Cloudflare 工程经理 Boris Tane 写了一篇题为《How I Use Claude Code》的文章,记录了他使用 Claude Code 作为主力开发工具九个月后总结出的一套工作流。
Boris 的经历很有分量——他之前创办了无服务器可观测性平台 Baselime,获得过红杉资本的投资,并在 2024 年被 Cloudflare 收购,之后负责领导 Workers 可观测性团队。这篇文章之所以值得深读,不在于它提供了多少提示词技巧,而在于它复盘了一位架构师如何与 AI 协作,进行复杂的系统演进。在踩了九个月的坑之后,他收敛出的核心原则可以浓缩为一句话:
在你审查并批准书面方案之前,绝不让 AI 写哪怕一行代码。
这听起来可能有些反直觉。我们购买 AI 编程工具,不就是为了让它帮我们写代码吗?
但读完他的全文,你就能理解其深意。他反对的并非 AI 的能力,而是一种常见的、代价高昂的失控模式:AI 写出来的代码单独看挑不出毛病,但一旦放入你的现有系统,就开始引发各种问题。
今天,我们就从架构设计的角度,来拆解一下这套流程。
一、AI 编程最昂贵的失败,不是代码写错了
Boris 早期曾踩过一个让他印象深刻的坑。
他让 Claude 去实现一个功能,AI 写得很快,运行起来也不报错,看起来一切顺利。但过了一段时间他才发现,Claude 完全无视了项目里已经存在的缓存层,从头造了一个新的。他花了半小时才意识到问题所在,然后又花了一小时把所有改动回滚。
类似的情况反复出现:一个函数忽略了现有的缓存机制,一个数据库迁移没有考虑 ORM 的约定,一个 API 端点重复实现了系统里早已存在的逻辑。
这些代码有一个共同的特点:孤立来看完全正确,但放到系统里就成了定时炸弹。
做过架构设计的人对这种感觉不会陌生。系统最怕的不是“写错了”,而是“写对了,但放错了位置”。一个新加入团队的工程师可能写出一个完美的函数,但如果他不理解模块之间的职责边界、不知道哪些部分应该复用、不清楚某个设计决策背后的约束条件,他写出的代码就会成为未来的维护负担。
AI 的问题与此一模一样,甚至更加隐蔽——它写得更快,覆盖范围更广,你来不及一行一行地审查。等到发现问题时,它已经在错误的方向上堆砌了大量实现。
Boris 的原话是:
This is the most expensive failure mode with AI-assisted coding, and it's not wrong syntax or bad logic. It's implementations that work in isolation but break the surrounding system.
AI 辅助编程最昂贵的失败,不是语法错误,也不是逻辑缺陷,而是那些孤立运行良好、但会破坏周边系统的实现。
