本系列介绍增强现代智能体系统可靠性的设计模式,以直观方式逐一介绍每个概念,拆解其目的,然后实现简单可行的版本,演示其如何融入现实世界的智能体系统。本系列一共 14 篇文章,这是第 10 篇。原文:Building the 14 Key Pillars of Agentic AI[^1]。
构建健壮的智能体解决方案,离不开软件工程思维的支撑。我们需要确保各个组件能够协调一致地工作,并行运行,并与整个系统高效交互。例如,预测执行[^2]会尝试预处理可预测的查询,核心目标在于降低系统延迟;而冗余执行[^3]则是让同一智能体任务重复运行多次,以防止单点故障,提升鲁棒性。除了这些,还有许多其他能显著增强现代智能体系统可靠性的经典设计模式。
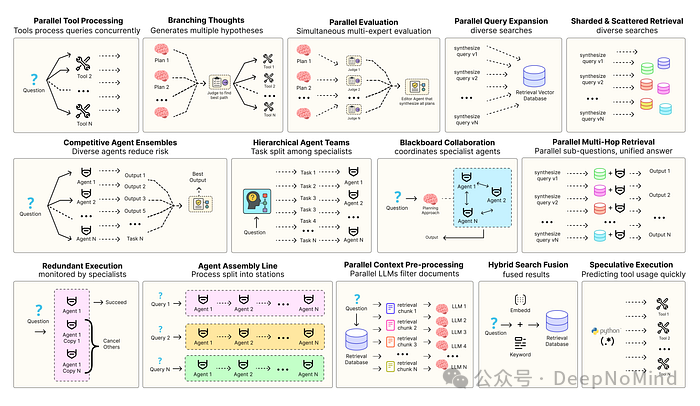
- 并行工具调用:智能体同时执行独立的 API 调用,利用并发隐藏 I/O 等待时间。
- 层级智能体团队:管理智能体将复杂任务分解为若干小步骤,交由不同的执行智能体处理。
- 竞争性智能体组合:让多个智能体针对同一问题提出答案,系统从中选择最优解。
- 冗余执行:让两个或多个智能体解决同一任务,用于错误检测和可靠性提升。
- 并行检索与混合检索:多种检索策略协同运行,旨在提升上下文信息的质量。
- 多跳检索:智能体通过迭代的检索步骤,逐步收集更深层次、更相关的信息。
当然,模式远不止这些。本系列的目标是深入这些最常用智能体模式背后的基础概念,用直观的方式逐一介绍,拆解其设计目的,然后通过实现简单可行的版本来演示它们如何融入现实世界的智能体系统。
所有的理论阐述和示例代码都汇集在以下 GitHub 仓库中:🤖 Agentic Parallelism: A Practical Guide 🚀[^4]
代码库的组织结构如下:
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb
并行查询扩展以最大化召回率
在自主式 RAG(检索增强生成)系统中,一个最常见的问题是“词汇不匹配”。用户通常不了解专业知识库中使用的精确技术术语或关键词。
一个简单的用户查询,例如“如何使模型更大更快”,很可能无法直接检索到包含“混合专家(Mixture of Experts)”和“快速注意力(FlashAttention)”等专业术语的相关文档。这就是简单RAG的瓶颈所在。
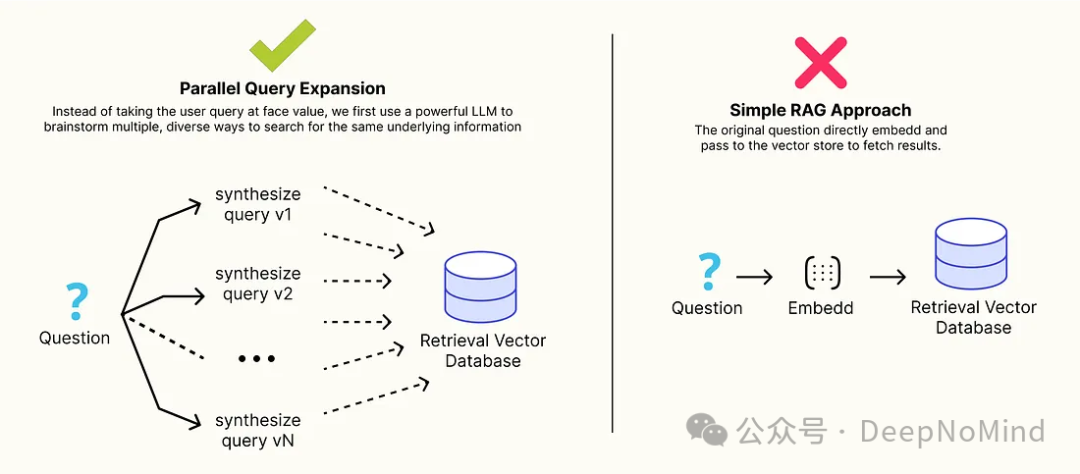
并行查询扩展(Parallel Query Expansion) 正是为解决这一痛点而生的架构解决方案。其核心思想在于:不直接使用用户输入的原生查询,而是首先利用一个大语言模型(LLM)来构思多种类、多样化的搜索方式,目标是获取相同的底层信息。这个“预检索”步骤可以并行生成一系列搜索查询,例如:
- 一份能回答该问题的假设性文档(HyDE,Hypothetical Document)。
- 将原问题分解出的若干子问题。
- 一组从问题中提取的关键词和实体。
通过并行执行所有这些生成的查询并融合结果,可以显著提高检索步骤的召回率。不同角度的查询术语确保了我们能够“撒下一张更大的网”,找到所有相关的证据片段。
接下来,我们将动手构建一个基于这种模式的系统,并与一个简单的RAG系统进行对比,以证明它所产生的最终答案确实更加完整和准确。
首先,我们定义一个 Pydantic 模型来结构化查询扩展的输出。这能让 LLM 在一次可靠的调用中,生成所有我们期望的查询变体。
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
class ExpandedQueries(BaseModel):
"""Pydantic 模型定义了一组不同的扩展查询,以提高检索召回率"""
# 生成的假设文档段落,在语义上与可能的答案相似
hypothetical_document: str = Field(description="A generated, paragraph-length hypothetical document that directly answers the user's question, which will be used for semantic search.", alias="hyde_query")
# 将原始查询分解为更小、更具体的问题列表
sub_questions: List[str] = Field(description="A list of 2-3 smaller, more specific questions that break down the original query.")
# 用于精确词法搜索的核心关键字和实体列表
keywords: List[str] = Field(description="A list of 3-5 core keywords and entities extracted from the user's query.")
通过指示 LLM 填充这个结构化的对象,我们就能确保获得一个多样化的搜索策略组合。它同时包含了语义策略(hypothetical_document)、分解策略(sub_questions)和词汇策略(keywords),而这一切都来自一次高效的 LLM 调用。
接下来,我们构建一个 LangGraph 工作流。第一个节点就是我们的查询扩展代理。
from typing import TypedDict, List, Optional
from langchain_core.documents import Document
class RAGGraphState(TypedDict):
original_question: str
expanded_queries: Optional[ExpandedQueries]
retrieved_docs: List[Document]
final_answer: str
# 节点 1: 查询扩展代理
query_expansion_prompt = ChatPromptTemplate.from_messages([
