在计算机的世界里,任何程序的运行都可以用两种基本视角来审视:数据如何流动,以及指令如何执行。这两种结构——数据流和控制流——不仅是理解程序行为的关键,更是诸如编译器优化、硬件设计乃至数据库查询等众多领域的基础。无论你是一名正在学习编程的新手,还是希望深入理解系统底层原理的开发者,厘清这两个概念都至关重要。
数据流描述的是数据在计算之间的依赖路径,它关注的是“值从哪来,被谁用”。而控制流则描述了指令执行的先后顺序与跳转路线,它决定了程序执行的“路线图”。本文将带你从C语言的基础代码示例出发,一步步理解这两种结构,并通过丰富的图示,看看编译器是如何利用它们来优化我们的代码的。
一、数据流:追踪数据的“生命线”
什么是数据流
数据流的核心在于数据的依赖关系。它只关心一个数值的生产者和消费者,而不关心它们在时间上的执行顺序。例如下面这段简单的C代码:
a = 5;
b = a + 3;
c = b * 2;
在这里,b 的值依赖于 a 的值,c 的值又依赖于 b 的值。这种“用到”的关系构成了数据流网络。从计算机科学的抽象层面看,任何计算都可以视为数据沿着这张依赖网流动的过程。
数据流图——可视化依赖关系
为了更直观地展现这种依赖,我们可以绘制数据流图。图中包含两种元素:
- 节点:代表一个操作(如加法、乘法)或一个数据(如常量、变量)。
- 边:代表数据流向,箭头从生产者指向消费者。
以表达式 y = (a + b) * c 为例,其数据流图如下:
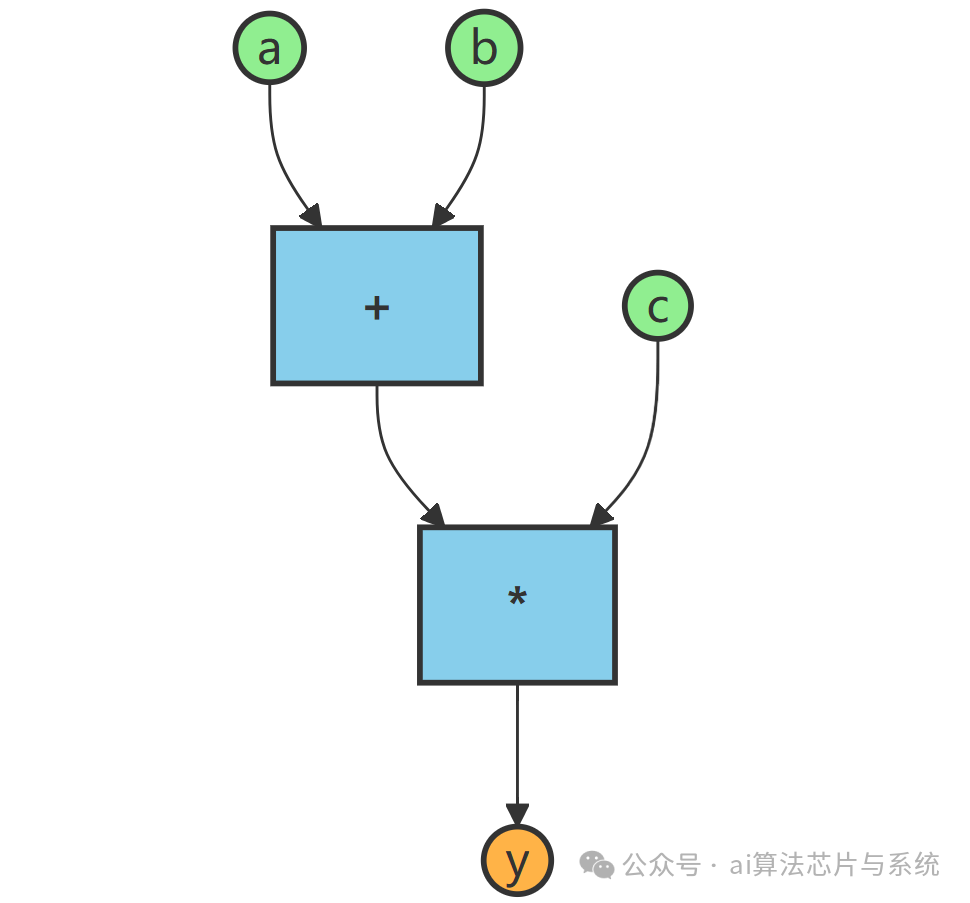
图中,绿色圆形节点是输入数据 a、b、c,蓝色方形节点是操作符 + 和 *,橙色圆形节点是最终结果 y。箭头清晰地指明了数据的流动路径。
数据流图的性质
数据流图通常具有两个重要特性:
- 有向无环图:由于一个计算的结果通常不会直接或间接地依赖自身(循环是特殊情况),因此数据流图大多是有向无环图。
- 数据驱动:只要一个节点的所有输入数据都准备就绪,它就可以立即执行,无需等待其他不相关的节点。这为并行计算提供了理论基础,也是硬件设计(如FPGA)和分布式系统中的核心思想。
二、控制流:程序执行的“导航图”
什么是控制流
