你是否感觉构建一个真正“好用”的AI Agent工具(Tool)总是困难重重?设计的接口大模型看不懂,复杂的调用链路难以追踪,海量的存量API不知如何转化。本文将带你系统性地拆解Agent Tools开发的核心原则,并介绍如何借助火山引擎AgentKit,一站式解决工具碎片化、连接复杂化、治理黑盒化三大痛点。
在探讨具体方法之前,我们必须明确一点:高质量的Tools是构建高效、可靠Agent的基石。Tools是连接大语言模型(LLM)与现实世界的“感官”与“肢体”。单纯的LLM虽有强大的逻辑推理能力,但就像一个处于真空状态的“大脑”;只有配备了精良、易用的工具,它才能进化为能够主动感知和干预环境的智能体。一个合格的Agent Tool,其核心标准是构建一个 “可理解、安全且具备容错能力” 的交互接口。
基于实践,我们可以从Agent工具调用的完整生命周期出发,归纳出设计Tools时需要重点考量的六大关键要素:

- 类型安全与自动化
充分利用Python的类型系统和Pydantic库,可以自动生成接口Schema并进行数据验证,从根本上防止模型“瞎猜”参数。
- 使用 Pydantic BaseModel:利用Pydantic进行复杂的参数验证,让其自动处理Schema生成和数据校验。
- 限制枚举值:通过
Literal 等方式明确限制参数的可选值范围,大幅降低模型传参出错的概率。
- 设置清晰的默认值:合理的默认值能显著减轻模型的决策负担,并防止返回过于庞大的响应内容。
def search_products(
query: str = Field(
description="用户的自然语言搜索意图。例如: ‘适合跑步的防水鞋‘"
),
category: Literal[“electronics“, “clothing“, “food“] = Field(
description=“产品类别。如果用户提到‘手机’/‘电脑’用electronics“
),
price_max: Optional[int] = Field(
None,
description=“最高价格(人民币)。只有当用户明确提到预算时才填写“
),
sort_by: Literal[“relevance“, “price_asc“, “rating“] = Field(
default=“relevance“,
description=“排序方式。默认按相关性,除非用户说‘便宜的’/‘评分高的’“
)
):
- LLM 友好的接口设计
LLM无法像人类开发者那样阅读技术文档,它完全依赖自然语言描述来理解如何使用一个工具。因此,接口设计必须“说人话”。
- 自然语言优先:在函数签名、参数描述和错误信息中,始终使用清晰、自然的语言,避免晦涩的技术术语。
- 精心打磨 Docstring:建议投入大量时间撰写高质量的文档字符串。善用
Examples 和 Sample Case 来引导模型准确传参。
- 遵守“单一职责”原则:不要设计一个功能庞杂的“瑞士军刀”式接口。应该将其拆解为参数清晰、职责明确的小型工具集合,这能让Agent的决策链路更加稳定和可控。
def get_user_preferences(user_id: str) -> dict:
“““
获取用户偏好设置
常见后续操作:
- 如果需要推荐商品 → 使用 recommend_products(preferences)
- 如果需要发送通知 → 检查 preferences[‘notification_enabled’]
“““
return user_service.get_preferences(user_id)
- 使用 OpenAPI 规范快速集成外部 API
面对企业大量的现有HTTP API,手动转换成本极高。推荐使用像 OpenAPIToolset 这样的工具集,它可以通过 OperationParser 自动从OpenAPI规范文件中生成函数声明、参数Schema和请求构建逻辑,实现标准化的快速工具创建。
openapi_toolset = OpenAPIToolset(
spec_str=openapi_spec_yaml,
spec_str_type=“yaml“,
auth_scheme=oauth2_scheme,
auth_credential=oauth2_credential,
)
- 构建自我修复能力,而非直接终止
工具在遇到错误时不应简单抛出异常导致整个Agent流程中断,而应具备引导Agent调整策略的能力。
- 结构化错误返回:返回值应包含清晰的
error 信息和具体的 recovery_suggestion(修复建议)。