从架构设计的视角来看,这句话的本质是说:AI 缺乏对系统完整性的理解。它能看清局部,却看不清全局。
下面这张对比图可以直观地展示两种工作模式的差异:
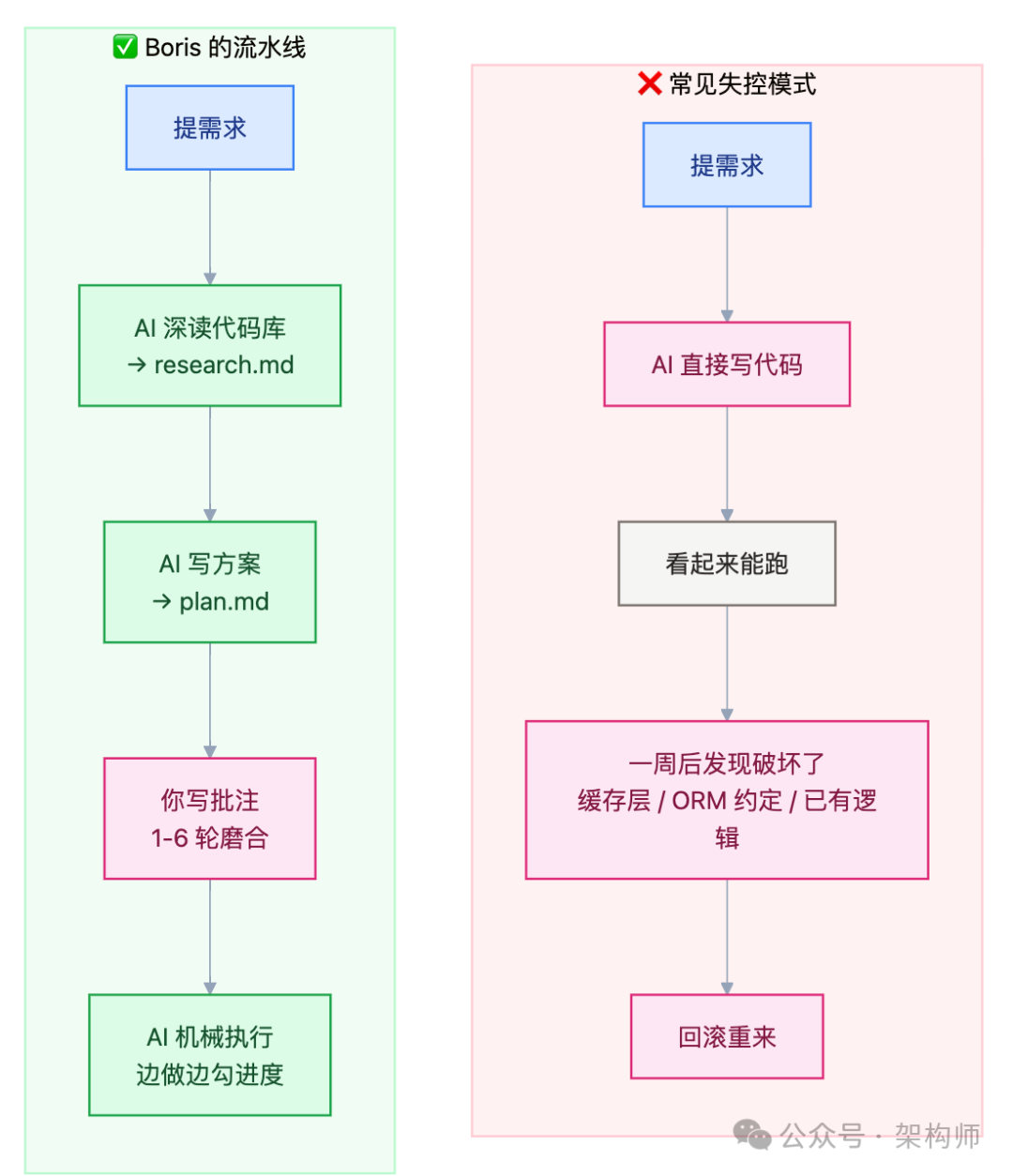
二、思路:把架构决策显式注入 AI 的工作流
在传统的开发模式中,架构师最核心的工作是什么?
很多人认为是画架构图、选技术框架、编写设计文档。这些当然重要,但它们都是手段。架构师真正在做的事情是守住系统边界:明确哪些部分应该复用、哪些部分不该动、哪些约束不可妥协、在当前的阶段哪些取舍是合理的。
这些知识大部分并不直接写在代码里。它们存在于架构师的脑海中,沉淀在团队的工程文化里,蕴含在那些“我们当时为什么这么做”的口头传承里。
一个新成员加入团队,需要几周甚至几个月才能将这些隐性知识内化。而 AI 永远是一个“新人”——每一次会话,它都是从零开始理解你的系统。
Boris 想明白的正是这一点:与其寄希望于 AI 自己领悟你的架构意图,不如建立一套流程,把架构决策显式地注入到 AI 的工作流中。
因此,他设计了一条清晰的流水线:

每一步都有明确的产出物,每一步都有明确的审查节点。AI 不是不能写代码,而是必须首先通过你的架构审查。
接下来,我们逐一展开每个阶段。
三、Research:先让 AI 把系统读明白
在进行任何有分量的改动之前,Boris 的第一步不是让 AI 写方案,更不是直接写代码。第一步是命令它彻底阅读相关的代码库,然后将理解写成一份 research.md 文档。
他分享了几条真实使用的指令,注意其中的用词:
“深入阅读这个文件夹,深刻理解它的工作原理、功能以及所有细节。完成后,把你的学习和发现写成一份详细的 research.md 报告。”
“非常详细地研究通知系统,了解它的复杂性,并写一份详细的 research.md 文档,包含所有关于通知如何运作的知识。”
“走通任务调度的完整流程,深入理解它,并排查潜在的 bug。系统确实存在 bug,因为有时候已经被取消的任务仍然会被执行。持续排查,直到找出所有 bug 为止。”
请注意他反复使用的关键词:“deeply”、“in great details”、“intricacies”、“go through everything”。他说这些词并非修饰——如果你不这样强调,Claude 就可能只是走马观花,打开文件看看函数签名就跳过去了。你必须明确告诉它:浅层阅读是不可接受的。
那么,research.md 的价值究竟在哪里?Boris 说得很直接:
It‘s not about making Claude do homework. It’s my review surface.
