
像数据侦探一样,用Python发现数据背后的故事。
本节课,我们将借助 Python 中两个强大的第三方库,一起动手探索中国二手车市场的奥秘。你将体验到数据分析从数据加载到可视化的完整流程。
今天你将掌握的核心技能

学习建议:建议按顺序逐个运行代码块,观察每一步的输出结果。遇到不理解的地方,可以随时向 AI 助手提问!
实战场景:分析某二手车平台数据
本节课目标:在本节课中,你将动手体验两个超实用的第三方 Python 库——pandas 和 matplotlib,帮助你轻松地探索和可视化数据!
启动项目:认识第三方库
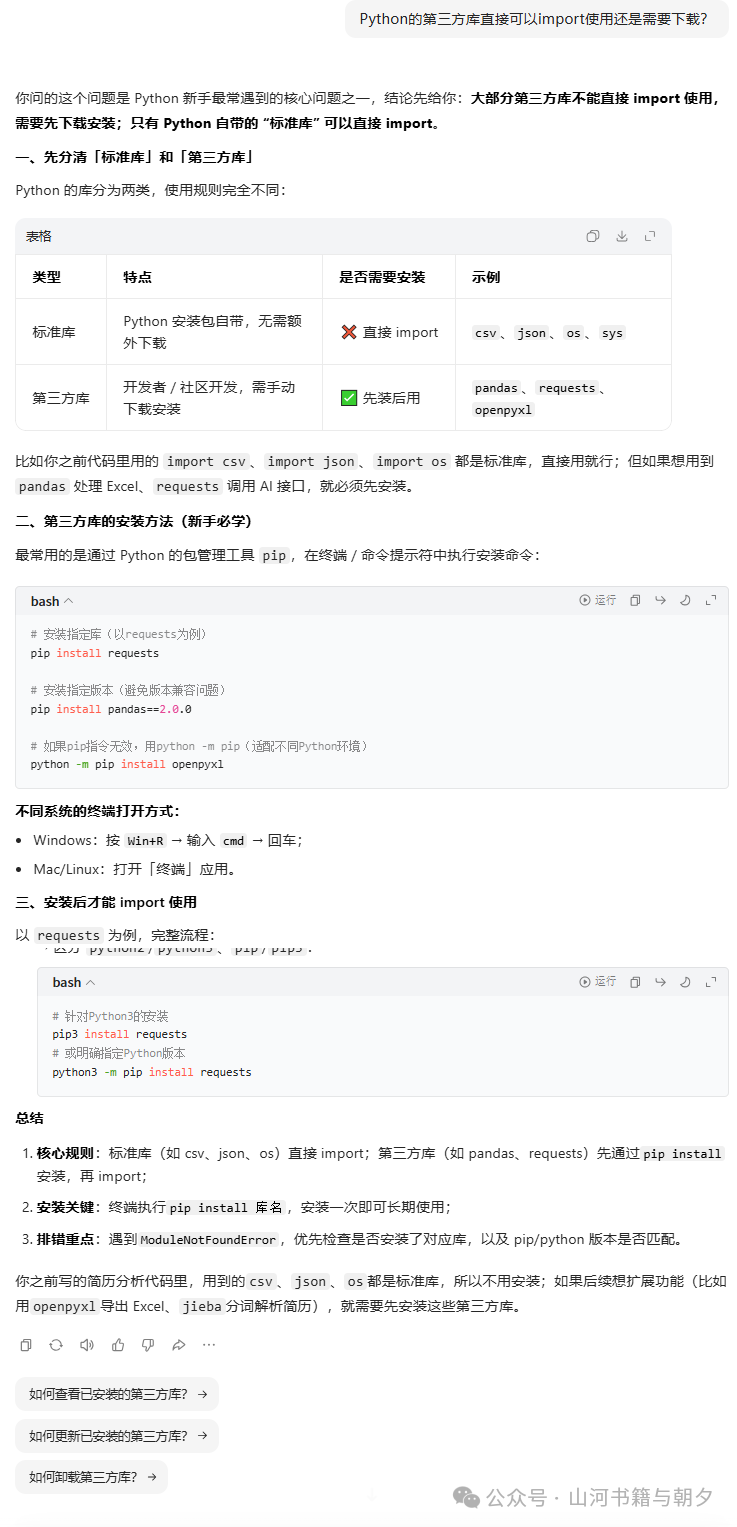
是不是对“第三方库”有点疑问?不知道它是可以直接用,还是需要额外操作?
