基于 Transformer 架构构建的自回归模型是一种强大的范式,可通过逐段合成内容生成超长篇视频。然而,这种串行生成过程的速度问题一直饱受诟病。尽管缓存策略已被证实能有效加速传统视频扩散模型,但现有方法均假设所有帧的去噪过程是均匀的 —— 这一假设在自回归模型中不再成立,因为在相同时间步下,不同视频块会呈现出差异化的相似性模式。
针对上述问题,厦门大学与字节跳动的研究团队联合提出 FlowCache,这是首个专为自回归视频生成设计的缓存方法。
该方法在 MAGI-1 模型上实现了 2.38 倍的速度提升,在 SkyReels-V2 模型上达到了惊人的 6.7 倍加速效果,且生成质量下降幅度可忽略不计。FlowCache 成功释放了自回归模型在实时超长篇视频生成场景下的潜力,为大规模高效视频合成树立了新的基准。

自回归视频模型瓶颈:相似性异质化
在自回归视频模型的背景下,计算第 i 个视频片段在相邻时间步长上的相对 L1 距离:
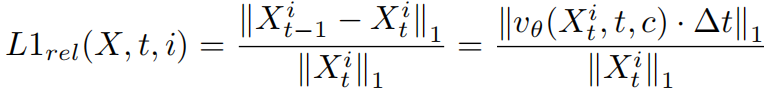
相对 L1 距离具有固有数学特性,可刻画自回归视频模型去噪过程的时序动态。在流匹配与扩散模型框架下,去噪轨迹上的速度场呈现出规律的变化模式。通过分析速度预测与状态演化的数学关系,能够得到相对 L1 距离在不同时间步的基本性质。
以下定理在标准扩散模型假设下,建立了从最优速度场中涌现出的关键单调性性质:

定理 1 表明,随视频片段趋近真实视频,相邻时间步的相对 L1 距离单调递增,即片段相似性递减。
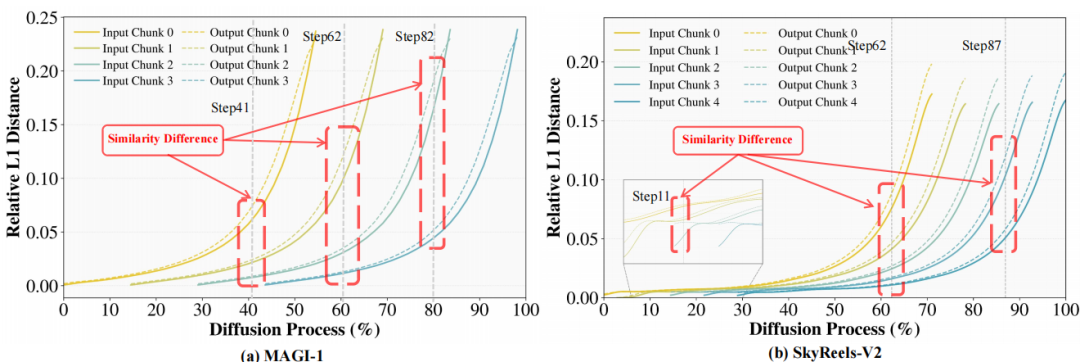
图 1:自回归视频扩散模型在去噪轨迹上相邻时间步的相对L1距离比较。
如图 1 所示,通过绘制不同自回归视频模型各片段相邻步长的相对 L1 距离验证该性质(横轴:去噪进程,纵轴:相对 L1 距离,颜色区分片段),并揭示三个规律:
- 去噪后期相对
L1 距离显著增大(定理1的直接体现);
- 同一时刻不同片段的相似性差异显著,反映其去噪进度的异质性;
- 模型输入与采样器输出在全过程中始终保持高度相似。
由定理1可得推论1:
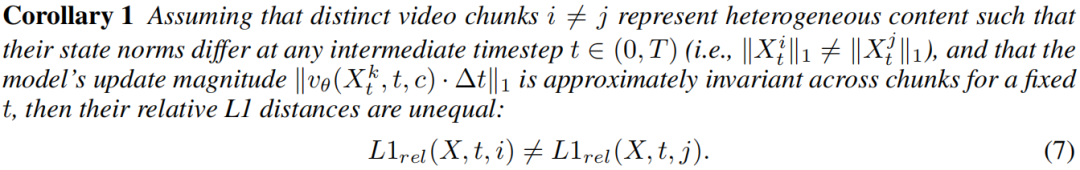
由于不同视频块在去噪过程中的状态范数存在差异且模型更新幅度近似不变,导致它们的相对 L1 距离不相等。传统缓存方法对所有片段采用统一策略,忽视了同一时刻各片段去噪进度的异质性,导致灵活性受限、加速不足且质量下降。
