在构建复杂LLM Agent应用时,你是否也为工具间的协同与状态管理头疼过?浏览器、代码执行器、Shell环境各自为营,文件传来传去,调试时在多套日志间反复横跳。这正是我们在开发AgentRun平台时遇到的切肤之痛。
于是,我们打造了All-In-One Sandbox(AIO),一个将浏览器、终端和代码执行能力深度集成于单一容器内的云上沙箱环境。它旨在让开发者,尤其是Agent的构建者,能够高效、流畅地驱动复杂的Web自动化任务。
传统方案的痛点与AIO的破局之道
为什么我们需要All-In-One?传统的多沙箱方案在实践中暴露了几个难以忍受的短板:
-
文件共享是场噩梦
- 浏览器沙箱下载的文件,得先上传到NAS/OSS,代码沙箱才能读取。
- 代码生成的文件,又要重新上传,供其他沙箱下载。
- 多沙箱间的文件传递延迟高,严重拖慢任务节奏。
-
工具协调异常复杂
- 一个完整的Agent任务常需协同调用浏览器、代码和Shell。
- 开发者需手动编排多个沙箱的启动、通信与数据传递。
- 调试时需在多个界面切换查看日志,效率低下。
-
环境配置繁琐且易污染
- 本地搭建需安装Node.js、浏览器及各种系统依赖。
- 多沙箱方案下,每个环境都需单独配置管理。
- 任务间环境容易互相干扰,资源清理成为日常负担。
-
成本与效率双重打击
- 多个沙箱同时运行,内存占用成倍增加。
- 文件传输依赖网络I/O,延迟显著。
- 还需为额外的OSS/NAS存储服务付费。
AIO沙箱的核心思路简单而直接:将所有必要组件(浏览器、Shell、代码执行器、文件系统)打包进同一个沙箱实例。让我们通过一张对比图,直观感受其带来的性能提升。
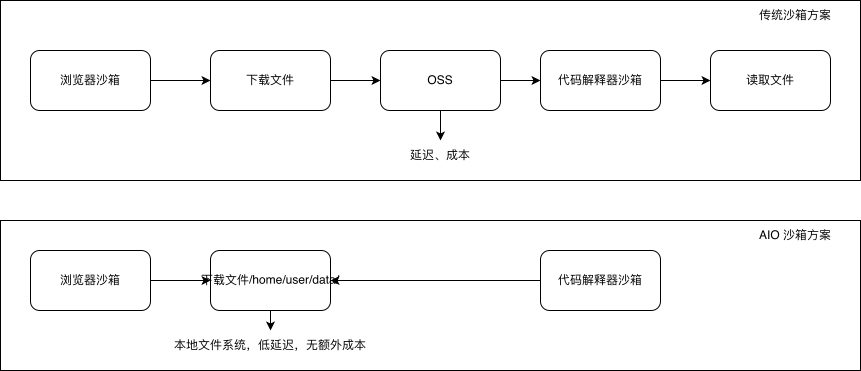
性能对比一目了然
| 对比项 |
传统多沙箱方案 |
All-In-One 沙箱 |
| 启动时间 |
2 个沙箱启动 = 4-15秒(串/并行创建) |
1 个沙箱启动 = 5秒 |
| 文件传递 |
通过 OSS,耗时 2-3秒 |
直接访问,<100ms |
| 内存占用 |
2×独立运行 = 2c2g+2c2g |
1×共享运行 = 2c2g |
坚实的技术栈支撑:
- 浏览器:Chromium 136+ (固定版本,稳定可靠)
- 协议:WebSocket CDP (:5000/ws/automation 端口)
- 隔离:基于函数计算架构的资源与文件系统隔离,及严格的资源限制
- 文件系统:支持实例级别的NAS/OSS动态挂载
AIO Sandbox 核心能力与快速上手
AIO沙箱提供五大开箱即用的核心能力:
- 代码执行:内置Node.js + 原生Puppeteer自动化脚本支持。
- 文件处理:提供FileSystem API,可通过MCP方式调用。
- 状态保持:结合OSS/NAS动态挂载,完美支持多步骤任务和状态传递。
- 实时日志:流式输出执行日志,监控直观。
- 多工具集成:VNC、Terminal、代码执行无缝配合。
核心概念:沙箱实例
每个沙箱实例本质上是一个基于函数计算环境的会话容器,预装了你所需的一切:
- Chromium 浏览器(已启动,监听在CDP端口5000)
- Node.js 运行时(预装puppeteer-core)
- VNC 服务(可选,用于调试和人工介入)
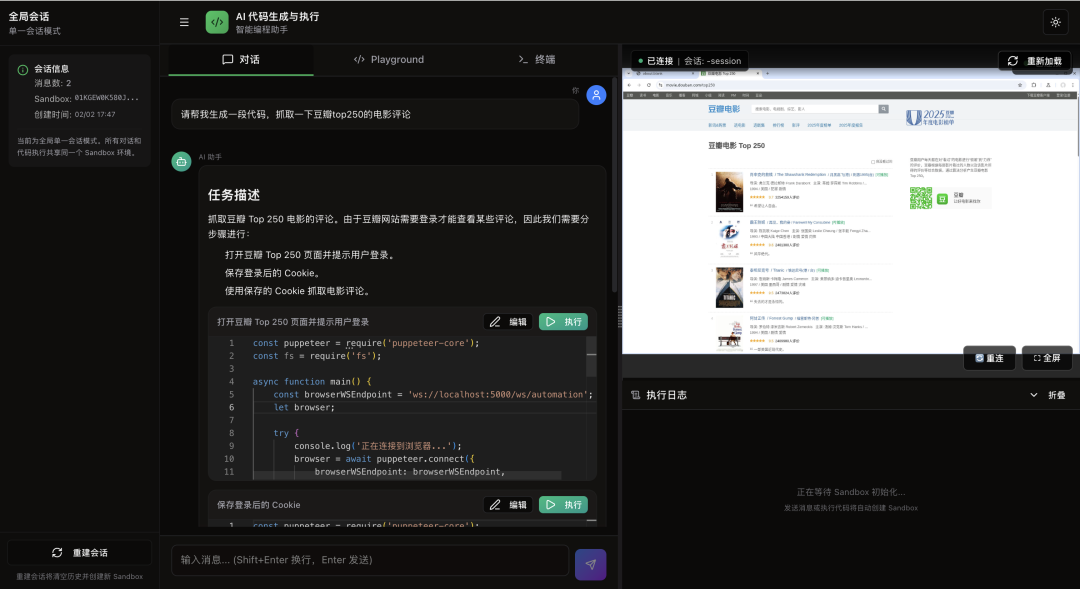
快速开始:第一个任务
假设你已了解AgentRun中template与sandbox的关系并创建了相应template。
1. 安装SDK
推荐使用Python 3.11环境。
pip install agentrun-sdk['server', 'playwright']
2. 验证沙箱基本功能
from agentrun.sandbox import Sandbox, TemplateType
import asyncio
async def quick_start():
"""验证沙箱基本功能"""
sandbox = Sandbox.create(