简单来说,除了 Python 自带的“标准库”(如 csv、json),社区开发的强大工具(如 pandas、matplotlib)都需要先安装才能使用。最常用的安装方式是通过 pip 命令,在终端中输入 pip install pandas matplotlib 即可。下图清晰地解释了标准库与第三方库的区别及安装方法:
我们将使用一份 真实的中国二手车交易数据,包含各种热门品牌,通过数据分析来回答以下问题:
- 💰 哪些车的价格最高?
- 📅 不同年份的二手车价格有什么规律?
- 📈 里程数和价格之间有什么关系?
为什么选择二手车数据? 二手车市场是一个典型的结构化数据场景,数据维度清晰(车型、价格、年份、里程),非常适合作为数据分析的入门案例。通过这个实战项目,你将体会到数据分析在现实生活中的应用价值。

使用 pandas 加载和探索数据
pandas 是 Python 中最受欢迎的数据分析库之一,它的名字来源于“Panel Data”(面板数据)的缩写。pandas 非常适合用来加载和分析结构化数据,比如电子表格和 .csv 文件中的内容。它提供了一种叫做 DataFrame(数据框)的数据结构,你可以把它想象成一个功能强大的“智能表格”。

在使用 pandas 之前,首先需要导入它:
# 导入 pandas 库并设置别名为 pd
# 为什么使用 pd 作为别名?这是数据科学社区的约定俗成,
# 几乎所有的 pandas 教程和文档都使用这个别名
import pandas as pd
import pandas as pd 这行代码相当于给 pandas 起了个简写别名 pd,这样你就不用每次都敲完整的 pandas 了。
💡 为什么使用别名? 在数据分析领域,pd 是 pandas 的约定俗成的别名,就像 np 是 numpy 的别名一样。使用这些标准别名可以让你的代码更易读,也方便与其他开发者交流。
注意: 在调用 pandas 里的函数时,记得用 . 来访问,比如 pd.read_csv()。如果你对这部分有疑问,可以回去复习一下本课程中“从本地文件调用函数”的那节内容!
加载中国二手车数据
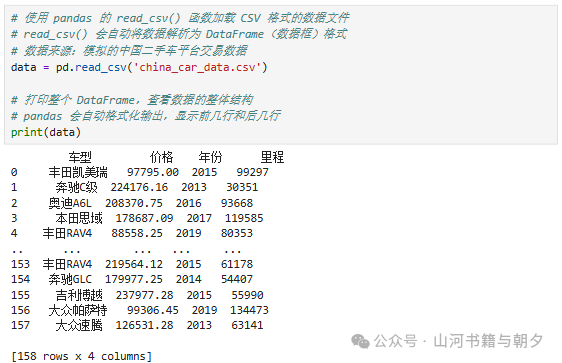
接下来,我们将使用 pandas 的 read_csv() 函数加载一份来自某二手车平台的交易数据。
这份数据包含以下字段:

让我们加载数据并查看其内容:
# 使用 pandas 的 read_csv() 函数加载 CSV 格式的数据文件
# read_csv() 会自动将数据解析为 DataFrame(数据框)格式
# 数据来源:模拟的中国二手车平台交易数据
data = pd.read_csv('china_car_data.csv')
# 打印整个 DataFrame,查看数据的整体结构
# pandas 会自动格式化输出,显示前几行和后几行
print(data)
数据筛选实战
在实际的数据分析工作中,我们经常需要根据特定条件筛选数据。比如,如何只显示售价超过 100,000 元的汽车呢?