("system", "You are a query expansion specialist. Your goal is to transform a user's question into a diverse set of search queries to maximize retrieval recall. Generate a hypothetical document, sub-questions, and keywords."),
("human", "Please expand the following question: {question}")
])
# 该链将提示符通过管道链接到 LLM,并基于 Pydantic 模型构建其输出
query_expansion_chain = query_expansion_prompt | llm.with_structured_output(ExpandedQueries)
def query_expansion_node(state: RAGGraphState):
"""图中的第一个节点:获取原始问题并生成一组扩展查询"""
print("--- [Expander] Generating parallel queries... ---")
expanded_queries = query_expansion_chain.invoke({"question": state['original_question']})
return {"expanded_queries": expanded_queries}
query_expansion_node 是整个高级检索过程的“思考”步骤。它接收用户的原始查询,但并不立即跳入搜索环节,而是先用 LLM 进行一次头脑风暴,生成一套更强大、更多元的查询集合,为后续更全面的搜索做好准备。
下一个节点,我们将并行执行所有这些生成的查询。
from concurrent.futures import ThreadPoolExecutor
def retrieval_node(state: RAGGraphState):
"""第二个节点:接受且并行执行扩展查询"""
print("--- [Retriever] Executing parallel searches... ---")
# 创建一个包含所有要执行的查询列表
all_queries = []
expanded = state['expanded_queries']
all_queries.append(expanded.hypothetical_document)
all_queries.extend(expanded.sub_questions)
all_queries.extend(expanded.keywords)
all_docs = []
# 用 ThreadPoolExecutor 并发运行所有检索器调用
with ThreadPoolExecutor(max_workers=5) as executor:
results = executor.map(retriever.invoke, all_queries)
for docs in results:
all_docs.extend(docs)
# 最后一步是对检索到的文档删除重复数据,以创建干净、唯一的上下文
unique_docs = {doc.page_content: doc for doc in all_docs}.values()
print(f"--- [Retriever] Found {len(unique_docs)} unique documents from {len(all_queries)} queries. ---")
return {"retrieved_docs": list(unique_docs)}
retrieval_node 是真正执行并行查询的“引擎”。其核心是 ThreadPoolExecutor 和 executor.map,它将由7-9个扩展查询组成的列表,同时分派到向量存储中进行搜索。这种“分散-收集”的方法确保了我们可以获得所有搜索视角的综合效益,而不会因为查询数量的增加而引入线性延迟。
最后,我们组装整个图,按顺序连接扩展、检索以及最终的生成节点。
from langgraph.graph import StateGraph, END
workflow = StateGraph(RAGGraphState)
# 将节点加入图
workflow.add_node("expand_queries", query_expansion_node)
workflow.add_node("retrieve_docs", retrieval_node)
workflow.add_node("generate_answer", generation_node)
# 定义线性工作流
workflow.set_entry_point("expand_queries")
workflow.add_edge("expand_queries", "retrieve_docs")
workflow.add_edge("retrieve_docs", "generate_answer")
workflow.add_edge("generate_answer", END)

现在,让我们进行最终的对比分析。我们向简单RAG系统和我们刚刚构建的高级RAG系统提供同一个模糊的查询,然后比较两者检索到的上下文质量以及最终答案的质量。
# 用户查询使用一般术语(“big and fast”)而不是知识库中的技术术语
user_query = "How do modern AI systems get so big and fast at the same time? I've heard about attention but I'm not sure how it's optimized."