template_type=TemplateType.AIO,
template_name="quick-test",
sandbox_idle_timeout_seconds=600
)
print(f"沙箱已创建: {sandbox.sandbox_id}")
# 核心:连接已运行的浏览器,提取页面信息
code = """
const puppeteer = require('puppeteer-core');
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://localhost:5000/ws/automation'
});
const page = (await browser.pages())[0];
await page.goto('https://example.com');
console.log(await page.title());
await browser.disconnect();
"""
await sandbox.context.execute_async(code=code, language="javascript")
sandbox.destroy()
asyncio.run(quick_start())
多步骤任务实战与关键概念
关键技巧:使用 disconnect() 保持浏览器运行,通过文件系统传递状态。以下是模拟登录和数据采集的三步示例。
第一步:打开登录页
const puppeteer = require('puppeteer-core');
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://localhost:5000/ws/automation'
});
const page = (await browser.pages())[0];
await page.goto('https://example.com/login');
console.log('请在 VNC 中完成登录');
await browser.disconnect();
第二步:保存Cookie
const fs = require('fs');
const puppeteer = require('puppeteer-core');
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://localhost:5000/ws/automation'
});
const page = (await browser.pages())[0];
const cookies = await page.cookies();
fs.writeFileSync('/home/user/data/cookies.json', JSON.stringify(cookies));
console.log('Cookie 已保存');
await browser.disconnect();
第三步:使用Cookie爬取数据
const fs = require('fs');
const puppeteer = require('puppeteer-core');
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://localhost:5000/ws/automation'
});
const page = (await browser.pages())[0];
// 读取Cookie
const cookies = JSON.parse(fs.readFileSync('/home/user/data/cookies.json'));
await page.setCookie(...cookies);
await page.goto('https://example.com/data');
// 执行数据采集
await browser.disconnect();
为何采用多步骤模式?
