昨天晚上(2月19日),Google发布了Gemini系列的新成员——Gemini 3.1 Pro。距离上一代Gemini 3 Pro(去年11月发布)仅仅过去三个月,这个更新节奏确实有些令人意外。但看完官方发布的性能数据后,这次升级的分量,可能远超一次常规迭代。

核心看点:推理能力取得突破性进展
此次升级最引人注目的,是模型在抽象推理能力上的巨大飞跃。
ARC-AGI-2 是目前业界公认难度最高的抽象推理基准测试之一,它并非考查记忆或知识,而是真正检验模型识别模式、归纳规则并进行逻辑推导的“举一反三”能力。
在这个关键测试上,上一代Gemini 3 Pro的成绩是31.1%。而 Gemini 3.1 Pro直接将分数提升到了77.1%,涨幅达到148%,性能翻了一倍还不止。
这个成绩放在当前的顶级模型阵营里是什么水平?我们来看一组对比数据。
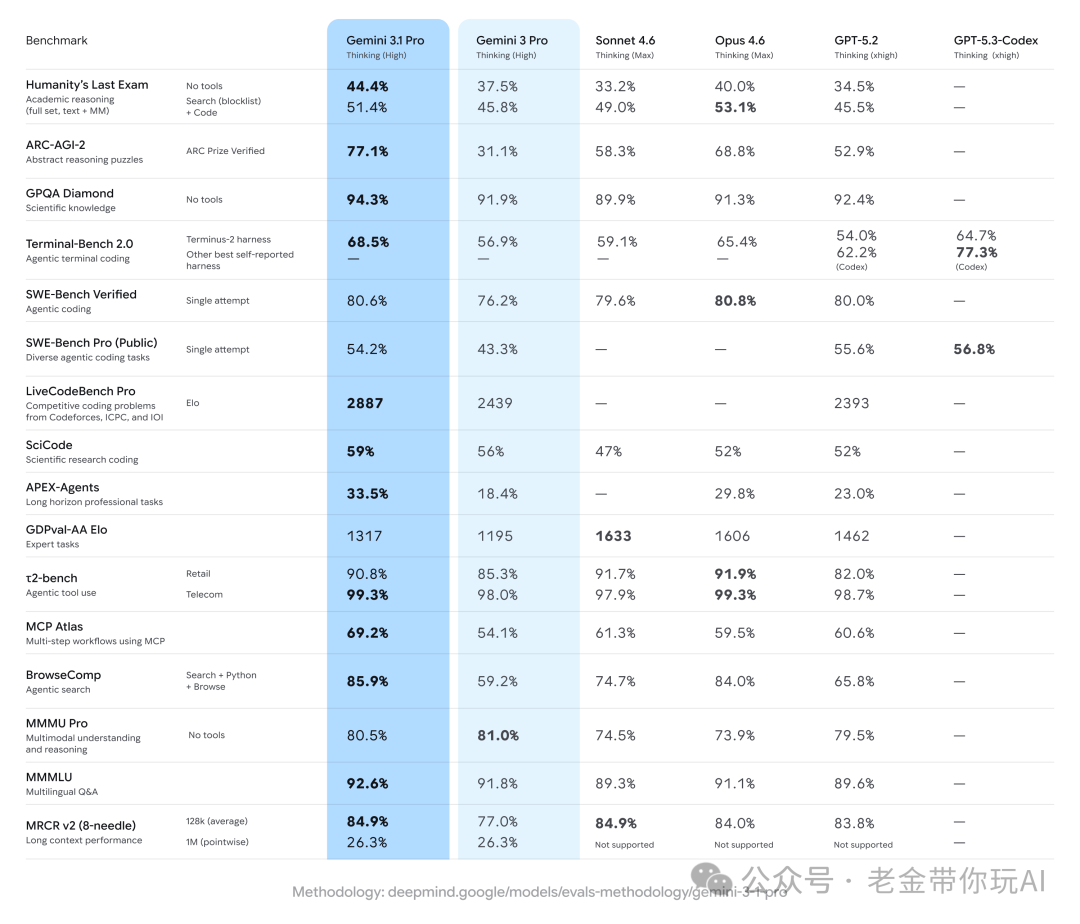
根据Google公布的基准测试结果,Gemini 3.1 Pro的77.1%显著高于Claude Opus 4.6的68.8%,更是大幅领先于GPT-5.2的52.9%。这标志着Google的模型在核心推理能力这个关键赛道上,首次实现了对OpenAI和Anthropic的全面领先。
16项测试胜出13项,综合表现强劲
除了推理能力,Gemini 3.1 Pro在更广泛的评估中也展现出了强大的竞争力。在官方对比的16项标准测试中,它拿下了其中13项的第一名。
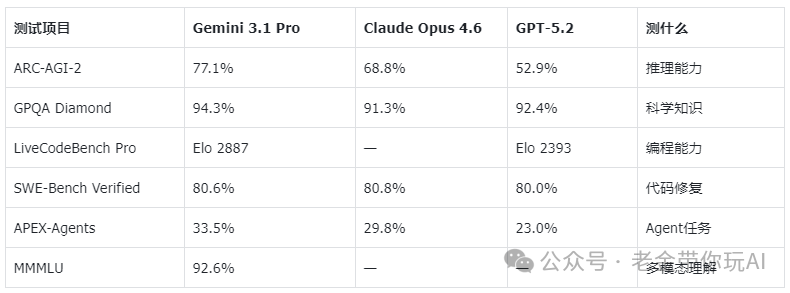
一些关键测试结果解读:
- GPQA Diamond (94.3%):这项测试包含物理、化学、生物等学科的博士级别难题。94.3%的得分意味着模型在硬核科学知识问答上,已经达到了相当高的专业水平。
- SWE-Bench Verified (80.6%):这对开发者尤为重要。该测试使用真实的GitHub issue来评估模型修复bug的能力。80.6%的通过率意味着在十个真实bug中,模型能成功修复超过八个,具备了很高的实用价值。
- LiveCodeBench Pro (Elo 2887):在竞争性编程问题测试中,Gemini 3.1 Pro的Elo评分达到了2887,远超GPT-5.2的2393,显示出强大的代码生成与问题解决能力。
