摘要:来自华盛顿大学、艾伦人工智能研究所等机构的团队发布了OpenScholar,这是首个专为科学研究设计的完全开源检索增强语言模型系统。其在多学科文献综合任务中性能超越GPT-4o,引文准确率达到专家水平,为科研工作者带来了高效、可信的文献综述工具。
引言:科学文献综合的新时代
科学进步高度依赖于研究人员综合海量文献的能力。然而,随着学术出版物呈指数级增长,研究人员想要跟踪最新进展变得越来越困难。高效的知识综合不仅需要精确检索,还需要准确的归因以及对最新文献的访问。虽然大语言模型(LLMs)展现出强大的文本生成能力,但在处理科学文献任务时,依然面临“幻觉”、预训练数据过时以及归因能力有限等核心挑战。
一个令人警醒的发现是,当被要求引用计算机科学或生物医学等领域的最新文献时,主流模型如GPT-4o在高达78%至90%的情况下会虚构引用。这凸显了当前AI系统在严肃的科学文献综合任务中存在着重大缺陷。
为了解决准确、全面且透明的科学文献综合这一难题,研究团队推出了OpenScholar——这是首个专为科学研究任务设计的、完全开源的检索增强语言模型(RAG)系统。
OpenScholar:开源科学文献综合系统
系统架构与核心组件
OpenScholar集成了领域专业化的数据存储、自适应检索模块以及创新的自我反馈引导生成机制,实现了对长文本输出的迭代优化。
OpenScholar DataStore(OSDS) 是一个完全开放、持续更新的语料库,包含了4500万篇科学论文和2.36亿个段落嵌入,为模型的训练和推理提供了可复现且规模庞大的基础。这一数据规模在开源科学文献系统中处于领先地位。
OpenScholar的标准工作流程包含以下步骤:
- 使用专门训练的检索器和重排序器从OSDS中检索出与问题最相关的段落。
- 基于检索到的上下文,生成带有准确引用的回答草稿。
- 通过一个独特的自我反馈循环进行迭代优化,持续提升答案的事实性、内容覆盖度以及引用准确性。
值得注意的是,这套流程同样被用于生成高质量的合成数据。这使得研究团队能够在完全不依赖专有大型语言模型的情况下,成功训练出紧凑的80亿参数模型(OpenScholar-8B)以及高效的检索器。
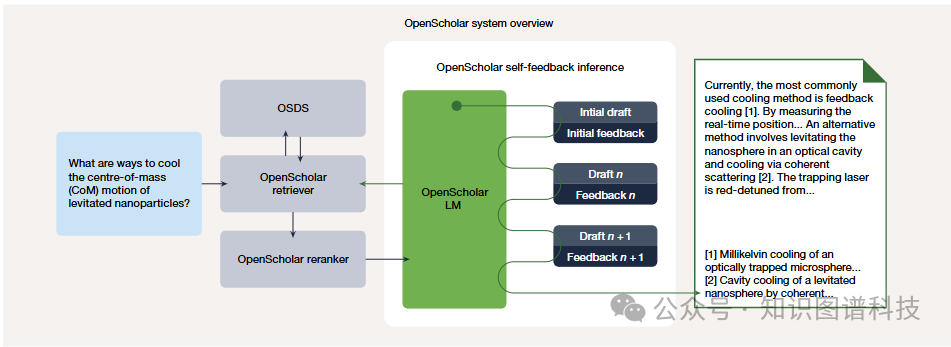
自我反馈机制
OpenScholar的核心创新之一在于其自我反馈推理循环。系统并非一次生成最终答案,而是先产生一个初始草稿,随后由模型自身对该草稿进行评估并生成反馈(例如,指出引用缺失或事实错误),接着基于这份反馈对草稿进行修订。这个过程可以重复多次,每一次迭代都产生新的草稿和反馈,直至达到预设的质量标准。
这种机制赋予了OpenScholar强大的自我修正能力,使其能够:
- 识别并修正引用错误。
- 增强答案对主题的覆盖深度。
- 提高长文本回答的连贯性与组织性。
- 从根本上确保事实的准确性。
ScholarQABench:首个多学科文献综合基准
基准设计
