在机器学习项目的特征工程环节中,特征离散化(Feature Discretization)是一项强大却常被忽视的技术。它的核心思想,是将原本连续的数值型特征转换为离散的类别型特征,通过设定阈值将连续值“分箱”(binning),从而提升模型的可解释性与稳定性。
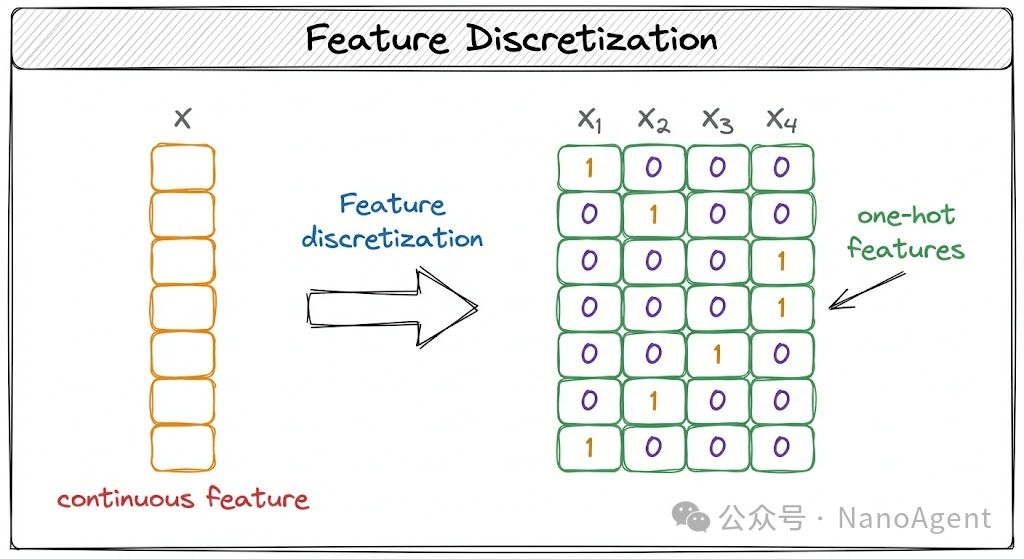
为什么要进行特征离散化?
在实际业务中,很多连续变量的微小波动对业务逻辑并无实质影响。例如,在分析用户消费行为时,29岁与30岁在数值上差异很小,但在人生阶段和消费习惯上可能代表着从青年到成家的重大转变。将年龄这样的连续特征离散化为“青年”、“中年”、“老年”等有意义的组别,能让模型更好地捕捉这种阶段性的跳跃式影响,而非纠结于无意义的微小数值差异。
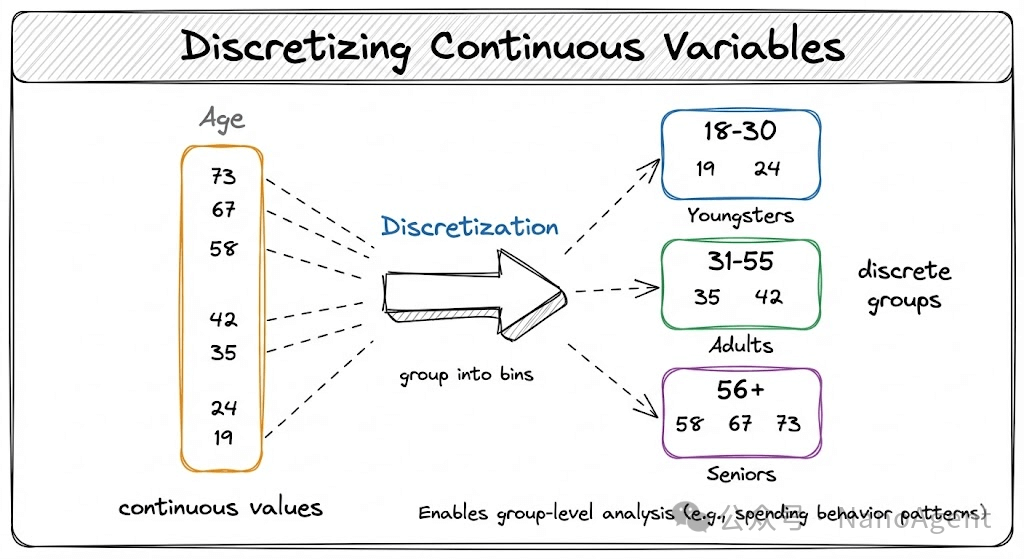
除了增强业务可解释性,离散化还是一个有效的“降噪”手段。现实数据中的连续变量往往包含大量随机波动或测量误差。通过将数值归入不同的箱体,离散化能平滑掉这些无意义的噪声,有效提高数据的信噪比。
从模型能力的角度看,离散化甚至能为简单模型赋予捕捉复杂模式的能力。一个经典的例子是,即便使用最基础的线性回归模型,在将特征离散化并进行独热编码(One-Hot Encoding)后,模型也能在不同的数值区间内拟合出不同的斜率,从而近似地刻画非线性关系。这相当于用一系列“阶梯”去逼近复杂的曲线。
如何进行特征离散化?常用切分策略
特征离散化通常包含两个步骤:切分(Binning) 和 编码(Encoding)。其中,切分策略的选择至关重要,主要分为两种:
- 等宽离散化:将特征值的取值范围均匀地划分为若干个宽度相等的区间。这种方法简单直观,适用于数据分布相对均匀的场景。
- 等频离散化:将数据划分为若干个区间,并确保每个区间内包含的样本数量大致相同。这种方法能更好地处理长尾分布或存在极端值(离群点)的数据,保证每个“箱”都有足够的样本进行学习。