与数据流关注“数据”不同,控制流关注的是“指令”的执行顺序。它描述了程序在遇到条件或循环时,如何决定下一步执行哪条指令。请看下面这段带 if 语句的C代码:
int x = a + b;
int y = x * 2;
if (y > 0) {
z = y + 10;
} else {
z = y - 10;
}
return z;
计算机执行时,会根据 y 的取值决定走哪条分支。这种“决策下一步去哪儿”的过程就是控制流。它是冯·诺依曼体系结构的核心,也是所有顺序执行程序的基石。
基本块——控制流的基本单元
为了分析控制流,编译器首先会将代码切分成一个个基本块。一个基本块是一段顺序执行的指令序列,它有两个关键特征:
- 只有一个入口:只能从该块的第一条指令进入。
- 只有一个出口:只能从该块的最后一条指令离开(可能是跳转或返回)。
基本块内部没有跳转,所有指令都会按顺序执行一次。上面那段代码可以被划分为四个基本块,如下图所示:
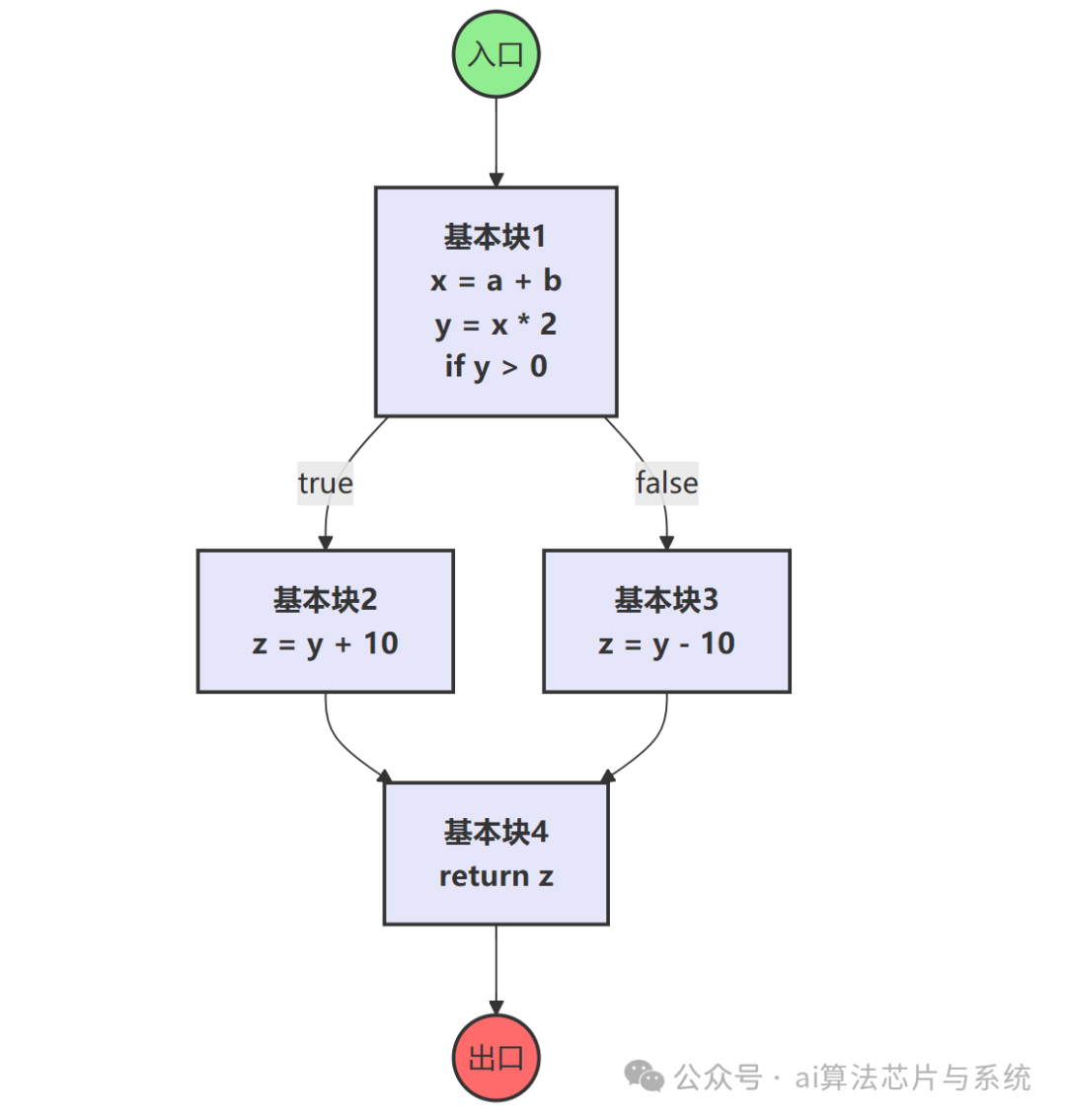
图中,绿色圆形是入口节点,红色圆形是出口节点,紫色长方形是基本块。实线和虚线分别代表条件为真和为假时的跳转路径。
