当一个大语言模型完成训练后,真正发挥其“聪明才智”的阶段便是推理(Inference)。在这个阶段,模型接收我们的输入(Prompt),并基于所学知识生成连贯的文本输出,整个过程不更新模型参数,其核心是“前向计算”与“文本生成”的紧密结合。
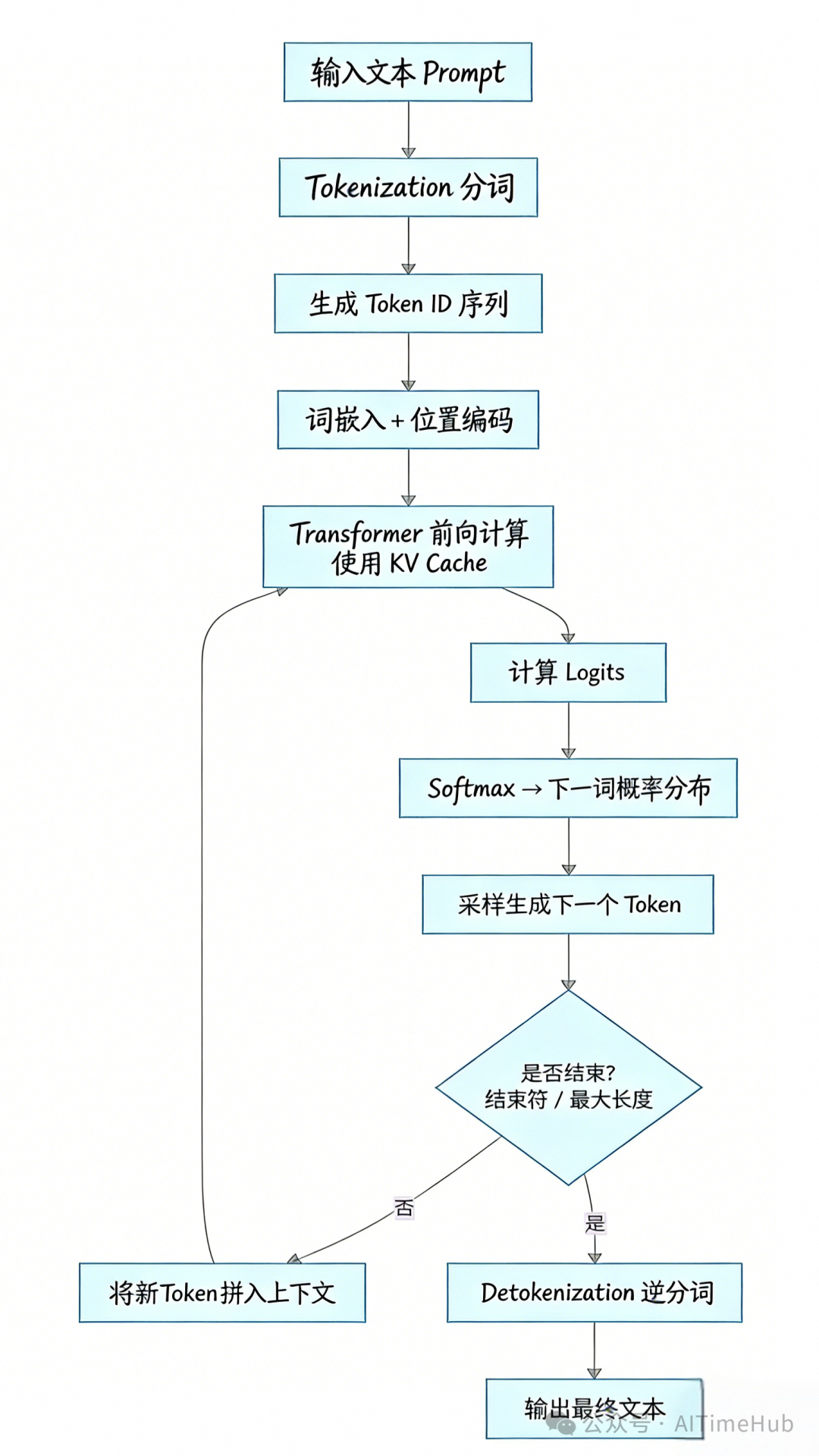
为了高效地完成这一任务,典型的Transformer架构大模型(如GPT系列)的推理过程被清晰地划分为两个主要阶段:Prefill(预填充)阶段和Decode(解码)阶段。这两个阶段如同精密的流水线,包含了以下6个核心环节:
Prefill(预填充)阶段
这个阶段负责对输入提示(Prompt)进行一次性、完整的处理,为后续的逐词生成打好基础。
-
输入预处理:将人类自然语言转换为模型能理解的数字格式。
- 分词:将输入文本切分成模型词汇表中的基本单位(Token,可以是子词或字符),并为每个Token映射一个唯一的数字ID,形成Token ID序列。
- 添加特殊标记:根据模型约定,在序列的开头、结尾或特定位置插入起始符(如
<bos>)、结束符(如<eos>)、分隔符等控制符号。
- 位置编码:为序列中的每个Token添加位置信息,让模型能够理解词语之间的先后顺序关系。
-
词嵌入:通过一个嵌入查找表,将上一步得到的Token ID转换为高维的、蕴含语义信息的向量表示。这些向量是模型进行数学计算的基础。
-
Transformer前向计算:将词嵌入向量(连同位置编码)输入到模型的Transformer层中。经过多层多头自注意力机制和前馈神经网络的处理,模型对整个输入上下文进行深度的语义建模,捕捉词与词之间复杂的依赖关系,从而形成对当前对话或任务背景的全面“理解”。
Decode(解码)阶段
在Prefill阶段完成后,模型进入自回归的解码阶段,开始逐个生成输出Token。
-
输出概率计算
- 模型最后一层输出的是一组原始的、未归一化的分数,称为 Logits。
