想让你的手机语音助手更懂你,就需要用你的聊天记录对它进行“微调”。但如今的大语言模型(LLM)动辄数十亿参数,手机有限的算力和内存连顺畅推理都吃力,更别提需要反复更新参数的训练过程了。
虽然已有像MeBP这样的技术,能让大模型在1GB内存的手机上训练,但每次迭代仍需老老实实地为所有层计算梯度,这成了拖慢速度的最大瓶颈。来自Opt-AI的研究者提出了一个看似“偷懒”却极其聪明的思路:为什么每次都要给所有层计算梯度?能不能只算一部分?
他们提出的方法叫做LCSB。简单来说,它就像给训练过程装了个“随机跳过”按钮,每次只随机选择一部分层进行完整的梯度计算,剩下的层则暂时“休息”。结果令人惊讶:训练速度最高提升40%,而模型性能损失不到2%。更意外的是,在严苛的4位量化训练中,当传统方法崩溃时,LCSB竟能稳定运行。

移动端训练瓶颈:反向传播的计算之殇
在手机上微调大模型,核心挑战在于内存和计算。MeBP通过梯度检查点和惰性权重加载解决了内存大头,但计算瓶颈依然突出。
对于一个典型的Transformer模型,反向传播的时间是前向传播的1.6倍。每反向通过一层,MeBP都需要:1. 解压缩4位整数量化权重(占32%-42%时间);2. 重新加载保存的激活值;3. 执行复杂的反向计算。这个过程需要对所有层重复。
于是问题来了:在每次训练迭代中,真的有必要为每一层都精确计算梯度吗? Transformer架构提供了两个关键线索:
1. 残差连接
每个Transformer层的核心是 y = x + F(x, θ)。这意味着即使不计算F部分的梯度(视其为常数),梯度依然可以通过恒等路径x流向上游。
2. 优化器动量
像AdamW这样的优化器会维护“动量”项,即历史梯度的指数移动平均。即使某一时刻某层的当前梯度为0,动量项里仍保存着过去的“运动趋势”,能推动参数进行基于历史的微小更新。
LCSB正是巧妙利用了这两个特性,实现了一场高效的“梯度计算轮休制”。
化繁为简:LCSB如何实现选择性梯度计算?
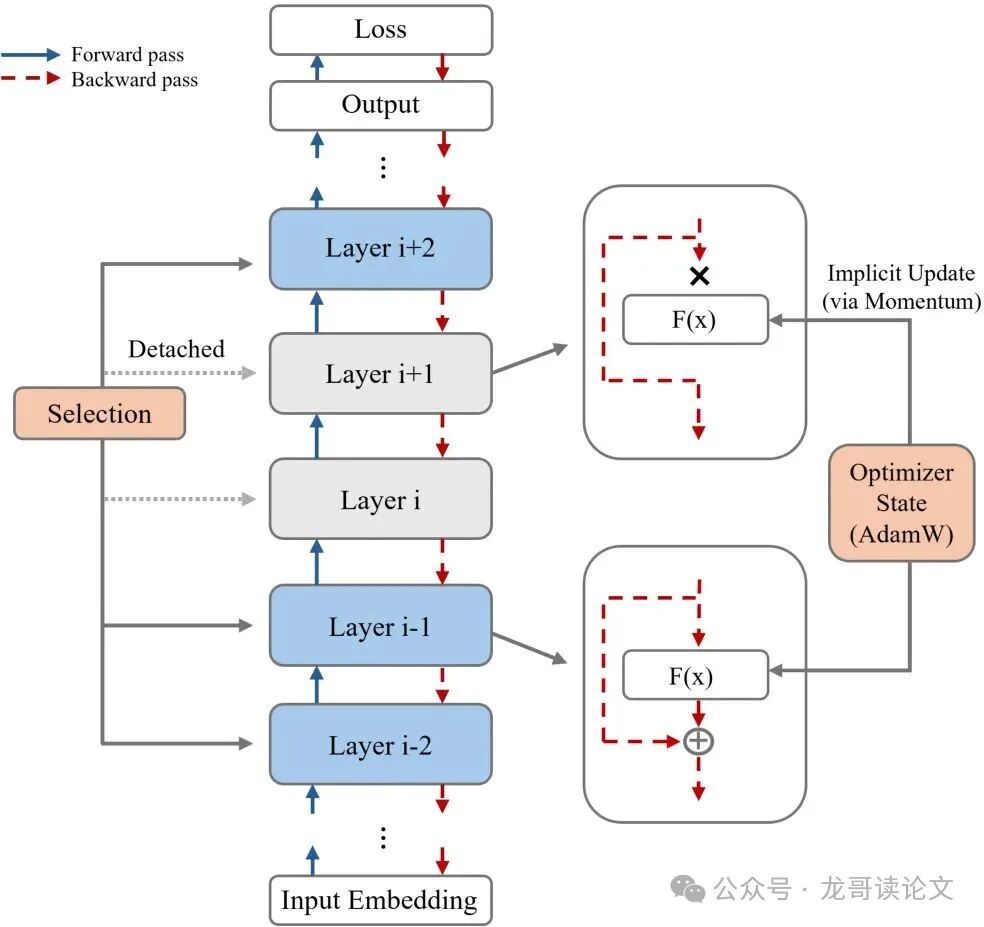