当然,竞争并非一边倒。Claude系列模型在部分领域依然保持优势。例如,在SWE-Bench测试中,Claude Opus 4.6以80.8%的微弱优势领先;在GDPval-AA专家任务评估中,Claude Sonnet 4.6的1633分也高于Gemini 3.1 Pro的1317分。
因此,更客观的结论是:Gemini 3.1 Pro在大多数通用及推理测试中确立了领先地位,但在某些特定或专家级任务场景下,Claude等模型仍有其不可替代的优势。当前的大模型竞赛,已经进入了各有所长、差异化竞争的阶段。
容易被忽略的升级:SVG生成与Agent工作流潜力
除了跑分,本次升级还有两个值得关注的实用特性提升。
1. SVG生成能力质变
SVG(可缩放矢量图形)是Web开发中用于数据可视化、图标和交互图表的核心格式。Gemini 3.1 Pro在此方面的能力获得了大幅增强。Google展示了一个Demo:模型能够独立配置公共遥测数据流,生成代码并构建出一个实时追踪国际空间站轨道的航空航天仪表盘。
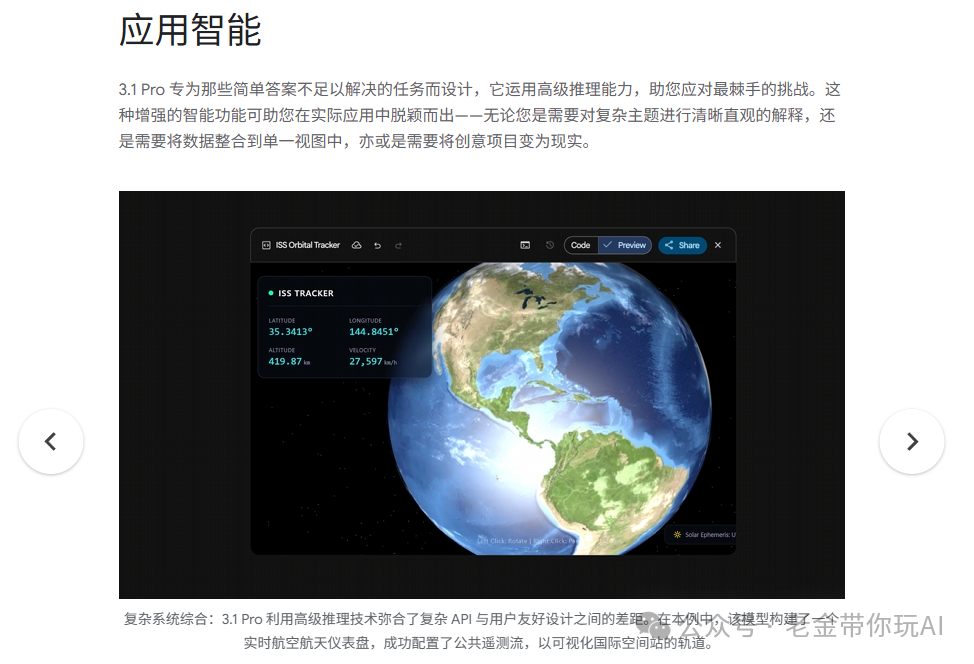
关键在于“独立配置”——这不是简单地生成一段示例代码,而是模型理解了任务目标后,自主完成了寻找数据源、处理数据、生成可视化界面并整合成一个可运行应用的全过程。
2. Agent能力的明确信号
上述Demo实质上展示了初步的Agent(智能体)能力:给定一个目标,模型可以规划步骤、调用工具(代码、搜索等)并执行,最终完成复杂任务。Google在博客中也明确表示,将持续优化模型在“雄心勃勃的Agent工作流”上的表现,这意味着未来我们可能看到它能处理更复杂的多步骤、多工具协作任务。
另一个创意Demo是,当要求为小说《呼啸山庄》的主角创建一个现代个人作品集网站时,模型并非简单复述情节,而是分析了小说的整体氛围和人物特质,设计并生成了一个符合角色气质的简约风格网站界面。

价格不变,获取渠道广泛
在性能大幅提升的同时,Gemini 3.1 Pro保持了与上一代相同的定价策略,这一点颇具诚意。
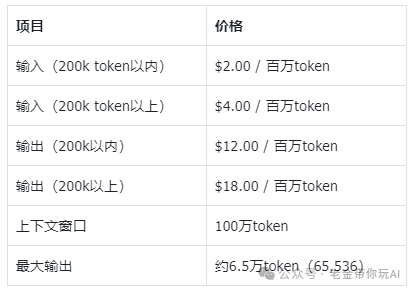
价格未变,但价值提升:输入/输出价格保持不变,同时保留了100万token的上下文窗口,处理长文档的能力依然是业界顶级水平。
