春节期间,各家模型扎堆发布,相信大家已经学累了。
但热闹归热闹,这些模型实际用起来到底怎么样?尤其是进行代码审查时,该如何正确使用才能达到可靠的效果?
前阵子,我用AI评审一份PR时,发现了一件有趣的事:先是Claude指出代码存在数据竞争,而Gemini却笃定没有问题。于是,我将Opus 4.6、Gemini 3 Pro、GPT-5.2-Codex、Qwen-3.5-Plus、MiniMax-M2.5这几个最新的旗舰模型全部拉进来,让它们自行辩论。结果,得出了一个更反直觉的结论:
单个模型查找已知Bug的最高命中率仅为53%。但当它们开启辩论模式后,命中率直线飙升到了80%。尤其是最难的L3级Bug(需要系统级理解的那种),在辩论模式下被全部找出。
那么,各家旗舰模型到底哪一个更强?模型辩论机制的最优搭配又是什么?本文将还原整个实验的设计思路与过程。
五个最新旗舰模型单兵测评,效果如何?
经常使用AI辅助编程的开发者可能已经发现,不同模型在进行Code Review时,其风格与能力差异显著。
例如,Claude擅长追踪完整的调用链,能够顺着代码逐层排查,连错误处理路径也不会遗漏;Gemini则倾向于先对代码定性,常以“this is a disaster”开篇,从架构层面展开分析,但难以判断它是否完整浏览了所有相关代码;Codex发言较少,但偶尔的反馈却能直接命中问题的要害。
那么,在实际的生产环境中,到底哪个模型更有优势呢?我们干脆做一个实战测评。
在模型选择上,我挑选了Opus 4.6(Claude)、Gemini 3 Pro、GPT-5.2-Codex、Qwen-3.5-Plus、MiniMax-M2.5这五个最新的旗舰模型。测评工具则采用了我此前自研并已开源的Magpie;测评所用的“考题”均来自Milvus(一个开源的向量数据库,也是我日常参与维护的项目),一共筛选了15个PR。
为了更好地检验模型的真实实力,所选PR都有一个共同特征:合入后出现了问题,需要进行revert操作或后续的热修复。同时,我将这些Bug按难度分为了3级:
- L1:仅查看diff即可发现,如use-after-free、off-by-one等类型;(由于L1难度过低,所有模型均能轻松检出,无区分度,故不列入最终测评)
- L2(10个):需要理解周边代码才能发现,如接口语义变更、并发竞争等,贴合日常高频Bug场景;
- L3(5个):需要具备系统级理解能力才能发现,如跨模块状态一致性、升级兼容性等,是最能检验模型深度的难点Bug。
测试过程分为裸测(无任何辅助)和Magpie加持(给足相关代码上下文)两种模式,以贴合日常不同的Code Review场景。
最终测试结果如下:

从单个模型的测评表现中,我们可以提炼出4个核心结论:
- Claude裸测封神:53%的检出率全场最高,尤其是在L3级最难Bug上,裸测5/5全中——这意味着它不需要额外提供上下文,就能搞定系统级问题。
- Gemini输在上下文获取能力:裸测只有13%,全场最低。但加上Magpie提供的上下文后,直接涨到33%(翻了一倍多)。这说明该模型不擅长自己寻找和分析上下文,更适合由开发者提前整理好代码上下文,再让它辅助审PR的场景。
- R1模式下Qwen表现突出(40%):在R1模式下取得了40%的检出率,尤其是在L2级别Bug上,拿到了5/10,是该难度下的最高分,实用性很强,适合日常常规的PR Review。
- 上下文不是万能的:更多的上下文提示帮助了Gemini(13% → 33%)和MiniMax(27% → 33%),但却“坑”了Claude(53% → 47%)。推测原因是Claude本身就擅长自主梳理上下文,额外注入的信息反而成了噪音,干扰了它的判断。
这个测试结果与我日常的使用体感基本吻合。Gemini的分数比实际体感略低,可能因为我平时使用Gemini更多是多轮对话,而这次评测是固定流水线、一轮出结果的形式,刚好卡在了它不擅长的模式上。后续换成多轮对抗辩论后,Gemini的表现有了明显改善。
引入对抗式辩论,五大模型效果直线提升
单个模型的测评结果显示,各模型均有优劣。基于此,我尝试引入互相辩论的模式,探究能否进一步提升Bug的检出效果。
辩论测试基于第一阶段的实验规则,仅增加一个核心要求:5个模型同时参与,开展5轮对抗式辩论。所有观点必须以代码为证据,互相挑错、反驳,禁止无依据的妥协。
最终,辩论模式与最强个体(裸测版本的Claude)的效果对比如下:

可见,辩论模式的效果全面碾压了单个模型,核心提升体现在两点:
- 命中率大幅提升:从单个模型最高的53%检出率飙升至80%,尤其是L2级常规Bug,检出率直接翻倍,彻底弥补了单个模型的检测盲区。
- 最难Bug零遗漏:L3级最难的系统级Bug,在辩论模式下实现了100%命中。而在单个模型中,仅有Claude能做到这一点,这充分体现了模型协作的核心价值——能力互补。系统级Bug对最强个体而言难度不大,辩论模式的核心价值在于补齐了Claude在L2级常规Bug上的检测短板。
这里补充一个具体的辩论细节还原,来自PR #44474 (https://github.com/milvus-io/milvus/pull/44474):

模型如何搭配,才能找到最多的Bug?
