本文旨在提供一个清晰的指引,帮助你通过Python快速获取“深圳共享单车企业每日订单表”数据,即使你没有编程基础。此方法专注于获取指定时间段的数据,并可以直接导出为CSV文件。
相较于涉及数据库的旧版本方法,新版教程更加轻量,不建议用此方法去获取全量数据(2.4亿条),具体原因将在后文说明。如果你需要处理全量数据,可参考完整的开发者版教程。
在上期关于深圳市共享单车数据分析的分享后,很多朋友询问如何获取数据,尤其是没有Python基础的该怎么办。接下来分享的代码,你只需要修改其中三个变量,就能获取指定日期的深圳共享单车数据。
1. 数据集介绍
- 数据集概览:该数据集名为“深圳共享单车企业每日订单表”,来源于深圳市政府数据开放平台。它包含2021年1月至8月的部分共享单车订单信息,字段包括用户ID、开始时间、开始经度、开始纬度、结束时间、结束经度、结束纬度、企业ID,总计约2.4亿条记录。
- 获取子集:可通过“
startDate”和“endDate”参数限定时间范围,查询对应时间范围内的入库数据。参数格式为 yyyymmdd,示例:startDate=20240624&endDate=20240626。
2. 数据获取方式
1)直接下载
对于如此庞大的数据集,直接下载的文件仅包含前10万条数据,无法满足获取某天完整数据的需求。要获取特定日期的全部数据,必须通过API接口。
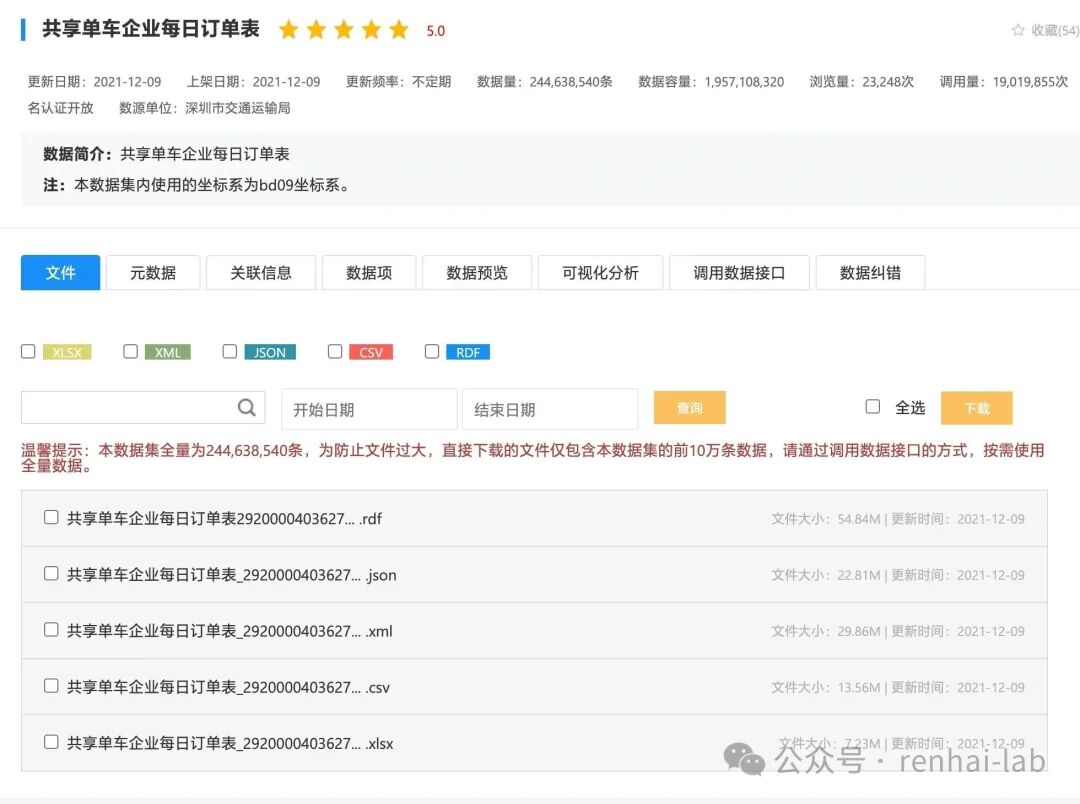
每条数据包含的字段如下:
| 字段名 |
含义 |
| USER_ID |
用户 id |
| COM_ID |
企业 id |
| START_TIME |
开始时间 |
| START_LNG |
开始经度 |
| START_LAT |
开始纬度 |
| END_TIME |
结束时间 |
| END_LNG |
结束经度 |
| END_LAT |
结束纬度 |
2)调用 API 接口
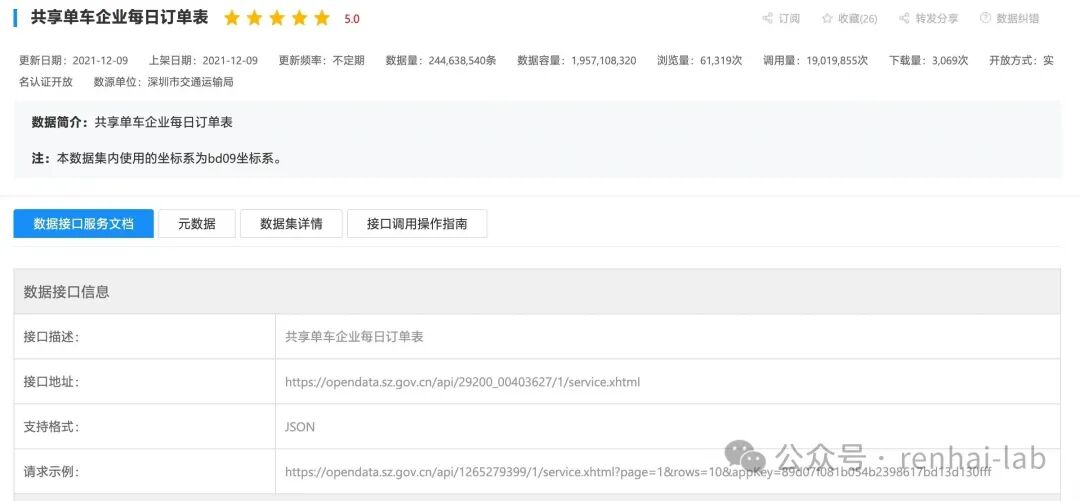
深圳数据开放平台也提供调用数据接口的方式进行下载:
我们将使用简洁且流行的 Python 来完成数据获取,核心是 requests 库。当然,你也可以使用 http.client 或异步库如 aiohttp。
在数据接口详情页上,官方给出了调用说明:

首先,你需要登录网站并完成前两步:
第一步:提交应用名称
根据提示填写相关信息并提交。成功后,可在个人中心-我的应用中查看你的 appKey。
第二步:订阅接口
第三步:测试接口
完成订阅后,你可以在线测试接口。
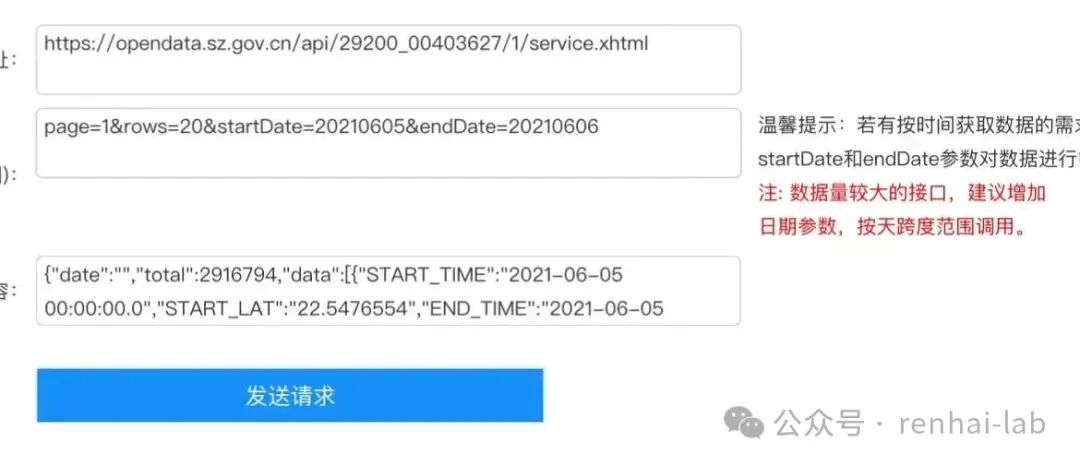
关键提示:若有按时间获取数据的需求,务必使用 startDate 和 endDate 参数对数据进行筛选。
所以,我们的任务就是用 Python 编写一个 requests 请求,并将返回的数据存储到CSV文件中。
3. 配置数据库(获取少量数据可跳过)
如果你只需要获取几天的数据,可以完全跳过这一步!