LCSB的核心操作异常简单。在每一步训练中,它随机选择一定比例(例如50%)的层,并对剩余层执行 “分离” 操作。这里的“分离”是PyTorch框架中的detach()操作,意为告知自动微分系统:“这个张量是常数,不要通过它回传梯度”。
这样一来:
- 对于被选中的层:它们接收精确的梯度信号,参数通过标准优化器步骤更新。
- 对于未被选中的层:它们的当前梯度
∇θL 被设为0。但是,它们的参数并未停滞。由于AdamW优化器有动量项 m_t = β₁·m_{t-1} + (1-β₁)·g_t,即使当前梯度g_t=0,历史动量m_{t-1}依然存在。
此时参数更新公式变为:
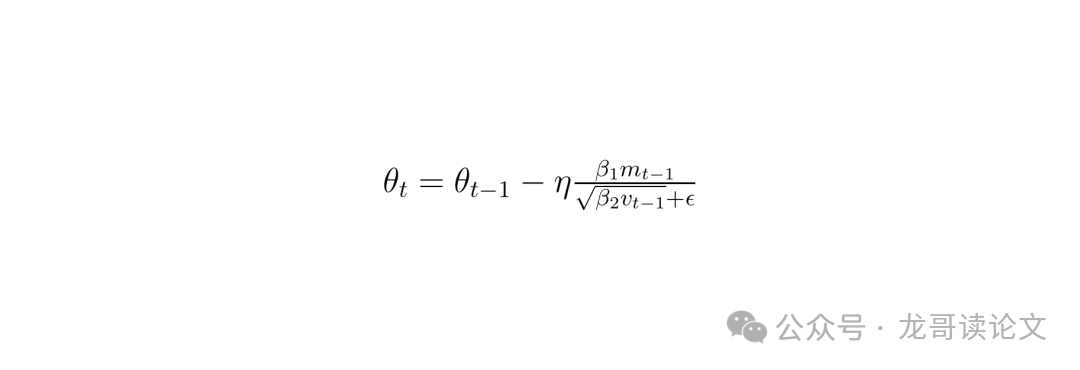
这意味着未被选中的层仍在进行一种 “隐式更新” ,参数会沿着历史梯度的平均方向进行微小的“滑行”。

这种设计的巧妙之处在于,它大幅减少了每步的计算量(跳过了耗时操作),同时又保证了:
- 前向计算的完整性:模型每次的输入-输出映射都是完整的,没有引入额外噪声。
- 梯度的顺畅流通:通过残差连接,梯度总能流回上游的被选中层。
- 参数的持续演化:所有参数都在以不同方式(显式或隐式)更新。
理论支撑:块坐标下降视角下的收敛保证
一个听起来像“偷懒”的方法,如何保证收敛?论文给出了坚实的理论视角:块坐标下降(Block Coordinate Descent, BCD)。
想象优化一个复杂函数,其变量可分组成若干“块”。BCD的策略不是同时更新所有变量,而是每次只选一组变量沿其梯度方向更新,其他组变量保持不动,下次迭代可能选另一组。只要轮换均匀,最终也能收敛。
在LCSB中,每一层的参数可视为一个“块”。每次训练步骤,随机选择一些“块”进行精确梯度更新(显式更新),而未被选中的“块”则通过动量进行平滑的隐式更新。这可视作一种带动量的、软性的BCD,为其可行性提供了理论基础。
实验验证:速度提升显著,质量几乎无损
研究者在多个模型和任务上进行了全面测试。首先验证了选择比例(r)对速度和效果的影响。
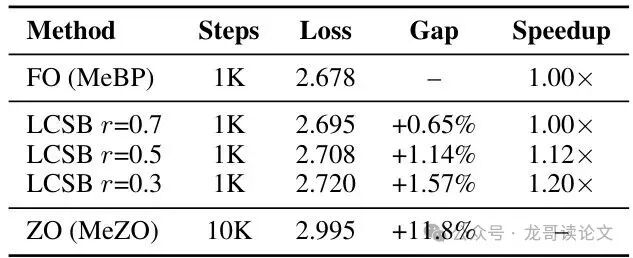