这里我们将展示一个非常实用的技巧——借助 AI 助手来生成代码。当你不确定如何实现某个功能时,可以向 AI 描述你的需求,让它帮你生成代码。
让我们来请教一下 AI 吧!(此处 print_llm_response 是一个假设的辅助函数,用于模拟与AI对话的输出)
# 向 AI 描述我们的需求:筛选价格 >= 100000 元的车辆
# 注意:在提问时,清晰地描述数据结构和需求是获得准确答案的关键
print_llm_response("""
我已经用这段代码加载了一些数据:
data = pd.read_csv('china_car_data.csv')
print(data)
打印出来的数据包含:车型、价格、年份、里程 这几列。
请帮我筛选出价格大于或等于 100000 元的车辆。
""")

接下来,让我们运行 AI 生成的代码,根据价格筛选数据。
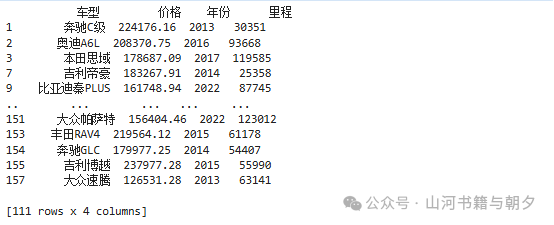
🔍 代码解析:data[data[“价格”] >= 100000] 这行代码使用了 布尔索引 技术。data[“价格”] >= 100000 会返回一个 True/False 的序列,然后用这个序列来筛选出符合条件的行。
# 使用布尔索引筛选价格 >= 100000 元的汽车
# 工作原理:
# 1. data["价格"] >= 100000 生成一个布尔序列(True/False)
# 2. 将这个布尔序列作为索引,筛选出 True 对应的行
# 这种语法简洁高效,是 pandas 数据筛选的核心技巧
print(data[data["价格"] >= 100000])
你也可以根据数据中的其他列进行筛选,比如按年份筛选。
