本文将带你从零开始,完整实现一个基于 Adaptive RAG、LangGraph、FastAPI 和 Streamlit 的技术概念验证项目。这套组合能做什么?Adaptive RAG 可以根据问题复杂度动态调整检索策略;LangGraph 将多步的 LLM 推理编排成稳定可靠的工作流;FastAPI 作为高性能后端,对外提供统一的 AI 管道接口;而 Streamlit 则让你无需编写复杂的前端代码,就能获得一个交互式的演示界面。
读完本文,你收获的将不仅是一套理论,更是一个可以立刻运行起来的端到端 AI 应用系统。
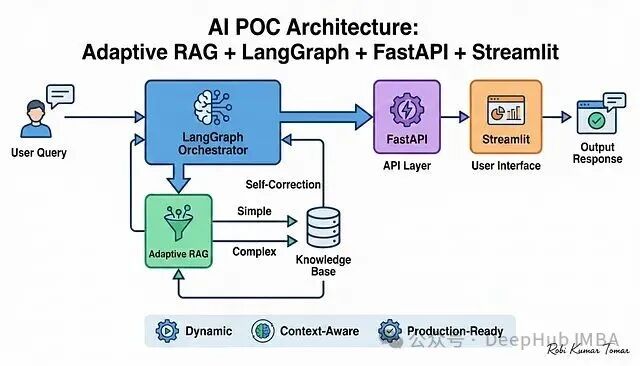
我们的目标是构建一个技术知识智能助手。它能理解用户的问题,根据查询复杂度动态选择检索深度(这就是Adaptive RAG的作用),通过 LangGraph 驱动整个推理流程,经由 FastAPI API 层返回结果,最终在一个直观的 Streamlit 界面上呈现答案。
这个应用场景直击一个现实痛点:当团队面对海量文档时,传统的 RAG 系统在处理模糊查询或多步骤复杂问题时,常常给出无关或错误的答案。
技术概览
Adaptive RAG
你可以把它理解为“先思考,再搜索”的 RAG 系统。对于简单的查询,它仅进行轻量级检索;一旦遇到复杂问题,则会自动切换到多跳深度检索、重排序或查询扩展等模式,用稍高的延迟换取更高的答案准确率。
LangGraph
这是用于构建有状态、多步骤 AI 工作流 的框架。与传统的链式调用不同,它将整个 LLM 流程建模为一张图——每个节点代表一个步骤(例如:检索 → 推理 → 验证 → 响应),并原生支持重试、记忆、循环和故障转移。对于需要在生产环境中保证确定性和可控性的场景,这种图结构的抽象比线性链条灵活得多。
FastAPI
FastAPI 负责将 Adaptive RAG 和 LangGraph 工作流封装成标准的 RESTful API 接口对外暴露,处理请求路由,并且天然支持高效的异步 I/O。
Streamlit
前端我们使用 Streamlit 搭建。它提供聊天式界面,无需编写 HTML/CSS,对于构建概念验证(POC)和演示来说,完全足够。
系统架构
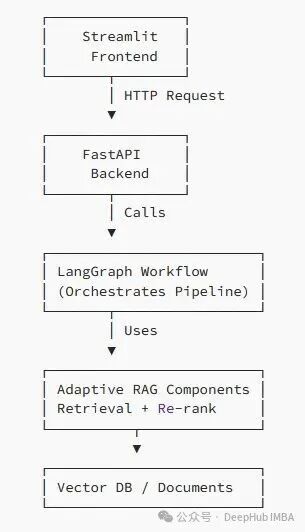
整个系统的数据流向非常清晰:
用户 → 输入查询 → Streamlit UI
Streamlit → 发送请求 → FastAPI
FastAPI → 传递查询 → LangGraph
LangGraph → 执行 Adaptive RAG → 检索器
检索器 → 获取文档块 → 向量数据库
向量数据库 → 返回结果 → LangGraph
LangGraph → 生成最终答案
FastAPI → 发送至 UI → 用户
项目结构
我们尽量保持项目结构简洁明了:
ai-poc/
│
├── backend/ # 后端逻辑
│ ├── app.py # FastAPI API 服务器
│ ├── rag_pipeline.py # Adaptive RAG 检索逻辑
│ ├── graph_workflow.py # LangGraph 工作流
│ ├── config.py # 配置和环境设置
│ ├── data/ # 源文档目录
│ └── __init__.py # 包初始化文件
│
├── frontend/ # UI 层
│ ├── ui.py # Streamlit 界面
│ └── __init__.py # 包初始化文件
│
├── .env # API 密钥和机密信息
├── requirements.txt # 项目依赖
└── README.md # 设置说明
requirements.txt 文件列出了所有必需的依赖包:
fastapi
uvicorn[standard]
streamlit
requests
pydantic
langchain
langchain-community
langgraph
faiss-cpu
sentence-transformers
openai
python-dotenv
核心代码实现
Adaptive RAG 管道 (backend/rag_pipeline.py)
这是检索层的核心,实现了自适应的检索逻辑。
# backend/rag_pipeline.py
from typing import List
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
class AdaptiveRAG:
"""
Adaptive Retrieval Pipeline
"""
def __init__(self, vector_db: FAISS):
self.db = vector_db
def retrieve(self, query: str) -> List[Document]:
if not query.strip():
return []
# Adaptive heuristic
token_count = len(query.split())
k = 3 if token_count < 6 else 8
return self.db.similarity_search(query, k=k)
def build_vector_store(texts: List[str]) -> FAISS:
"""
Build FAISS index from raw texts (POC only).
