过大或过小),连乘后的总梯度就会迅速趋近于0,导致“梯度切断”,前面的层几乎无法得到有效的训练。
这也是为什么如今更稳定的ReLU系列函数成为从业者的默认选择。
示例三:代码复现梯度爆炸
理论说千遍,不如代码跑一遍。下面这段PyTorch代码直观地展示了梯度爆炸的威力。我们随机生成一个4x4的矩阵,然后让它与100个同样分布的随机矩阵连续相乘。
import torch
M = torch.normal(0, 1, size=(4,4))
print('一个初始矩阵\n', M)
for i in range(100):
M = torch.mm(M, torch.normal(0, 1, size=(4,4)))
print('乘以100个矩阵后\n', M)
输出结果令人震惊:
一个初始矩阵
tensor([[-0.4430, 1.8467, 1.2274, 0.2537],
[ 1.6749, -1.5996, 0.6402, 0.1141],
[-0.1859, -0.4506, 2.5819, -1.3329],
[ 2.7346, 0.1642, -0.6078, -0.0507]])
乘以100个矩阵后
tensor([[ 6.9875e+23, 5.5570e+23, 7.6843e+23, -1.9781e+23],
[-6.3054e+23, -5.0146e+23, -6.9342e+23, 1.7850e+23],
[ 6.4354e+23, 5.1180e+23, 7.0772e+23, -1.8218e+23],
[-1.1732e+24, -9.3301e+23, -1.2902e+24, 3.3212e+23]])
矩阵中的元素从最初的一位数爆炸到了 10^23 量级。如果这种情况发生在深度网络的反向传播中,优化器根本无法收敛。
破局之路:巧妙的参数初始化
既然问题是初始化引起的,解决方案自然也从初始化入手。一个良好的初始化方案,需要达到两个核心目标:
- 打破对称性: 让不同神经元学到不同的特征。
- 保持数据流通量: 让每一层的输出和梯度都保持在一个合适的尺度范围内,既不消失也不爆炸。
破局第一步:打破对称性——为何不能全部初始化为0?
一个常见的误区是,将所有权重都初始化为0或同一个常数 c。
想象一个有两层隐藏单元的简单网络。如果我们将第一层所有权重 W^(1) 都初始化为常数 c:
- 前向传播: 由于输入和权重完全相同,两个隐藏单元会计算出完全相同的激活值。
- 反向传播: 基于相同的激活值,反向传播计算出的梯度也完全相同。
- 参数更新: 使用梯度下降法更新后,W^(1) 的所有参数仍然保持相等。
这样一来,无论隐藏层有多少个单元,它们的行为都完全一致,相当于只有一个隐藏单元在工作,网络失去了其强大的表达能力。因此,必须使用随机初始化来打破这种对称性。
破局第二步:Xavier初始化——黄金折中方案
仅仅随机还不够,随机数的“尺度”也至关重要。如果方差过大,可能导致梯度爆炸;方差过小,又可能导致梯度消失。
Xavier初始化(又称Glorot初始化)是一个被广泛应用的经典方案,它的核心思想是在前向和反向传播中,尽可能地保持信号方差不变。
其背后的推导思路如下:
- 前向传播: 为了保持某一层输出的方差与输入方差一致,权重的方差 Var(W) 应满足 Var(W) = 1 / n_in,其中 n_in 是输入维度。
- 反向传播: 为了保持梯度反向传播时的方差稳定,权重的方差 Var(W) 又应满足 Var(W) = 1 / n_out,其中 n_out 是输出维度。
这两个条件显然无法同时满足。Xavier初始化做了一个聪明的折中:取两者的调和平均。最终得出权重的方差应为:
[
Var(W) = \frac{2}{n{in} + n{out}}
]
在实践中,通常从一个均值为0、方差为 2 / (n_in + n_out) 的高斯分布或均匀分布中采样权重。尽管推导中忽略了非线性激活函数,但Xavier初始化在实践中被证明非常有效,尤其是在使用tanh等对称型激活函数时。
总结与建议
模型初始化绝非微不足道的小事,它是决定深度学习模型能否成功训练的基石。回顾我们的探索之旅:
警惕陷阱: 深度网络的连乘结构天然地存在梯度消失和梯度爆炸的风险。Sigmoid等激活函数会加剧梯度消失。
打破对称: 永远不要将所有权重初始化为同一个值(如0),必须使用随机初始化,让每个神经元都有机会学习不同的特征。
控制尺度: 随机初始化的尺度至关重要。Xavier初始化通过平衡前向和反向传播的方差,提供了一个强大而通用的默认选择。
联合优化: 初始化方案与激活函数的选择紧密相连。搭配使用ReLU等现代激活函数时,还有如He初始化等更适合的变种方案。
理解这些底层原理,能帮助你在模型训练遇到问题时,快速定位瓶颈所在,而不仅仅是盲目调参。如果你想深入探讨更多模型训练的技巧或交流实践经验,云栈社区 是一个不错的去处,那里聚集了不少对技术细节有深入研究的开发者。
 发表于 2026-2-19 01:33:19
|
查看: 235|
回复: 0
发表于 2026-2-19 01:33:19
|
查看: 235|
回复: 0