上述结论表明,各片段需要独立的缓存策略,为此研究者们提出了 FlowCache 方法。
FlowCache 原理:自适应缓存与KV压缩
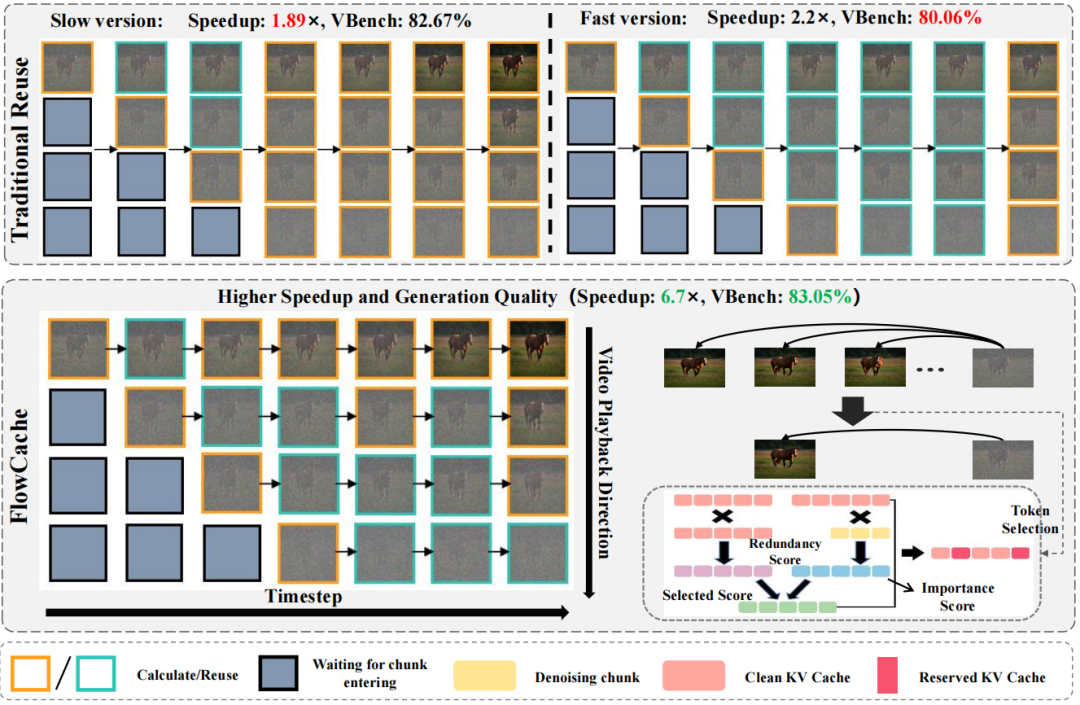
图 2:自回归视频生成中缓存策略的比较。上图展示了传统复用策略,本文提出的FlowCache(左下)采用逐块自适应的缓存策略。右下角详细展示了FlowCache的键值缓存管理机制。
如图 2 所示,FlowCache 则为每个片段独立评估相似性:对于第 i 个片段,定义一个函数 f(X, t, i):
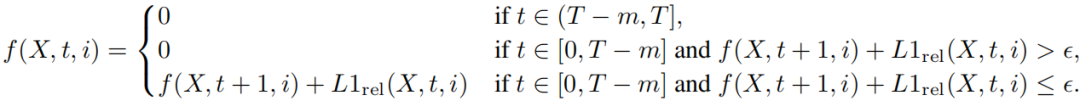
其中 ε 为阈值, m 为禁止缓存的初始步数(MAGI-1: m=41,SkyReels-V2: m=11)。当 f(X, t, i) = 0 时执行前向计算,否则复用缓存。实验表明,排除早期时间步对保证生成质量至关重要。
由定理1可知,接近去噪完成的片段相似性低,应减少缓存复用;而接近噪声的片段相似性高,可连续复用。FlowCache 通过为每个片段制定自适应策略,最大化缓存效率,从而显著提升推理速度。
键值(KV)缓存压缩
研究团队提出了联合优化重要性与冗余性的压缩策略,通过筛选既与当前去噪相关、又互不相似的历史条目,在有限缓存预算下最大化信息多样性,从而在保证长视频生成质量的同时降低显存与计算开销。
具体而言,分配一个固定大小的键值缓存缓冲区 B,并将其划分为两个区域:
- 压缩的干净块区域,大小为
B_clean,用于存储所有干净块的压缩键值状态;
- 当前去噪区域,大小为
B_denoise,用于存放当前正在去噪的视频块组的键值状态。
当 B_denoise 写满时,将干净块和新完成去噪的块合并,通过重要性-冗余性筛选进行压缩,然后释放当前区域,为后续待处理块腾出空间。
所提筛选准则平衡了重要性与冗余性。计算注意力分数,在键维度上应用 softmax,并在查询序列维度上取平均,得到每个注意力头上历史令牌的重要性分布:
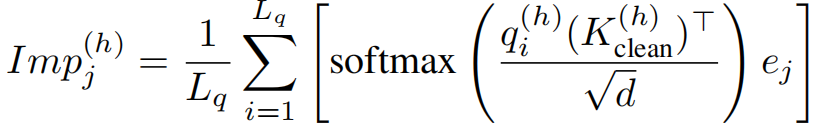
对于冗余性,计算每个注意力头上干净块的键(K_clean^(h))的余弦相似度矩阵 S^(h),然后:
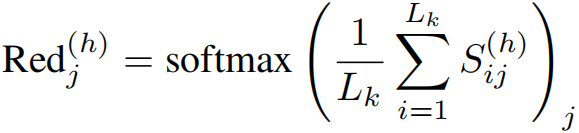
此操作得到每个注意力头的冗余性分布,其中值越高表示该令牌在相同注意力头中平均而言与其他令牌越相似。
