如何让你的 AI 助手拥有“长期记忆”?本文将从架构设计到代码实现,带你深入理解一个生产级的 Agent 记忆系统。
你是否遇到过这样的困扰:与AI聊了很久,它却像初次见面一样,对你之前提到的喜好或约定毫无印象?这并非AI的“健忘”,而是源于大语言模型(LLM)的一个根本特性——无状态。每次对话对LLM来说,都是一次全新的开始。要让AI真正成为一个可靠的智能助手,构建一套记忆系统是必不可少的工程实践。
本文将分享一套基于Rust实现的记忆系统架构,深入探讨其设计哲学、核心组件与工作流程,并附上可直接运行的代码示例。
为什么AI Agent需要记忆系统?
LLM的局限性
大语言模型固然强大,但存在一个核心瓶颈:有限的上下文窗口。即便最新的模型支持百万级别的tokens,也不可能无限制地记住所有历史对话。这背后是几个现实问题:
- 成本激增:每次交互都携带完整的对话历史,API调用成本会迅速累积。
- 注意力稀释:过长的上下文会导致模型注意力分散,反而影响当前回复的质量。
- 信息孤岛:不同会话之间的信息无法互通,每次对话都从零开始。
记忆系统的价值
一个设计精良的记忆系统,能有效弥补上述缺陷,为AI Agent赋予:
- ✅ 跨会话记忆:记住用户的身份、偏好和历史交互细节。
- ✅ 智能检索:根据当前对话的语义,精准召回最相关的历史信息。
- ✅ 知识沉淀:将交互中产生的有价值信息(如用户提供的资料)长期保存。
- ✅ 成本优化:用高效的检索替代冗长的上下文传递,降低token消耗。
系统架构概览
agent-io的记忆系统采用了分层架构设计,职责清晰,易于扩展。
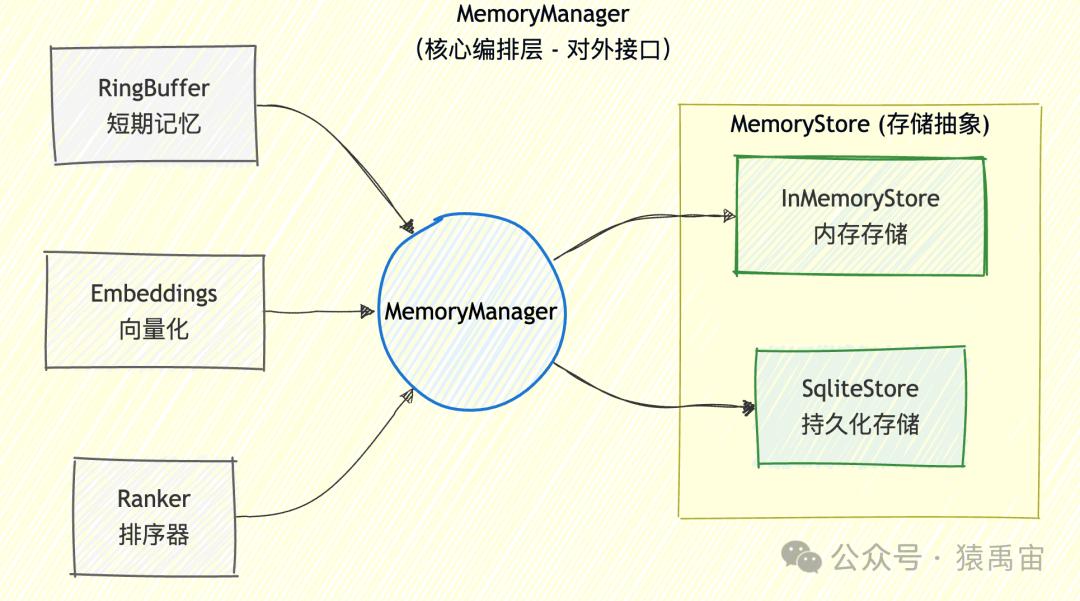
核心模块职责
| 模块 |
职责 |
文件 |
MemoryManager |
统一入口,协调各组件 |
manager.rs |
MemoryEntry |
记忆条目的核心数据结构 |
entry.rs |
MemoryStore |
存储抽象trait |
store.rs |
RingBuffer |
实现短期记忆的环形缓冲区 |
buffer.rs |
EmbeddingProvider |
文本向量化接口 |
embeddings.rs |
MemoryRanker |
记忆相关性排序器 |
ranker.rs |
核心组件详解
记忆条目(MemoryEntry)
每条记忆都被封装为一个结构化的数据条目,这是系统的基础单元。
pub struct MemoryEntry {
pub id: String, // 唯一标识
pub content: String, // 记忆内容
pub embedding: Option<Vec<f32>>, // 向量表示(用于相似度搜索)
pub memory_type: MemoryType, // 记忆类型
pub metadata: HashMap<String, Value>, // 元数据
pub created_at: DateTime<Utc>, // 创建时间
pub last_accessed: Option<DateTime<Utc>>, // 最后访问时间
pub importance: f32, // 重要性评分 (0.0 - 1.0)
pub access_count: u32, // 访问次数
}
记忆类型分类
系统借鉴了认知心理学模型,对记忆进行了分类:
pub enum MemoryType {
ShortTerm, // 短期记忆:最近的对话
LongTerm, // 长期记忆:持久化知识
Episodic, // 情景记忆:特定事件/经历
Semantic, // 语义记忆:事实和概念
}
- 短期记忆:容量有限,存取迅速,类似于我们的“工作记忆”,存放最近几轮对话。
- 长期记忆:容量理论上无限,需要检索才能访问,用于存放需要持久化的信息。
- 情景记忆:记录个人经历,例如“昨天用户告诉我他养了一只猫”。
- 语义记忆:存储通用事实和概念,例如“巴黎是法国的首都”。
相关性评分算法
系统会根据多重因素动态计算每条记忆与当前查询的相关性分数。