控制流图——将跳转路线可视化
将基本块作为节点,块之间的跳转关系作为边,我们就得到了控制流图。它清晰地勾勒出程序所有可能的执行路径。
控制流与数据流的内在联系
这里需要强调一个关键点:控制流图并不孤立存在,它的每个基本块内部都隐含着一个数据流图。基本块内的指令之间存在着数据依赖关系,这些依赖就构成了该块内部的数据流图。控制流图决定了哪些基本块(及其内部的数据流)会被执行。因此,控制流是更高层次的抽象,它包含了数据流。理解这种包含关系,才能完整把握程序的运行机制。
三、数据流 vs 控制流:核心对比
为了让区别更清晰,我们用一张表格来总结:
| 维度 |
数据流 |
控制流 |
| 关注点 |
数据从哪来到哪去 |
指令执行的先后顺序 |
| 核心元素 |
操作、数据依赖 |
基本块、分支、循环 |
| 图结构 |
数据流图 (DFG) |
控制流图 (CFG) |
| 节点含义 |
单个操作(如加、乘) |
基本块(多条顺序指令,用长方形表示) |
| 边含义 |
数据依赖(结果传递) |
控制依赖(条件/无条件跳转) |
| 典型性质 |
多为 有向无环图 (DAG) |
可能有环,有 入口/出口 |
| 执行语义 |
数据驱动:数据就绪即可执行 |
程序计数器驱动:按顺序或跳转执行 |
四、编译器如何利用它们优化你的代码?
编译器(如 GCC、Clang)的核心任务之一就是优化。数据流图和控制流图是其进行各种优化分析的强大工具。
1. 常量传播——数据流图的威力
考虑以下代码:
int a = 5;
int b = a + 3;
int c = b * 2;
int d = c - a;
编译器为其构建数据流图后,可以进行追踪:
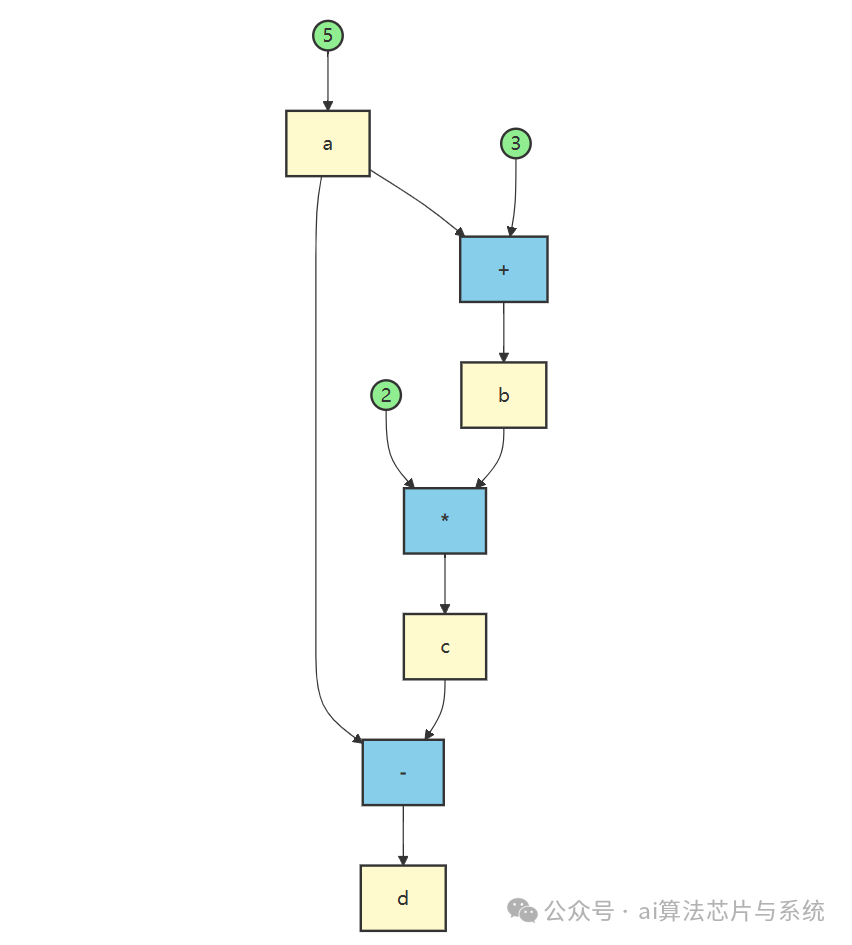
通过追踪数据流,编译器发现 a 恒为5,因此 b 恒为8,c 恒为16,最终 d 恒为11。于是,整段代码可以直接被优化为 d = 11,这就是常量传播优化。
2. 死代码消除——控制流图的功劳
再看这段代码:
int foo(int x) {
int y = x * 2;
if (0) { // 条件永远为假
y = y + 1;
}