💡 举一反三:布尔索引的语法非常灵活,你可以使用各种比较运算符(==、!=、>、<、>=、<=)来构建筛选条件。
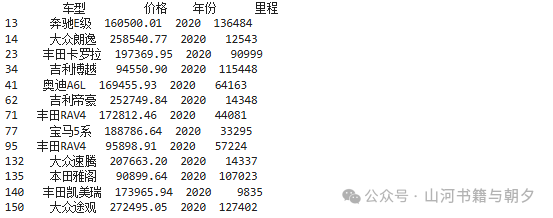
# 使用布尔索引筛选特定年份的数据
# 这里使用 == 运算符进行精确匹配
# 显示所有 2020 年出厂的二手车
print(data[data["年份"] == 2020])
描述性统计:计算中位数
pandas 内置了方便的统计工具,可以帮我们快速计算各种描述性统计指标。
📚 什么是中位数? 中位数(Median)是将一组数据从小到大排列后,位于中间位置的数值。与平均值相比,中位数不受极端值的影响,更能反映数据的“典型”水平。在分析房价、工资等容易出现极端值的数据时,中位数往往比平均值更有参考价值。
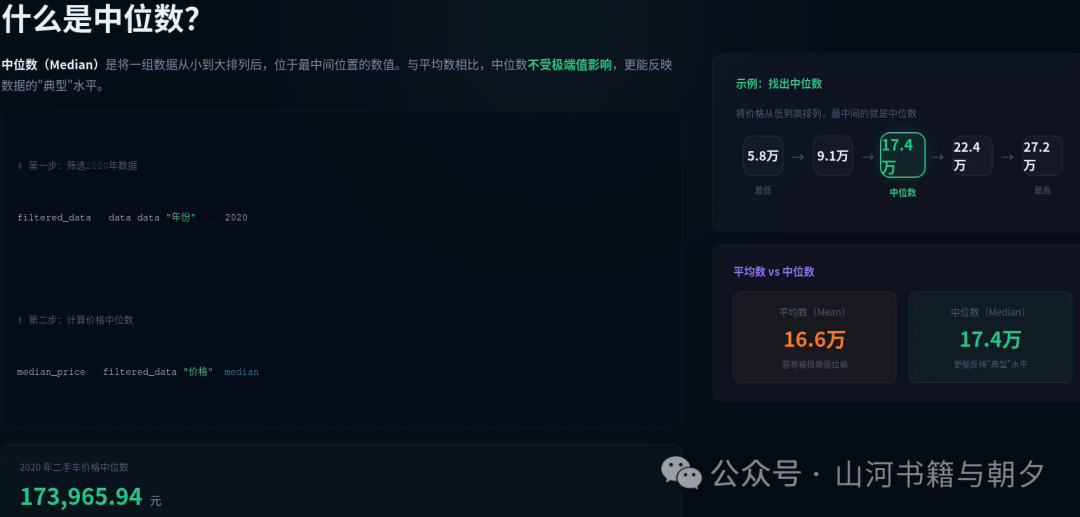
接下来,我们来计算 2020 年二手车的价格中位数:
# 第一步:筛选出 2020 年的数据子集
# 将筛选结果保存到变量 filtered_data 中,方便后续操作
filtered_data = data[data["年份"] == 2020]
# 第二步:计算价格列的中位数
# .median() 是 pandas Series 对象的内置方法
# 它会自动处理数据排序和中间值计算
median_price = filtered_data["价格"].median()
# 使用 f-string 格式化输出结果
# :.2f 表示保留两位小数
print(f"2020 年二手车的价格中位数为:{median_price:.2f} 元")

使用 matplotlib 绘制数据图表