- 配合反思重试插件:可以结合
ReflectAndRetryToolPlugin 等插件来拦截错误,提供结构化的反思指导,让Agent能够从失败中学习并自动重试。
def delete_file(file_id: str) -> Union[ToolSuccess, ToolError]:
“““删除文件“““
try:
result = file_service.delete(file_id)
return ToolSuccess(data=result)
except FileNotFoundError:
return ToolError(
error=“文件不存在“,
recovery_suggestion=“使用 list_files() 查看可用文件列表“
)
except PermissionError:
return ToolError(
error=“权限不足“,
recovery_suggestion=“请用户确认是否有删除权限,或尝试 get_file_permissions(file_id)“
)
- 加入 Human-in-the-loop(人机回环)安全机制
对于涉及数据修改、金钱交易或敏感信息的高风险操作,必须引入人工确认环节,将最终决策权和责任交还给用户。
- 关键行为确认:通过
require_confirmation 参数定义工具是否需要开启确认模式。利用 tool_context.tool_confirmation 在敏感操作执行前,验证用户是否已明确授权。
- 主动请求帮助:当Agent无法决策或缺少关键信息时,可以通过
ask_human 工具主动向用户发起询问。
def ask_human(question: str) -> str:
“““
当遇到无法自动决策的情况时,询问用户
使用时机:
- 需要用户授权敏感操作
- 多个选择都合理,需要用户偏好
- 缺少关键信息无法继续
“““
return input(f”🤖 需要你的帮助: {question}\n你的回答: “)
- 性能优化与上下文管理
为了保证Agent的响应速度并防止LLM上下文窗口溢出,需要对工具返回的结果进行精细控制。
- 异步并行调用:当提供多个工具供模型调用时,可以实现异步方案,将可能的串行调用转为并行执行以加速整体流程。
- 限制返回数量与摘要化:通过
max_query_result_rows 等参数限制返回的数据条数,或仅返回摘要而非全文,避免耗尽宝贵的上下文长度。
def search_knowledge_base(
query: str,
max_results: int = Field(
default=3, # 👈 默认值很关键
le=5, # 限制最多5条
description=“返回结果数量。默认3条已足够,除非用户要求更多“
)
) -> list[dict]:
“““搜索知识库,返回相关文档片段“““
results = kb.search(query, limit=max_results)
# 👇 关键优化:返回摘要而非全文
return [
{
“id“: r.id,
“title“: r.title,
“summary“: r.content[:200] + “…“, # 只返回前200字
“relevance_score“: r.score,
“full_text_available“: True # 提示可以获取全文
}
for r in results
]
def get_document_full_text(doc_id: str) -> str:
“““获取文档完整内容 - 仅在需要详细信息时调用“““
return kb.get_by_id(doc_id).content
掌握了上述开发原则,我们便有了打造“好工具”的能力。然而,当企业真正尝试规模化落地AI Agent时,会面临更加现实的挑战:面对海量的存量API和数以万计的旧有应用,Tools的集成与治理会陷入工具碎片化、连接复杂化、运维黑盒化的多重困境。火山引擎AgentKit通过其全新的Gateway(网关)架构,提供了从工具鉴权、转化、调用到治理的全套企业级解决方案。
存量应用智能化:3分钟打造 LLM 友好的工具
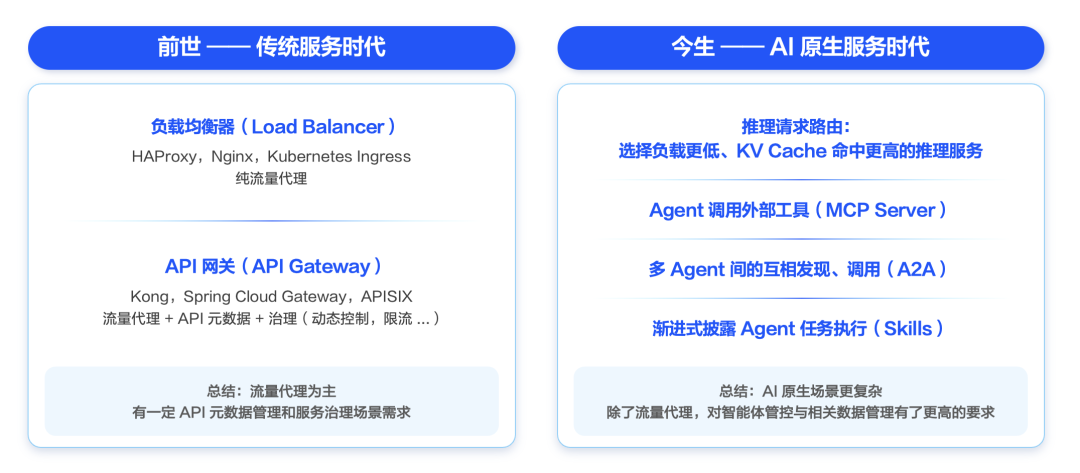
在微服务时代,网关的核心是流量代理和负载均衡;而在AI原生时代,网关需要进化为Agent与外部世界沟通的“智能中枢”。它不仅需要支撑高并发流量(百万级QPS),更要解决一个核心难题:如何让Agent“看懂”并调用企业现有的老旧接口?