为什么数据库很重要?
如果你计划存储整个数据集(2.4亿条),强烈不建议将数据保存在单个JSON或CSV文件中。因为文件大小可能超过电脑内存,导致无法读取和查询。有些人会选择按日期分割成多个文件保存,但分散的文件不利于维护和查询。例如,如果你想查询某个企业在特定时间段内的订单,使用数据库将是最高效的方式。因此,对于大规模数据处理,数据库几乎是必备的选择。
4. 配置 Python 环境
对于新手,一个关键建议是:不要使用 Anaconda 管理环境,直接安装官方 Python 包即可。
为什么推荐新手从官方包开始?
- 简化学习:避免环境管理工具的复杂性,让你更专注于
Python 本身。
- 掌握基础:帮助你理解如何配置环境、使用
pip 等核心技能。
- 节省资源:Anaconda 附带大量你可能暂时用不到的包,官方安装包更轻量。
- 灵活控制:可以自由选择所需的库和版本,减少潜在的依赖冲突。
从基础开始,能为后续学习打下更坚实的根基。当然,Anaconda 在数据科学领域有其便利性,但初学者从简入手往往收益更大。
进阶提示:对于有经验的用户,可以尝试 uv 作为Anaconda的替代品,它在速度上有显著优势。
1)Windows 安装 Python
- 下载 Python: 访问 Python 官网。
- 安装 Python: 运行安装程序,务必勾选“Add Python to PATH”,然后点击“Install Now”。
- 验证安装: 打开命令提示符(CMD),输入
python --version 并回车。若显示版本号则安装成功。
2)macOS 安装 Python
- 下载 Python: 访问 Python 官网。
- 安装 Python: 打开下载的
.pkg 文件,按向导完成安装。
- 验证安装: 打开终端(Terminal),输入
python3 --version 并回车。若显示版本号则安装成功。
5. 安装依赖
pip 是 Python 的包管理工具。以下是安装必要库的步骤。
1)确保已安装 pip
大多数现代 Python 安装包已自带 pip。打开命令行或终端,运行以下命令检查:
pip --version
如果已安装,会显示版本信息。若未安装,请参考 Python 官方文档进行安装。
2)使用 pip 安装包
安装 Python 包的基本命令格式为:
pip install <package_name>
本次任务需要在终端运行以下命令:
pip install pandas requests -i https://pypi.tuna.tsinghua.edu.cn/simple
简要说明:
pandas: 一个强大的数据分析和处理库。requests: 用于发送HTTP请求的库。-i https://pypi.tuna.tsinghua.edu.cn/simple: 指定使用清华大学的PyPI镜像源,在国内访问速度更快。
6. 准备代码
- 新建一个文件夹,例如
shenzhen_data。
- 在该文件夹内新建一个文本文件,重命名为
main.py。
- 用文本编辑器(如记事本、VS Code)打开
main.py,将以下代码复制进去。
"""
深圳共享单车数据研究——获取数据(无数据库版,适合初学者)
数据名称:共享单车企业每日订单表
更新日期:2021-12-09 上架日期:2021-12-09
更新频率:不定期
数据量:244,638,540条
数据容量:1,957,108,320
开放方式:实名认证
开放数源单位:深圳市交通运输局
数据简介:共享单车企业每日订单表
说明:
- 本脚本不再依赖 MongoDB,数据将直接保存为 CSV 文件;
- 时间字段保留接口返回的原始本地时间字符串(不做时区转换);
- 按页追加写入 CSV,首页写入表头,其余页不写入表头。
"""
import time
from pathlib import Path
import pandas as pd
import requests
def _build_output_csv(start_date: str, end_date: str) -> Path:
"""根据日期范围生成输出 CSV 路径,位于项目 data 目录。"""
project_root = Path(__file__).resolve().parent.parent.parent
csv_dir = project_root / "data" / "raw"
csv_dir.mkdir(parents=True, exist_ok=True)
filename = (