matplotlib 是 Python 中最经典的数据可视化库,几乎是每个数据科学家和开发者的必备工具。它的名字来源于 MATLAB(一款商业数学软件)的绘图功能,因此语法风格与 MATLAB 非常相似。
🎨 为什么要做数据可视化? 人类大脑对图像的处理速度远快于文字和数字。通过将数据转化为图表,我们可以更直观地发现数据中的规律、趋势和异常值。
首先,让我们加载必要的工具:
# 导入 matplotlib 的 pyplot 模块,设置别名为 plt
# pyplot 提供了类似 MATLAB 的绘图接口,简单易用
import matplotlib.pyplot as plt
# 加载中文字体支持
# 这是一个自定义模块,用于解决 matplotlib 默认不支持中文显示的问题
# 如果不加载中文字体,图表中的中文会显示为方块
import chinese_font
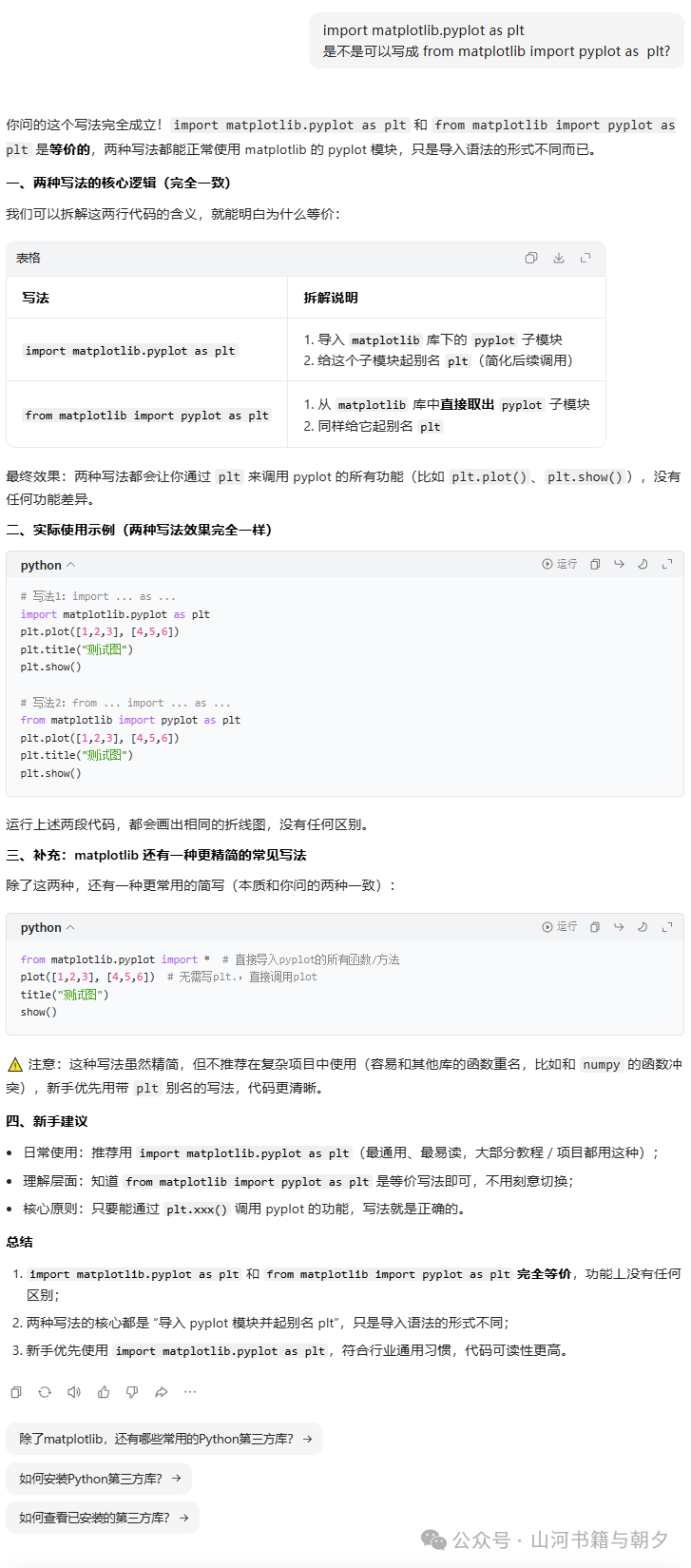
在使用时,你可能会有疑问:import matplotlib.pyplot as plt 是不是可以写成 from matplotlib import pyplot as plt?
答案是肯定的,这两种写法完全等价,功能上没有任何区别。下图为你详细解析了这两种导入方式:
探索关系:里程 vs. 价格
不用担心记住这些命令,你随时可以通过问 AI 来找到它们。这里用到了 import 命令的 as 形式来创建别名——这样你就可以用 plt 代替 matplotlib.pyplot,大大减少了输入量!
接下来,我们用 matplotlib.pyplot 来绘制汽车售价与行驶里程的关系图。
🤔 思考题:你觉得里程数和价格之间会是什么关系?是里程越高价格越低,还是没有明显关系?让我们通过散点图来验证你的猜测!