- 对Logits应用Softmax函数,将其转换为整个词汇表上的概率分布。这个分布清晰地表明了在当前上下文中,每一个可能的词作为下一个输出Token的概率有多大。
-
解码生成(自回归循环)
这是推理过程的核心循环,模型像“接龙”一样生成文本:
- 采样策略选择:根据设定的生成策略,从概率分布中选取下一个Token。常见策略包括贪心搜索(直接选概率最高的)、束搜索(保留多个候选序列)、Top-K采样(从前K个高概率词中选)、Top-P(核采样,从累积概率达到P的词中选)以及温度调节(控制输出的随机性与创造性)。
- KV Cache缓存:为了极致优化性能,在生成每个新Token时,模型会缓存历史序列在注意力机制中计算出的Key和Value向量。在下次前向计算时直接复用这些缓存,避免了对已生成上下文的重复计算,从而大幅提升解码速度。这是像DeepSeek等模型实现高效推理的关键技术之一。
- 循环迭代:将新生成的Token拼接到已有的输入序列末尾,作为新的上下文,重复进行前向计算、概率计算和采样。这个过程循环往复,直到生成结束符(如
<eos>)或达到预设的最大生成长度。
-
输出后处理
- 逆分词:将最终生成的Token ID序列,通过词汇表反向映射,还原成人类可读的自然语言文本。
- 格式规整:去除特殊的控制符号,修正标点与空格,优化语句的通顺度,最终呈现给用户一个清晰、完整的回答。
为了让上述流程更直观,我们通过下面这张流程图来全景式地回顾大语言模型从接收输入到产生输出的完整推理路径:
理解大模型推理的全流程,对于进行性能优化、设计高效的RAG(检索增强生成)系统或构建稳定的AI应用都至关重要。希望这篇梳理能帮助你建立起清晰的技术认知。如果你想深入探讨更多AI工程化实践,欢迎来到云栈社区与其他开发者一起交流。 |  发表于 2026-2-27 04:51:43
|
查看: 287|
回复: 0
发表于 2026-2-27 04:51:43
|
查看: 287|
回复: 0