检出率从53%提升到80%的背后,关键在于不同模型互补了彼此的能力盲区。那么,新的问题来了:哪些模型互相搭配,效果会更好?
此前,在R1(有上下文加持)模式下,每个模型找到的Bug数量如下:Claude 7/15(47%),Qwen 6/15(40%),Gemini 和 MiniMax 各 5/15(33%),Codex 4/15(27%)。五个模型联合覆盖了11/15的Bug——这意味着还有4个Bug全军覆没。
这里有一个有意思的细节:Claude找到的最多,但也只覆盖了不到一半。它漏掉的8个Bug里,Gemini能补上3个——分别是一个并发竞态、一个云存储API兼容性问题、一个权限校验遗漏。反过来,Gemini漏掉的数据结构和深层逻辑Bug,Claude几乎全找到了。
而将不同模型两两组合后,整体的Bug检出率如下:
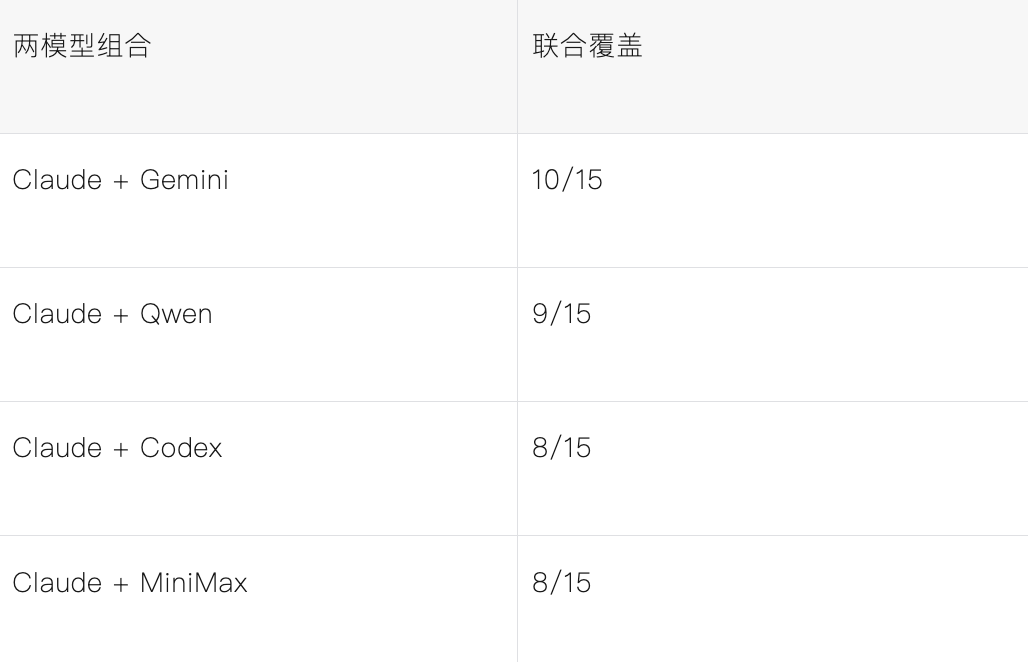
因此,针对我们的测评集,Claude + Gemini 是最优的两模型组合,仅两个模型就能覆盖五个模型联合上限(11个)的91%(10个)。
此外,在对Bug的类型与数量进行更细致的分析后,我们发现Claude + Gemini并非所有场景下的最优解,Bug的类型决定了模型的适配性:
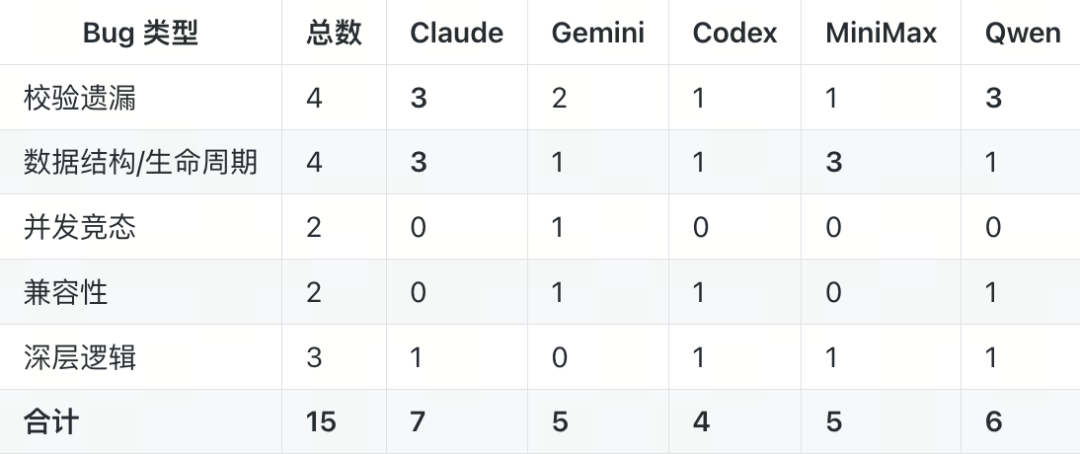
可以看出:
- 数据结构和生命周期问题,找Claude和MiniMax,两者并列检出3/4。
- 校验遗漏问题,找Claude和Qwen,两者并列检出3/4。
- 并发和兼容性问题,Claude反而是0检出——这刚好是Gemini可以补位的地方。
没有真正的全能选手,但Claude覆盖范围最广,是最接近全能的那一个。至于那4个全军覆没的Bug,它们的共同特点是:代码语法完全正确,Bug藏在开发者脑子里的业务假设中,不在diff里,甚至不在周边代码里。这或许就是当前AI进行Code Review的天花板所在。
找完Bug改Bug,谁的建议最可靠?