从表中可以清晰看到一个 “甜蜜点”:
- r=0.5(选择一半的层):速度提升12%,性能损失仅1.14%,是理想的平衡点。
- r=0.3:速度提升20%,性能损失1.57%,适合追求极致速度。
- r=0.7:性能几乎无损(+0.65%),但速度提升不明显。
同时,对比结果显示了零阶优化方法MeZO的不足:即使使用10倍训练步数,效果仍远差于LCSB。这说明在大语言模型(LLM)微调场景下,稀疏但精确的一阶梯度远比密集但噪声大的零阶估计高效。
更惊喜的是,模型越大,LCSB收益越明显。
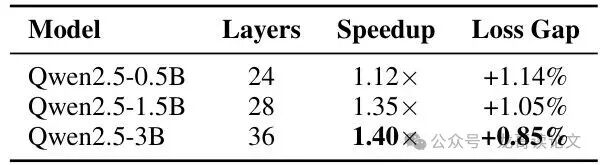
从0.5B到3B模型,速度提升从1.12倍增至1.40倍,而性能损失反而从1.14%下降到0.85%。这可能是因为大模型层间冗余更多,且跳过大模型反向传播的线性开销收益更大。
与其他高效训练方法的对比结果如何?
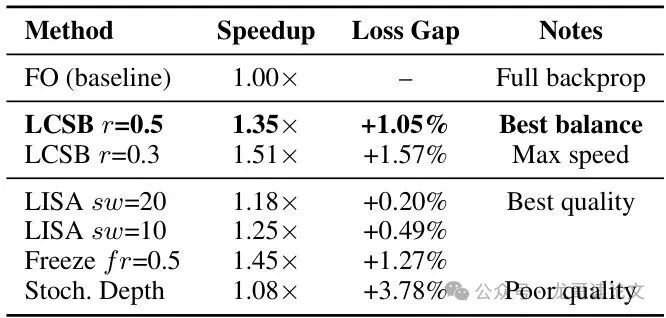
如表所示,LCSB在速度与质量间取得了最佳平衡:
- LISA:质量好,但计算梯度重要性的开销拖累了速度。
- Freeze:速度快,但僵化地固定某些层损害了质量。
- Stochastic Depth:因丢弃层改变前向计算而引入噪声,质量与速度均不佳。
- LCSB:凭借“完整前向+选择性反向”设计,在1.35倍加速下仅牺牲1.05%质量,表现全面。
另一个重要发现是:简单的均匀随机选择策略就是最好的。尝试按梯度重要性选择层,其计算开销(慢了4.8倍)完全抵消了潜在收益,使得LCSB部署异常简单。
意外发现:量化训练中的稳定性提升
如果说前述结果是“意料之中的优秀”,那么这个发现便是“意料之外的惊喜”,也是论文最引人注目的亮点。
为了真实模拟手机环境,研究者进行了4位整数量化(INT4)下的训练实验。结果令人震惊:
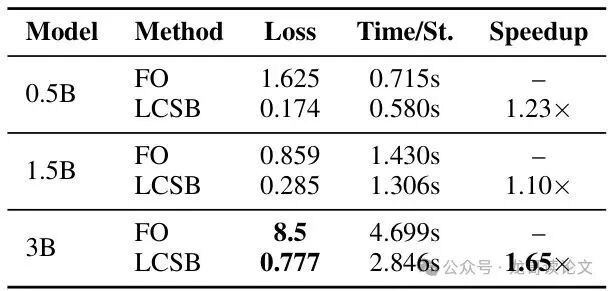
对于3B量化模型,传统的全反向传播训练完全发散(损失暴增)。然而,使用LCSB时,训练奇迹般地平稳收敛,同时还获得了1.65倍加速!