它不是让 AI 交作业。它是你的审查界面。 你通读这份报告,以此来验证 AI 是否真正理解了系统——模块间的依赖关系对不对?关键的调用链路是否走通了?有没有遗漏重要的边界条件?
如果调研阶段就错了,后面的方案必定是错的,实现也一定是错的。在架构设计里,这被称为“问题定义阶段的错误会被后续每一步放大”。
四、Plan:方案要具体到文件路径和代码片段
审查完调研报告之后,Boris 会要求 AI 在 plan.md 文件中撰写一份详细的实现方案。
但他对“计划”的标准非常高。这不是“优化性能、改善体验”这类愿景式的描述,而是要具体到文件路径、代码片段、明确的取舍和约束。
他的原文写道:
The generated plan always includes a detailed explanation of the approach, code snippets showing the actual changes, file paths that will be modified, and considerations and trade-offs.
方案必须包含对方法的详细解释、展示实际改动的代码片段、将被修改的文件路径,以及所有需要考虑的权衡因素。
他并不使用 Claude Code 内置的 Plan 模式。原因很直接——内置模式不够用。使用自己的 Markdown 文件,可以在编辑器里随意修改、添加行内批注,并且能作为项目中的真实文件持久存在。
Boris 还分享了一个常用技巧:提供参考实现。
如果你在某个开源项目里见过某个功能实现得很好,就把那段代码贴给 AI,并说“这是他们的实现方式,请写一份 plan.md 来说明我们如何采用类似的方案”。
Claude works dramatically better when it has a concrete reference implementation to work from rather than designing from scratch.
当 AI 有具体的参考实现可以对照时,其效果远比让它从零开始设计要好得多。
这在架构设计中就是模式复用——优秀的架构师不会每次都从零开始,而是识别已有的成熟模式,评估其适用性,然后进行适配。给 AI 一个锚点,它就不容易偏离方向。
五、批注循环:这套方法真正值钱的地方
Boris 指出,方案文档本身并非最有价值的部分,真正有价值的是接下来的步骤。
AI 写完 plan.md 之后,他会在编辑器里打开这份文档,直接在文档中添加行内批注——纠正错误的假设、否决不合适的方案、补充 AI 所不具备的领域知识和约束条件。

批注的长度差异很大。有时只有两个字——比如在一个被标记为可选的参数旁边写上“必填”。有时则是一整段话,用于解释复杂的业务约束,或者粘贴代码片段来展示期望的数据结构。
他举了几个真实的批注例子:
- “用 drizzle:generate 来生成迁移,不要写原始 SQL” —— 这是项目规范,AI 无从知晓。
- “不对,这里应该用 PATCH,不是 PUT” —— 纠正错误的假设。
- “把这一节整个删掉,这里不需要缓存” —— 否决过度设计。
- “队列消费者已经内置了重试机制,这段重试逻辑多余了。删掉,让它直接失败就好” —— 补充系统上下文。
- “visibility 字段应该在 list 层级,不是在单个 item 上。当一个列表是公开的,所有 item 都是公开的。据此重构 schema 部分” —— 重新调整整个章节的方向。
然后,他把更新后的文档交回给 AI,并附上指令:
“我在文档里加了一些批注,逐条处理所有批注并更新文档。先不要实现。”
这个批注循环会重复 1 到 6 次。 “先不要实现”这五个字至关重要——如果不明确写出,AI 一旦觉得方案差不多了,就可能直接开始动手写代码。
Boris 对这套机制有一个精准的描述:Markdown 文件充当了他和 AI 之间的共享可变状态(shared mutable state)。
The markdown file acts as shared mutable state between me and Claude. I can think at my own pace, annotate precisely where something is wrong, and re-engage without losing context.