在日常的Code Review中,仅仅找到Bug是远远不够的。模型给出的修改建议是否准确、可用,同样是核心的评价标准。
因此,本次实验在辩论结束后,我们还新增了模型Review质量互评环节,以进一步筛选实用型模型。
互评规则:每个模型开启一个新会话作为裁判,采用匿名打分(将5个模型的输出随机映射为Reviewer A/B/C/D/E)。打分维度包括4项,每项1-10分:准确性、可操作性、深度、清晰度。(裁判无法知晓所评内容对应的模型,以确保评分的客观性。)
这一轮的最终评分如下:
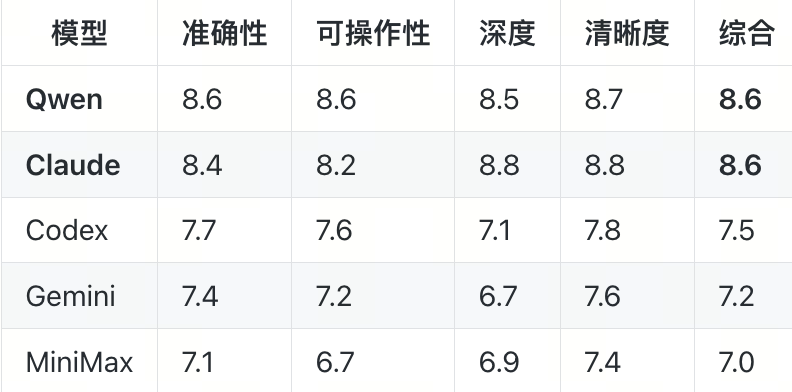
互评结果显示,Qwen和Claude的Review质量并列第一,其建议的准确性、可操作性,以及分析的深度、表述的清晰度,均远超其他3个模型;Codex、Gemini、MiniMax表现相对普通,无明显优势。
小结与实验局限性
经过五轮辩论,每个模型的个性非常鲜明:
- Claude:严谨细致,擅长追踪完整调用链和深层逻辑,能自主梳理上下文,L3级Bug检出能力独一档。偶尔会在数学层面过度自信,但认错态度坦诚。适合核心代码、深层Bug的审核。
- Gemini:风格激进,擅长从架构层面定性问题,对代码风格和工程规范高度敏感。但常聚焦于表面问题,Review深度不足。其质疑能推动其他模型进行更严谨的验证,适合搭配Claude使用,补充架构层面的视角。
- Codex:沉默寡言,发言频次低,但Bug检出命中率高,偶尔能精准命中核心问题。在辩论中常能提供关键线索,适合作为辅助模型,补充检测盲区。
- Qwen:综合表现优秀,Review质量与Claude并列第一,擅长综合各方观点、梳理重点,修改建议可操作性强。L2级常规Bug检出能力突出,适合日常常规PR Review。偶尔会因上下文窗口限制,在多轮辩论后丢失部分上下文。
- MiniMax:单个模型的Bug检出能力偏弱,适合作为辅助模型补充使用。
最后,需要坦诚说明本次实验的局限性,避免过度解读,也保证实验的客观性:
- 样本量有限:只有15个PR,且都来自同一个Go/C++项目(Milvus),不代表所有编程语言和业务场景的结果,仅供参考。
- 模型有随机性:同样的Prompt跑两次,结果可能不同。文中数据是一次快照,不是稳定的期望值。不能根据此实验明确得出所谓的模型能力绝对排行,但“辩论比个体强”、“某些模型擅长某些方向”这些趋势是成立的。
- 顺序可能影响表现:辩论中发言顺序固定,可能影响后续模型的判断。
本次实验的相关工具与数据集已全部开源,对Transformer架构和模型测评感兴趣的朋友可以进一步研究:
 发表于 2026-2-25 03:42:40
|
查看: 195|
回复: 0
发表于 2026-2-25 03:42:40
|
查看: 195|
回复: 0
