上下文图谱是企业AI实现自主决策的必要基石吗?答案是肯定的。但仅有结构化的数据表示还不够——统一上下文层(UCL) 让上下文图谱真正发挥作用,通过构建能够消费、学习并行动的系统。这才是智能体迈向真正自主的关键。
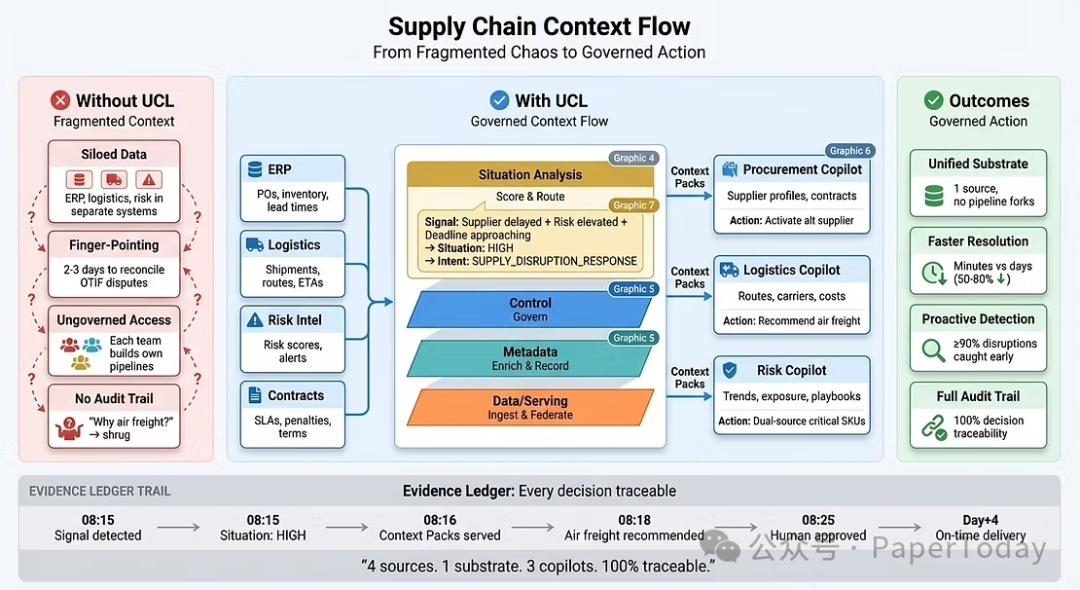
一张图足以揭示问题与解决方案的核心。当供应商延迟、风险评分飙升、截止日期迫近时:
- 没有UCL:数据孤岛林立,需要2-3天来协调争议,各团队构建无治理的流水线,且缺乏审计追踪。
- 有UCL:四个数据源融合为统一基座,情境分析对信号进行评分与路由,三个Copilot接收受管控的上下文包,证据账本捕获从08:15信号检测到第4天准时交付的每一个决策。
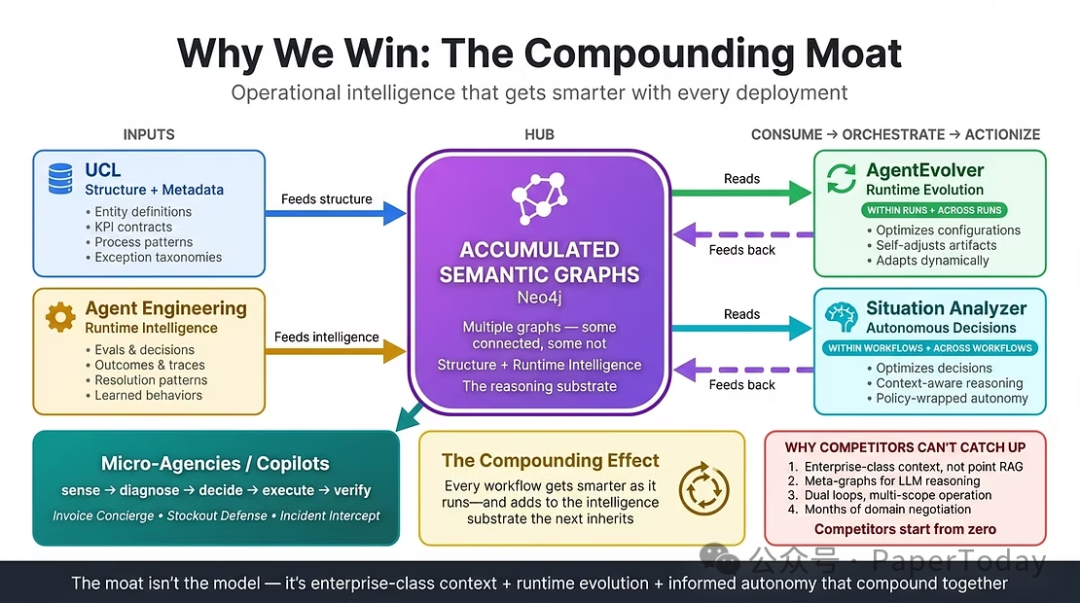
我们为何能构建竞争优势?关键在于复合护城河——UCL提供结构,智能体工程贡献运行时智能,二者通过累积的语义图谱形成读写闭环。
执行摘要
企业级AI正在经历大规模失败。S&P Global Market Intelligence的数据显示,2025年有42%的企业放弃了大部分AI项目,这一比例较一年前的17%大幅上升。行业分析进一步指出,87%的企业RAG实现未能达到预期的投资回报率目标。根本原因在于,智能体仍在碎片化地处理上下文,并在缺乏治理契约的情况下回写业务系统。
失败点并非模型能力不足,基础模型已达到相当的复杂程度。真正的失败点在于上下文——它处于碎片化、缺乏治理的状态,并被视作副产品而非需要工程化的基础设施。