针对海量的存量HTTP API,AgentKit Gateway提供了智能化的“AI转换器”,能大幅降低企业应用AI化的门槛。其核心是将传统的API协议(如OpenAPI)自动转化为Agent交互的标准协议——MCP(Model Context Protocol)。
- AI逆向工程生成:只需上传Swagger/OpenAPI文档甚至是一段代码,内置的专用大模型即可自动生成符合MCP标准的Tool Definition,并智能补全缺失的参数描述和用途说明。
- 自动化测试脚手架:在生成工具的同时,自动创建测试用例,通过模拟Agent调用来验证工具的可用性和返回格式的规范性。
- 一键热加载:转换后的工具(Skills)可直接推送到Gateway并实时生效,无需修改任何后端业务代码。
据统计,这种智能转化方式相比人工重构,成本可降低80%。自动生成的提示词被大模型正确理解的概率超过95%,历史API的自动化转化率可达90%。
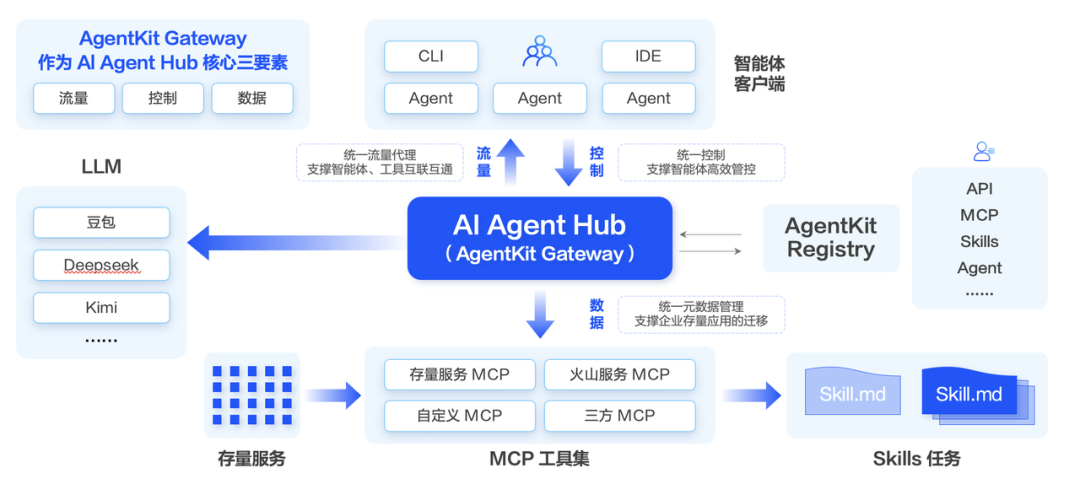
AgentKit Gateway作为整个生态的核心枢纽,集成了流量、控制与数据三大核心能力:
- 流量中枢:统一接管和处理所有流量,无论是Agent间交互、对MCP工具的调用,还是访问底层模型服务。
- 控制中枢:通过控制台集中配置MCP路由、模型路由及负载均衡策略,并集成限流、安全认证等传统服务治理能力。
- 数据中枢:提供对Agent相关元数据(MCP、API、Skills)的全生命周期管理。
针对原生MCP调用中存在的上下文冗余、Token消耗高及模型幻觉问题,AgentKit Gateway引入了独有的优化机制:
- 智能召回:通过独特的搜索方案,综合提升工具调用的准确率,大幅减少无效Token消耗。
- 标签筛选:支持基于场景和分类标签的工具筛选。用户可以自定义MCP工具组合,通过标签逐级索引,显著提升调用效率与准确性。
关键性能指标:
- Token 节省率:在涉及50+工具调用的复杂场景下,MCP调用的Token消耗降低70%。
- 调用准确率:基于Schema优化技术,复杂工具调用的参数填充准确率提升至98.5%。
- 响应延迟:结合语义缓存技术,常用工具的响应速度提升300%。
开发高质量的 MCP Server:让 Agent 更精准地理解并调用工具
当底层的MCP工具定义清晰后,我们需要从更高维度思考:如何将这些独立工具组合成顺畅的任务流?这涉及到工具规划(设计组合)和工具编排(动态调用)两个核心。
核心思想:把大模型当作一个聪明的“实习生”。无需告知所有技术细节(最小化接口),但需将相关任务打包好(避免零散),并明确告知任务目标。一次只提供当前相关的资料(渐进式披露),对于复杂流程,则提供清晰的操作指南(如Agent Skill)。
-
工具定义:“模型友好”
- 名称采用“动词-名词”结构(如
create_order),避免技术实现名(如 call_http_endpoint)。