# --- 执行简单 RAG 系统 ---
print("--- [SIMPLE RAG] Retrieving documents...")
# 拦截检索步骤以检查简单系统找到的内容
simple_retrieved_docs = retriever.invoke(user_query)
print(f"--- [SIMPLE RAG] Documents Retrieved: {len(simple_retrieved_docs)}")
simple_rag_answer = simple_rag_chain.invoke(user_query)
# --- 执行高级 RAG 系统 ---
# --- 最终分析 ---
print("\n" + "="*60)
print(" RETRIEVED DOCUMENTS COMPARISON")
print("="*60)
print(f"\n--- Simple RAG Retrieved {len(simple_retrieved_docs)} document(s) ---")
for i, doc in enumerate(simple_retrieved_docs):
print(f"{i+1}. {doc.page_content}")
print(f"\n--- Advanced RAG Retrieved {len(advanced_rag_result['retrieved_docs'])} document(s) ---")
for i, doc in enumerate(advanced_rag_result['retrieved_docs']):
print(f"{i+1}. {doc.page_content}")
print("\n" + "="*60)
print(" ACCURACY & QUALITY ANALYSIS")
运行后,我们得到了清晰的输出对比:
#### 输出 ####
============================================================
RETRIEVED DOCUMENTS COMPARISON
============================================================
--- Simple RAG Retrieved 1 document(s) ---
1. **Multi-headed Attention Mechanism**: The core component of the Transformer architecture is the multi-headed self-attention mechanism...
--- Advanced RAG Retrieved 3 document(s) ---
1. **FlashAttention Optimization**: ...FlashAttention is an I/O-aware algorithm that reorders the computation to reduce the number of read/write operations...
2. **Mixture of Experts (MoE) Layers**: ...a router network dynamically selects a small subset of 'expert' sub-networks to process each input token...
3. **Multi-headed Attention Mechanism**: The core component of the Transformer architecture...
============================================================
ACCURACY & QUALITY ANALYSIS
从结果中,我们可以得出几个关键结论:
- 高级系统成功的关键在于
query_expansion_node 弥合了语义鸿沟。它生成的假设文档和目标子查询,引入了用户原始问题中缺失的技术术语,如 Mixture of Experts、FlashAttention、scaling、optimization 等。正是这些术语,使得检索到额外的关键文档成为可能。
- 检索到的文档召回率得到了显著提升。简单RAG只找到1篇关于注意力机制的文档,而高级系统捕获了全部3篇相关文档(增加了FlashAttention和MoE)。这为后续的答案生成器提供了完整的上下文,使其能够产出更全面、技术更准确、质量更高的最终答案。
这种并行查询扩展的模式,本质上是将一次“猜测”变成了多次“覆盖”,极大地提升了AI智能体在信息检索阶段的鲁棒性和准确性,是构建高可靠智能体系统不可或缺的一环。想了解更多类似的架构实践和深度讨论,欢迎访问云栈社区与广大开发者交流。
[^1]: Building the 14 Key Pillars of Agentic AI: https://levelup.gitconnected.com/building-the-14-key-pillars-of-agentic-ai-229e50f65986
[^2]: 预测执行: https://en.wikipedia.org/wiki/Speculative_execution
[^3]: 冗余执行: https://developer.arm.com/community/arm-community-blogs/b/embedded-and-microcontrollers-blog/posts/comparing-lock-step-redundant-execution-versus-split-lock-technologies
[^4]: 🤖 Agentic Parallelism: A Practical Guide 🚀: https://github.com/FareedKhan-dev/agentic-parallelism
 发表于 2026-2-19 01:35:37
|
查看: 261|
回复: 0
发表于 2026-2-19 01:35:37
|
查看: 261|
回复: 0