为了全面、公正地评估OpenScholar,研究团队开发了ScholarQABench——这是首个面向开放式科学文献综合任务的多学科基准。
与以往专注于短文本、多项选择题或单一领域推理任务的基准不同,ScholarQABench要求模型生成基于多篇论文最新发现的长文本综述性回答。该基准包含:
- 近3000个高质量研究问题
- 超过200个由专家撰写的长文本参考答案
- 涵盖计算机科学、物理学、生物医学和神经科学四大核心领域
- 所有问题与答案均由经验丰富的博士生和博士后根据真实的文献综述实践撰写。
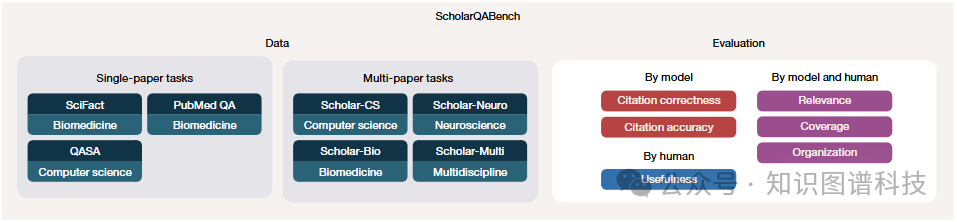
评估协议
为克服评估长文本、综合性回答的困难,ScholarQABench引入了一套严格的混合评估协议,结合了:
- 自动指标:例如引用准确性(Citation F1),客观衡量引文的真伪。
- 基于评分标准的人工评估:由领域专家从覆盖度、连贯性、写作质量和事实正确性等多个维度进行深度评分。
分析表明,这套多维评估管道与专家的整体判断高度一致,能够可靠地捕捉科学答案在多个关键维度上的质量。
性能评估:全面超越现有系统
自动评估结果
研究团队在ScholarQABench上系统评估了包括GPT-4o、Llama 3.1系列以及PaperQA2、Perplexity等专有系统在内的众多模型。
关键发现如下:
-
准确性对比(在最具挑战性的多论文综合任务子集上):
- OpenScholar-GPT-4o:57%
- OpenScholar-8B:51%
- GPT-4o:45%
- PaperQA2:40%
- Perplexity:40%
-
引用准确性对比:
- OpenScholar-8B:43%
- PaperQA2:41%
- OpenScholar-GPT-4o:37%
- Perplexity:20%
- GPT-4o:仅1%
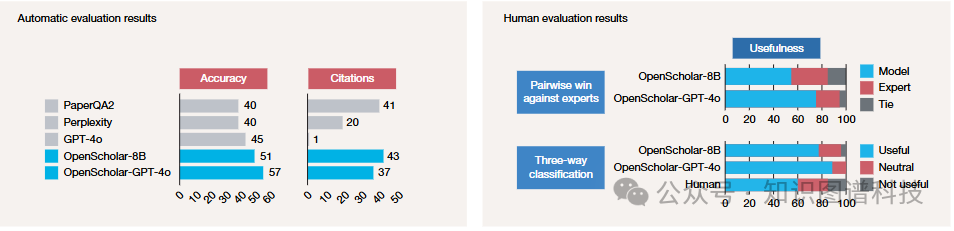
尽管GPT-4o在通用能力上强大,但其在科学文献综合中的引用准确性和内容覆盖度上表现不佳,经常产生“幻觉”引用。相比之下,OpenScholar在各项评估中均表现出色。尤为引人注目的是,完全基于开源组件的OpenScholar-8B不仅超越了GPT-4o,甚至击败了基于专有模型构建的PaperQA2等生产系统。
此外,OpenScholar的框架具有普适性,能够显著增强现有商业模型。例如,当将GPT-4o接入OpenScholar管道(即OpenScholar-GPT-4o)时,其在答案正确性上比原生GPT-4o提升了12%。
人工评估结果
研究还组织了大规模人工评估,由16位拥有博士学位的专家对108个复杂问题进行了盲审。
人工评估的关键结论:
-
与专家答案的配对盲测:当被问及更倾向于哪个答案时,
- 专家选择OpenScholar-GPT-4o(而非人类专家答案)的比例高达 70%。
- 专家选择OpenScholar-8B的比例为 51%。
