美国时间2月23日,AI初创公司Anthropic在其官方博客发布了一篇措辞强硬的声明,直接点名了三家中国AI公司——DeepSeek、月之暗面(Moonshot AI)和MiniMax,指控它们对自家的大语言模型Claude发动了“工业级知识蒸馏攻击”。
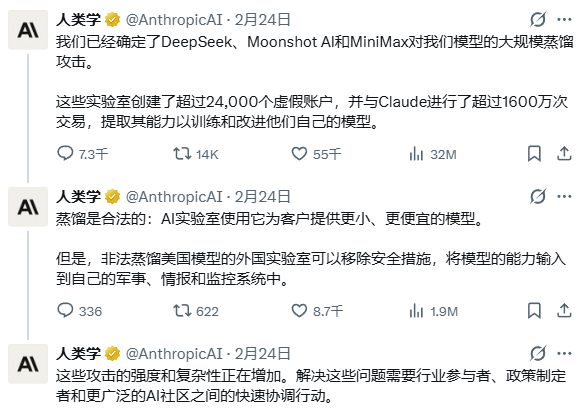
根据Anthropic的描述,这三家公司通过创建超过2.4万个虚假账户,与Claude模型完成了超过1600万次交互。其目的是为了提取Claude的核心能力,用于训练和优化他们自己的模型。声明进一步指出,这类行为不仅违反了服务条款,提取出的模型能力甚至可能被用于“军事、情报和监控系统”,从而将问题提升到了国家安全层面。
这一指控迅速在科技圈引发了广泛讨论。
然而,第一个站出来回应的并非被指控的中国公司,而是埃隆·马斯克。他在社交媒体平台X上直接转发了相关报道,并评论道:“Anthropic因大规模窃取训练数据而被认定有罪,并为此支付了数十亿美元的和解金。这是一个事实。”
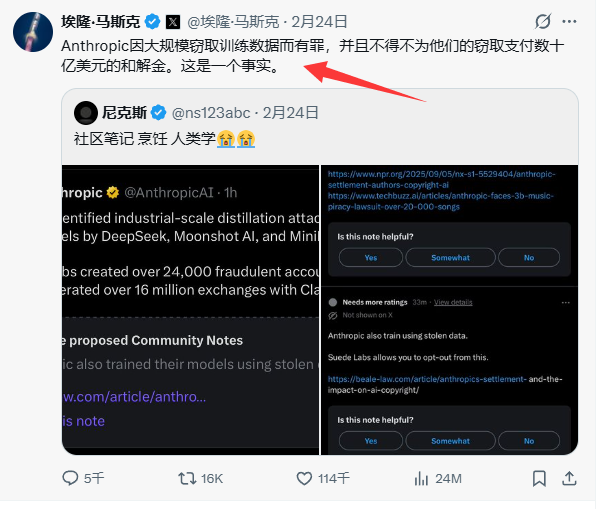
这番评论直指Anthropic自身的历史。在2025年9月,Anthropic被曝光曾从盗版网站LibGen非法下载了超过70万本受版权保护的书籍,用于训练Claude模型。事后,该公司与全球作家团体达成和解,支付了15亿美元的赔偿金,创造了AI行业版权和解金额的纪录。此事在当时影响甚广,甚至促使美国西北大学图书馆专门发出通知,提醒本校作者申领赔偿金。
更具讽刺意味的是,就在Anthropic发布指控声明的同一天,有研究机构发布报告称,包括Anthropic在内的多家头部AI公司的模型,能够通过特定提示词复述出《哈利·波特》、《权力的游戏》等畅销书的大段原文。斯坦福和耶鲁的研究人员利用特定方法引导Claude 3.7 Sonnet输出内容,几乎提取了整部小说的完整原文。
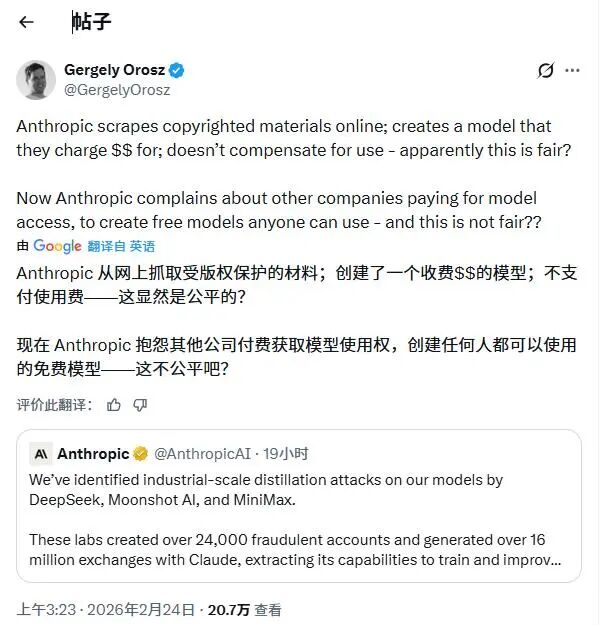
因此,整个事件呈现出一种“回旋镖”效应:Anthropic自身曾因使用未授权的版权材料训练模型而陷入风波,如今却转身指控其他公司通过其API输出“窃取”模型能力。
有网友犀利地评论道:“他们怎么敢偷Anthropic从人类创作者那里偷来的东西?”