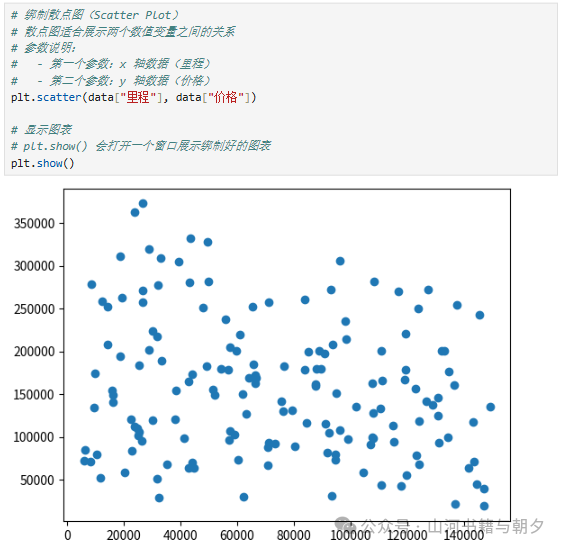
# 绘制散点图(Scatter Plot)
# 散点图适合展示两个数值变量之间的关系
# 参数说明:
# - 第一个参数:x 轴数据(里程)
# - 第二个参数:y 轴数据(价格)
plt.scatter(data["里程"], data["价格"])
# 显示图表
# plt.show() 会打开一个窗口展示绘制好的图表
plt.show()
定制图表样式
从上面的散点图可以看出,数据点分布比较分散,里程和价格之间似乎没有非常明显的线性关系。这可能是因为影响二手车价格的因素很多,里程只是其中之一。
matplotlib 提供了丰富的配置选项,方便你定制图表的样式,让图表更加专业、易读。接下来,让我们请 AI 帮忙添加标题和坐标轴标签:
# 向 AI 请求帮助:为图表添加标题和坐标轴标签
# 清晰地描述当前代码和期望的效果
print_llm_response("""
我用下面的代码绘制了一个散点图:
plt.scatter(data[“里程”], data[“价格”])
plt.show()
请帮我添加标题‘二手车里程与价格关系图’,并为 x 轴添加标签‘行驶里程(公里)’,为 y 轴添加标签‘价格(元)’。
""")

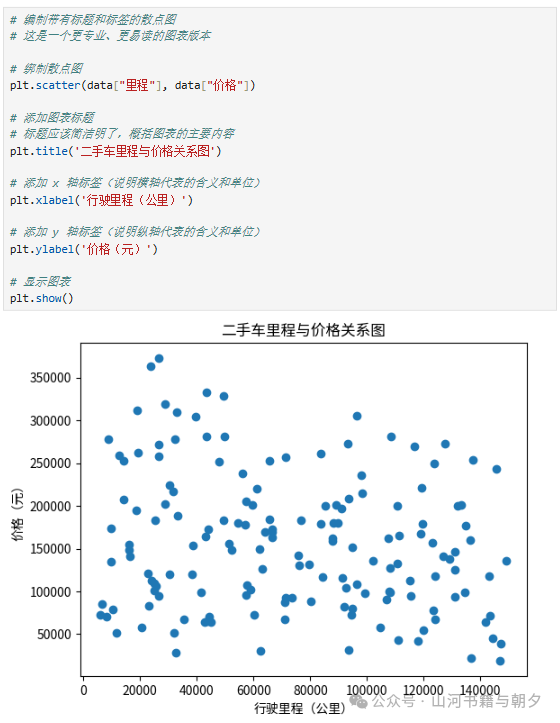
# 绘制带有标题和标签的散点图
# 这是一个更专业、更易读的图表版本
# 绘制散点图
plt.scatter(data["里程"], data["价格"])
# 添加图表标题
# 标题应该简洁明了,概括图表的主要内容
plt.title('二手车里程与价格关系图')
# 添加 x 轴标签(说明横轴代表的含义和单位)
plt.xlabel('行驶里程(公里)')
# 添加 y 轴标签(说明纵轴代表的含义和单位)
plt.ylabel('价格(元)')
# 显示图表
plt.show()
课后练习
太棒了!你已经学完了本课的核心内容。现在是时候动手实践了!