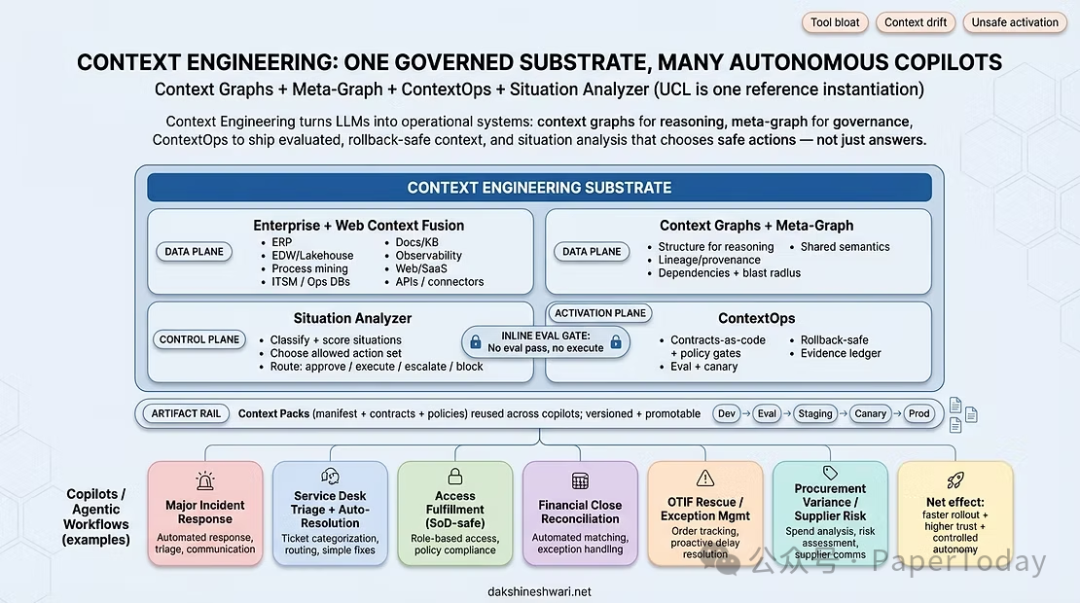
上下文图谱 作为一个理论方向备受关注,它旨在通过结构化的企业知识表示,使AI能够推理而非仅仅检索。然而,上下文图谱作为一种数据结构是必要的,但并不充分。真正的难题依然存在:
- 智能体决策:智能体必须能分析情境并做出决策,而非机械执行脚本。这需要系统能够消费图谱:遍历、推理、评估选项并确定响应。缺乏这一点,智能体无法实现真正自主。
- 智能体生产化:部署必须在运行时持续演进。这需要系统能够操作图谱:创建、合并、修改、连接实体,并在每次执行中积累智能。否则,智能体发布后便会僵化,性能在生产中衰减。
- 企业集成:企业在ERP、EDW、流程挖掘、ITSM等领域已有数十年投资,这些系统蕴含智能体所需的关键信号与机构知识。任何解决方案都必须集成而非忽视这些现有资产。
简单地将元数据导入Neo4j无法让智能体工作。你需要消费结构(读取系统)、变异操作(回写系统)和受控激活(安全行动系统)。这三者共同构成了真正自主的智能体与脚本化Copilot的本质区别。
本报告提出的统一上下文层,正是这样一种领先的企业级上下文工程架构——它将上下文图谱可操作化,并使真正自主的智能体能够在企业治理框架内可靠运行。
1. 上下文工程:正式学科
1.1 定义与范围
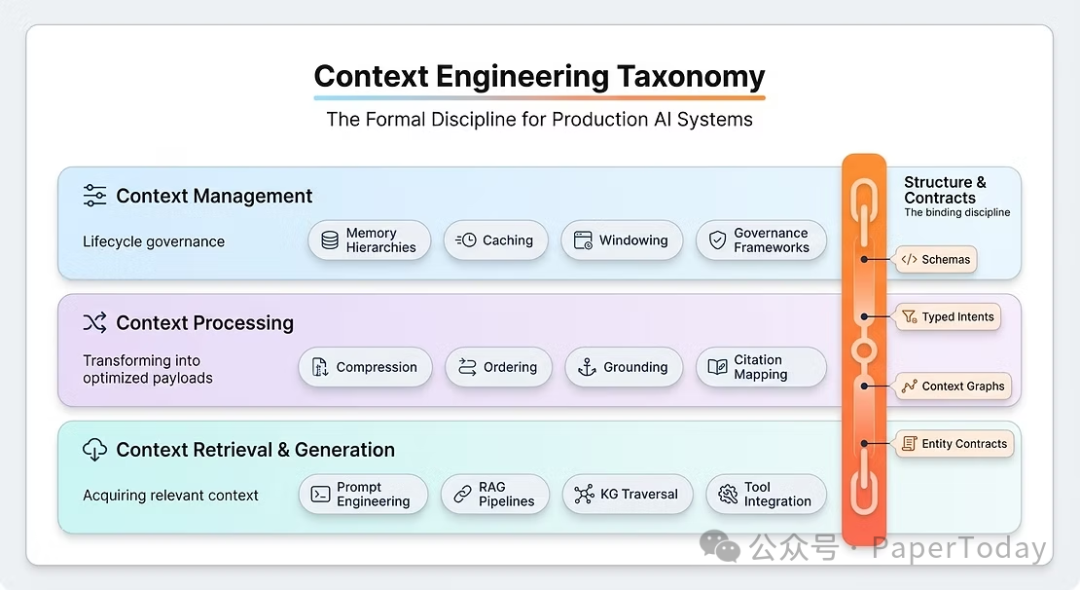
