AI市场已经发生了根本性变革。过去,AI处理主要在云端完成。终端设备从传感器收集数据并将其发送到云端进行推理处理和决策,结果再被发送回终端设备。这种方法需要巨大的带宽才能将海量数据传输到云端。
如今,边缘设备越来越多地使用AI推理技术,以实现快速实时响应并提高数据隐私和安全性,同时避免因连接云端而产生的延迟和成本。这也显著降低了功耗,使其适用于电池供电的物联网应用。因此,边缘AI具备了自主性、低延迟、低功耗、低成本、更低云端带宽依赖以及更高安全性的优势,这对众多新兴应用极具吸引力。
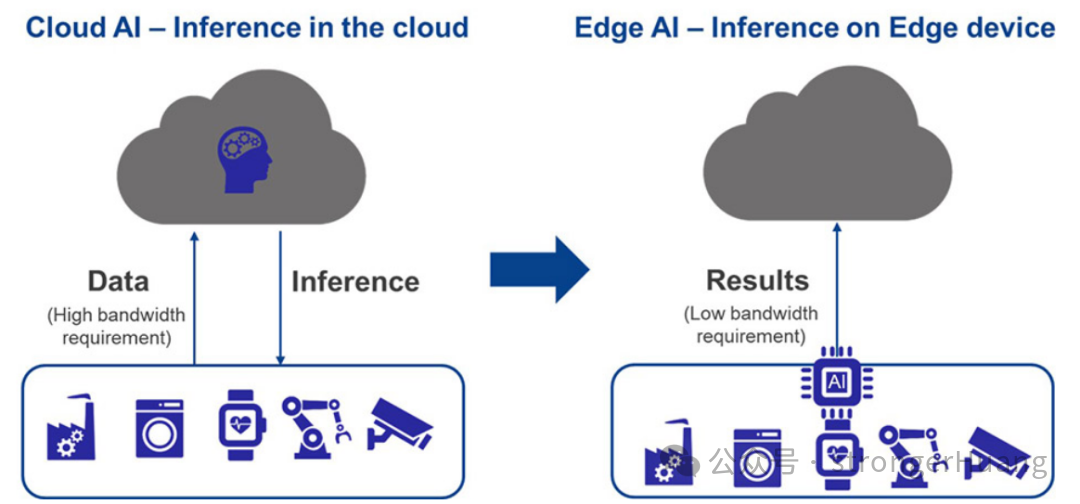
图 1:从云端的推理迁移到边缘的推理
MCU正越来越多地用于边缘AI。与MPU相比,它们提供了更好的实时响应能力、更低的功耗与成本,以及能简化产品设计、降低开发和BOM成本的全面集成解决方案,这使其成为低功耗和成本敏感型应用的理想选择。
现已推出具有集成硬件加速器的高性能MCU,它们可以高效处理神经网络所需的线性代数运算,例如点积、快速且并行的矩阵乘法、卷积和转置。此外,针对资源有限的MCU而优化的小型神经网络模型、软件库和生态系统解决方案也已成熟。
使用RA8P1 AI加速MCU构建高能效AI应用
RA8P1 MCU是瑞萨电子首款具备AI加速能力的单核与双核MCU,集成了高性能Arm® Cortex-M85®(CM85)和Cortex-M33(CM33)CPU内核,以及Arm Ethos™-U55神经网络处理器(NPU)。它是边缘AI和物联网应用的理想选择,能够在AI/ML、DSP和标量性能方面提供显著的提升,同时维持更低的功耗。
RA8P1 MCU基于先进的台积电22nm ULL工艺构建,提供了前所未有的7300+ CoreMark原始性能和256 GOPS的AI性能,恰好满足了边缘AI应用对高性能与低功耗的双重需求。
这类MCU结合了大容量内存和丰富的外设集成,可以直接在芯片上实现要求苛刻的语音、视觉AI和实时分析应用程序。双核RA8P1 MCU能够实现强大的处理能力、两个内核之间的高效任务划分以及优化的实时性能。此外,它还内置了高级安全性功能、不可变内存和TrustZone技术,以构建真正安全的AI应用程序。