return y;
}
其控制流图如下,清晰显示了一个不可达的基本块:
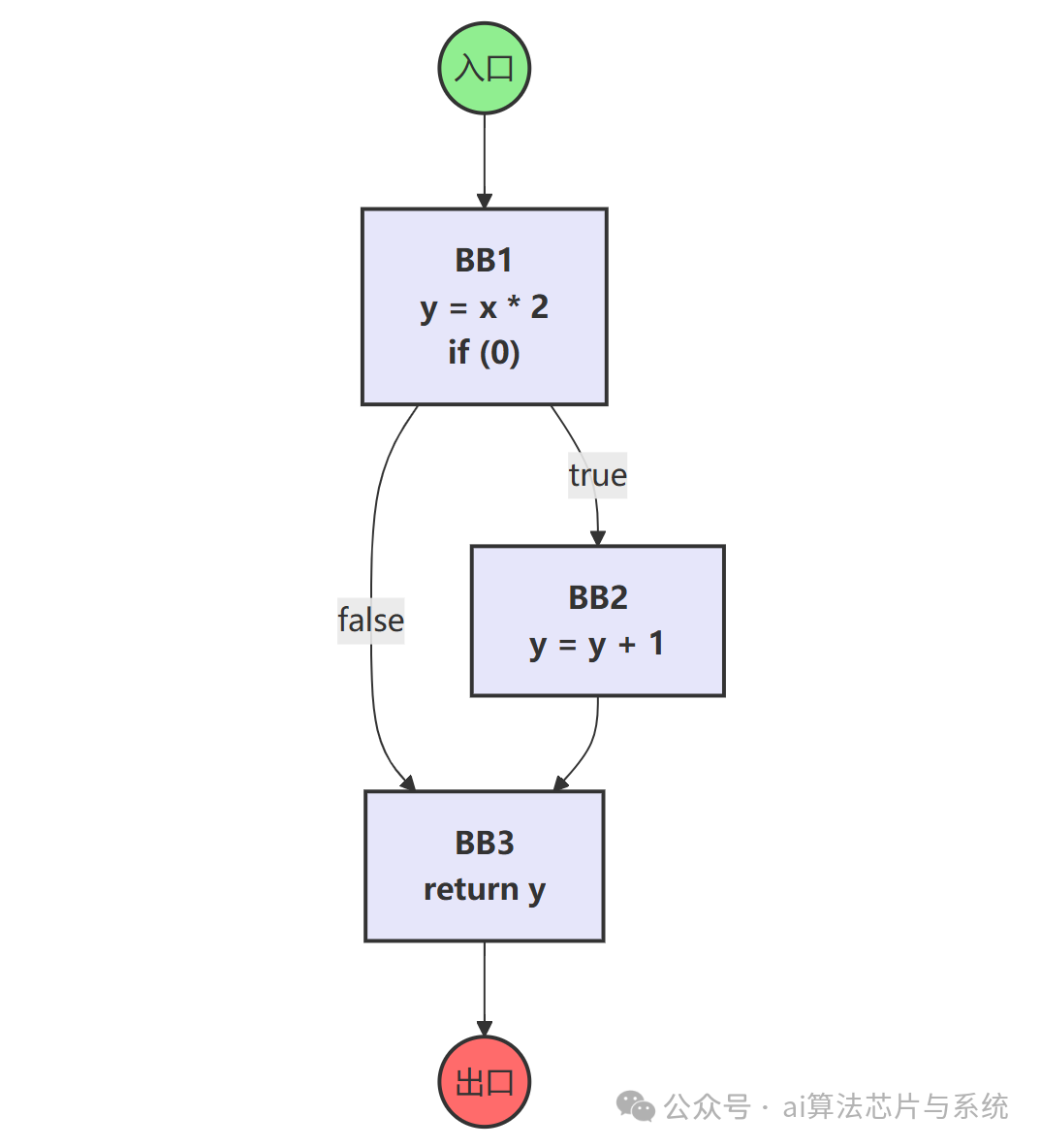
编译器分析控制流图后,发现 if (0) 分支永远无法进入,因此基本块2是“死代码”,可以直接删除。优化后的控制流图变为:
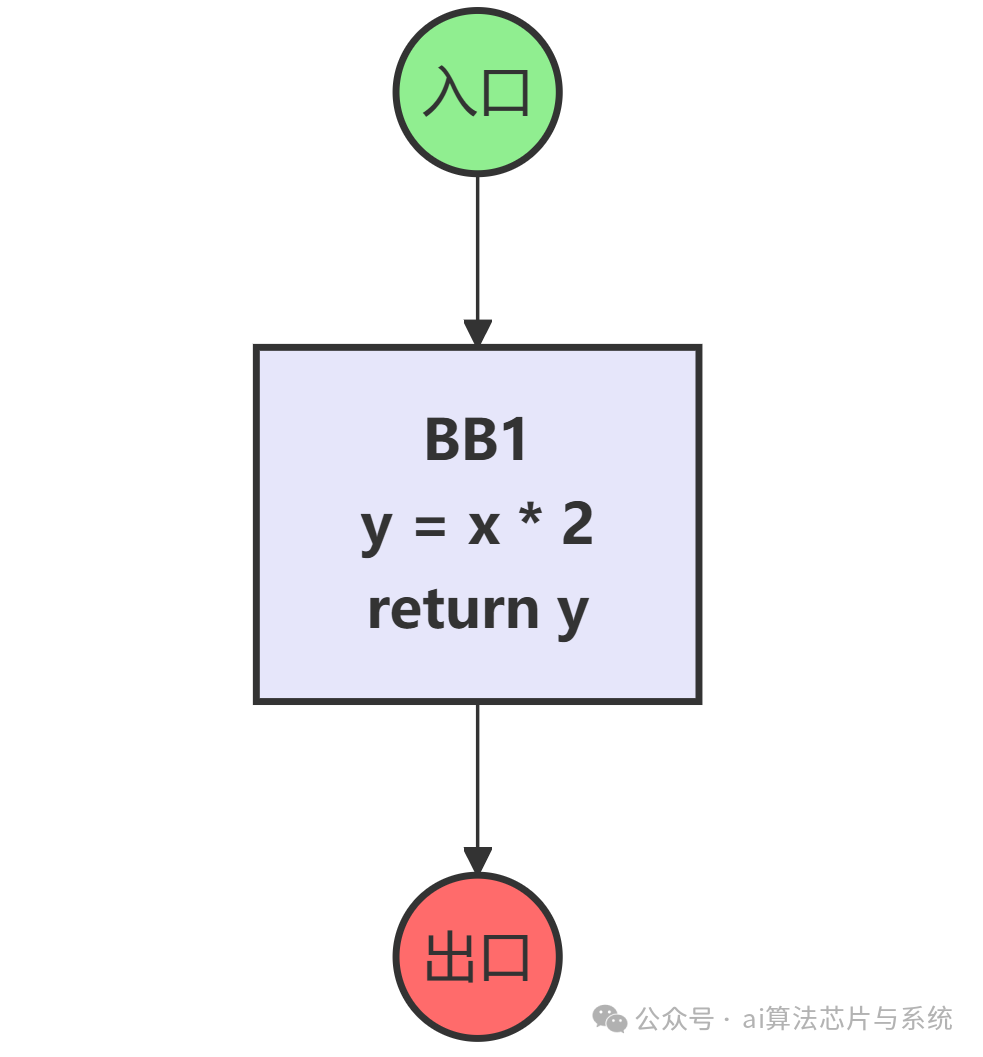
这就是死代码消除优化,让程序更精简。
3. 两者联手:更强大的优化
许多高级优化需要两者结合。例如到达定值分析,它需要分析在控制流的每条路径上,变量的某个赋值能否“到达”特定位置。这需要在控制流图上传播信息,同时考虑每个基本块内部的数据流。基于此,编译器可以消除从未被使用的赋值,实现更彻底的优化。这类分析在C/C++等语言的编译器后端中非常常见。
五、无处不在的通用结构
数据流和控制流并非编译器专属,它们是描述计算的两种通用语言,广泛存在于计算机科学的各个领域。
数据流无处不在
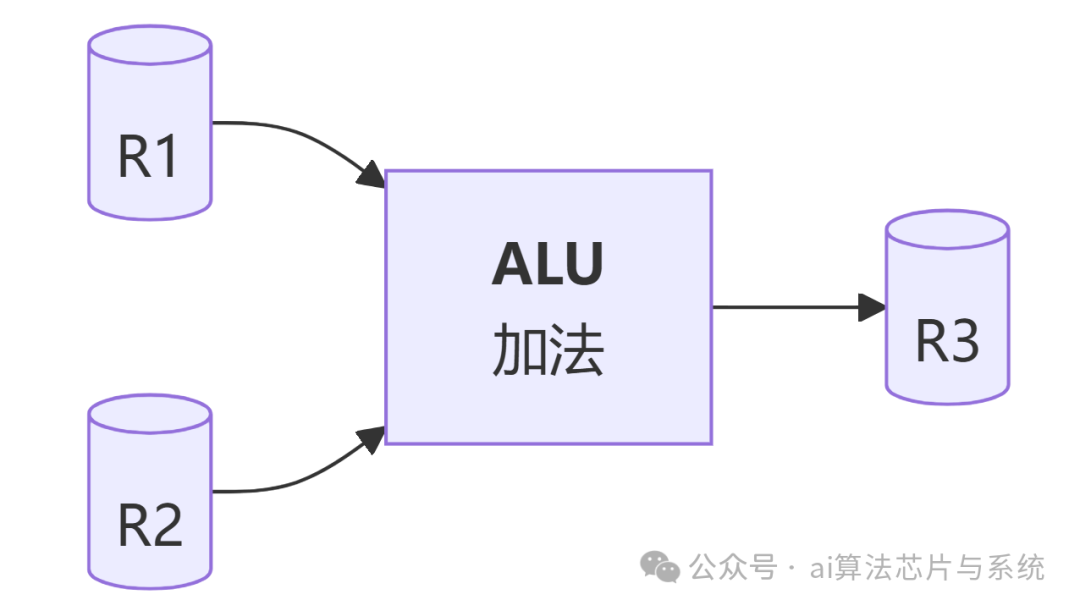