练习 1:数据筛选
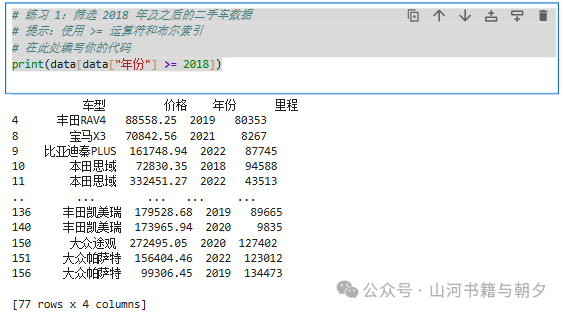
编写代码,筛选出 2018 年之后(包括 2018 年)的所有二手车数据。
💡 提示:使用 >= 运算符进行筛选。
# 练习 1:筛选 2018 年及之后的二手车数据
# 提示:使用 >= 运算符和布尔索引
# 在此处编写你的代码
print(data[data["年份"] >= 2018])
练习 2:数据可视化
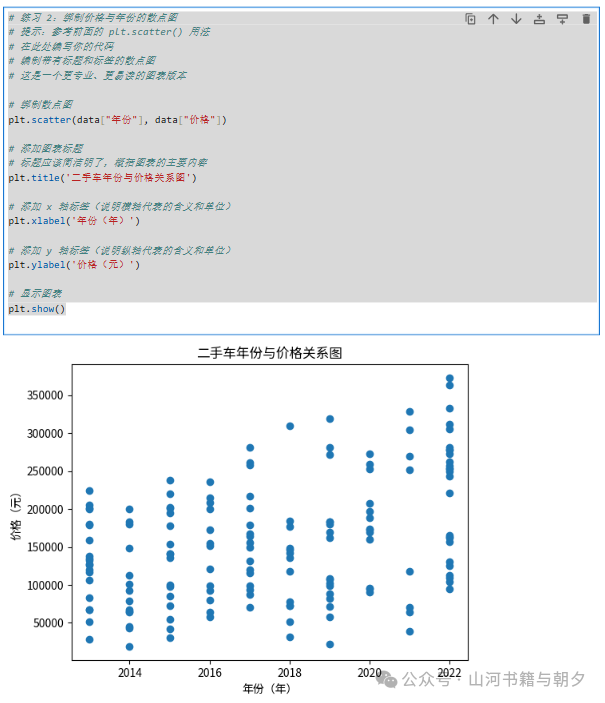
请编写代码,绘制价格与年份的散点图,观察年份对价格的影响。
💡 提示:参考前面绘制“里程 vs. 价格”散点图的代码,只需要修改 x 轴和 y 轴对应的列名即可。
# 练习 2:绘制价格与年份的散点图
# 提示:参考前面的 plt.scatter() 用法
# 在此处编写你的代码
# 这是一个更专业、更易读的图表版本
# 绘制散点图
plt.scatter(data["年份"], data["价格"])
# 添加图表标题
plt.title('二手车年份与价格关系图')
# 添加 x 轴标签
plt.xlabel('年份(年)')
# 添加 y 轴标签
plt.ylabel('价格(元)')
# 显示图表
plt.show()
挑战练习!
这是一道进阶挑战题,需要你综合运用今天学到的知识。
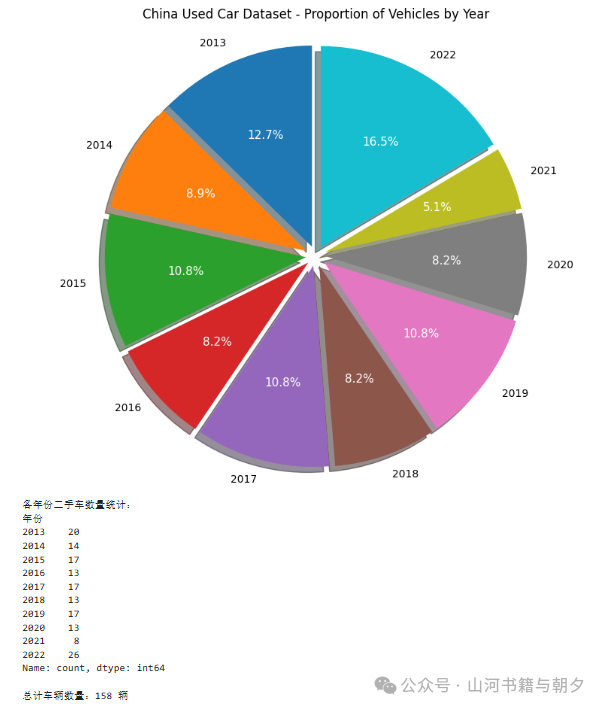
请让 AI 帮助你绘制一个饼图(Pie Chart),展示数据集中不同年份二手车的数量占比。
💡 提示:
- 使用
value_counts() 方法统计每个年份出现的次数
- 使用
plt.pie() 函数绘制饼图
- 可以向 AI 描述你的需求,让它帮你生成完整的代码
⚠️ 注意:饼图适合展示各部分占总体的比例关系,但当类别过多时,饼图会变得难以阅读。在实际工作中,要根据数据特点选择合适的图表类型。
(以下为示例代码,展示了解决中文显示和绘制饼图的一种方法)
# 挑战练习:绘制饼图展示不同年份二手车的数量占比
# 导入库
import pandas as pd
import matplotlib.pyplot as plt
# ========== 核心:解决中文显示方框问题 ==========
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei", "SimHei", "DejaVu Sans"] # Windows系统字体
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示方框
# ==============================================
# 加载数据
data = pd.read_csv('china_car_data.csv')
# 统计年份数量
year_counts = data["年份"].value_counts().sort_index()