- 描述需简洁完整,说明用途、输入输出、典型场景和异常处理。
- 输入/输出统一使用JSON Schema(或由Pydantic/Zod生成),善用类型和约束,避免巨大的嵌套结构。
-
工具规划:控制“颗粒度”和“数量”
- 遵循“最小必要接口”原则,只暴露必需参数。
- 避免拆得过碎,从“用户要完成的任务”出发,将强相关步骤打包成一个任务型工具。
- 以“任务导向”而非“接口罗列”为中心设计工具集。
-
工具编排:“减负 + 渐进披露”
- 不要一次性挂载所有MCP工具给一个Agent,而是根据场景按需加载小部分工具集。
- 可通过标签或搜索动态选择工具,避免上下文被无关描述淹没。
- 对于复杂流程,使用Agent Skill编写“操作说明书”,引导模型按步骤调用多个工具。
Skills:消除碎片化与技能孤岛,提高企业复用率
AgentKit将“工具”升级为“技能(Skills)”。技术上与Claude Code Skills兼容,但增加了企业级的管理维度,将其视为可复用的核心数字资产,提供全生命周期管理。
| 维度 |
传统 Tools |
企业级 Skills |
| 定位 |
离散的功能插件 |
核心数字资产 |
| 管理 |
手动维护、版本混乱 |
集中管理、版本回滚、灰度发布 |
| 构建 |
纯代码编写 |
原子能力编排 + Vibe Coding |
| 价值 |
单点执行 |
高复用、高效率、安全隔离 |
AgentKit通过平台级能力,将Skills的落地拆解为三个环节:
- 生成:基于预置的skill-creator,将团队SOP、模板沉淀为可复用的Skills包。
- 管理:通过Skills中心统一完成注册、更新与版本发布,基于空间解决跨团队共享和权限问题。
- 发现与执行:Skills Sandbox按需加载Skills,与LLM交互决策,并在沙箱中隔离执行,返回最终结果。
工具鉴权及身份管理:为 Agent 打造的“零信任”安全盾牌
在Agent自主执行任务的场景下,传统静态API Key的风险极高。AgentKit Identity面向Agent运行时重新定义身份与权限,通过引入 Agent Persona(工作负载身份) 与 Delegation Chain(委托链),以零信任(Zero Trust)方式在每次工具调用时执行策略判定与审计。
- Secretless 动态临时凭证:每次调用时,根据上下文即时签发短期凭证,用完即失效,支持快速撤销与最小权限原则。
- 端到端委托链:将终端用户身份、Agent Persona、任务上下文绑定为可验证的身份链路,用于下游精细化授权与审计归因。
- 存量身份一键迁移:支持与企业现有身份体系(OIDC/SAML等)无缝衔接。
- 工具调用级细粒度授权:在RBAC基础上,支持叠加属性条件(如操作危险等级、资源标签等),实现关系型访问控制(ReBAC)。
- 全面审计与可观测:记录每次令牌签发、策略判定和工具调用的全链路信息,便于事后追溯与合规运营。