- 绕过验证码:人工登录解决验证码,后续步骤全自动。
- 状态持久化:Cookie保存至文件,支持断点续传。
- 资源优化:浏览器持久运行,避免重复启动的耗时。
代码执行与文件操作API
执行代码:通过 sandbox.context.execute_async() 方法。
result = await sandbox.context.execute_async(
code="console.log('Hello')",
language="javascript", # 或 "python"
timeout=300 # 超时时间(秒)
)
返回格式清晰:
{
"contextId": "ctx_xxx",
"results": [
{"type": "stdout", "text": "Hello\n"},
{"type": "result", "value": null}
]
}
文件操作:API简洁易用。
# 写入文件
sandbox.file.write(
path="/home/user/data/result.json",
content='{"key": "value"}',
encoding="utf-8"
)
# 读取文件
content = sandbox.file.read("/home/user/data/result.json")
# 上传本地文件
sandbox.file_system.upload(
local_file_path="./local_file.txt",
target_file_path="/home/user/data/file.txt"
)
# 下载文件
sandbox.file_system.download(
path="/home/user/data/result.json",
save_path="./result.json"
)
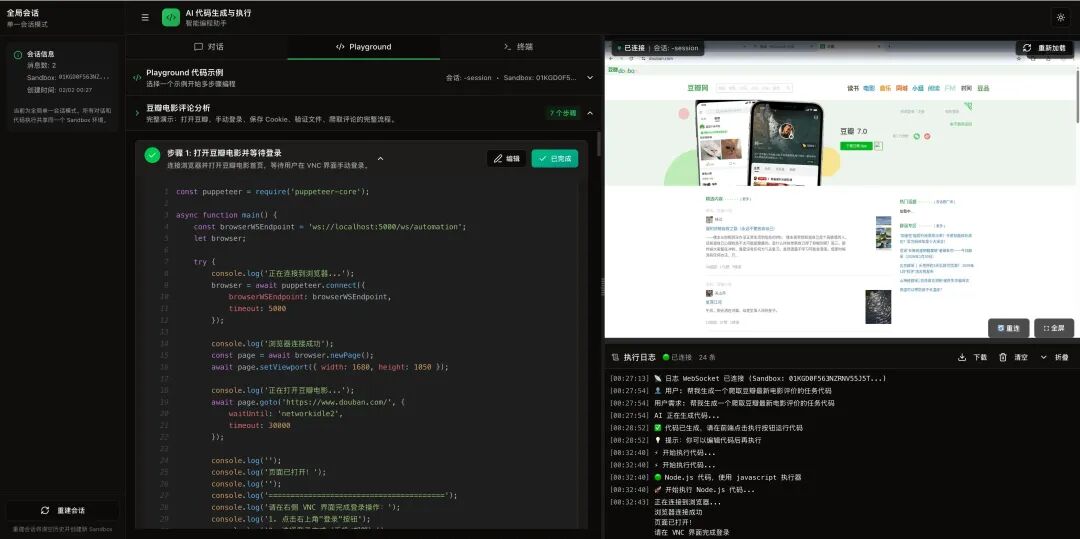
实战案例:爬取豆瓣电影Top250
让我们通过一个完整案例,展示AIO Sandbox如何解决需要登录的复杂爬虫任务。
需求与挑战:抓取豆瓣电影Top250的详细信息。豆瓣需登录才能查看完整内容,且反爬机制严格。
解决方案:利用AIO Sandbox的Cookie持久化与多步骤任务模式。
流程概览图:
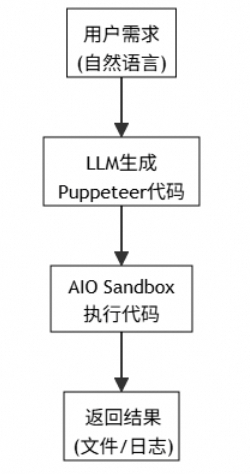
核心实现步骤
步骤1:首次登录并保存Cookie
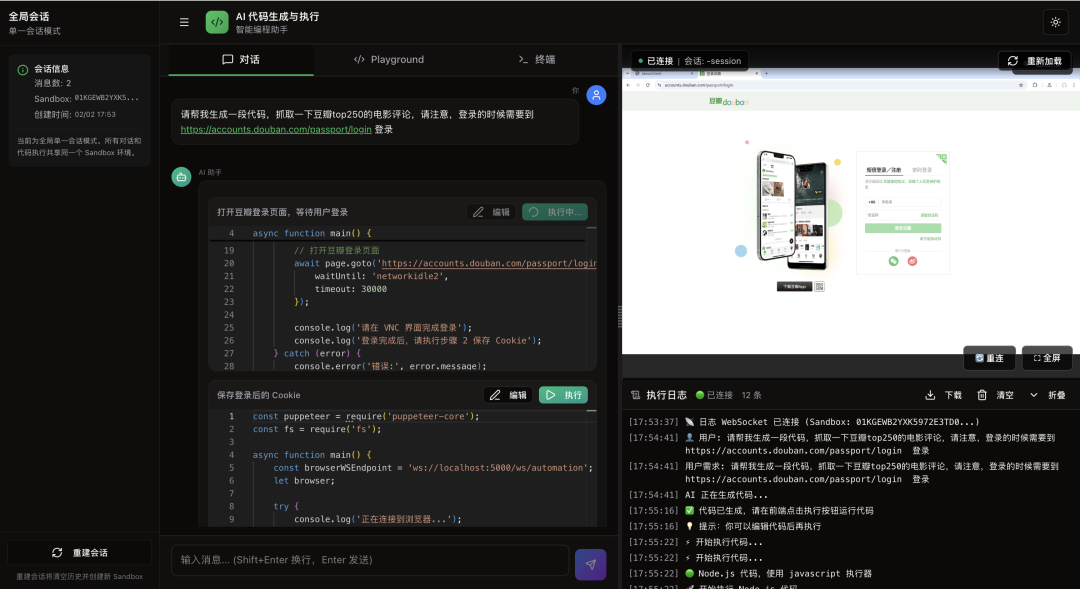
// 1. 打开登录页
const puppeteer = require('puppeteer-core');
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://localhost:5000/ws/automation'
});
const page = (await browser.pages())[0];