最后,将池化后的重要性与冗余性组合为统一的每注意力头选择分数:
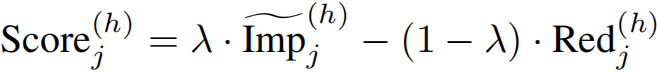
通过联合优化相关性与多样性,该方法在显著降低 DiT 注意力内存占用与计算开销的同时,保持了长程时间一致性,从而支持高效、高保真的长视频生成。
评估:速度与质量的显著提升
为评估所提方法的有效性,研究者选取了两种基于自回归范式的代表性扩散模型:MAGI-1-4.5B-distill 和 SkyReels-V2-1.3B-540P。
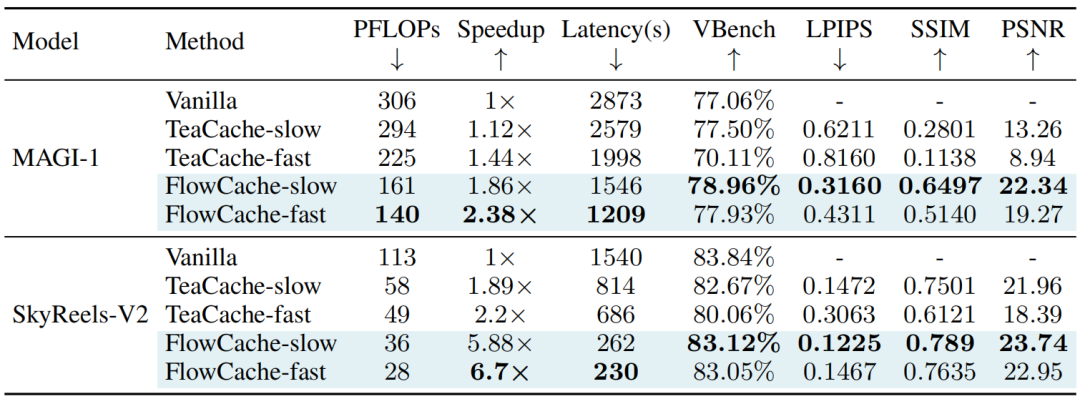
表 1:自回归视频生成模型中推理效率与视觉质量的量化评估
表1的量化结果表明,FlowCache 相较于基线方法 TeaCache 具有显著优越性。在慢速与快速两种配置下的评估显示,FlowCache 在不同模型及加速比设置中均能实现更高的视频质量与更低的延迟。
在 MAGI-1 上,当加速比从 1.12 倍提升至 1.44 倍时,TeaCache-fast 出现明显的质量下降(VBench分数从 77.50 降至 70.11);而 FlowCache-fast 在实现 2.38 倍加速的同时,仍保持了较高的视觉质量(VBench 分数 77.93),甚至略超基线模型。
FlowCache-slow 在所有变体中取得了最佳质量,加速比达到 1.86 倍。该优势在 SkyReels-V2 上更为突出:FlowCache-slow 在实现 5.88 倍加速的同时,质量损失极小(VBench 分数 83.12),显著优于 TeaCache-slow(加速比 1.89 倍,VBench 分数 82.67);FlowCache-fast 在 6.7 倍加速比下仍保持优异质量(VBench 分数 83.05),而 TeaCache-fast 在 2.2 倍加速时质量已下降至 80.06。
这项来自厦门大学与字节跳动的研究,为视频生成这一热门领域的效率瓶颈提供了创新性的解决方案。其核心思想——识别并利用自回归生成过程中固有的相似性异质性——不仅带来了最高6.7倍的性能飞跃,也为未来人工智能生成模型的高效推理设计提供了新的思路。对这项技术细节感兴趣的开发者,可以在云栈社区的相关板块找到更多深入的讨论和资料。
 发表于 2026-2-28 03:14:14
|
查看: 246|
回复: 0
发表于 2026-2-28 03:14:14
|
查看: 246|
回复: 0
