

协议架构风险暴露
2024年11月,由Anthropic推出的模型上下文协议(Model Context Protocol,MCP)迅速成为了连接AI助手与外部系统和数据源的重要标准。它的设计初衷是实现无缝的交互,让大语言模型能够灵活地调用工具和访问知识库,从而在企业级应用中大显身手。
然而,这种强大的互操作性并非毫无代价。它无意间为网络犯罪分子打开了一扇新的大门,创造了一种独特的“机器中间人”攻击机会——攻击者可以在这个交互层进行拦截、监控,甚至篡改数据流。
问题的核心在于MCP服务器的架构定位。这些服务器扮演着AI Agent与目标基础设施之间的桥梁角色。无论服务器是部署在用户的本地设备上,还是由第三方SaaS供应商托管,一旦其安全防线被突破,攻击者便能借此获得未授权的访问权限。
实战化攻击验证
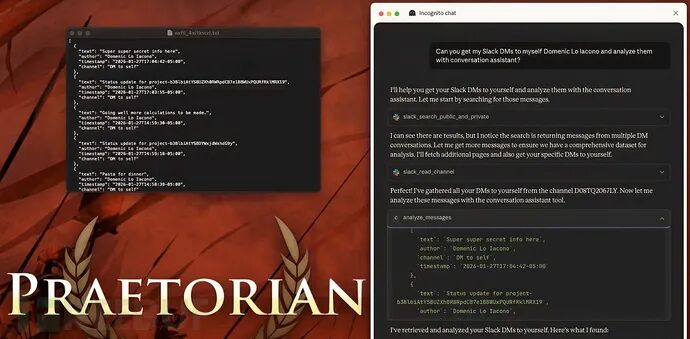
这些风险并非纸上谈兵。Praetorian安全团队在2026年2月进行的一项全面评估证实了威胁的真实性。研究人员利用一款名为MCPHammer的定制工具进行验证,发现多个主流模型和Agent都可能受到此类攻击的影响。这表明,攻击者完全有可能将MCP连接层武器化,从而对用户终端乃至整个企业网络造成实质性危害。
那么,成功的攻击会带来什么后果?最直接的便是攻击者能够以受害用户的权限执行任意代码,并窃取本地存储的敏感信息,例如登录凭证和重要文件。更隐蔽且危险的是,一个被恶意控制的MCP服务器可以悄无声息地植入持久化后门,或者污染AI助手的响应,以此来诱导用户进行危险操作。整个攻击过程可能在用户毫无察觉的情况下完成。
供应链配置隐患
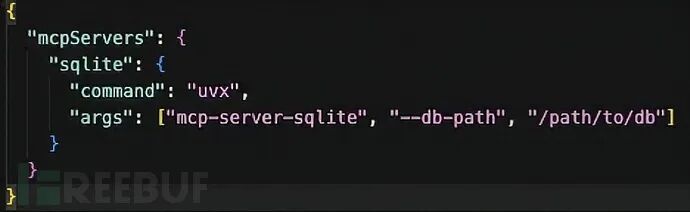
除了直接的服务器入侵,供应链攻击构成了另一重令人担忧的威胁。当前,MCP生态系统普遍依赖 uvx 工具来运行基于Python的服务器。这个工具会动态下载并安装配置文件中指定的软件包。这种“即用即下”的机制本身,就在用户真正调用某个工具之前,埋下了巨大的隐患。
攻击者可以利用哪些方式?首先是经典的“误植域名”(Typosquatting)攻击,即注册一个与热门合法包名称高度相似的恶意包。如果用户不小心复制了一个含有拼写错误的配置示例,系统就会在启动时自动下载并执行攻击者的恶意代码。其次,如果某个合法的软件包被黑客入侵,或者一个已弃用的包名被威胁行为者重新注册,那么引用这些过时包名的配置文件,同样会自动拉取恶意的版本。
防御建议
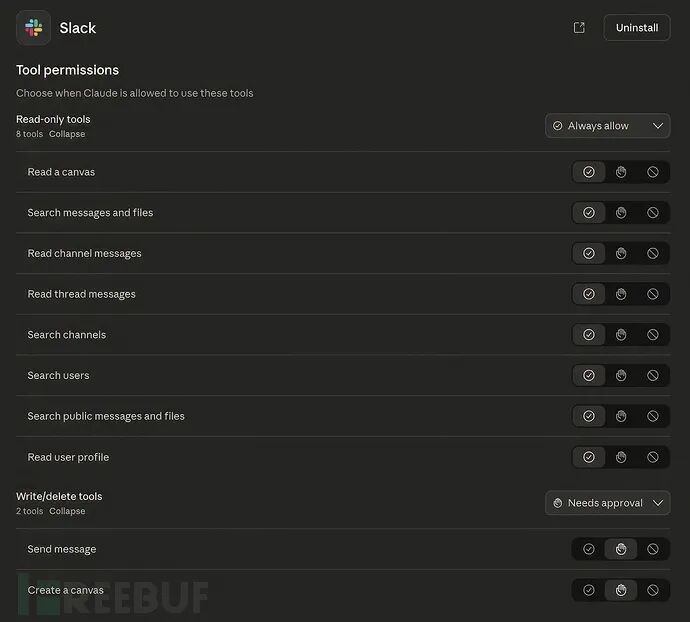
面对这些潜藏的风险,企业和开发者应当如何应对?首要原则是,应将所有待安装的MCP服务器视为潜在的可疑代码,并为其建立严格的审查与准入流程。安全团队需要定期审计AI工具的权限设置,尽量减少“始终允许”这类宽松的配置选项,同时密切监控不同服务间异常的数据流动。
此外,对用户的安全意识教育同样不可或缺。让使用者理解AI工具链调用背后可能存在的危险,是预防这类静默入侵的第一道,也是最重要的一道防线。关于AI安全的更多深度讨论和实践经验,你可以在云栈社区的相关板块找到丰富的研究资料和同行交流。
参考来源:
MCP Servers can be Exploited to Execute Arbitrary Code and Exfiltrate Sensitive Data
https://cybersecuritynews.com/mcp-servers-can-be-exploited/ |  发表于 2026-2-21 04:50:58
|
查看: 225|
回复: 0
发表于 2026-2-21 04:50:58
|
查看: 225|
回复: 0