在完成切分后,我们通常会对产生的离散类别进行独热编码,将其转换为二进制的稀疏向量,以便模型能够独立地学习每个区间(箱)的权重。
特征离散化是“万能药”吗?适用场景与风险
特征离散化是一把双刃剑。最需要警惕的风险是过拟合。离散化,特别是独热编码,会显著增加数据的特征维度。在机器学习中有一个基本规律:维度越高,数据越容易变得线性可分。这听起来是好事,但也意味着模型更容易“记住”训练数据中的噪声和特定样本,而非学到泛化性强的规律,从而导致过拟合风险急剧上升。
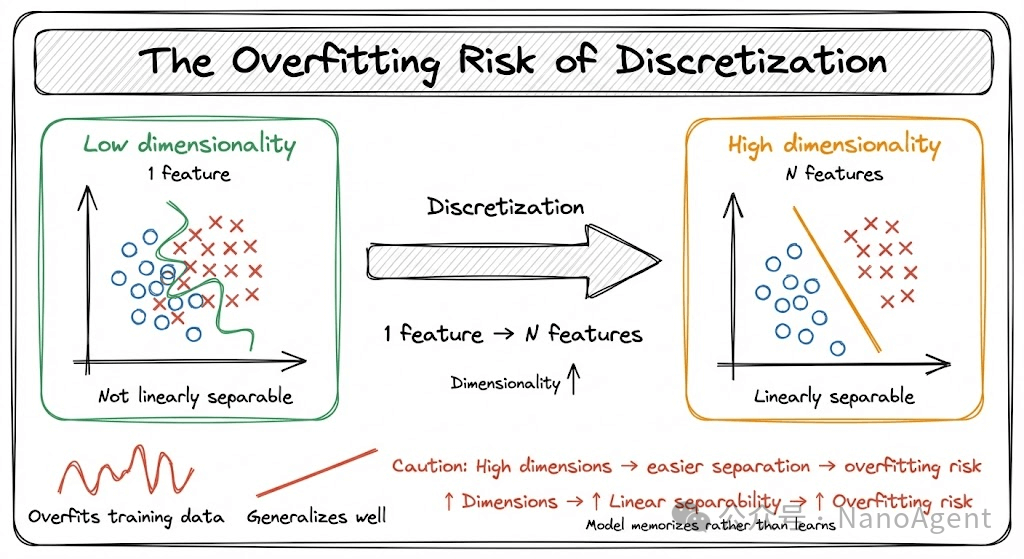
因此,使用特征离散化时务必牢记以下几点:
- 切忌过度离散化:将特征切得过碎(分箱过多),会失去分组归纳的意义,不仅增加计算负担,也会放大过拟合风险。
- 业务直觉先行:离散化的边界(如年龄分组切在30岁还是35岁)应有业务逻辑支撑,而非纯粹的数据驱动。模糊的正确远胜于精确的错误。
- 明确适用场景:在以下场景中,特征离散化往往能发挥良好效果:
- 地理空间数据:将连续的经纬度坐标离散化为地理网格或行政区域。
- 生理或阶段指标:如年龄、血压分段、产品生命周期阶段等,其影响通常是阶梯式的。
- 存在明确范围限制的指标:如收入等级、信用评分区间等,其数值本身就被限制在特定 brackets 内。
总结
特征离散化通过将连续特征转换为离散特征,以牺牲少量数值精度为代价,换来了模型鲁棒性、稳定性和解释性的大幅提升。它让简单的模型具备了表达复杂关系的能力,并能有效抑制数据噪声。然而,我们必须清醒地认识到其带来的维度爆炸与过拟合风险,做到有逻辑、有节制地使用。在合适的场景下,这项技术无疑是提升模型性能的一件利器。
想了解更多关于特征工程、模型调优的实战技巧与深度讨论?欢迎来云栈社区与众多开发者一起交流切磋。 |  发表于 2026-2-20 19:35:12
|
查看: 215|
回复: 0
发表于 2026-2-20 19:35:12
|
查看: 215|
回复: 0