In production load persisted DB instead.
"""
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100
)
docs = []
for text in texts:
chunks = splitter.split_text(text)
for chunk in chunks:
docs.append(chunk)
return FAISS.from_texts(docs, embeddings)
自适应检索的核心逻辑其实很简单:根据查询的词数(Token 数)来决定检索深度。如果查询短于 6 个词,就只取最相关的 3 条结果;否则,拉取 8 条。这是一个非常直观的启发式方法,在 POC 阶段完全够用,生产环境可以替换为基于 LLM 的分类器或更精细的规则。
build_vector_store 函数负责从原始文本构建 FAISS 向量索引。请注意,为了演示方便,这里每次启动服务都会重建索引。在生产环境中,你应该加载已经持久化保存的向量数据库。
LangGraph 工作流 (backend/graph_workflow.py)
这里定义了一个简单的两节点工作流,负责编排检索和推理步骤。
# backend/graph_workflow.py
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
from langchain.schema import Document
from langchain_openai import ChatOpenAI
class GraphState(TypedDict):
question: str
docs: List[Document]
answer: str
def create_workflow(rag):
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
workflow = StateGraph(GraphState)
# Retrieval Node
async def retrieve_node(state: GraphState):
docs = rag.retrieve(state["question"])
return {"docs": docs}
# Reasoning Node
async def reasoning_node(state: GraphState):
question = state["question"]
docs = state.get("docs", [])
context = "\n\n".join([d.page_content for d in docs])
prompt = f"""
You are a technical assistant.
Use ONLY the context below to answer the question.
If the answer is not in the context, say you don't know.
Context:
{context}
Question:
{question}
"""
response = await llm.ainvoke(prompt)
return {"answer": response.content}
# Add nodes
workflow.add_node("retrieve", retrieve_node)
workflow.add_node("reason", reasoning_node)
# Connect nodes
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "reason")
workflow.add_edge("reason", END)
return workflow.compile()
整个工作流目前只包含两个节点:retrieve 负责检索相关文档,reason 负责根据检索到的上下文生成最终答案。GraphState 作为一个类型化的字典,在各节点间传递状态。当前的流程是线性的:先检索,再推理,然后结束。在实际项目中,你可以轻松地在这张图上增加验证节点、循环重试等分支逻辑,这正是 LangGraph 图结构的强大之处。
FastAPI 后端 (backend/app.py)
后端服务负责初始化组件,并提供 API 端点。
# backend/app.py
import os
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from dotenv import load_dotenv
from rag_pipeline import AdaptiveRAG, build_vector_store
from graph_workflow import create_workflow
load_dotenv()
app = FastAPI(title="Adaptive RAG API")
# ---------------------------
# Startup Initialization
# ---------------------------
class AskRequest(BaseModel):
query: str
@app.on_event("startup")
async def startup_event():
global workflow
# Sample knowledge base (replace with real docs)
sample_docs = [
"LangGraph supports stateful workflows and retry logic.",
"Adaptive RAG dynamically changes retrieval depth based on query complexity.",
"FastAPI is a high-performance async Python framework.",
]
vector_db = build_vector_store(sample_docs)
rag = AdaptiveRAG(vector_db)
workflow = create_workflow(rag)
# ---------------------------
# API Endpoint
# ---------------------------
@app.post("/ask")
async def ask(payload: AskRequest):
if not payload.query.strip():
raise HTTPException(status_code=400, detail="Query cannot be empty")
try:
result = await workflow.ainvoke(
{"question": payload.query}
)
return {"response": result["answer"]}
except Exception as e:
raise HTTPException(
status_code=500,
detail="Internal RAG processing error"
)
后端服务在启动时完成向量库构建和工作流初始化。随后,它通过 /ask 端点接收查询请求。这里使用了全局变量 workflow 来持有工作流实例——在 POC 阶段这样做没问题,但如果要部署到生产环境,建议使用依赖注入等更优雅的方式管理应用状态。
Streamlit 前端 (frontend/ui.py)
前端界面简洁明了,专注于功能的快速验证。
# frontend/ui.py
import streamlit as st
import requests
API_URL = "http://localhost:8000/ask"
st.set_page_config(page_title="Adaptive RAG Assistant")
st.title("Adaptive RAG Support Assistant")
query = st.text_input("Enter your question")
if st.button("Ask"):
if not query.strip():
st.warning("Please enter a question.")
else:
try:
with st.spinner("Thinking..."):
response = requests.post(
API_URL,
json={"query": query},
timeout=60
)
response.raise_for_status()
answer = response.json()["response"]
st.markdown("### Answer:")
st.write(answer)
except Exception as e:
st.error(f"Error: {e}")
前端代码非常简洁:一个输入框接收问题,一个按钮触发请求,获取结果后直接渲染显示。Streamlit 的优势就在于,你无需折腾传统前端框架那套复杂的技术栈,就能快速搭建出可交互的原型,这对于前端概念验证来说再合适不过。
如何运行这个项目?