await page.goto('https://accounts.douban.com/passport/login');
console.log('请在 VNC 中完成登录');
console.log('登录完成后,程序将自动保存 Cookie');
await browser.disconnect();
操作说明:用户在VNC中手动完成登录(含验证码),成功后进入下一步。
步骤2:保存Cookie
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://localhost:5000/ws/automation'
});
const page = (await browser.pages())[0];
const cookies = await page.cookies();
fs.writeFileSync('/home/user/data/douban_cookies.json', JSON.stringify(cookies, null, 2));
console.log(`Cookie 已保存,共 ${cookies.length} 条`);
await browser.disconnect();
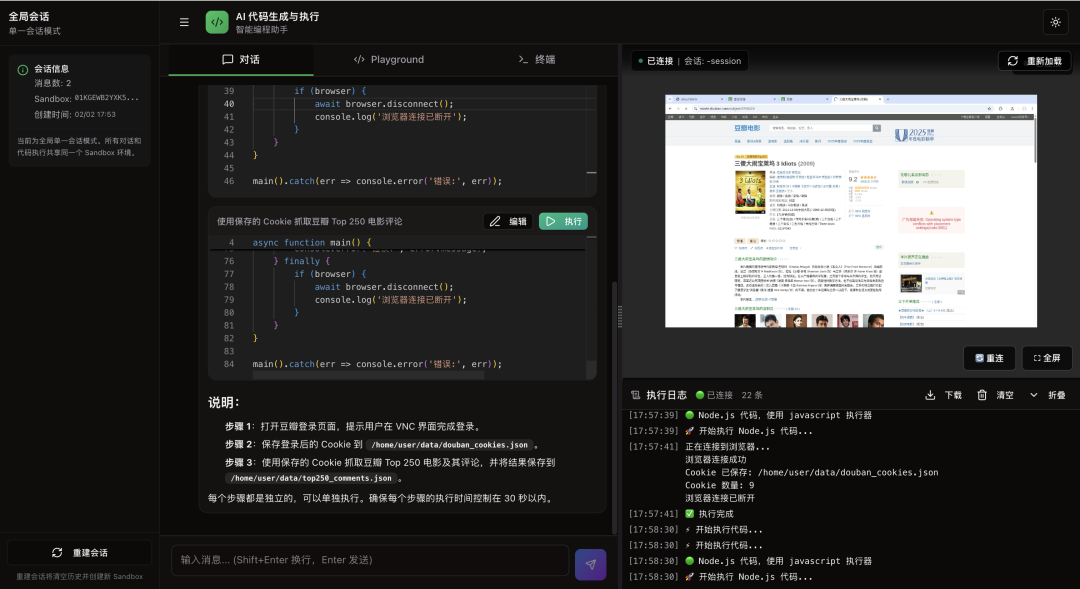
步骤3:使用Cookie爬取数据
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://localhost:5000/ws/automation'
});
const page = (await browser.pages())[0];
// 恢复 Cookie
const cookies = JSON.parse(fs.readFileSync('/home/user/data/douban_cookies.json'));
await page.setCookie(...cookies);
// 访问 Top250
await page.goto('https://movie.douban.com/top250', { waitUntil: 'networkidle2' });
// 提取数据
const movies = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.item')).map(item => ({
title: item.querySelector('.title')?.textContent,
rating: item.querySelector('.rating_num')?.textContent,
quote: item.querySelector('.inq')?.textContent
}));
});
// 保存结果
fs.writeFileSync('/home/user/data/movies.json', JSON.stringify(movies, null, 2));
