OpenAI推出的Whisper,是一个在多种语音处理任务上表现出色的先进自动语音识别(ASR)系统。它不仅能将语音转换为文字,还集成了语音翻译、语言识别等强大功能,堪称当前语音识别领域的标杆之一。
Whisper模型概述
Whisper是一个基于 Transformer 序列到序列架构的神经网络,专为处理语音数据设计。它被巧妙地构建为一个多任务模型,能够统一处理:
所有这些任务在解码器中都被表示为一系列要预测的标记,这让单个模型就能替代传统语音处理流水线中的多个独立环节。
模型架构
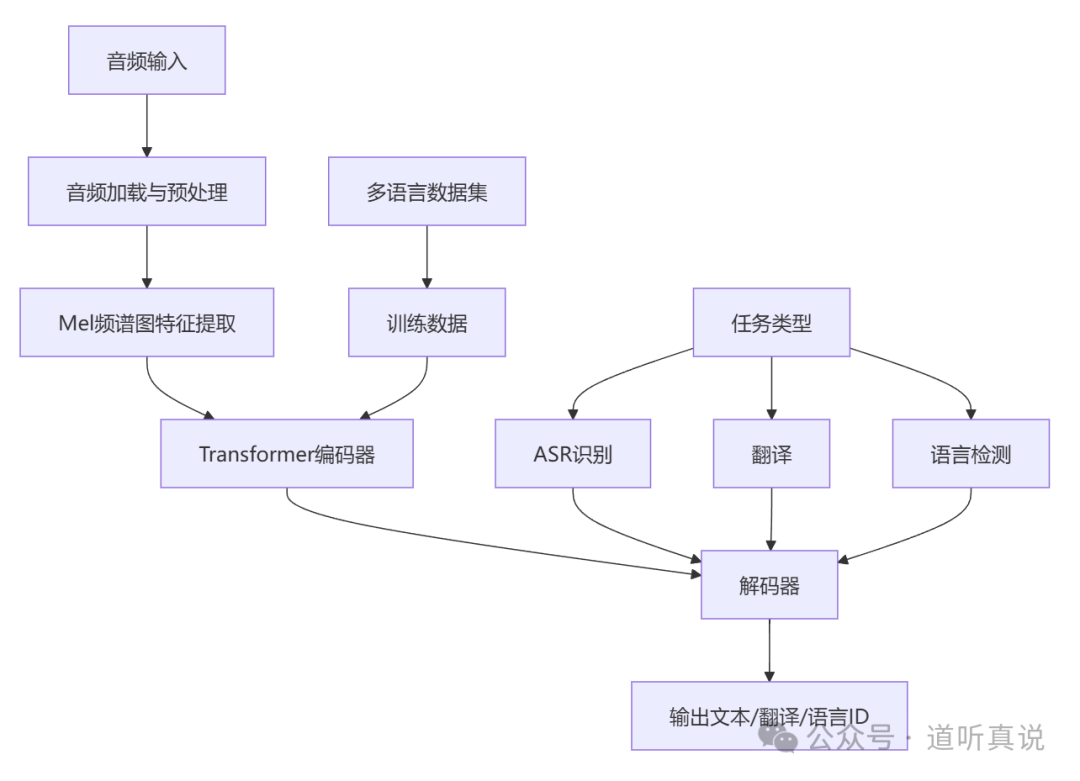
Whisper采用了经典的编码器-解码器 Transformer 架构:
- 编码器:负责处理输入的音频特征(如Mel频谱图),并将其转换为更高级的语义表示。
- 解码器:根据编码器的输出,自回归地生成目标文本序列。
- 注意力机制:让模型能够动态关注输入音频序列中与当前生成文本最相关的部分。
- 多任务统一框架:通过引入特殊的任务指定符标记,模型能在同一架构下执行识别、翻译等不同指令。
训练数据与方法
Whisper的成功很大程度上归功于其训练数据。它在一个大规模、多样化的音频数据集上,通过弱监督学习方法进行训练。这个数据集囊括了多种语言、口音、音质和录音环境,来源极其广泛,确保了模型出色的泛化能力。
数据核心特点:
- 规模巨大:训练数据包含海量小时级的音频。
- 高度多样:覆盖了海量语言、方言及各种真实环境音。
- 弱监督学习:使用从互联网收集的、质量不一的转录文本作为训练标签。
- 多任务学习:模型被同时训练以掌握语音识别、翻译和语言识别等多个任务。
模型变体
为了在不同场景下平衡速度与精度,Whisper提供了多种尺寸的模型:
| 尺寸 |
参数量 |
仅英语模型 |
多语言模型 |
所需VRAM |
相对速度 |
| tiny |
39M |
tiny.en |
tiny |
~1GB |
~10x |
| base |
74M |
base.en |
base |
~1GB |
~7x |
| small |
244M |
small.en |
small |
~2GB |
~4x |
| medium |
769M |
medium.en |
medium |
~5GB |
~2x |
| large |
1550M |
N/A |
large |
~10GB |
1x |
| turbo |
809M |
N/A |
turbo |
~6GB |
~8x |
- .en结尾的模型:专为英语优化,在纯英语任务上(尤其是tiny.en和base.en)表现更佳。
- turbo模型:这是large-v3版本的优化变体,显著提升了转录速度,但准确率略有妥协。
- 注意:turbo模型未针对翻译任务进行训练。
应用场景
凭借其多功能特性,Whisper在多个领域都展现出巨大潜力:
- 语音转文字:实时将会议、访谈、讲座的音频转换为可编辑的文本记录。
- 语音翻译:实现跨语言的实时或离线语音翻译,打破沟通壁垒。
- 语言识别:自动判断一段语音所使用的语种。
- 字幕生成:自动为视频、播客等内容生成精准的字幕文件。
- 语音活动检测:识别音频流中何时开始或结束有人声。
使用方法
安装
首先,通过 pip 安装 Whisper 库:
pip install -U openai-whisper
或者,安装最新的开发版:
pip install git+https://github.com/openai/whisper.git
Whisper 依赖 ffmpeg 来处理音频文件,需要确保系统已安装:
# Ubuntu/Debian
sudo apt update && sudo apt install ffmpeg