-
安装依赖:
pip install -r requirements.txt
-
设置 OpenAI API Key:
- Linux/macOS:
export OPENAI_API_KEY="your_key_here"
- Windows (命令提示符):
set OPENAI_API_KEY=your_key_here
- Windows (PowerShell):
$env:OPENAI_API_KEY="your_key_here"
-
启动后端服务:
uvicorn backend.app:app --reload
服务将运行在 http://localhost:8000。
-
启动前端界面:
streamlit run frontend/ui.py
按照命令行提示,在浏览器中打开 Streamlit 提供的本地地址(通常是 http://localhost:8501)。
内部执行流程示例
当你在 UI 中输入查询,例如:
How does retry logic work in LangGraph workflows?
- 请求首先到达 FastAPI 后端。
- LangGraph 工作流从
retrieve 节点启动,Adaptive RAG 根据查询长度(本例中较长)动态选择 k=8 的检索深度。
- 从 FAISS 向量数据库中检索出最相关的 8 个文档块。
- 工作流转到
reasoning 节点,这些上下文被拼接成 Prompt,发送给配置的 LLM(如 GPT-4o-mini)生成答案。LLM 被严格限制只能基于提供的上下文作答。
- 生成的答案沿着原路径返回,最终呈现在 Streamlit UI 上。
如果一切顺利,你现在就拥有了一条完整的、可运行的端到端 RAG 管道:UI → API → Graph → Retriever → LLM → Response。
从 POC 到生产:下一步优化方向
虽然 POC 已经跑通,但距离一个健壮的生产级系统还有差距。下面按模块列出关键的优化方向:
检索层增强
- 混合检索:将向量相似度搜索与 BM25 等关键词搜索结合,可以提升在特定边缘情况下的召回率。
- 重排序:在初步检索出 top-k 文档后,使用 Cross-Encoder 模型进行精细的重排序,能显著提升最终答案的相关性。
- 多租户隔离:如果系统需要服务多个团队或客户,必须引入基于命名空间的向量存储隔离,防止信息跨域泄露。
工作流完善
- 答案验证:在当前工作流中增加一个验证节点,检查 LLM 生成的答案是否严格基于检索到的上下文,这对于控制“幻觉”至关重要。
- 对话记忆:若要支持多轮对话,需要在图中加入记忆节点,以持久化和管理对话历史状态。
可靠性与成本
- 重试与降级:为 LLM 调用实现重试机制和超时控制。当主模型不可用时,应能自动降级到备选模型。
- 成本优化:实现更智能的模型路由,让简单查询走轻量级、低成本的模型,仅在处理复杂问题时才调用更强大的模型。
可观测性与评估
- 全面日志:记录检索分数、命中文档 ID、响应延迟、Token 消耗等关键指标。
- 离线评估:准备测试数据集,定期运行,评估检索质量和答案生成质量。
- 幻觉监控:专门追踪那些答案明显脱离检索上下文的案例,用于后续模型或流程的优化。
用户体验
- 聊天历史:在 UI 中支持对话历史记录和多轮交互。
- 答案溯源:对生成的答案进行来源高亮,让用户清楚看到答案是基于哪几段文档生成的。
- 反馈机制:增加“有用/无用”反馈按钮,收集的用户反馈数据可用于后续的模型微调和系统评估。
部署与架构
- 容器化:将前后端服务都进行 Docker 容器化,确保环境一致性和可重复部署。
- 云部署与弹性伸缩:部署到云平台(如 AWS、GCP、Azure),并配置自动扩缩容策略以应对流量波动。
- 安全加固:为 API 端点启用 HTTPS,并集成 JWT 或 OAuth 等认证方式。生产环境的 API 密钥应使用专业的密钥管理服务,而非简单的环境变量。
总结
通过本文,我们逐步搭建了一个模块化、可扩展的 RAG 系统原型。它集成了自适应检索、有状态工作流编排、高性能 API 接口和快速原型界面等核心模块。这个架构具备良好的演进性,完全可以从当前的 POC 状态,通过上述的优化步骤,逐步迭代成一个稳定、高效的生产级系统。希望这个实战指南能为你构建自己的 AI 应用提供清晰的路径和扎实的起点。更多类似的技术实践 与深度讨论,欢迎在云栈社区与广大开发者一同交流。
 发表于 2026-2-25 03:49:37
|
查看: 150|
回复: 0
发表于 2026-2-25 03:49:37
|
查看: 150|
回复: 0