f"bike_orders_{start_date}_{end_date}.csv"
if start_date != end_date
else f"bike_orders_{start_date}.csv"
) # 如果你要修改导出的csv的文件名,请修改这里。
return csv_dir / filename
# 主函数
if __name__ == "__main__":
# 环境变量和初始化
app_key = "4xxxxxxxxxxxxxxxxxxxxxxxxxx5" # TODO: 替换为你从深圳开放数据平台申请的 app_key
page_num = 1
rows = 4000
# 日期范围 可以选择你要爬取的范围
startDate = "20210820" # TODO: 替换为你要爬取的开始日期,格式 YYYYMMDD
endDate = "20210820" # TODO: 替换为你要爬取的结束日期,格式 YYYYMMDD
url = "https://opendata.sz.gov.cn/api/29200_00403627/1/service.xhtml"
# 请求头 不加请求会被拒绝
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Accept": "application/json, text/javascript, */*; q=0.01",
}
# 输出 CSV
output_csv = _build_output_csv(startDate, endDate)
print(f"数据将保存到: {output_csv}")
# 数据请求和处理循环
while True:
params = {
"appKey": app_key,
"page": page_num,
"rows": rows,
"startDate": startDate,
"endDate": endDate,
}
response = requests.get(url, headers=headers, params=params)
if response.status_code != 200:
print(f"请求错误,状态码:{response.status_code}")
break
items = response.json().get("data", [])
if not items:
print("没有更多数据或数据为空,结束。")
break
# 将本页数据追加写入 CSV
df = pd.DataFrame(items)
write_header = (page_num == 1) and (not output_csv.exists())
df.to_csv(
output_csv, mode="a", index=False, encoding="utf-8-sig", header=write_header
)
print(f"已写入第 {page_num} 页,共 {len(df)} 条。")
# 判断是否继续
if len(items) < rows:
print("最后一页已写完。")
break
else:
page_num += 1
# 轻微休眠,避免请求过快
time.sleep(0.5)
上述代码也可在 GitHub 查看:fetcher-legacy.py
你需要修改以下三处代码:
app_key = "4137xxxxxxxxxxxxxxxx68d0d5" # <<<<<<<< 填写从深圳开放数据平台申请的app_key
startDate = "20210820" # TODO: 替换为你要爬取的开始日期,格式 YYYYMMDD
endDate = "20210820" # TODO: 替换为你要爬取的结束日期,格式 YYYYMMDD
7. 运行脚本
-
打开终端(命令提示符),并切换到你的代码文件夹:
cd /path/to/shenzhen_data # 请修改为你的文件夹实际路径
# 如果路径包含空格或特殊字符,请使用英文引号,例如:cd "/my path/to/shenzhen_data"
-
运行 Python 脚本:
python main.py
-
查看输出:如果运行成功,终端会显示写入进度,如下图所示。

8. 查看数据
根据运行成功时提示的路径,找到生成的CSV文件(例如 bike_orders_20210820.csv),用Excel或任何文本编辑器打开即可查看数据。
9. 常见问题
欢迎在 Github Issue 上集中讨论问题。
(1)如何获取全量2.4亿条数据?
