
在设计高效的随机优化器时,我们总在权衡两个核心目标:在确定性区域保持精确的更新方向,以及有效适应随机梯度带来的扰动。
长久以来,Adam及其变体AdamW凭借坐标级别的自适应矩估计,显著提升了训练稳定性,已成为大型语言模型(LLM)预训练的事实标准。然而,这类方法通常将神经网络的参数视为一个展平的向量进行处理,忽略了权重矩阵自身的内在结构信息。
近期,在LLM训练中崭露头角的Muon优化器另辟蹊径,它利用矩阵结构,通过正交化动量来更新参数。但在随机优化的实际场景中,矩阵正交化本质上是一个无界操作,这很容易放大原始动量矩阵中的噪声,导致训练过程不稳定,并且对超参数的选择变得异常敏感。
那么,能否找到一种方法,既能利用矩阵的结构化优势,又能保有Adam家族的自适应鲁棒性呢?
来自加州大学洛杉矶分校(UCLA)数学系的研究团队在其最新论文《Adam Improves Muon》中,给出了肯定的答案。他们提出了NAMO及NAMO-D两种新型优化器,首次在理论层面将正交化更新方向与Adam风格的噪声自适应机制进行了严谨融合。

论文标题:
Adam Improves Muon: Adaptive Moment Estimation with Orthogonalized Momentum
论文链接:
https://arxiv.org/pdf/2602.17080
代码仓库:
https://github.com/minxin-zhg/namo

核心机制
要理解NAMO的巧妙之处,首先得回顾Muon的核心逻辑。给定动量矩阵 M_t,Muon通过计算其近似正交化矩阵 O_t = Orth(M_t) 来进行参数更新。为了避开计算开销巨大的精确正交化,工程上通常采用高效的Newton-Schulz迭代来近似求解。
NAMO:基于范数的单一标量自适应
NAMO在Muon的基础上,引入了一个关键的自适应标量。它维护了随机梯度矩阵的Frobenius范数平方的二阶矩估计。在对一阶矩 M_t 和二阶矩 v_t 进行偏差校正,得到 M̂_t 和 v̂_t 后,NAMO计算一个自适应步长标量 α_t:
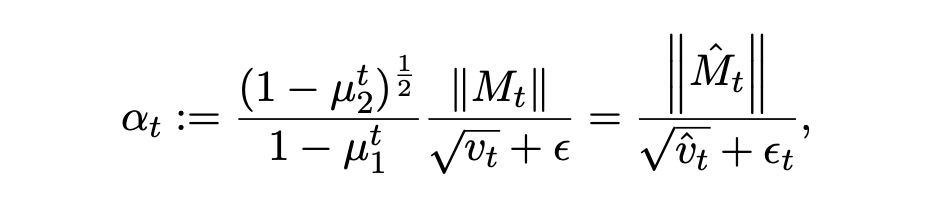
Algorithm 1 NAMO: Norm-Based Adaptive Moment Estimation with Orthogonalized Momentum
Require: Learning rate η, momentum μ1,μ2 ∈ [0,1), batch size b, ε > 0
1: Initialize Θ0 ∈ ℝm×n, M0 = 0, v0 = 0
2: for t = 1,2,…,T do
