几个小时前,NVIDIA CUDA Toolkit 13.1 正式发布。英伟达官方将其定义为 CUDA 平台诞生近20年来的一次重大更新。

此次更新内容全面,主要亮点包括:
- 全新发布的 NVIDIA CUDA Tile,这是一种基于Tile的编程模型,可用于抽象化张量核心等专用硬件。
- 运行时API开始支持Green Contexts(绿色上下文),提供更细粒度的GPU资源划分。
- NVIDIA cuBLAS 库中引入了双精度和单精度仿真功能。
- 一本为新手和高级程序员完全重写的 CUDA 编程指南。
下面我们逐一进行解析。
CUDA Tile:抽象硬件细节的新编程范式
CUDA Tile 是 NVIDIA CUDA Toolkit 13.1 最核心的更新。它是一种基于Tile的编程模型,允许开发者在更高层次上编写算法,同时屏蔽了张量核心等专用硬件的底层细节。

核心概念解析
根据英伟达的官方解释,CUDA Tile 让开发者能够在高于传统SIMT(单指令多线程)的层级上编写GPU核函数。
在当前的SIMT编程模式下,开发者需要划分数据并详细定义每个线程的执行路径。而借助CUDA Tile,开发者可以直接操作被称为“Tile”的数据块,只需指定要在这些Tile上执行的数学运算。编译器和运行时环境会自动负责将工作负载最优地分发到各个线程。
这种模型不仅简化了调用Tensor Core等专用硬件的复杂度,而且基于Tile编写的代码具备更好的向前兼容性,能够适应未来的GPU架构。
CUDA 13.1 包含了两个用于Tile编程的关键组件:
- CUDA Tile IR:一种面向NVIDIA GPU的全新虚拟指令集架构。
- cuTile Python:一种新的领域特定语言,用于在Python中编写基于数组和Tile的核函数。
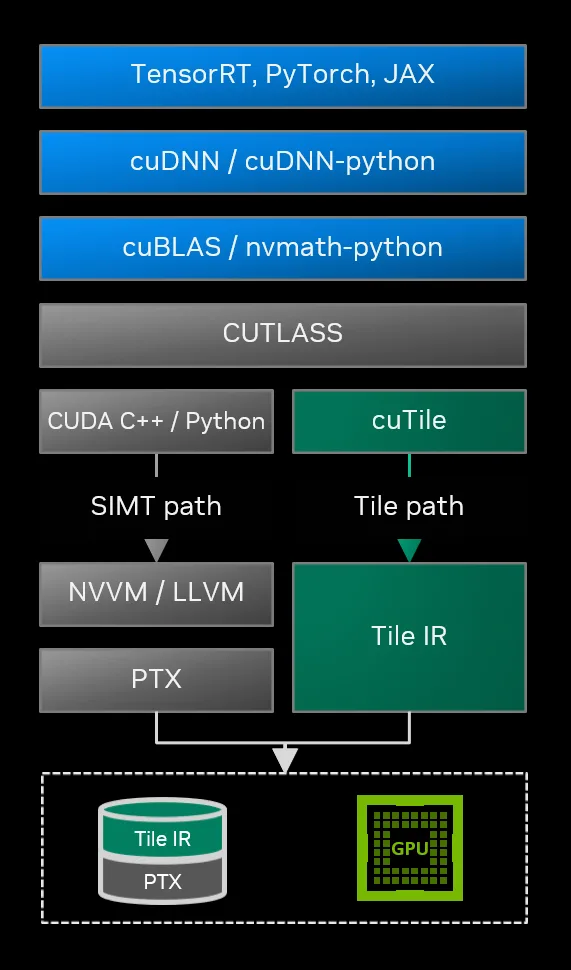
编译后的Tile路径可以无缝集成到完整的软件栈中,与传统的SIMT路径协同工作。
重要说明与限制
这是该软件的首个版本,目前存在一些限制:
- 仅支持NVIDIA Blackwell系列(计算能力10.x和12.x)产品,未来版本将扩展支持范围。
- 当前开发重点聚焦于AI算法的Tile编程,后续版本将增加更多特性和性能优化。
- 英伟达计划在未来的CUDA版本中引入C++实现。
为何需要Tile编程?
传统的CUDA SIMT模型赋予了开发者极大的灵活性和细粒度控制能力,但编写高性能代码往往需要深入理解硬件,且适配多种架构的代价较高。
随着AI工作负载成为主流,张量成为了基础数据类型。NVIDIA为此开发了Tensor Core等专用硬件。硬件越复杂,就越需要高级软件来驾驭其能力。CUDA Tile 对Tensor Core及其编程模型进行了抽象,使得编写的代码能兼容当前及未来的Tensor Core架构。
基于Tile的编程方式允许开发者通过指定数据块(Tile)和其上执行的计算来编写算法,而无需关注逐元素的执行细节,这类似于在Python中使用NumPy进行批量矩阵操作的高效体验。
下图展示了Tile模型与SIMT模型在概念上的差异:

CUDA软件的其他重要更新
运行时对Green Context的支持
Green Context是一种轻量级的CUDA上下文,可作为传统上下文的替代方案,提供更精细的GPU空间与资源划分能力。自CUDA 12.4起已在驱动API中提供,现在正式在运行时API中开放。
典型应用场景是,为对延迟极为敏感的高优先级代码创建独立的Green Context并分配SM资源,确保其总能获得计算资源,而其他任务则在另一个Context中运行。CUDA 13.1还引入了更易用的split() API来简化分区创建。
CUDA多进程服务更新
- 内存局部性优化分区:适用于Blackwell及更新GPU,允许从单块物理GPU派生出多个独立的CUDA设备,每个设备拥有更少的计算资源和内存,以优化内存局部性。目前支持B200/B300系列。
- 静态SM分区:针对Ampere及更新GPU,为MPS客户端提供创建独占SM分区的方法,旨在提供确定性资源分配和更好的隔离性。
cuBLAS中的双精度和单精度模拟
在CUDA Toolkit 13.0的cuBLAS更新中,引入了通过Tensor Core进行浮点模拟的新API,以提升双精度矩阵乘法的性能,特别是在NVIDIA GB200 NVL72等GPU架构上。
开发者工具增强
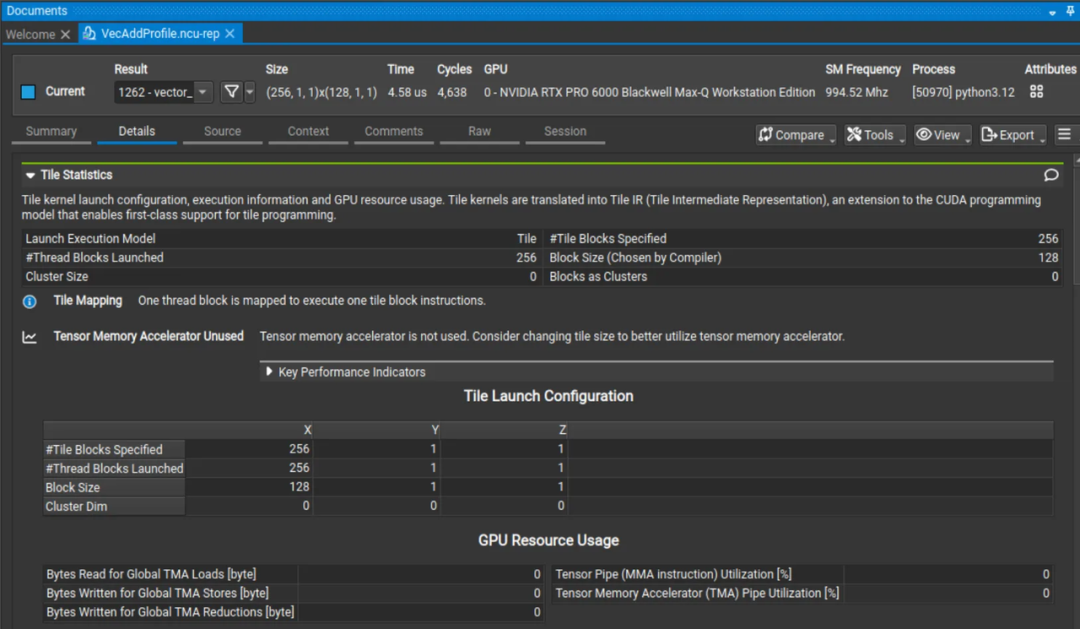
CUDA Tile核函数性能分析
Nsight Compute工具现已支持分析CUDA Tile核函数,在摘要页区分Tile与SIMT核函数,在详情页提供Tile统计信息,并支持在源码页映射指标到高级cuTile代码。
编译时修补
NVIDIA Compute Sanitizer 2025.4 通过-fdevice-sanitize=memcheck编译器标志,增加了对NVCC编译时修补的支持。这增强了内存错误检测能力并提升了性能。使用方法如下:
nvcc -fdevice-sanitize=memcheck -o myapp myapp.cu
compute-sanitizer --tool memcheck myapp
NVIDIA Nsight Systems
2025.6.1版本新增多项追踪功能,包括系统级CUDA追踪、CUDA主机函数追踪,并默认启用硬件追踪模式。
数学库性能提升
cuBLAS
新增实验性API,支持Blackwell GPU的分组GEMM功能(兼容FP8/BF16/FP16),在MoE等用例中相比多流实现可带来最高4倍的设备端加速。
cuSOLVER
继续优化批处理特征分解API(如SYEVD)。测试显示,在批处理大小为5000的SYEV计算中,Blackwell RTX Pro 6000相比L40S实现了约2倍的加速,符合内存带宽提升预期。GEEV函数在计算大规模一般矩阵特征值时也获得了最高约1.7倍的性能提升。
NVIDIA CUDA核心计算库更新
NVIDIA CCCL 3.1 为CUB库带来了重要更新:
- 确定性浮点运算简化:提供了额外的确定性选项,允许开发者在结果的位级一致性和性能之间进行权衡,包括“不保证”和“GPU间保证一致”等模式。
- 更便捷的单相API:为部分CUB算法新增了重载,允许用户跳过繁琐的临时存储查询/分配/释放两阶段模式,简化了代码编写。
资源与参考
 发表于 2025-12-7 01:10:38
|
查看: 225|
回复: 0
发表于 2025-12-7 01:10:38
|
查看: 225|
回复: 0