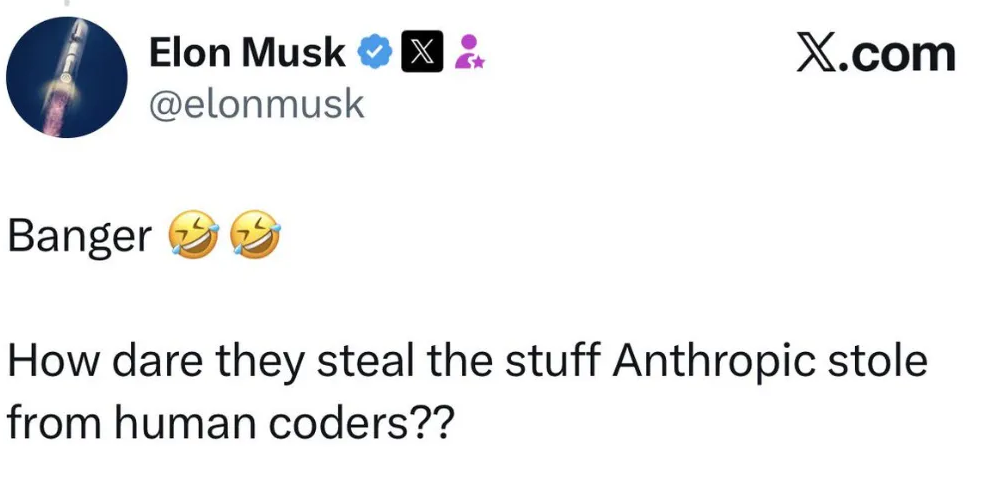
这句话在社交媒体上获得了极高的传播度。
实际上,“知识蒸馏”技术本身在人工智能领域并不新鲜。其原理是利用一个大型、高性能的“教师模型”的输出,来训练一个更小、更高效的“学生模型”,让小模型尽可能复现大模型的能力。许多AI实验室都在内部使用这项技术。Anthropic在声明中也承认,“前沿AI实验室会定期蒸馏自己的模型,为客户创建更小、更便宜的版本”。争议的核心在于,使用竞争对手的API输出来训练自己的模型,明确违反了Anthropic的服务条款。
但这里存在一个法律上的灰色地带:AI模型的输出在美国目前不受版权保护。美国版权局在2025年1月已明确,版权保护要求有人类作者身份,仅通过提示词生成的AI输出不符合这一要求。因此,从严格的法律角度看,此类行为更像是一种合同违约,而非知识产权盗窃。
Anthropic显然希望将事态扩大化。其在声明中使用了大量军事化术语,如“九头蛇集群”、“攻击”、“国家安全”等,并特别强调 “这进一步支撑了美国对AI芯片实施出口管制的理由” 。有分析指出,这篇博客的真正目标读者或许并非技术社区,而是华盛顿的政策制定者。
一个耐人寻味的细节是,在Anthropic公布的数据中,三家被指控公司的“蒸馏规模”差异巨大。其中MiniMax进行了约1300万次交互,月之暗面为340万次,而DeepSeek仅有15万次,占比不到总交互次数的1%。然而,在绝大多数媒体报道的标题中,DeepSeek均被列在首位,这或许是因为其在华盛顿的知名度更高,更能触动“中美AI竞争”这一政治叙事。
截至发稿,被点名的三家公司均未对此事做出公开回应。
这场关于AI技术伦理与规则的争论最终将如何收场尚未可知,但它清晰地揭示了一点:在快速发展的AI行业中,关于何为“窃取”或“合理使用”的界定,很大程度上取决于话语权的归属。Anthropic可以从海量、有时存在版权争议的数据中学习成长,转而指责使用类似技术路径的后来者。这既是技术竞争的现实,也引发了整个开发者广场对于未来AI治理规则的深度思考。 |  发表于 2026-2-27 06:03:29
|
查看: 226|
回复: 0
发表于 2026-2-27 06:03:29
|
查看: 226|
回复: 0