需要使用支持高并发、多线程且包含数据库的版本。完整源代码请参考Github项目:深圳共享单车 2.4 亿级数据获取与 PostGIS 分析流水线。若无法访问GitHub,可使用Gitee镜像。
(2)数据字段相关
- 坐标系问题:官方标注数据集使用bd09坐标系,但实测可能为WGS1984或GCJ02。建议对具体日期的坐标数据进行验证。详细排查过程可参考文章:共享单车数据坐标系排查实录。
- 企业ID字段:请注意,并非所有数据都包含企业ID (
COM_ID)字段。
(3)Python 学习相关
(4)浏览器访问链接出错,但Python调用正常
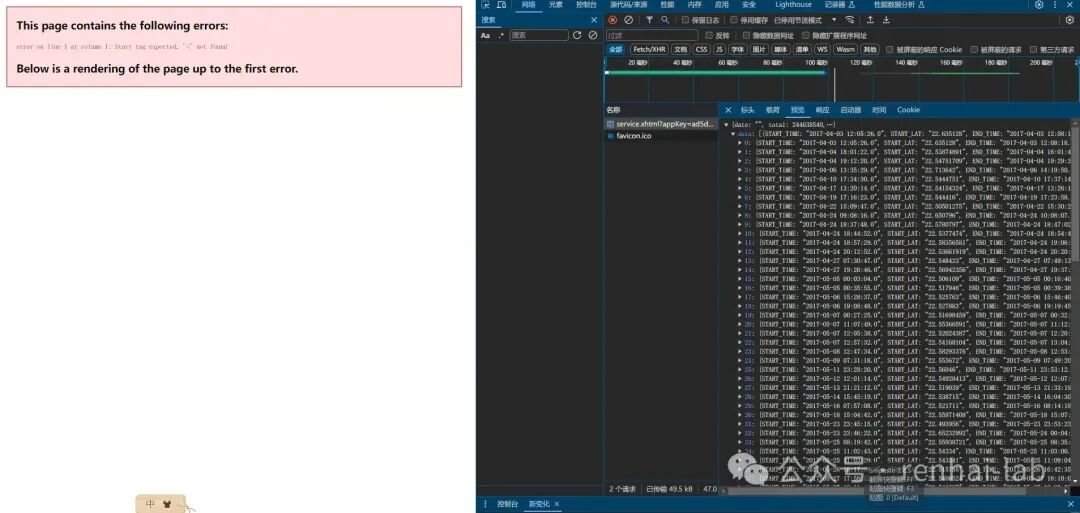
这是正常现象。错误信息 Start tag expected, '<' not found 表明浏览器尝试将返回的数据解析为XML(或HTML),但实际返回的是纯JSON数据。浏览器无法直接渲染JSON,因此报错。你可以按F12打开开发者工具,在“Network(网络)”标签页中找到该请求,查看其“Response(响应)”内容,即可看到正确的JSON数据。
(5)【遗留问题】查询不到数据
- 时区问题:如果你参考过旧文章并使用MongoDB储存,请注意数据库内的时间是UTC时区。
- 字段类型:检查数据库中
START_TIME 字段的类型是 Date 还是 String。如果不是 Date 类型,建议进行转换并创建索引以加快查询速度。若图简便,可在查询时使用字符串比较:
query = {
'START_TIME': {
'$gte': '2021-08-04 16:00:00', # 使用字符串比较
'$lt': '2021-08-05 16:00:00' # 使用字符串比较
}
}
写在最后
支持与反馈
如果你希望直接获取已处理好的按日分割的共享单车数据文件(CSV/GeoJSON),可以通过爱发电支持作者并获取国内网盘下载链接。
如果你对本文有任何意见、对文中图表的制作方法感兴趣,或者有任何其他问题,欢迎在文章评论区留言。你的问题很可能也是别人遇到的。
- 本文同步发布和更新于个人网站,你可以在相关平台点击“阅读原文”跳转。
- 如果你觉得这个主题有趣,欢迎点赞、在看或分享。
- 欢迎在评论区讨论你在处理类似数据时遇到的任何问题,或者聊聊你对哪个技术方向最感兴趣,这可能会影响我后续内容的侧重点。
本文在云栈社区进行过优化和整理,旨在提供更清晰的技术指引。
 发表于 2026-2-28 07:32:29
|
查看: 286|
回复: 0
发表于 2026-2-28 07:32:29
|
查看: 286|
回复: 0