上下文工程是对推理时提供给大语言模型的所有信息进行系统性设计、优化和治理的学科。该定义基于对1400多篇研究论文的综述,正式将上下文工程确立为超越简单提示设计的独立学科。
其范围涵盖:系统指令与提示、对话历史与记忆、检索到的信息、工具定义与模式、结构化输出约束以及治理机制。
一个关键洞察是:LLM的功能类似于一类新的操作系统。模型充当处理器,上下文窗口则如同工作内存。上下文工程的核心,便是管理在每个推理步骤中占据该窗口的内容。
1.2 理解-生成不对称性
研究发现了一个关键不对称性:模型在理解复杂上下文方面表现出卓越能力,但在生成同样复杂的输出时却困难重重。在GAIA基准测试中,人类受访者成功率高达92%,而配备了插件的GPT-4仅达到约15%。这揭示的是合成失败,而非检索失败。
这意味着,仅仅提供更多上下文是不够的。上下文的架构——如何被结构化、排序和呈现——直接决定了模型能否将理解转化为有效的自主行动。
2. 行业中的架构方法
目前已有四种架构框架涌现,各自解决不同问题,但也存在阻碍真正自主智能体运行的特定局限。
2.1 模型上下文协议:集成标准
Anthropic的MCP旨在解决N×M集成问题,建立了将AI应用与数据源解耦的通用协议。其生态系统包含超过75个生产级连接器,并于2025年12月捐赠给Linux基金会的Agentic AI基金会。
局限性:MCP解决了连接问题,但未触及治理。它实现了集成,却不强制执行语义一致性、情境分析或受控激活。智能体可以连接数据,但无法对其进行自主推理。
2.2 Google ADK:上下文作为编译视图