在获取渠道上,Google也进行了全面铺开:
- 消费端:Gemini App(Pro和Ultra订阅用户)、NotebookLM。
- 开发端:Gemini API、Google AI Studio、Vertex AI。
- 第三方生态:一个值得注意的动向是,GitHub Copilot 现在也提供了Gemini 3.1 Pro作为底层模型选项之一。Google的模型深度集成到微软的开发工具链中,这在几年前是难以想象的。
总结与使用建议
综合来看,Gemini 3.1 Pro是一次扎实且有突破的升级,尤其在抽象推理能力上树立了新的标杆。不过,在尝试将其用于生产环境前,有几点需要注意:
- 预览状态:目前Gemini 3.1 Pro处于“Preview”阶段。这意味着API可能调整,性能可能波动,特别是其Agent工作流能力仍在优化中。生产环境应用建议等待正式版。
- 基准测试不等于一切:ARC-AGI-2的高分证明了强大的模式推理能力,但日常的编程、写作、分析等任务是多维度的。Claude在长文本深度处理、GPT在对话流畅度上仍有其优势。
- 等待独立验证:目前的数据均来自Google官方发布。模型的真实表现,还需要等待更多第三方开发者和研究机构的实际评测。
给你的建议:
- 开发者:可以立即通过 Google AI Studio 或 Gemini API 进行体验和测试,由于价格与上代一致,试错成本较低。
- 普通用户:如果你已经是Gemini Pro或Ultra的订阅用户,可以在App中直接体验新模型。
- 观望者:如果不急于尝鲜,可以等待正式版发布以及更丰富的社区评测后再做决定。
大模型的快速迭代正在持续改变人工智能的应用 landscape。这次Gemini 3.1 Pro的发布,无疑给整个行业带来了新的刺激和更高的标杆。对于关注技术趋势的开发者而言,持续跟踪、比较和测试这些顶尖模型,是理解未来工具潜力的重要方式。如果你对这类技术动态和实战讨论感兴趣,欢迎到 云栈社区 的 开发者广场 板块与其他朋友一起交流看法。
 发表于 2026-2-22 06:55:12
|
查看: 209|
回复: 0
发表于 2026-2-22 06:55:12
|
查看: 209|
回复: 0