为何如此?论文给出合理解释:选择性梯度计算起到了隐式正则化的作用。
在低精度(4位)量化下,权重和计算充满噪声。全反向传播时,噪声会通过漫长梯度链逐层累积放大,最终可能导致梯度爆炸或方向偏离,致使训练崩溃。
而LCSB周期性地“断开”一些层,主动打断了这些长程的噪声累积路径。梯度只能通过残差主路径流动,如同在湍急河流中设置缓冲池,防止了误差的无限传播,从而使在手机上微调大模型的过程更加稳定。

这一发现意义重大。这意味着LCSB不仅是“加速工具”,在移动端超低精度训练等极端条件下,它可能成为让原本不可能的训练成为可能的 “稳定器”和“必需品”。
未来展望:从即插即用到自适应调度
LCSB设计干净,几乎可作为现有移动端训练管道的一个即插即用模块。但研究并未止步,他们尝试了更智能的自适应调度:在训练早期使用较高的选择比例r,后期逐渐降低。
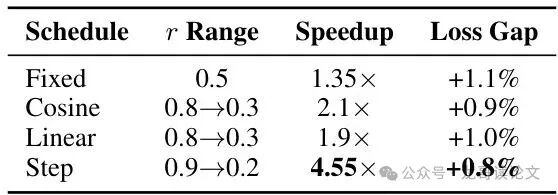
结果振奋人心!阶梯下降调度实现了夸张的4.55倍加速,且最终性能损失比固定比例策略还要低。这印证了一个直觉:训练初期需要密集梯度信号寻找方向;后期损失曲面已较平滑,可忍受稀疏更新进行微调。
这为未来研究打开了新大门:能否设计轻量级元控制器动态预测最优r?能否将LCSB思想与其他效率技术结合产生叠加效应?其在量化训练中的正则化效应,也值得更深层的理论研究。
核心问题解答
LCSB和随机深度有什么区别?
这是最核心的区别。随机深度是在前向传播时直接丢弃(跳过)某些层,改变了每次前向计算结果,引入了噪声。而LCSB是在反向传播时“分离”某些层的计算图,前向传播是100%完整的,模型输出不变,只是被分离的层在当前步不更新参数(但通过动量隐式更新)。LCSB更稳定,效果更好。
LCSB中的“隐式更新”如何工作?
关键在于优化器的动量项。以AdamW为例,其参数更新不仅依赖当前梯度g_t,还依赖历史动量的指数平均m_{t-1}。当某层未被选中时,其当前梯度g_t被设为0。但更新公式中 β₁ * m_{t-1} 项仍然存在,这意味着参数会沿着过去一段时间平均梯度的方向“滑行”一小步,而非完全静止,从而保证了训练的连续性。
为什么LCSB在量化训练中更稳定?
低精度量化会引入显著数值噪声。传统全反向传播中,噪声会沿从输出到输入的长链反向传播,并在每层梯度计算中被累积放大,最终可能导致梯度爆炸。LCSB周期性地“切断”某些层的反向路径,相当于在长链中插入“断路点”,阻止了噪声的无限制累加,从而起到了稳定训练的隐式正则化效果。
方法评价
创新性:核心思路清晰巧妙,是对现有训练流程的“手术式”优化。将残差连接和优化器动量结合实现选择性反向传播,并上升到块坐标下降理论框架,创新性扎实。
实验与价值:实验设计全面,覆盖多模型尺寸、任务类型和对比基线。在量化训练中发现稳定性提升这一“意外收获”并给出合理解释,增强了说服力。为移动端大模型高效训练提供了简单有效的工具,其“选择性计算”思想及在低精度下的正则化效应对后续研究有启发价值。
实用性与复现:方法本身基于成熟的自动微分和优化器,在常规及量化训练中均表现稳定。目标明确为降低训练成本,实验证明能带来显著的时间节省,且对硬件无额外要求。算法本身极其简单,核心即几行detach操作,复现门槛很低。
当然,论文的收敛性理论分析主要基于BCD框架,这对于非凸的神经网络训练更多是一种启发性保证。此外,所有设备实验均在模拟环境中进行,未在真实手机芯片上验证,可能存在未知的硬件适配问题。但总体而言,LCSB为资源受限环境下的大模型微调提供了一个颇具前景且易于实现的优化思路。对这类边缘计算与模型优化技术感兴趣的朋友,欢迎在云栈社区继续交流探讨。
参考文献
- LCSB: Layer-Cyclic Selective Backpropagation for Memory-Efficient On-Device LLM Fine-Tuning. Juneyoung Park, et al. arXiv:2602.13073v1. 2026.
- Memory-efficient fine-tuning of large language models on mobile devices. Junhao Song, Mingjie Tang. arXiv:2510.03425. 2025. (MeBP)
- LoRA: Low-Rank Adaptation of Large Language Models. Hu et al. arXiv:2106.09685. 2021.
- Deep Residual Learning for Image Recognition. He et al. CVPR 2016.
*本文基于公开论文进行解读,仅代表个人观点,不构成任何投资或项目落地建议。
 发表于 2026-2-19 02:16:55
|
查看: 231|
回复: 0
发表于 2026-2-19 02:16:55
|
查看: 231|
回复: 0