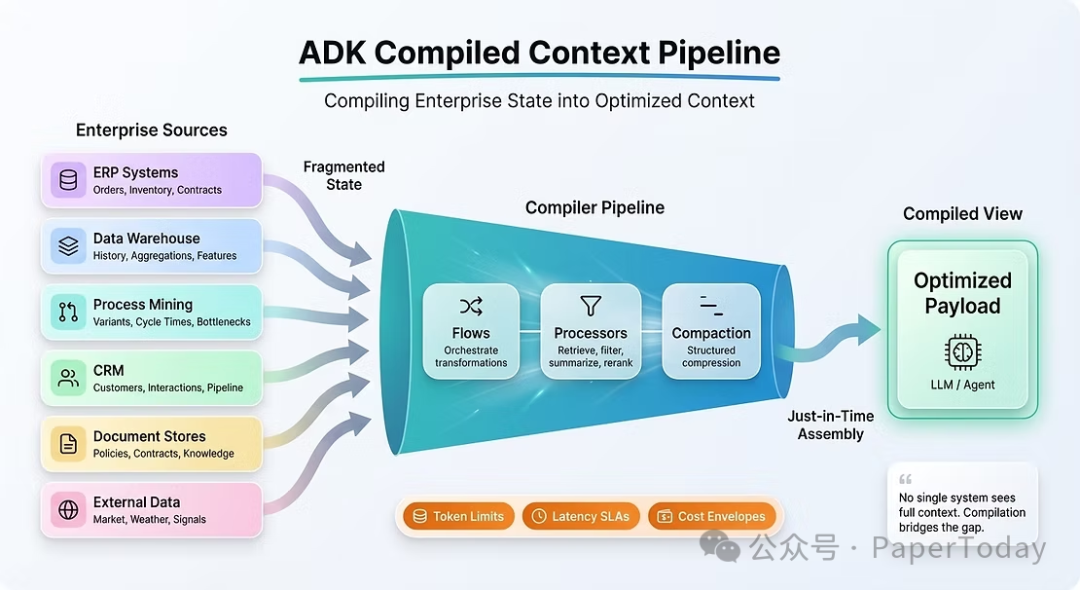
Google的智能体开发工具包将上下文框架为“编译视图”——遵循“源 → 编译器流水线 → 编译视图”的范式。它旨在解决成本/延迟螺旋上升、信号衰减和推理漂移三个核心压力。
局限性:ADK提供了编译规范,但未能解决流程-技术融合、多消费支持或受控激活。智能体获得了更优的上下文,但其行为仍被限制在预定的路径上。
2.3 智能体上下文工程:自改进的Playbook
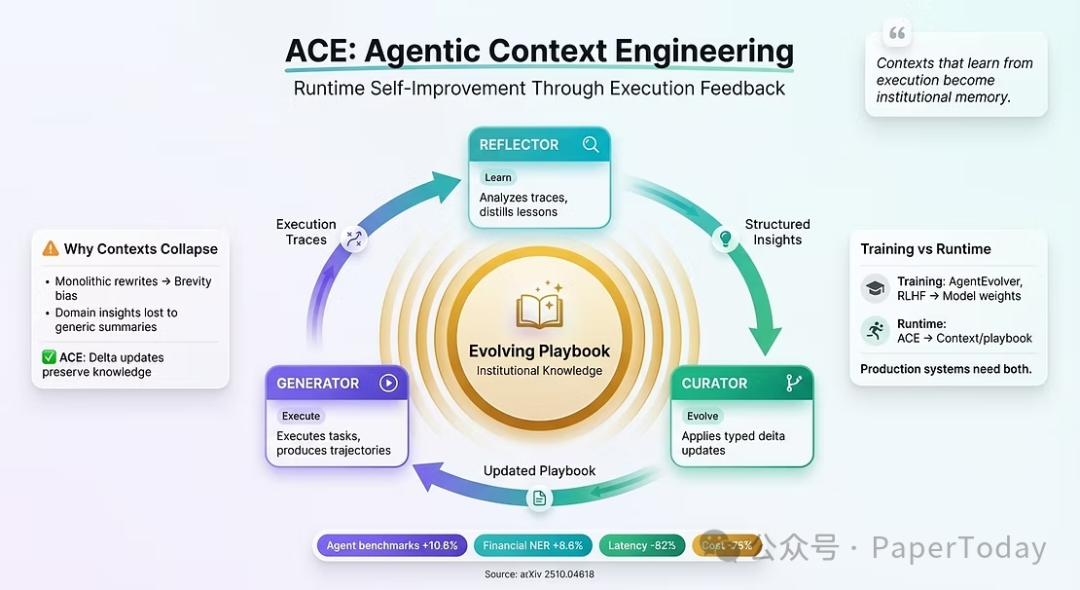
ACE框架将上下文视为一个不断演进的“Playbook”,通过“生成器 → 反射器 → 策展人”的循环实现自改进。该框架在智能体基准测试中实现了+10.6%的改进,并将适应延迟降低了82-91%。
局限性:ACE实现了自改进,但需要一个企业基座作为其改进的对象。如果没有来自企业系统的受控上下文,Playbook将无从学起?智能体只能在孤立中改进,与企业现实脱节。
2.4 上下文图谱:必要但不充分
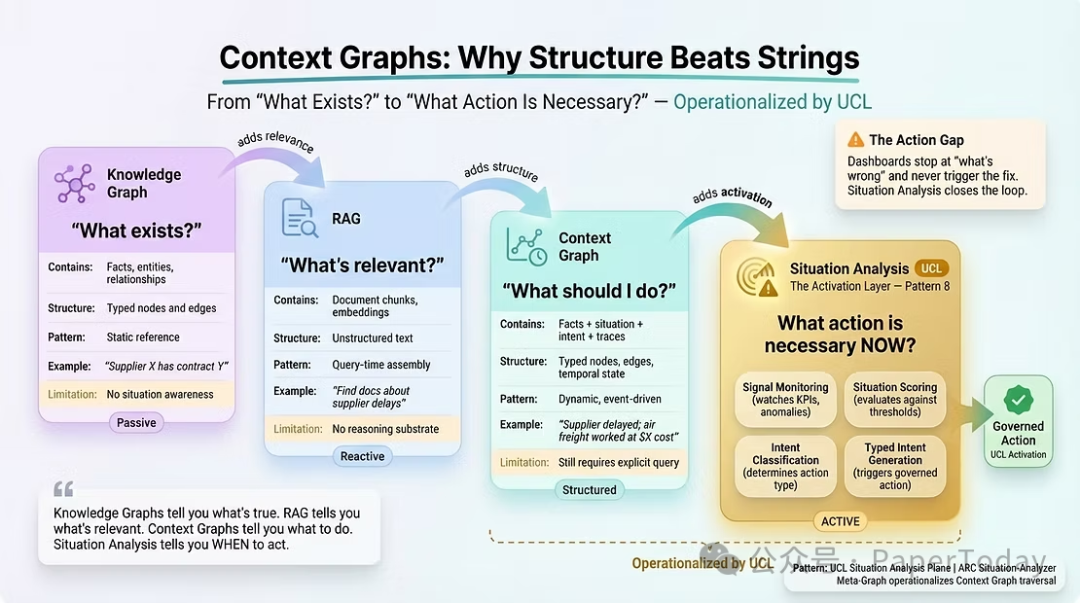
“上下文图谱”理论识别了一个巨大的机遇:即不仅捕获状态,还捕获决策痕迹的图谱——为什么做出决策、批准了哪些例外、存在哪些先例。
这个方向极具吸引力,但上下文图谱作为一种数据结构,并未解决真正的工程难题:
- 智能体决策问题:智能体必须分析情境并做出决策,而非遵循脚本。存储在Neo4j中的数据本身做不到这一点。你需要一个情境分析器——一个能够消费图谱并产生决策的系统。没有它,智能体无法处理新情况,只能将问题升级给人类,人类依旧是瓶颈。
- 智能体生产化问题:部署必须在运行时改进。图数据库只存储数据。你需要一个运行时演进系统来回写学习——创建新模式、合并实体、变更关系、连接决策痕迹。没有它,智能体在部署后便会僵化,性能衰减。
- 企业集成问题:任何忽视现有IT基础设施的上下文工程方法都错过了一个基本现实。企业在ERP、EDW等领域投资了数十年,这些系统包含智能体所需的关键信号。任何不集成它们的架构都无法捕获企业级的协同效应。
- 跨图谱发现问题:即使上下文图谱存储了多个语义域,图数据库本身也不会自动发现涌现的跨域关系。例如,决策历史图谱记录“127个新加坡登录被标记为误报”,而威胁情报图谱显示“新加坡IP范围的凭证填充攻击激增340%”。单独看,两者都无异常。但一个能定期跨图谱边界进行关联分析的系统会发现:在当前威胁背景下,之前的误报校准可能是危险的错误。这种发现不仅需要图数据库,更需要一个所有域共享实体定义和可遍历元图的受控基座——而这正是UCL所提供的。
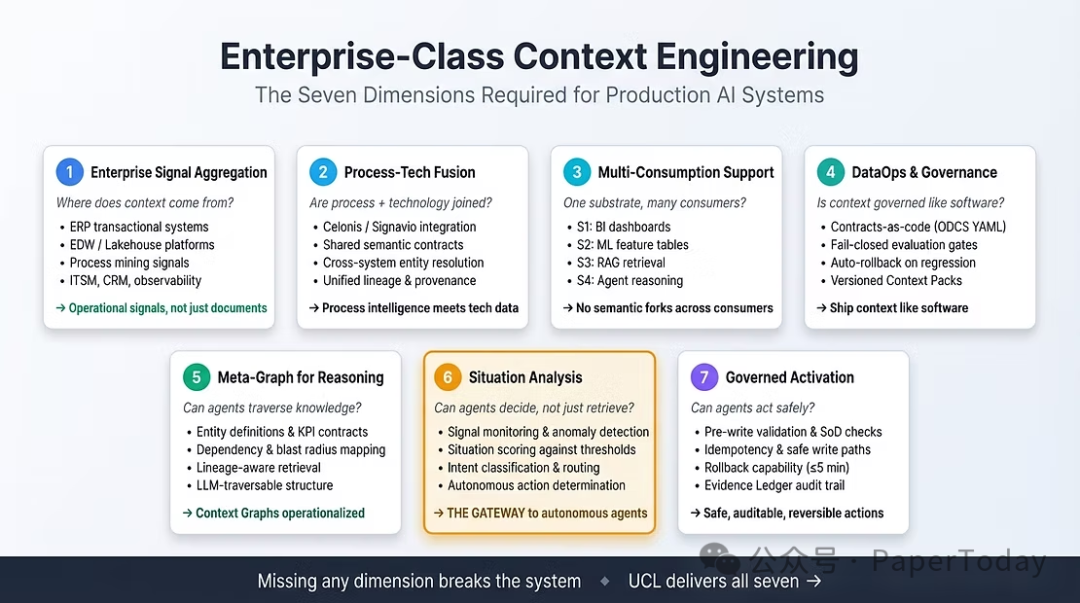
3. 什么使上下文工程成为“企业级”
企业级上下文工程需要满足七个维度,缺失其中任何一个,智能体都无法在生产中可靠且自主地运行。

4. UCL:企业级上下文工程的领先架构