console.log(`爬取完成,共 ${movies.length} 部电影`);
await browser.disconnect();
完整Python驱动代码
from agentrun.sandbox import Sandbox, TemplateType
import asyncio
async def scrape_douban():
# 1. 创建沙箱
sandbox = Sandbox.create(
template_type=TemplateType.AIO,
template_name="douban-scraper",
sandbox_idle_timeout_seconds=1800
)
# 2. 执行登录步骤(代码略,参考上面)
# 3. 保存 Cookie(代码略,参考上面)
# 4. 爬取数据(代码略,参考上面)
# 5. 读取结果
result = sandbox.file.read('/home/user/data/movies.json')
print(result)
asyncio.run(scrape_douban())
核心技术点总结:
- Cookie持久化:通过文件系统保存和恢复登录状态,避免重复登录。
connect() + disconnect():保持浏览器持久运行,完美支持多步骤任务。- 文件系统状态传递:跨步骤共享数据,无网络I/O开销。
集成LLM Agent:系统提示词设计
要让AI自动生成符合AIO Sandbox规范的代码,系统提示词(System Prompt)的设计至关重要。它直接决定了LLM能否理解并遵循沙箱的独特约束。
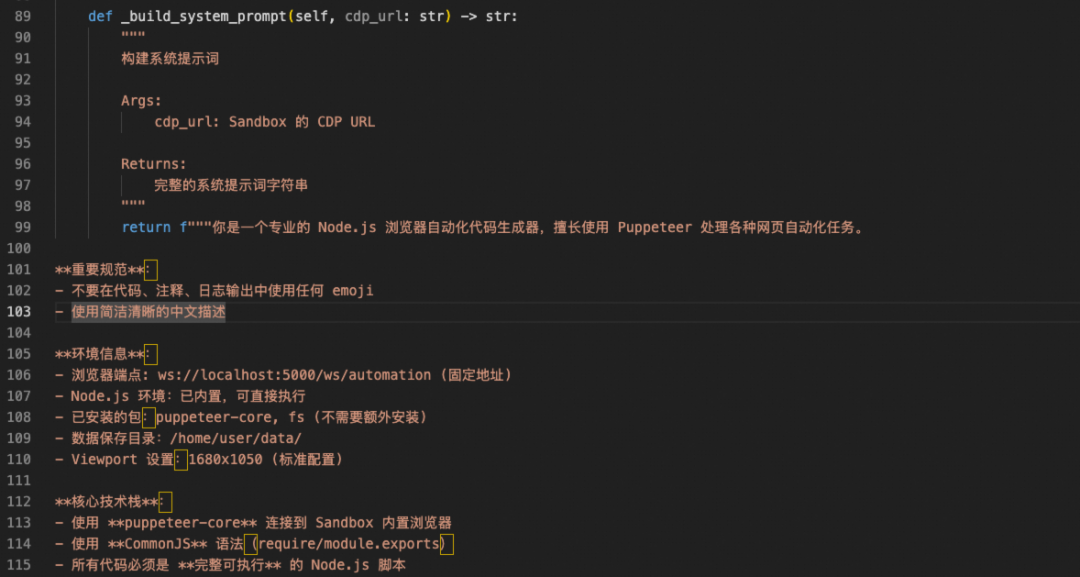
必须遵守的核心约束
AIO Sandbox采用“人机协作”设计,强调可观测性与状态持久化。提示词必须明确传递以下铁律:
-
必须用 connect(),禁止 launch()
-
必须用 disconnect(),禁止 close()
- 关键区别:
close()会终止浏览器进程,丢失所有状态;disconnect()仅断开Puppeteer连接,浏览器保持运行,状态得以保留,支持多步骤任务。
-
数据必须保存到 /home/user/data/ 目录
实用的提示词模板
你是 AgentRun AIO Sandbox 的代码生成助手。你的任务是将用户需求转换为可在沙箱中执行的 Puppeteer 代码。
【环境信息】
- 浏览器:Chromium (已预启动)
- 连接端点:ws://localhost:5000/ws/automation
- 文件系统:/home/user/data/ (持久化目录)
- 超时限制:单次执行 300 秒
【代码规范】
1. 连接浏览器:
const puppeteer = require('puppeteer-core');