# macOS
brew install ffmpeg
命令行使用
安装后,可以直接通过命令行工具进行转录,非常方便:
# 使用turbo模型转录音频文件
whisper audio.flac audio.mp3 audio.wav --model turbo
# 指定语言进行转录(例如日语)
whisper japanese.wav --language Japanese
# 将日语语音翻译成英语文本
whisper japanese.wav --model medium --language Japanese --task translate
Python使用
对于更复杂的集成和自定义处理,使用 Python API 是更灵活的方式:
import whisper
# 最简单的方式:加载模型并转录
model = whisper.load_model("turbo")
result = model.transcribe("audio.mp3")
print(result["text"])
# 更低级别、更可控的访问方式
model = whisper.load_model("turbo")
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio, n_mels=model.dims.n_mels).to(model.device)
# 检测音频的语言
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# 解码音频内容
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
print(result.text)
技术特点
- 通用性强:一个模型应对多种语音任务。
- 多语言支持:支持数十种语言的识别与互译。
- 内置语言识别:无需单独模型。
- 滑动窗口处理:内部使用30秒滑动窗口处理长音频。
- 自回归预测:采用序列到序列的自回归生成方式。
性能与评估
Whisper的性能因语言不同而有差异,通常使用词错误率(WER)或字符错误率(CER)来评估识别准确性。OpenAI在Common Voice 15和Fleurs等公开数据集上对其进行了全面评估,对于翻译任务则提供BLEU分数作为参考。
优势与挑战
优势:
- 准确度高:在多个基准测试中名列前茅。
- 开箱即用的多语言能力:无需为每种语言单独训练模型。
- 架构统一:单模型多任务,简化了部署流程。
- 完全开源:代码和模型权重均采用宽松的MIT许可证发布,促进了 开源实战 和社区发展。
- 鲁棒性好:对背景噪声、不同口音和录音质量有较好的适应性。
挑战:
- 计算资源需求:Large等大模型需要可观的GPU内存和算力。
- 实时性限制:对于严格的低延迟实时应用,可能需要进一步的模型优化或蒸馏。
- 翻译能力不均:并非所有模型变体都擅长翻译任务,且语言对的翻译质量有差异。
总结
Whisper代表了语音识别技术迈向通用化、一体化的重要一步。它将语音识别、翻译和语种检测等多种能力融合于一个简洁的Transformer架构中,大大降低了相关技术的应用门槛。无论是为视频自动配字幕,还是分析多语种会议录音,Whisper都提供了一个强大且易于上手的工具。随着后续迭代,其在效率、精度和语言覆盖面上的表现值得期待。对于开发者而言,深入理解并应用Whisper,无疑是切入智能语音处理领域的一个绝佳实践。如果你对类似的开源AI项目或技术实战感兴趣,欢迎到 云栈社区 交流探讨。
 发表于 2026-2-25 05:25:12
|
查看: 187|
回复: 0
发表于 2026-2-25 05:25:12
|
查看: 187|
回复: 0