统一上下文层交付了上述全部七个维度,解决了单独使用上下文图谱无法解决的难题,并使真正自主的智能体能在企业治理内运行。
4.1 六大范式转变
- 上下文成为受管控的产品:上下文包带有版本和评估门控。
- 异构源统一:流程智能、ERP、网络信号通过通用语义层汇聚。
- 元数据成为推理基座:元图是可操作化的上下文图谱。
- 一个基座服务所有消费模型:同时支持BI、ML、RAG、智能体推理和激活。
- 激活关闭受控循环:具备预写入验证、职责分离、回滚和证据账本。
- 情境分析实现自主行动:智能体基于上下文推理、分析情境并做出决策,而非遵循脚本。这是实现智能体真正自主的核心。
4.2 八大模式
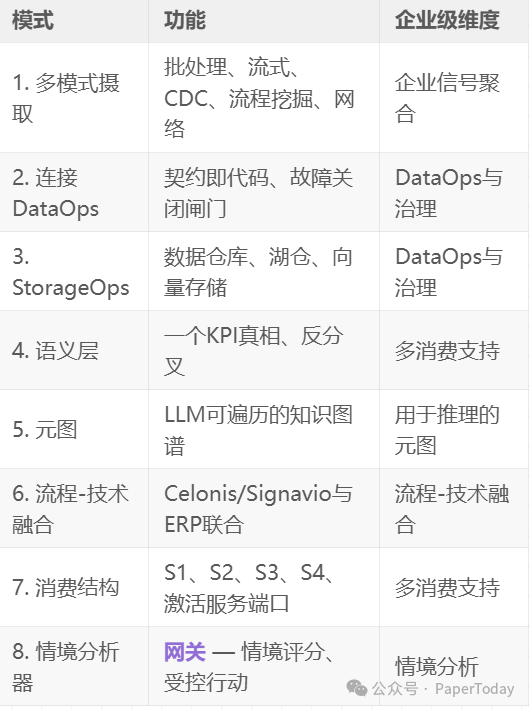
这些模式共同创建了受控基座。但基座本身并非最终状态。UCL的变革性在于,这个基座如何馈送并启用复合架构,而该架构又如何赋能真正自主的智能体。
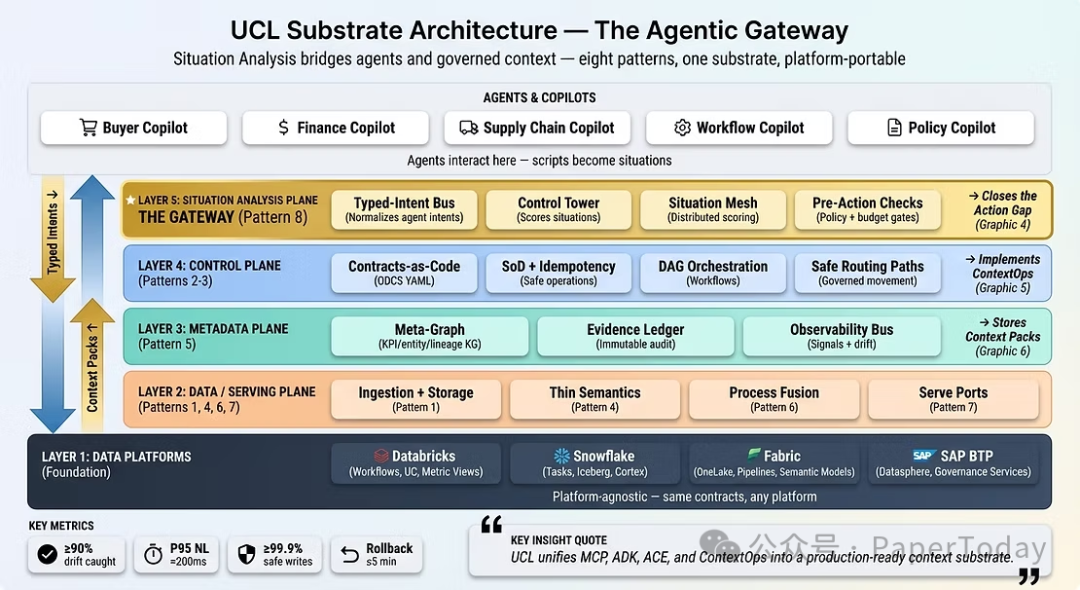
5. 行业用例:UCL vs. 替代方案
以下三个场景清晰地展示了为什么企业级上下文工程需要UCL,以及为什么其他替代方案无法使真正自主的智能体成为可能。
5.1 发票例外礼宾(寻源到付款)
场景:发票被冻结,三方匹配失败。需要拉取合同条款、识别根本原因、决定解决方案、执行并捕获证据。
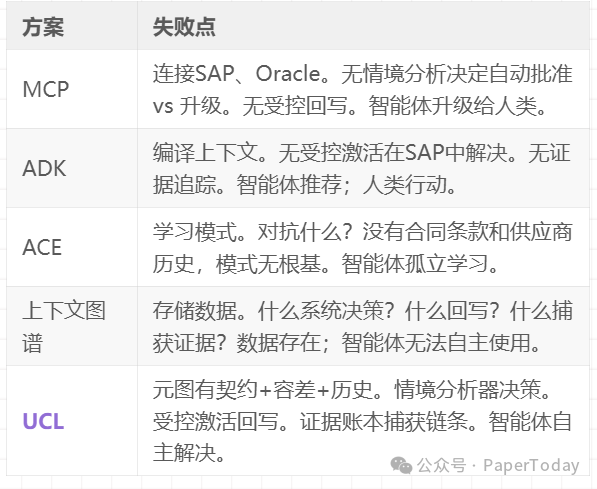
UCL结果:付款周期缩短11天,释放2700万美元营运资金。实现自主解决——仅将例外情况升级,其余流程自动运行。