3: Sample a minibatch of size b and compute stochastic gradient Gt = ∇Lt(Θt−1)
4: Mt ← μ1Mt−1 + (1 − μ1)Gt
5: vt ← μ2vt−1 + (1 − μ2)‖Gt‖²_F
6: Ot ← Orth(Mt)
7: αt ← √(1−μ²₂)/(1−μ²₁) · ‖Mt‖_F / (√vt+ε)
8: Update parameters Θt ← Θt−1 − ηαtOt
9: end for
10: return ΘT
图1. NAMO算法伪代码,通过标量自适应步长缩放正交化动量
在LLM预训练中,解耦权重衰减至关重要。NAMO将计算得到的自适应缩放因子直接作用于正交化动量与权重衰减项上。其完整的参数更新规则为:
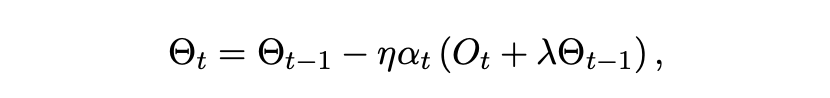
当随机梯度的噪声较大,或者优化过程接近驻点时,α_t 的值会相应减小,从而抑制更新幅度,促进稳定收敛。这种标量缩放严格保留了更新方向的正交性,且引入的额外计算成本仅为 O(1),几乎不增加显存开销。
NAMO-D:神经元级别的细粒度自适应
NAMO-D则放弃了单一标量,转而采用更细粒度的列级缩放策略,为网络中的每个神经元(对应权重矩阵的每一列)分配独立的自适应步长。这种设计与神经网络中常见的近块对角Hessian矩阵结构高度契合。
算法维护随机梯度每一列范数平方的二阶矩估计,并按下式计算列缩放向量 d_t(使用逐元素除法):
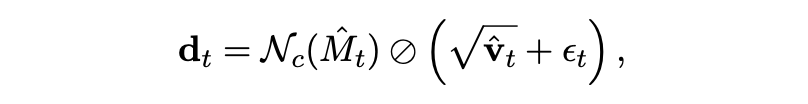
为了防止神经元级别的缩放导致更新方向的条件数恶化,NAMO-D引入了一个截断(Clamping)机制,将每个神经元的自适应步长向其均值 d̃_t 靠拢:
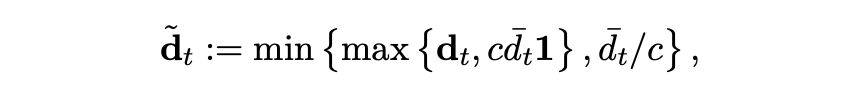
这里的 c 是一个截断常数。构造出对角矩阵 D_t = diag(d̃_t) 后,结合解耦权重衰减的NAMO-D参数更新公式为:
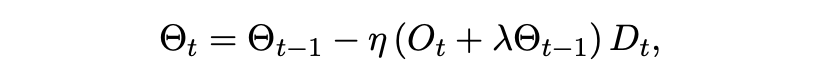
正交性折中:NAMO-D通过右乘对角矩阵实现了细粒度的自适应,但其代价是更新方向不再严格保持正交性。这本质上是一个工程上的权衡——用部分结构特性来换取更高的收敛性能。
Algorithm 2 NAMO-D: Diagonal extension of NAMO
Require: Learning rate η, momentum μ1, μ2 ∈ [0,1), batch size b, ε > 0, c ∈ (0,1]
1: Initialize Θ0 ∈ ℝ^(m×n), M0 = 0, v0 = 0