你可以按照自己的节奏思考,在出问题的精确位置进行标注,AI 再整体消化并更新文档。你不需要在聊天记录里费力解释一大堆,直接指着文档里的具体位置写出修改意见即可。
他说,这与单纯通过聊天消息引导实现有本质区别。方案是一份结构化的完整规格,可以进行整体审查;而聊天记录则需要来回翻看才能还原决策脉络。经过几轮批注,一份泛泛的通用方案就能演变为完美适配现有系统的精准规格说明书。
从架构角度看,这个过程就是架构评审——只不过评审对象从人变成了 AI,评审载体从会议室变成了一份可持续编辑的 Markdown 技术文档。而且效率更高:无需协调时间、无需等人、无需反复解释上下文。
六、Implement:让实现变得“无聊”
在正式开始写代码之前,Boris 还会多做一步:让 AI 将 plan.md 转变一份详细的待办事项清单(todo list),并按阶段拆分成每一个具体的任务。这样,即使会话持续了几个小时,打开文档看看勾选了哪些项目,就能了解进度,无需费力翻找聊天记录。
然后,他发出实现指令。这段指令几乎是原样复用的:
“全部实现。每完成一个任务或阶段,在方案文档中标记为已完成。在所有任务和阶段全部完成之前不要停下。不要添加不必要的注释或 JSDoc,不要使用 any 或 unknown 类型。持续运行类型检查,确保不引入新问题。”
每一句话都有其明确的用意:
- “全部实现” —— 执行计划里的所有内容,不要挑三拣四。
- “标记为已完成” —— 方案文档是进度的唯一真相来源。
- “不要停下” —— 不要中途暂停等待确认。
- “不要添加不必要的注释” —— 保持代码整洁。
- “不要使用 any 或 unknown” —— 保持严格的类型安全。
- “持续运行 typecheck” —— 尽早发现问题,不要积压到最后。
当说出“全部实现”时,意味着所有关键决策都已完成并经过了验证。实现阶段变成了机械性的执行工作,而不再是创造性的劳动。Boris 原文中有一句点睛之笔:
I want implementation to be boring.
他就是想要让实现变得“无聊”。 创造性的工作已经在之前的批注循环中完成了。一旦方案正确,执行就应该是顺理成章、平淡无奇的事情。
这在软件工程中是一个成熟的理念:在设计阶段充分投入,以换取实现阶段的低风险和高确定性。 在 AI 时代,这个理念反而容易被忽略——因为 AI 写代码太快了,快到让人产生“我们不再需要仔细设计”的错觉。
实现阶段的反馈应该非常简短。因为 AI 已经拥有了 plan.md 的完整上下文,简单的纠偏就足够了:“你漏掉了 deduplicateByTitle 函数”、“设置页面应该在管理后台,请挪过去”、“宽度再大一点”、“这个元素还是被裁切了”、“这里存在 2px 的间隙”。如果遇到视觉相关问题,直接贴截图,一张图比三段文字描述更清楚。
他也经常引用已有的代码作为参照:“这个表格应该跟用户列表的样式完全一样,相同的表头、相同的分页组件、相同的行间距。”在一个成熟的代码库中,大多数新功能都是已有模式的变体,指向一个参照物就传达了所有隐含的需求。
但如果实现方向走偏了怎么办? Boris 的做法非常干脆:不修补,直接回滚所有 Git 改动,然后收窄范围重新开始。
“我回滚了所有改动。现在我只想让列表视图更精简,别的什么都不要动。”
回滚并收窄范围,几乎总是比在一个错误的方案上渐进式修复效果更好。做过架构的人都知道,系统腐化很多时候并非因为方向错了不回头,而是在错误的方向上不断打补丁,最终积累的技术债务比推倒重来还要昂贵。
七、始终坐在驾驶座上:AI执行,人类判断
以上四个阶段贯穿下来,有一个始终不变的原则:虽然执行工作交给了 AI,但“要构建什么”的最终决定权始终牢牢掌握在你手里。
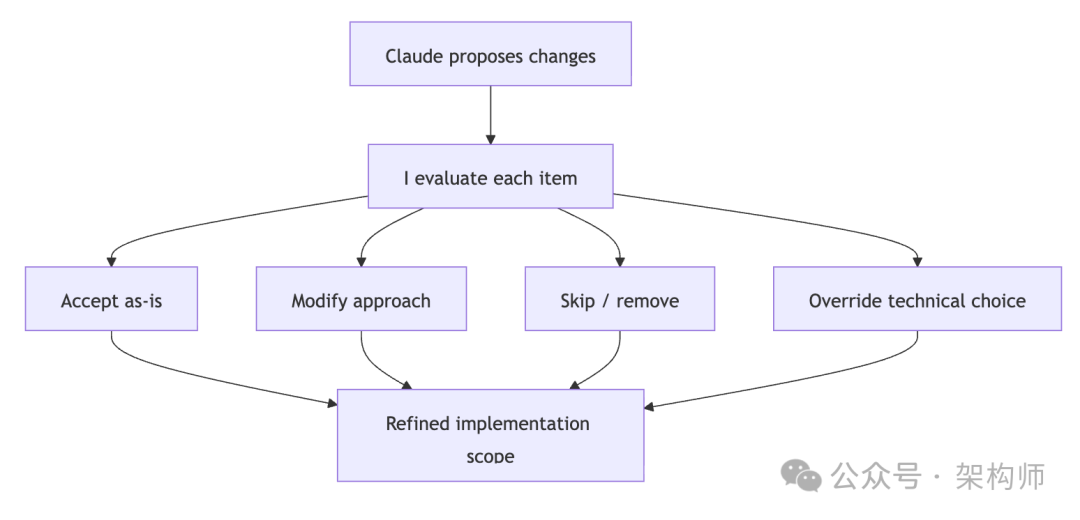