RA8P1中嵌入的Ethos-U55 NPU是一款专用处理器,经过优化可与CPU内核协同工作,以更高效率、更低功耗执行神经网络模型的核心运算,例如矩阵乘法和卷积。Ethos-U55针对AI模型中常用的低精度算术(8位整数)进行了优化,可在不降低推理精度的前提下,有效降低计算复杂性、内存占用和功耗。
瑞萨电子已成功展示了使用Ethos-U55进行推理处理的RA8P1 MCU所带来的性能飞跃。在一些AI/ML用例中,Ethos-U55 NPU相比CPU内核展现了显著的性能提升。
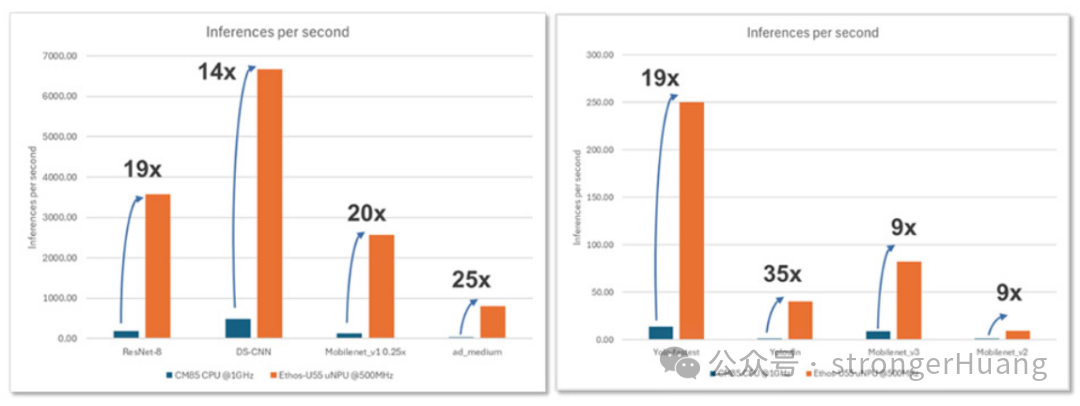
图 2:与CPU内核相比,Ethos-U55 NPU的AI性能显著提升
使用的模型包括:
- 图像分类:ResNet8、MobileNet v2、MobileNet v3
- 关键词识别:DS-CNN
- 视觉唤醒词:MobileNet v1
- 对象检测:Yolo_fastest、Yolov8N
- 异常检测:ad_medium
相关资源:
使用RUHMI框架实现更快的应用程序开发
RA8P1 AI解决方案采用了高度可配置和优化的RUHMI框架,为AI开发人员提供了加速、高效AI开发所需的所有工具。这是瑞萨电子首个用于MCU和MPU的综合AI框架,并集成到e² studio中,能以与框架无关的方式生成和部署高度优化的神经网络模型。
RUHMI支持模型优化、量化、图编译和转换为MCU友好格式。它包括对常用ML框架TensorFlow Lite、PyTorch和ONNX的原生支持,并提供了针对RA8P1优化的即用型应用程序示例和模型。
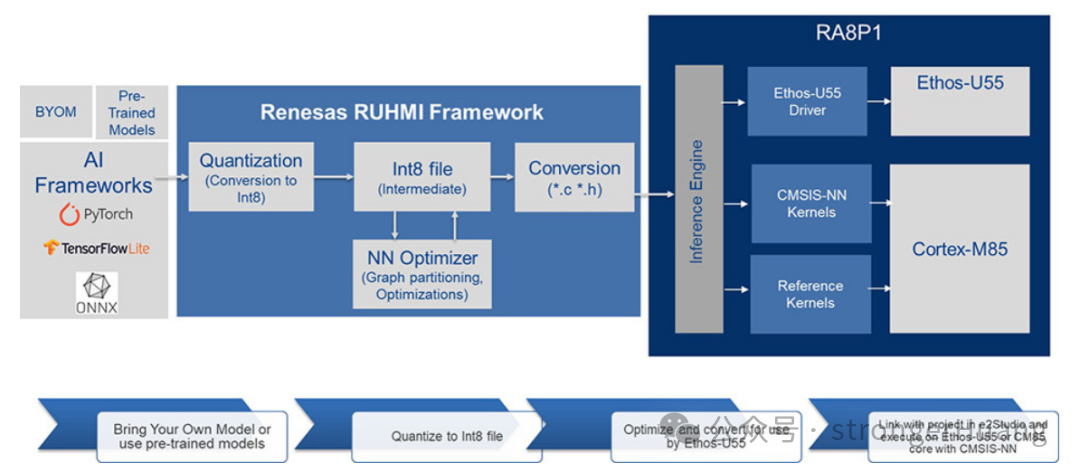
图 3:使用瑞萨电子RUHMI框架的AI工作流程
使用RUHMI框架的典型AI工作流程如下:
- 模型优化和编译(离线):将通过TensorFlow Lite、PyTorch或ONNX等常用框架获得的预训练AI模型输入。使用RUHMI优化和转换工具,首先将模型量化为Int8中间格式并进行优化。此过程涉及图分区、在NPU和CPU之间分配算子,以及编译为MCU友好格式(通常为.c/.h文件)。
- 数据输入和预处理:RA8P1 MCU捕获原始输入数据(来自摄像头的图像、来自麦克风的音频),并由高性能Cortex-M85内核进行预处理,以备输入到AI模型。
- 在NPU上执行:然后,CPU内核将预处理后的输入数据和编译后的AI模型的命令流发送到Ethos-U55 NPU执行。NPU读取命令流,并使用输入数据和模型权重(通常存储在本地内存中)处理神经网络的每一层。
- 输出和后处理:一旦NPU处理完神经网络的所有层,它就会将推理结果输出回主CPU,主CPU随后可以执行任何必要的后处理和操作。
RA8P1支持的AI应用
RA8P1 MCU凭借其高推理性能、低功耗和实时处理能力,成为各个细分市场中多种AI应用的理想选择。
以下是RA8P1支持的一些关键应用:
- 语音人工智能:关键词识别、语音识别、语速识别、降噪、发音人识别。
- 视觉AI:目标检测、图像分类、手势识别、人脸识别、图像分析、驾驶员/车辆监控。
- 实时分析:异常检测、振动分析、预测性维护。
- 多模态应用:具有语音和视觉功能的智能HMI、使用语音和视觉检测事件的增强型监控摄像头、结合视觉和听觉输入以进行环境感知和交互的机器人技术。
应用示例1:RA8P1上的图像分类
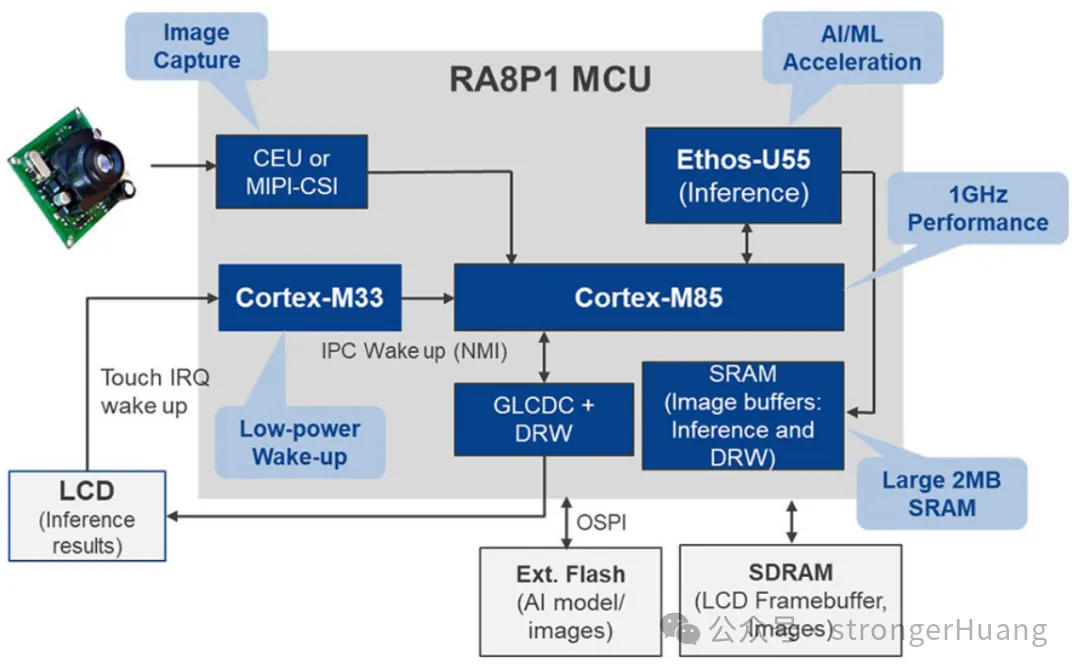
图 4:图像分类系统框图
上图展示了图像分类应用程序的实现。RA8P1将构建此视觉AI应用所需的CPU内核、NPU、内存和外设集成在单个芯片上。应用程序会分析输入图像并为其分配预定义的标签或类别。神经网络模型在庞大的图像数据集(其中每张图像都标有类别)上进行训练,然后部署在RA8P1 MCU上。