理论指明方向,实践验证价值。以下场景推演基于AgentKit核心能力构建,展示了其在不同行业的智能化转型路径。
案例1:零售行业——构建“全能数字员工”,重塑服务体验
场景痛点:全国性连锁零售集团客服重复问题占比超60%,客服需跨十余个系统查询信息,单次查询耗时长达2分钟,大促期间响应延迟严重。
AgentKit解决方案:
- 存量系统“零改造”智能融合:利用AgentKit的MCP服务,将分散的CRM、WMS等50多个核心接口,自动转化为具有语义描述能力的智能工具,统一“数据孤岛”。
- 动态工具组合与意图理解:构建“智能客服Agent”,当用户提出“订单A的赠品是什么?”等复合问题时,自动拆解意图,精准调用“订单查询”、“库存查询”、“促销规则计算”等一系列工具。
- 安全与成本双重治理:引入动态临时令牌机制,杜绝API Key长期暴露风险。通过精确定义和组合调用,避免原始数据大量灌入Prompt,使单次交互Token消耗降低70%。
落地价值:客服问题自动解决率大幅提升,人工坐席专注高价值工作;跨系统查询从分钟级降至秒级,用户体验无缝化。其本质是将后端复杂的业务系统网络,通过工具化封装,智能地映射为前端极简的服务界面。
案例2:金融科技行业——锻造智能风控“数字审计官”
场景痛点:跨境支付公司日均处理数百万笔交易,人工审计耗时数天、响应滞后,且难以满足全球动态合规要求。
AgentKit解决方案:
- 动态合规规则“Skill化”敏捷部署:合规专家利用“Skill Studio”,无需编码即可将最新监管要求封装为可执行的独立Skill(如“大额交易聚类分析Skill”),监管响应时间从“周级”缩短至“小时级”。
- 全链路可解释性与审计溯源:每一笔被标记的交易都能生成完整“决策报告”,包含调用的数据源、应用的风控规则和推理逻辑链,极大减轻合规汇报压力。
- “隐私优先”的安全范式:借助Agent Persona与Delegation Chain,对敏感数据的访问权限基于动态上下文(如任务类型、数据敏感级)进行评估,确保研发、生产等多环境下的数据安全底线。
落地价值:实现7x24小时实时事中风控拦截;自动化使合规审计总工时减少85%,团队得以聚焦风险策略优化。其核心价值在于构建一套能随业务快速迭代、同时满足最高安全与审计标准的智能风控基础设施。
四、行业展望
无论是零售业的服务重塑还是金融业的风控升维,其共同起点都是将企业固有的、数字化的业务能力,通过AgentKit转化为智能体可自如运用的“工具”。这标志着一次深刻的 “业务能力AI化”范式转移。
AgentKit通过存量应用无缝转化、Skills产品化、企业级治理三位一体的核心能力,正助力各行业将AI潜力转化为扎实的业务优势、可控的安全屏障和可持续的竞争力。未来,善用“智能工具链”的企业,将在智能化浪潮中掌握定义新时代游戏规则的主导权。
 发表于 2026-2-28 07:27:12
|
查看: 217|
回复: 0
发表于 2026-2-28 07:27:12
|
查看: 217|
回复: 0