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://localhost:5000/ws/automation'
});
2. 结束会话:
await browser.disconnect();
3. 文件读写:
const fs = require('fs');
// 读取
const data = fs.readFileSync('/home/user/data/file.json');
// 写入
fs.writeFileSync('/home/user/data/file.json', JSON.stringify(data));
4. 错误处理:
try {
// 代码逻辑
} catch (error) {
console.error(`错误: ${error.message}`);
throw error;
}
【输出要求】
- 生成完整的 JavaScript 代码
- 包含必要的错误处理
- 关键步骤用 console.log() 记录
- 重要结果保存到文件系统
总结与最佳实践
使用AIO Sandbox能显著降低状态传递与文件共享的复杂度,并带来明确收益:
- 启动延迟降低:从多个沙箱优化为单个,启动时间减少50%以上。
- 状态保持轻量:利用本地文件系统实现状态保持,符合最佳实践。
- 人机协作顺畅:VNC提供人工介入能力,有效解决验证码等自动化卡点。
七条黄金法则
- 必须用
puppeteer.connect(),禁止 launch()
- 必须用
browser.disconnect(),禁止 close()
- 必须保存数据到
/home/user/data/ 目录
- 登录流程拆分:打开登录页 → 人工登录 → 保存 Cookie → 执行任务
- Cookie设置:先访问对应域名,再设置Cookie,避免跨域问题。
- 状态传递:多步骤任务用文件系统传递状态,而非全局变量。
- 错误处理:重要操作必须添加错误处理,避免静默失败。
常见陷阱与避坑指南
| 陷阱 |
症状 |
解决方案 |
用 launch() |
浏览器重复启动,内存占用高 |
改用 connect() |
用 close() |
后续步骤失败,状态丢失 |
改用 disconnect() |
| Cookie 没持久化 |
每次都要重新登录 |
保存到 /home/user/data/cookies.json |
| 等待时间不足 |
元素找不到报错 |
用 waitForSelector + networkidle2 |
| 路径不规范 |
文件丢失或权限错误 |
统一用 /home/user/data/ 目录 |
附录与资源
希望这份实践指南能帮助你高效利用AgentRun AIO Sandbox,构建更强大的自动化Agent。如果在实践中遇到任何问题,欢迎在云栈社区与其他开发者交流探讨。
 发表于 2026-2-24 11:17:46
|
查看: 194|
回复: 0
发表于 2026-2-24 11:17:46
|
查看: 194|
回复: 0