为了进行推理,新的输入图像被馈送到模型中,并经由训练好的网络各层进行处理。输出层会提供所有类别的概率分布,并将概率最高的类别分配为图像的标签。然后,可以将此输出数据(图像标签和置信度)发送到显示器或云端。在具体的实施案例中,与仅使用CPU内核相比,使用Ethos-U55 NPU实现了高达33倍的推理速度提升。
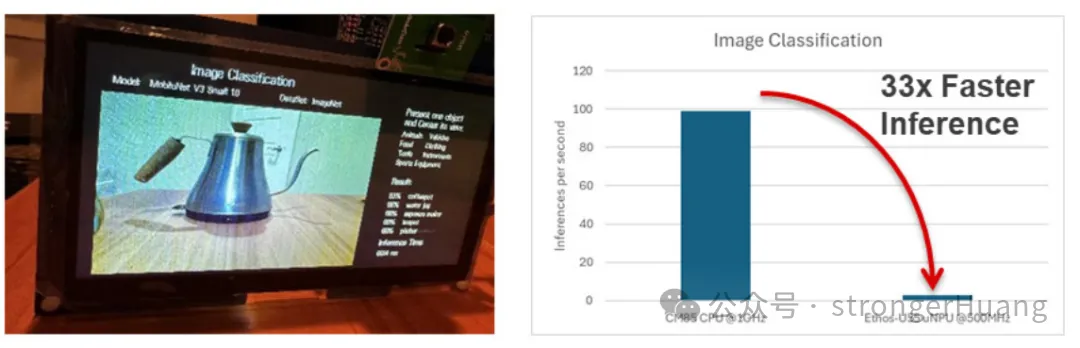
图 5:RA8P1上的图像分类和性能比较,NPU与CPU
图像分类可广泛应用于以下场景:
- 安防 – 危险品识别、人员识别、异常检测
- 零售 – 按类别创建产品目录、库存管理
- 农业 – 识别作物病害、植物分类
- 智慧城市 – 识别交通信号灯/标志和行人
- 智能家电 – 识别冰箱内的物体
应用示例 2:RA8P1上的驾驶员监控系统
此应用示例展示了Nota-AI驾驶员监控系统(DMS),这是一种旨在提升道路安全的车内解决方案。利用RA8P1,Nota-AI DMS可以检测未经授权的驾驶员、驾驶员疲劳、使用手机的情况以及驾驶员分心行为(如吸烟)。
得益于RA8P1的更高性能,该应用中使用的四种模型(人脸检测、人脸特征点、眼睛特征点和手机检测)的推理性能提升了4倍到惊人的24倍。
DMS可应用于仪表盘摄像头、车辆行驶记录仪和专用的驾驶员监控系统。
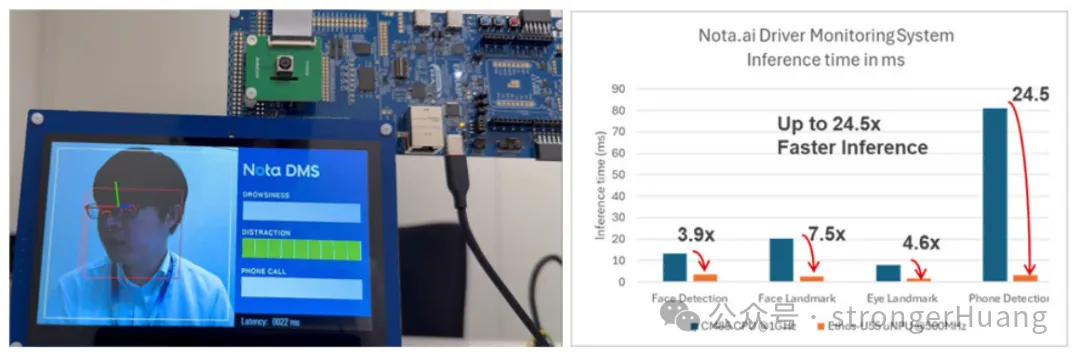
图 6:RA8P1上的驾驶员监控系统NPU与CPU性能比较
上述两个视觉AI应用都充分利用了RA8P1 MCU上的各类资源:
-
通过图像传感器进行高效的输入图像采集:
- RA8P1包含一个专用的MIPI CSI-2接口(带图像缩放单元)或16位CEU并行摄像头接口,用于捕获原始图像输入数据。
-
使用Ethos-U55 NPU进行高性能推理处理:
- RA8P1 MCU上的Ethos-U55 AI加速器分担了CPU内核的工作负载,能够以更高效率和更低功耗处理复杂的AI模型。它从MIPI CSI-2或并行CEU接收处理后的图像。
- 预训练的AI模型(例如MobileNet系列)使用RUHMI工具针对RA8P1进行了优化,并加载到NPU上。