# 绘制饼图
plt.figure(figsize=(10, 8))
patches, texts, autotexts = plt.pie(
year_counts.values,
labels=year_counts.index,
autopct="%1.1f%%",
startangle=90,
explode=[0.05]*len(year_counts),
shadow=True
)
# 美化文字
for autotext in autotexts:
autotext.set_color("white")
autotext.set_fontsize(11)
# 设置标题
plt.title('各年份二手车数量占比')
plt.axis("equal")
plt.show()
# 打印统计
print("各年份二手车数量统计:")
print(year_counts)
print(f"\n总计车辆数量:{year_counts.sum()} 辆")
本课总结
恭喜你完成了本课的学习!让我们回顾一下今天掌握的核心知识点:
关键知识点回顾
| 知识模块 |
核心内容 |
常用方法/函数 |
| pandas 数据加载 |
从 CSV 文件读取数据到 DataFrame |
pd.read_csv() |
| 数据筛选 |
使用布尔索引过滤数据 |
data[data[“列名”] >= 值] |
| 描述性统计 |
计算数据的统计指标 |
.median(), .mean(), .count() |
| matplotlib 可视化 |
绘制散点图展示数据关系 |
plt.scatter(), plt.show() |
| 图表定制 |
添加标题、坐标轴标签 |
plt.title(), plt.xlabel(), plt.ylabel() |
核心概念解析
DataFrame(数据框):pandas 中最核心的数据结构,可以理解为一个“智能表格”。它不仅能存储数据,还内置了丰富的数据处理方法。
布尔索引:通过条件表达式(如 data[“价格”] >= 100000)生成一个 True/False 的序列,再用这个序列筛选出符合条件的行。这是数据分析中最常用的筛选技巧。
散点图(Scatter Plot):用于展示两个变量之间关系的图表类型。每个数据点在图上的位置由其在两个变量上的值决定,非常适合探索变量间的相关性。
延伸学习建议
- 深入 pandas:尝试学习
groupby() 分组聚合、merge() 数据合并等高级功能。
- 丰富可视化:探索
matplotlib 的柱状图、折线图、饼图等更多图表类型。
- 实战练习:尝试用今天学到的技能分析其他数据集(如天气数据、股票数据),并借助 AI 辅助解决更复杂的问题。
🎉 你做得很棒! 数据分析是一项需要不断练习的技能。建议多动手实践,你会进步得越来越快!我们后续的课程将在 云栈社区 持续更新,欢迎关注更多实战教程。
 发表于 2026-2-23 00:29:35
|
查看: 190|
回复: 0
发表于 2026-2-23 00:29:35
|
查看: 190|
回复: 0