pub fn relevance_score(&self) -> f32 {
let age_hours = (Utc::now() - self.created_at).num_hours() as f32;
let recency_factor = (-age_hours / 24.0 / 7.0).exp(); // 一周内指数衰减
let access_factor = 1.0 + (self.access_count as f32).ln().max(0.0) * 0.1;
self.importance * recency_factor * access_factor
}
评分公式为:score = 重要性 × 时间衰减因子 × 访问频率因子。该算法确保了越重要、越新鲜、被访问越频繁的记忆,在检索时排名越靠前。
存储抽象(MemoryStore)
为了支持多种存储后端,系统使用Trait定义了统一的存储接口,这大大提升了灵活性和可测试性。
#[async_trait]
pub trait MemoryStore: Send + Sync {
async fn add(&self, entry: MemoryEntry) -> Result<String>;
async fn search(&self, query: &str, limit: usize) -> Result<Vec<MemoryEntry>>;
async fn search_by_embedding(&self, embedding: &[f32], limit: usize, threshold: f32)
-> Result<Vec<MemoryEntry>>;
async fn get(&self, id: &str) -> Result<Option<MemoryEntry>>;
async fn update(&self, entry: MemoryEntry) -> Result<()>;
async fn delete(&self, id: &str) -> Result<()>;
async fn clear(&self) -> Result<()>;
async fn count(&self) -> Result<usize>;
}
内存存储实现
InMemoryStore适合开发和测试场景,所有数据保存在内存的HashMap中。
pub struct InMemoryStore {
memories: RwLock<HashMap<String, MemoryEntry>>,
}
它支持基于向量余弦相似度的语义搜索。向量相似度是人工智能领域实现语义理解的关键技术。
fn cosine_similarity(a: &[f32], b: &[f32]) -> f32 {
let dot: f32 = a.iter().zip(b.iter()).map(|(x, y)| x * y).sum();
let norm_a: f32 = a.iter().map(|x| x * x).sum::<f32>().sqrt();
let norm_b: f32 = b.iter().map(|x| x * x).sum::<f32>().sqrt();
dot / (norm_a * norm_b)
}
SQLite存储实现
SqliteStore适用于生产环境,提供持久化存储能力,并巧妙利用SQLite的特性实现高效检索。
pub struct SqliteStore {
conn: Arc<Mutex<Connection>>,
}
数据库设计亮点:
- FTS5全文搜索:利用SQLite内置的FTS5扩展实现快速关键词匹配。
- 向量存储:将高维向量序列化为BLOB字段存储。
- 自动同步:通过触发器,在数据表更新时自动维护全文索引。
CREATE VIRTUAL TABLE memories_fts USING fts5(
id UNINDEXED,
content,
content='memories',
content_rowid='rowid'
);
-- 自动同步触发器