- Ethos-U55 NPU以极高的速度(高达256 GOPS)和高能效执行实际的AI推理。
-
使用Arm Cortex-M85和Cortex-M33加速应用程序处理:
- 配备Arm Helium矢量扩展的高性能1GHz CM85内核可用于输入图像/音频数据以及推理结果的预处理和后处理。Ethos-U55不支持的算子也可以由CM85内核在回退模式下执行,并受益于CMSIS-NN库的加速。它还负责执行主应用程序代码。
- 250MHz的Cortex-M33内核可用于处理低功耗唤醒和系统管理任务。
-
通过片上存储器和存储器接口高效存储数据:
- 片上大容量1MB MRAM和2MB SRAM对于存储AI模型权重、图像数据和中间激活值至关重要。与闪存相比,集成的嵌入式MRAM具有更快的写入速度、更高的耐用性和更好的数据保持能力。
- MCU还支持适用于更大模型的高吞吐量外部存储器接口(支持XIP和动态解密的OSPI以及32位SDRAM)。
-
用于LCD面板的高级图形外设:
- GLCDC(具有并行RGB或MIPI DSI接口)和2D绘图引擎可用于处理和渲染图像及推理结果到LCD显示屏。
-
灵活的连接选项:
- 提供多种连接选项,可将推理结果、图像或警报/通知传输到本地设备或云端,以供进一步存储或分析。
相关资源:
总结
边缘AI应用因采用AI加速MCU而受益匪浅。它们在实时性、低功耗和安全性至关重要的应用场景中具有关键价值。低功耗MCU的加入,无疑是AI解决方案领域的一次变革。
全新的RA8P1 MCU显著降低了延迟,保障了数据隐私,并最大限度地降低了功耗,使其成为电池供电应用的理想选择。整个开发流程由瑞萨电子全面的RUHMI框架提供支持,该框架能帮助开发人员高效地优化并将其AI模型部署在RA8P1硬件上,加速产品上市。想了解更多关于嵌入式人工智能和C/C++开发的实践与讨论,欢迎访问云栈社区与更多开发者交流。
 发表于 2026-2-26 04:35:04
|
查看: 238|
回复: 0
发表于 2026-2-26 04:35:04
|
查看: 238|
回复: 0