2: for t = 1,2,…,T do
3: Sample a minibatch of size b and compute stochastic gradient Gt = ∇ℒt(Θt−1)
4: Mt ← μ1Mt−1 + (1 − μ1)Gt
5: vt ← μ2vt−1 + (1 − μ2)Nc(Gt) ⊙ Nc(Gt)
6: dt ← √(1−μ2²)/(1−μ1²) Nc(Mt) ⊗ (√vt + ε)
7: d̃t ← ‖dt‖₁ / n
8: Ot ← Orth(Mt)
9: Dt ← diag(min{ max{dt, c d̃t 1}, 1/c d̃t 1})
10: Update parameters Θt ← Θt−1 − ηOtDt
11: end for
12: return ΘT
图2. NAMO-D算法伪代码,展示了引入截断机制的神经元级自适应缩放

收敛性理论保证
由于正交化梯度下降本质上是谱范数意义下的最速下降法,论文摒弃了传统的基于Frobenius范数的平滑性假设,转而采用了更具针对性的核范数与谱范数的对偶平滑性假设:
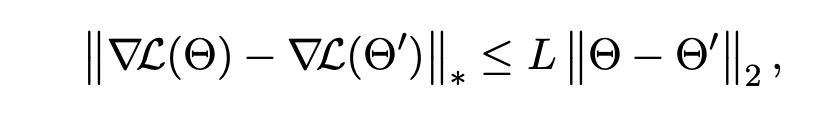
在这一严谨的假设,以及无偏、有界方差的随机梯度假设下,论文得出了以下关键结论:
确定性设定:在全量梯度无噪声的理想环境下,NAMO和NAMO-D的平均梯度范数上界均为 O(1/√T)。这完全匹配了确定性一阶平滑非凸优化的理论下界,证明正交化与自适应缩放的结合并未牺牲理论上的最优收敛速率。
随机设定:算法的收敛上界自然地分解为 O(1/√T) 的优化项和 O(1/√(bT)) 的方差项。当批大小(Batch Size)的量级达到 O(1/ε²) 时,方差项被主导,算法便能恢复至最优的 O(1/√T) 收敛速率。

实验验证
论文在OpenWebText数据集上,对GPT-2架构的124M和355M参数模型进行了预训练实验评估。实验中,所有标量和向量参数统一使用AdamW优化,而矩阵参数则交由各对比优化器(AdamW, Muon, NAMO, NAMO-D)处理。
工程实现的细节颇具参考价值。与AdamW默认使用 β1=0.9, β2=0.95 不同,NAMO与NAMO-D为了达到最佳性能,明确将动量系数设置为 μ1=0.95 和 μ2=0.99。此外,整个训练过程没有采用常见的余弦退火学习率调度,而是统一采用了2000步线性预热后保持恒定学习率的策略,这也是后续损失曲线呈现特定形态的原因。
调参鲁棒性验证
在针对GPT-2 (124M)模型的10,000步网格搜索实验中,NAMO和NAMO-D展现出了优于AdamW和Muon的超参数鲁棒性。它们在更宽的学习率范围内实现了更低的训练损失和验证损失。