- 而专家选择原生GPT-4o答案的比例仅为32%。
-
有用性评估:在“有用”、“中立”、“无用”的三分类评估中,OpenScholar系列模型生成的答案被判定为“有用”的比例与人类专家答案相当。
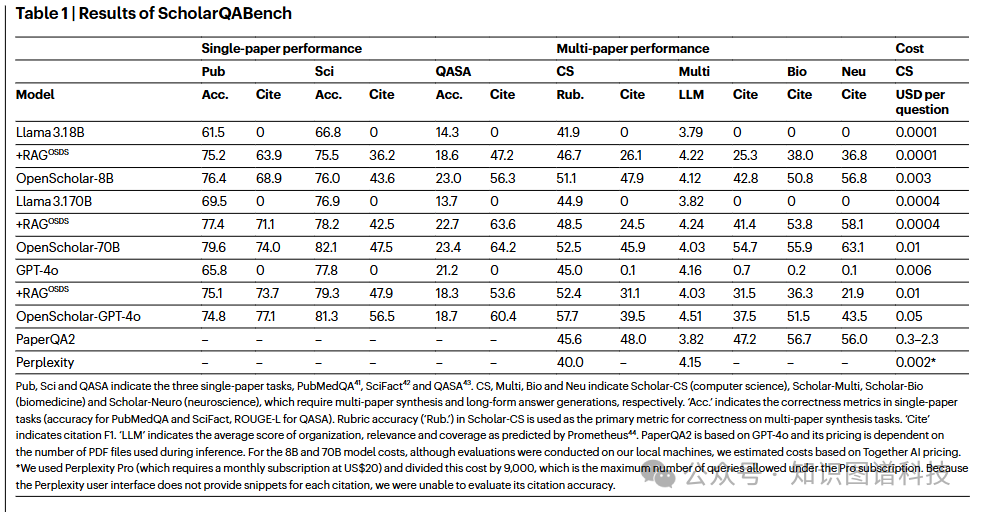
这项评估表明,在答案正确性和引用准确性方面,OpenScholar系统已经达到甚至在某些情况下超越了人类专家水平。这标志着AI辅助的科学文献综合正式迈入了实用化阶段。
成本效益分析
OpenScholar通过使用更小、更高效的专用检索器,大幅降低了每次查询的计算成本。这对于需要处理大规模文献的研究机构和企业而言,具有重要的现实经济意义。
核心技术优势与影响
广泛的消融实验证明了OpenScholar各个核心组件的重要性:
- 重排序模块:显著提升检索段落的相关性。
- 自我反馈循环:迭代式地优化答案质量。
- 专业化数据存储(OSDS):提供高质量、领域相关的知识基础。
这些组件的协同工作使OpenScholar能够:
- 极大减少引用“幻觉”。
- 生成覆盖更全面、更有深度的答案。
- 确保每一项引用都准确、可追溯。
- 产出结构更清晰、组织更良好的长文本综述。
开源与未来展望
OpenScholar的公开演示已吸引了来自全球不同科学学科的超过30,000名用户,证明了其巨大的实际应用需求。
为了推动整个领域的发展,研究团队已全面开源了项目所有资源,包括:
- OpenScholar系统代码。
- 模型检查点与训练数据。
- 包含4.5亿段落嵌入的OSDS数据存储。
- ScholarQABench基准数据集。
- 公开演示平台。
这一彻底的开源策略将极大地促进科学文献综合领域的技术迭代与创新。
当然,团队也指出了当前系统的局限性:OpenScholar并非旨在完全替代科研人员,人类专家的批判性思维和最终判断在科研过程中仍然不可或缺。未来的工作将集中于整合用户反馈、进一步提升引用精度、优化系统响应速度,并探索将其扩展到更多学科及多语言场景。
结论
OpenScholar与ScholarQABench的发布,是大语言模型在辅助科学家应对复杂文献综述任务上的一个里程碑。它首次提供了一个完全开源、高性能、高可信度的解决方案,不仅性能超越当前顶尖商业模型,其引文准确性更是达到了专家级水准。这为全球科研社区提供了一个强大、透明且可访问的工具,有望显著提升科研效率,加速科学发现的进程。
这项研究也展示了专业领域微调、高质量数据构建以及检索增强生成(RAG)技术的巨大潜力。对于任何致力于构建专业、可信AI应用的开发者而言,OpenScholar的设计思路与实现细节都具有极高的参考价值。你可以通过其开源仓库获取全部代码与模型,深入探索这一前沿技术。
 发表于 2026-2-28 04:23:05
|
查看: 155|
回复: 0
发表于 2026-2-28 04:23:05
|
查看: 155|
回复: 0