AI 有时会提出技术上完全正确,但对当前项目并不合适的方案——例如过度工程化、修改了公共 API 签名导致其他模块受影响、选择了复杂方案而简单方案就能胜任等。Boris 总结了四种常见的引导和决策方式:

逐项挑选。 AI 识别出多个待解决问题时,逐个过一遍:“第一个问题直接用 Promise.all 解决,不要搞复杂;第三个问题提取成单独的函数;第四和第五个问题忽略,不值得为此增加系统复杂度。”
裁剪范围。 对于方案中锦上添花、非核心的功能直接砍掉:“从方案中删掉下载功能,这个版本我们不做。”
保护现有接口。 当明确知道某些接口不应改变时,设定硬性约束:“这三个函数的签名绝对不能改,应该让调用方来适配,而不是修改库的接口。”
覆盖技术选型。 当你有特定的技术偏好或规范时,直接覆盖 AI 的选择:“使用这个库的内置方法来实现,不要自己重新编写。”
如果你做过技术架构评审,会发现这四种动作正是评审会上最常见的四类意见。区别在于,现在的评审对象从工程师变成了 AI,效率也因此更高——AI 没有情绪,不会觉得你在否定它,修改完方案后它会立即按照新方案执行。
Boris 的总结一语中的:
Claude handles the mechanical execution, while I make the judgement calls.
AI 负责机械性的执行,而你来做关键判断。
这就是 AI 时代对架构师角色的重新定义:你不再是写代码最多的人,甚至可能不是写代码最好的人。你是知道该写什么、不该写什么,以及为何如此的人。
另外,Boris 还有一个做法值得注意:他倾向于将调研、规划和实现放在同一个长会话中完成,而不是拆分成多个独立会话。很多人担心上下文窗口使用超过 50% 后模型性能会下降,但 Boris 表示没有观察到明显的退化——当发出“全部实现”指令时,AI 已经花费了整个会话的时间来构建对系统的理解,这些积累是有价值的。开启新会话反而需要从头开始。而且,plan.md 作为外部文件,即使在上下文被部分压缩后,其内容仍然完整保留,随时可供 AI 重新参考。因此,与其纠结“会话是否需要续命”,不如把关键决策都写进文档。文档不会被压缩,也不会被遗忘。
八、一句话总结
Boris 自己的原话完美概括了这套工作流:
Read deeply, write a plan, annotate the plan until it‘s right, then let Claude execute the whole thing without stopping, checking types along the way.
深度阅读,写出方案,反复批注直到方案正确,然后让 AI 一气呵成地执行完毕。
这里没有魔法般的提示词,没有精心设计的复杂系统指令,也没有花哨的框架。它只是一条有纪律的流水线,将思考与执行(打字) 彻底分开。
从软件架构设计的视角看,这套方法本质上在做一件事:把架构决策从隐性知识转变为显性文档,让 AI 在你清晰定义的边界内进行高效施工。
你不需要 AI 变成一个资深的架构师。你只需要它成为一支高效的、不知疲倦的施工队。而你,则始终稳坐在驾驶座上,掌控着方向。
参考:
• Boris Tane, How I Use Claude Code(2026-02-10):https://boristane.com/blog/how-i-use-claude-code/
写在最后
Boris Tane 的这套工作流,深刻揭示了在AI编程时代,工程师尤其是架构师角色演化的核心:从编码执行者转变为系统边界的定义者和决策质量的把控者。这套方法强调过程与文档,将人的判断力置于循环核心,值得每一个希望在AI辅助下提升工程效能的团队借鉴和讨论。如果你对类似的工作流实践或AI辅助开发有更多想法,欢迎在云栈社区的相应板块与我们交流。
 发表于 2026-2-25 04:00:16
|
查看: 155|
回复: 0
发表于 2026-2-25 04:00:16
|
查看: 155|
回复: 0