5.2 OTIF恢复(供应链)
场景:订单准时足量交付率下降。需要融合ERP与流程挖掘数据、识别根本原因、决定补救措施、执行并证明有效性。
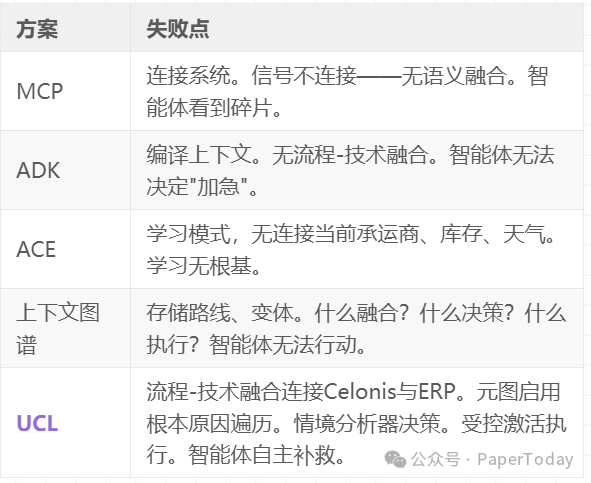
UCL结果:根本原因分析当日完成,OTIF从87%提升至96%。在政策护栏内实现自主补救。
5.3 重大事件拦截(IT运维)
场景:服务器延迟在凌晨2点飙升。需要与最近的变更关联、评估爆炸半径、决定补救措施、执行并捕获证据。
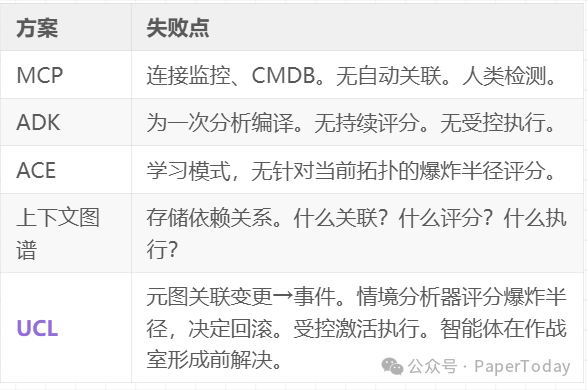
UCL结果:平均修复时间以分钟计而非小时,事件作战室从未形成。实现自主事件解决。
5.4 能力差距
上述用例揭示了一个一致模式:替代方案各自提供了部分能力,但没有一个能交付支撑真正自主智能体所需的完整系统。第3节中的七个企业级维度为此提供了客观的评估框架。

矩阵清晰揭示了差距:
- MCP 提供连接性但无其他——智能体可访问数据但无法推理、决策或安全行动。
- ADK 增加了编译和部分治理,但缺乏流程融合、情境分析和受控激活——智能体推荐但不行动。
- ACE 实现了学习,但缺乏可对抗学习的企业基座——智能体孤立改进。
- 上下文图谱 提供了数据结构,但缺乏消费、变异或激活系统——数据存在但智能体无法使用。
- UCL 交付了全部七个维度——是唯一能够实现推理、决策、行动和学习型智能体的架构。
