毫秒级响应的大模型对话,如今已经不再是设想。最近,加拿大初创公司 Taalas 推出了一款名为 HC1 的特殊芯片,其核心理念是将整个 AI模型 的权重直接“固化”到硅片之中。
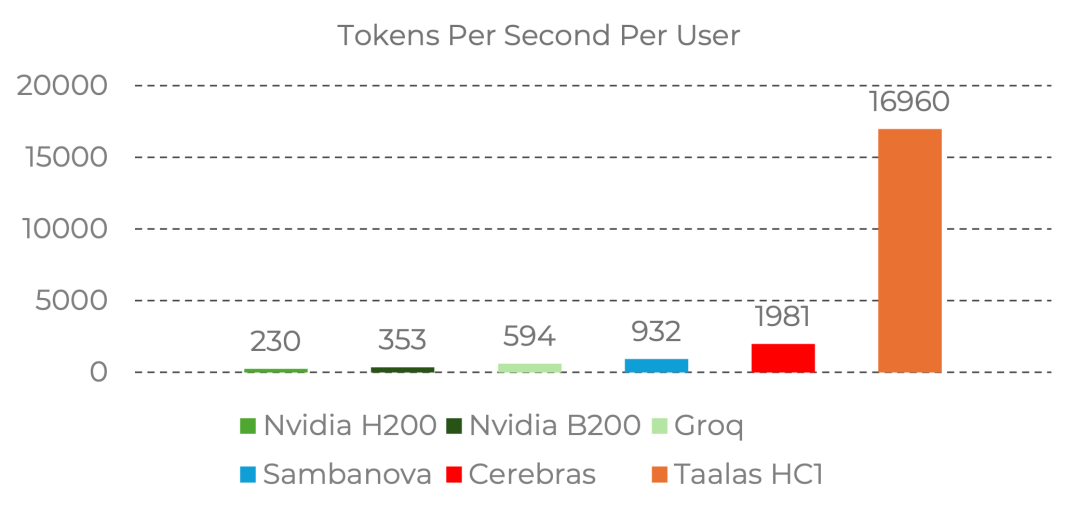
在运行 Llama 3.1 8B 模型时,其实测吞吐量高达每秒 16960个token。相比之下,我们日常使用的 ChatGPT 服务,每秒大约能生成110个token;而 Claude Opus 大约在每秒50个token左右。这其中的性能差距相当明显。
为了体验其速度,我们访问了其演示平台 https://chatjimmy.ai/。在这个平台上,我们向模型提问,得到的回复确实不再是秒级,而是百毫秒甚至毫秒级别。例如,当我们提问“想要抓取 X 上某个大 V 的发帖列表,有哪些方式,如果用代码实现的话,最好给我完整代码”时,模型在 53毫秒 后就给出了包含代码的完整回答。
芯片即模型:一种全新的AI推理思路
要理解HC1芯片的突破之处,需要先回顾一下传统 AI推理 面临的核心瓶颈。
无论是使用 Claude、GPT 还是 Gemini,其模型参数(权重)通常都存储在外部动态内存(DRAM)中。每次进行推理计算时,数据都需要从内存搬运到GPU的计算单元,计算完成后再将结果搬回。这个频繁的数据搬运过程带来了巨大的延迟和能耗开销,即经典的“冯·诺依曼瓶颈”。
业界的常规解法是不断提升内存带宽,例如从HBM、HBM2e到HBM3e,不断拓宽数据传输的“高速公路”。NVIDIA的H200就凭借141GB的HBM3e内存实现了4.8 TB/s的超高带宽。Taalas则采用了一种更激进的思路:与其不断拓宽公路,不如彻底消除搬运的需求。
HC1芯片直接将整个模型的权重硬编码(Hard-encode) 到芯片内部的掩膜只读存储器(mask-ROM)中。每个权重位都用一个晶体管来实现存储和乘法运算,再配合SRAM来处理动态数据(例如KV缓存和LoRA微调参数),从而从根本上消除了访问外部内存的需要。
从部署形式上看,HC1依然是一张标准的PCIe卡,可以插入任何支持PCIe的服务器中运行。

性能表现与核心特点
-
惊人的速度优势
在运行Llama 3.1 8B模型时,HC1的吞吐量远超其他专用硬件。根据官方数据,它比 Cerebras 的方案快约9倍,比 Groq 快约28倍。Taalas甚至宣称其速度比 NVIDIA H200 快约100倍,但需要注意的是,这个对比条件不同:H200的12000 tokens/s成绩是在运行更大模型且进行批处理(batch processing)时得出的。
-
延迟带来质变
如果说吞吐量的数字差异还不够直观,那么延迟的降低则是用户能直接感知的体验飞跃。从“等待0.5秒”到“几乎无延迟”的转变,可能会彻底改变人机交互的模式,未来的瓶颈可能将只是人类大脑处理信息的速度。
-
并非“智能水平”的直接比较
HC1速度快的一个重要原因是它运行的是一个相对较小的模型(Llama 3.1 8B)。像 GPT-4o 这样的大模型,其参数量要庞大数十倍,推理过程也复杂得多,因此单token生成速度较慢。这就像比较F1赛车和重型卡车的速度,前者快是因为其设计目标不同。
-
预示一个重要趋势
HC1的成功验证了一条技术路径:通过专用硬件将模型固化,可以换来极致的推理性能。这引发了一个有趣的设想:如果将 Claude 或 GPT 级别的超大模型也“烧录”进专用芯片呢?理论上速度提升将是巨大的。这正是Taalas HC2路线图的方向——该公司计划在2026年底支持万亿参数级别的模型。届时,“秒级回复的GPT-4级AI”或许将成为现实。
技术背后的权衡与局限性
尽管在吞吐量、能效比上表现卓越,但HC1的这种设计也带来了一些固有的限制:
- 模型固化,无法在线升级:模型被硬编码在芯片中,意味着无法通过OTA(空中下载技术)方式进行模型升级。要更换模型,就需要更换芯片。
- 激进的量化策略:为了将模型塞进芯片,HC1采用了3-bit和6-bit等激进的量化技术。量化就像压缩图片,虽然体积变小了,但不可避免地会损失一些精度和细节。
- 仅限推理,无法训练:这种架构专为推理优化,不具备训练大模型的能力。训练任务仍然是 NVIDIA GPU 等通用计算平台的天下。
结语
综合来看,HC1并不会在短期内取代 Claude、GPT 这类通用大模型服务,也不会撼动 NVIDIA 在AI训练领域的统治地位。但它清晰地揭示了一点:当前 AI推理 的性能远未触及天花板。在特定的应用场景下,通过牺牲一定的通用性和灵活性,专用硬件能够将推理速度推向一个前所未有的新高度,这为边缘计算、实时交互等对延迟极端敏感的领域提供了新的解决方案。想了解更多软硬件结合的前沿技术动态,欢迎来 云栈社区 交流探讨。 |  发表于 2026-2-24 04:29:02
|
查看: 247|
回复: 0
发表于 2026-2-24 04:29:02
|
查看: 247|
回复: 0