- 硬件数据路径:CPU或FPGA设计中,数据在寄存器与运算单元间的流动。
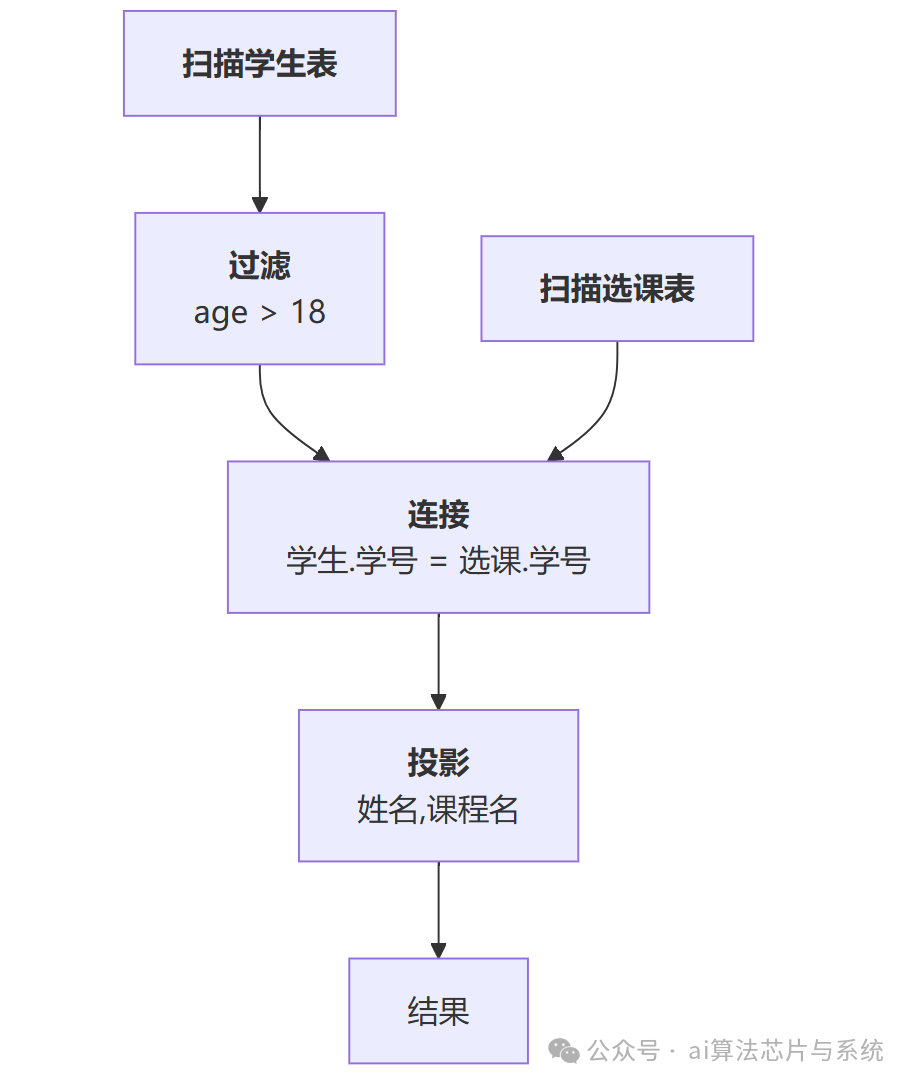
- 数据库查询计划:SQL查询被转换为一系列算子(扫描、连接、过滤),数据在算子间流动。
- 图形渲染管线:顶点和像素数据依次经过顶点着色器、光栅化、像素着色器等阶段。

控制流常伴数据流
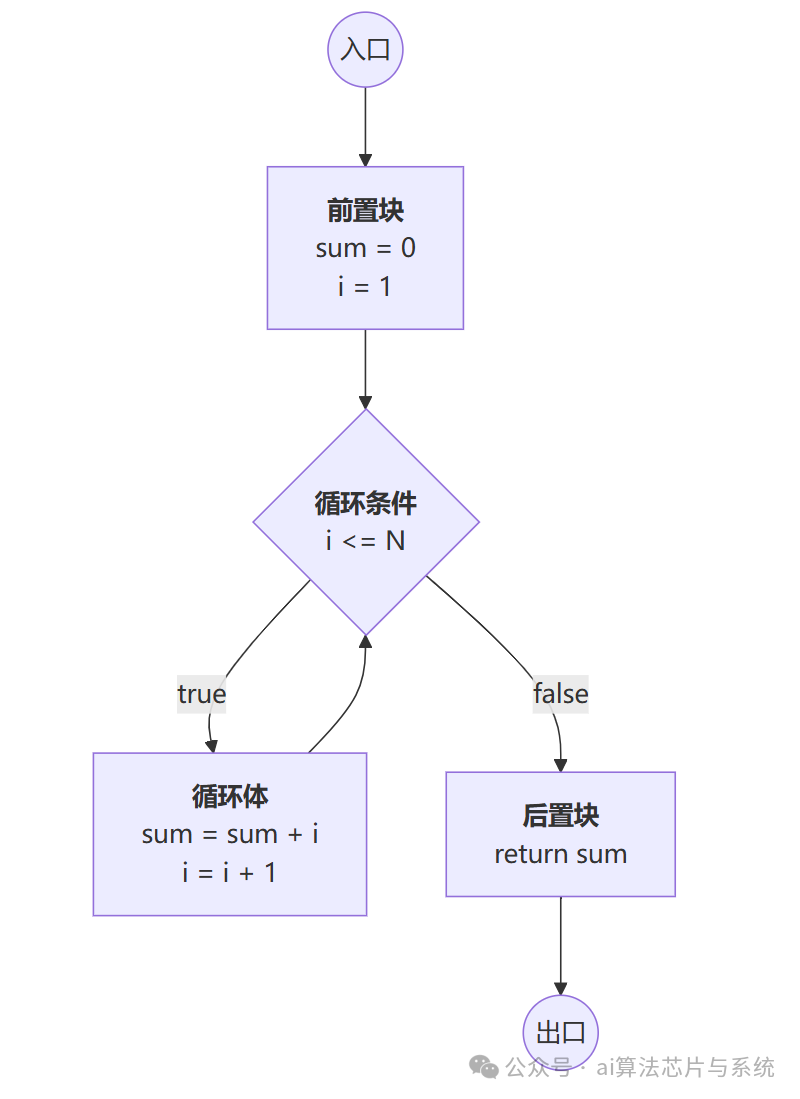
- 编程语言中的循环:循环条件控制迭代次数(控制流),循环体内进行数据计算(数据流)。
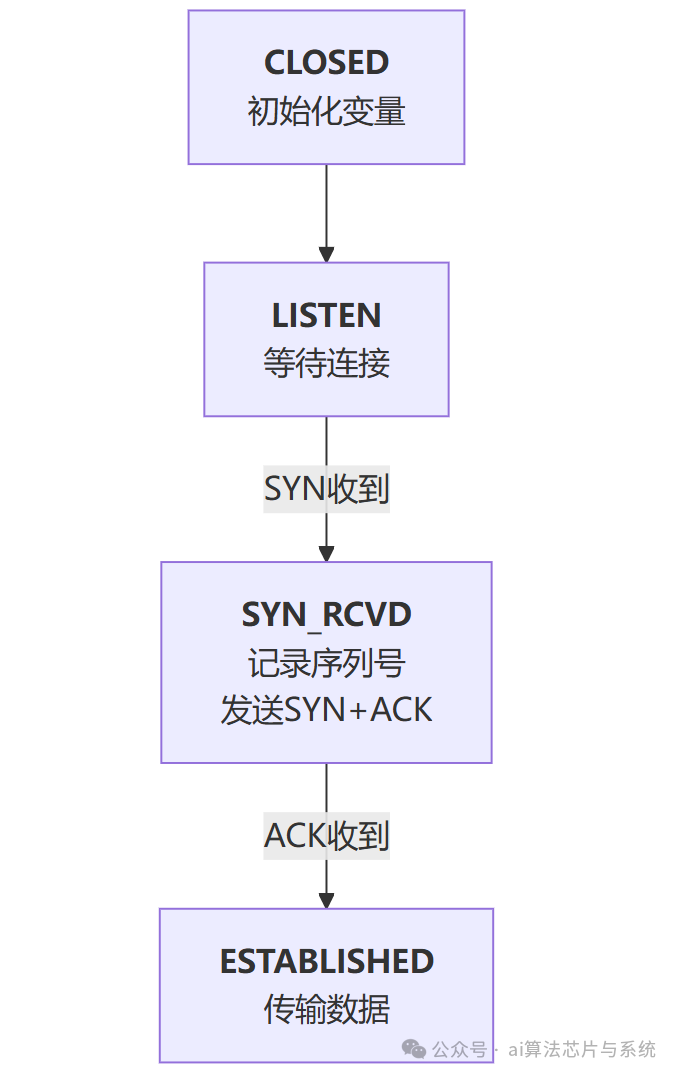
- 网络协议状态机:如TCP协议的状态迁移(控制流),每个状态内进行序列号记录、数据收发(数据流)。
| 领域 |
数据流的体现 |
控制流的体现(常含数据流) |
| 硬件设计 |
数据路径:寄存器与ALU间的数据流动 |
状态机:状态迁移触发,状态内进行数据运算 |
| 数据库 |
查询计划中的数据传递 |
查询中的条件分支(CASE WHEN),分支内包含数据操作 |
| 图形学 |
渲染管线:数据流经各着色器 |
着色器程序中的分支和循环,内部有数据运算 |
| 编程语言 |
表达式求值中的数据依赖 |
控制流语句(if, while, for),每个分支/循环体内有数据流 |
总结
我们从基础的代码片段出发,梳理了数据流与控制流这对核心概念。数据流及其数据流图揭示了计算的内在依赖,其数据驱动的特性是并行的关键;控制流及其控制流图则描绘了程序执行的宏观路径,其基本块内部又隐藏着精细的数据流图。
对于编译器而言,这两者是进行从常量传播到死代码消除等各种优化的基石。更重要的是,它们作为一种通用的分析框架,贯穿了从算法设计、硬件架构到网络协议等几乎所有的计算领域。深刻理解数据流与控制流,就如同掌握了阅读计算机系统“蓝图”的通用语言。
希望本文能帮助你建立起对这两个基础概念的清晰认知。如果你对编译器原理或系统底层设计有更多兴趣,欢迎在云栈社区与更多开发者交流探讨。
 发表于 2026-2-26 03:40:15
|
查看: 224|
回复: 0
发表于 2026-2-26 03:40:15
|
查看: 224|
回复: 0