关键洞察:大家手里都只有拼图碎片。只有UCL提供了能够产生复合效应的连接系统。这并非一个可以通过增量添加功能来弥补的问题——差距是架构性的。部分解决方案无法被修补成完整方案,因为它们缺乏基础的基座。
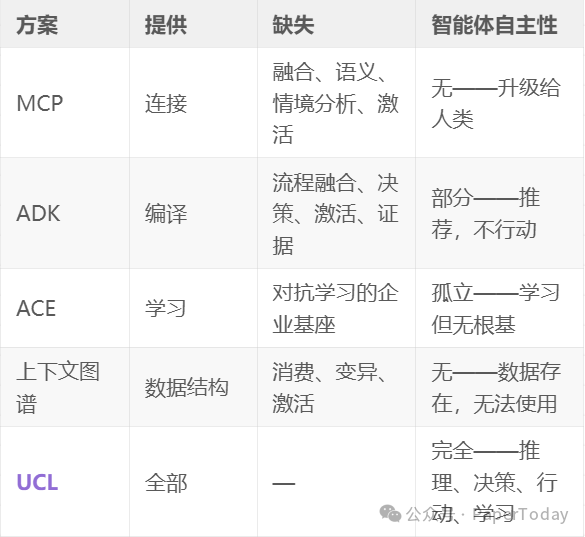
这些用例和能力矩阵论证了核心观点:企业级上下文工程不仅是关于获得更好的上下文,更是关于赋能能够在企业治理框架内自主运行的真正智能体。

结论
UCL是将上下文图谱可操作化,并实现企业级上下文工程的领先架构。通过其八大核心模式——并以模式8(情境分析)作为网关——UCL提供了:
- 将现有企业投资统一为受控的上下文源。
- 由结构和智能共同哺育的累积语义图谱。
- 两个复合智能循环:在单次运行中变得更智能,在跨次运行中继承智能。
- 具备回滚能力和证据追踪的受控激活,从而形成闭环。
- 最终,实现能够推理、决策、行动和学习的真正自主智能体。
对于希望深入探讨后端架构与智能体系统融合实践的技术同仁,欢迎在技术社区进行更多交流,例如在 云栈社区 的相关板块分享你的见解。
https://www.dakshineshwari.net/post/enterprise-class-context-engineering-from-context-graphs-to-production-ai
 发表于 2026-2-23 01:30:44
|
查看: 142|
回复: 0
发表于 2026-2-23 01:30:44
|
查看: 142|
回复: 0