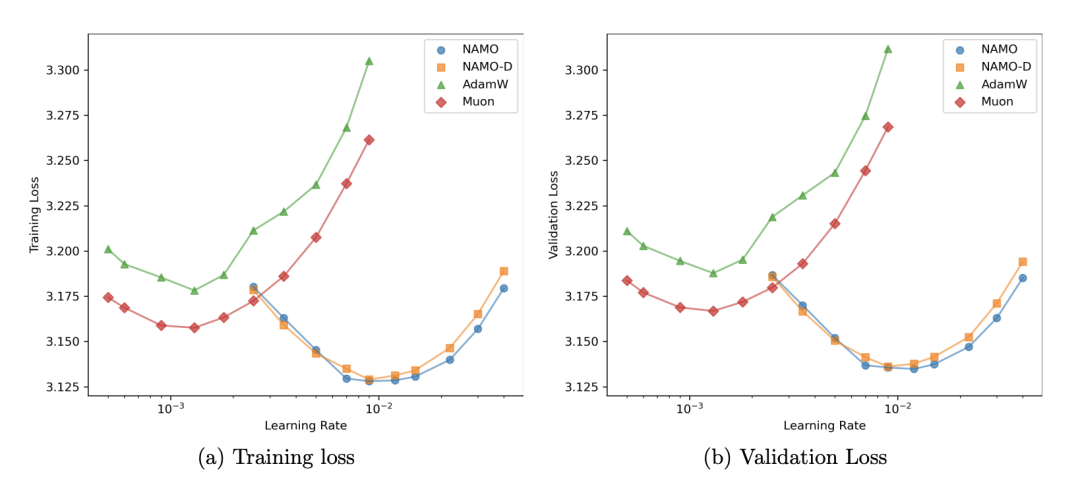
图3. GPT-2 124M模型的10K步超参数搜索。NAMO和NAMO-D在不同学习率下均呈现更宽阔且更低的损失盆地。
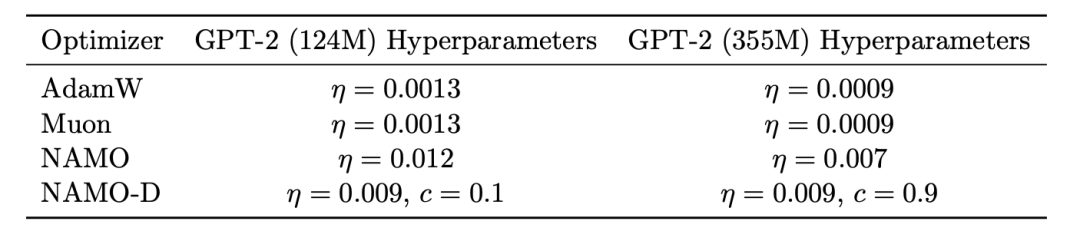
表1. 不同优化器在两个规模模型下搜索得到的最优超参数配置
对于NAMO-D而言,截断常数 c 是一个极其关键且对模型规模敏感的超参数。实验表明,在预训练124M模型时,c 的最优值为0.1。但当模型规模扩展至355M时,经过在 {0.1, 0.3, 0.5, 0.7, 0.9} 范围内的网格搜索,最终确定最优值为0.9。模型规模增大导致最优 c 值向1.0靠拢,这意味着在大模型训练中,需要适度放宽细粒度的截断限制,以维持大规模参数矩阵更新方向的条件数平衡。
长期训练性能对比
当使用寻优得到的最佳学习率,将124M模型的训练延长至50,000步时,细粒度自适应的优势彻底显现。NAMO-D最终实现了全场最低的训练损失和验证损失。
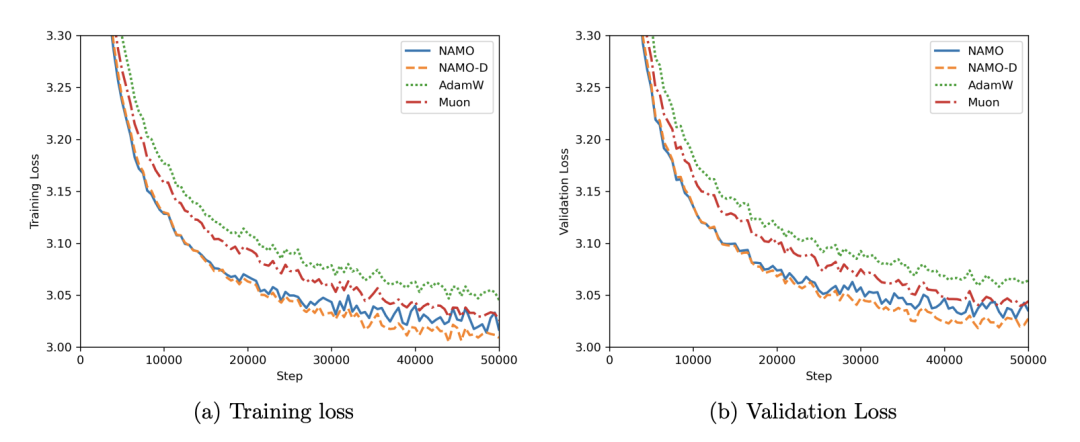
图4. GPT-2 124M预训练50K步损失曲线,NAMO-D在长线训练中获得最低损失
在355M模型的10,000步验证实验中,通过调节截断超参数 c,NAMO-D同样保持了最高的性能上限。
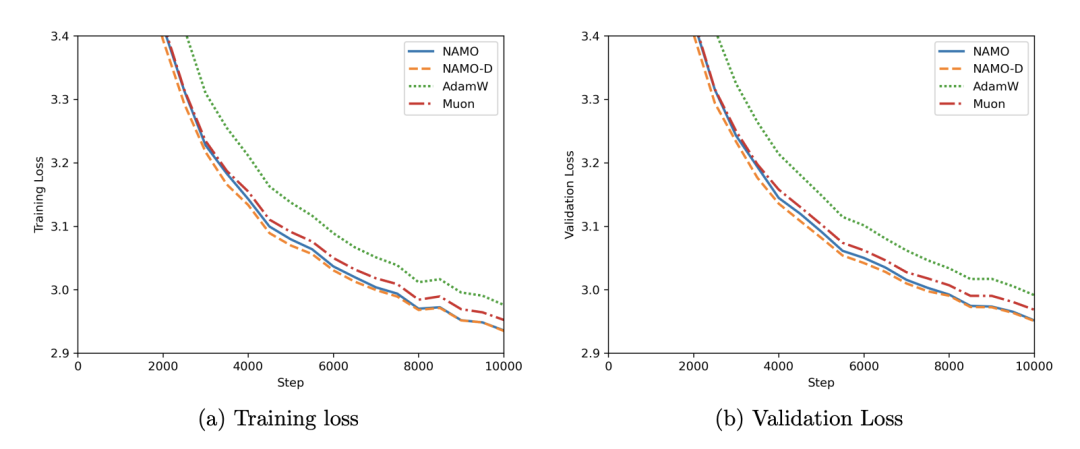
图5. GPT-2 355M预训练10K步损失曲线,NAMO-D通过调节截断超参数持续领跑
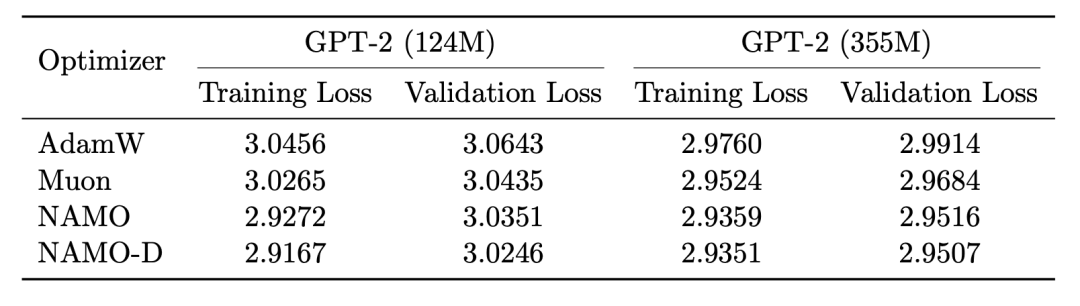
表2. 124M (50K步) 与 355M (10K步) 实验终止时的最终训练和验证损失精确数据

总结与展望
在大型语言模型训练领域,将权重矩阵的几何结构特性与成熟的自适应方差估计机制相结合,无疑是优化器设计的一个重要演进方向。
NAMO通过一个单一的标量自适应因子,在严格保留更新方向正交性的同时,引入了对数级别的噪声抵抗能力;而NAMO-D则通过神经元级别的对角缩放矩阵与截断机制,以部分正交性为代价,换取了更优越的收敛性能。
这项研究通过严谨的对偶范数理论证明和详实的预训练对比实验,为下一代结构化优化器的设计提供了坚实的理论基础与宝贵的工程实践参考。对于从事大语言模型训练和优化的开发者与研究者而言,NAMO系列优化器展示了一个富有潜力的技术路径。欢迎在 云栈社区 进一步交流与探讨相关技术细节。
 发表于 2026-2-24 05:10:59
|
查看: 369|
回复: 0
发表于 2026-2-24 05:10:59
|
查看: 369|
回复: 0