CREATE TRIGGER memories_ai AFTER INSERT ON memories BEGIN
INSERT INTO memories_fts(rowid, id, content)
VALUES (new.rowid, new.id, new.content);
END;
短期记忆缓冲区(RingBuffer)
短期记忆采用环形缓冲区实现,这是一种经典数据结构,固定容量,新数据满时会自动覆盖最旧的数据。
pub struct RingBuffer<T> {
buffer: VecDeque<T>,
capacity: usize,
}
impl<T> RingBuffer<T> {
pub fn push(&mut self, item: T) {
if self.buffer.len() == self.capacity {
self.buffer.pop_front(); // 淘汰最旧的
}
self.buffer.push_back(item);
}
}
设计优势:
- O(1)时间复杂度的插入和删除操作,性能高效。
- 内存占用可控,不会无限增长。
- 完美模拟了人类“最近对话”的记忆特性。
向量嵌入(Embeddings)
记忆系统的语义搜索能力,核心依赖于将文本转换为向量表示的嵌入模型。
#[async_trait]
pub trait EmbeddingProvider: Send + Sync {
async fn embed(&self, text: &str) -> Result<Vec<f32>>;
async fn embed_batch(&self, texts: &[&str]) -> Result<Vec<Vec<f32>>>;
fn dimension(&self) -> usize;
}
系统内置了多种嵌入模型供选择:
| Provider |
模型 |
维度 |
OpenAIEmbedding |
text-embedding-3-small |
1536 |
OpenAIEmbedding |
text-embedding-3-large |
3072 |
MockEmbedding |
测试用Mock |
可配置 |
记忆排序器(Ranker)
当从不同存储中检索到多条候选记忆时,Ranker负责对它们进行综合排序,返回最相关的Top-K结果。
pub struct RankingWeights {
pub similarity: f32, // 向量相似度权重 (默认0.4)
pub importance: f32, // 重要性权重 (默认0.25)
pub recency: f32, // 时效性权重 (默认0.2)
pub frequency: f32, // 访问频率权重 (默认0.15)
}
综合评分公式为:
最终分数 = 0.4 × 语义相似度 + 0.25 × 重要性 + 0.2 × 时效性 + 0.15 × 访问频率
时间衰减机制
系统模拟了记忆随时间淡忘的过程,重要性会按配置进行衰减。
pub struct DecayConfig {
pub daily_rate: f32, // 每日衰减率 (默认 1%)
pub min_threshold: f32, // 最小阈值 (低于此值的记忆可被清理)
pub grace_period_days: u32, // 宽限期 (新记忆在此期间不衰减)
}
衰减公式:当前重要性 = 原始重要性 × (1 - 每日衰减率)^已过天数
核心工作流程
记忆存储流程(Remember)
当需要记住一段新信息时,系统会执行以下流程:
pub async fn remember(&mut self, content: &str, memory_type: MemoryType) -> Result<String> {
// 1. 生成向量嵌入
let embedding = self.embedder.embed(content).await?;
// 2. 创建记忆条目
let entry = MemoryEntry::new(content)
.with_type(memory_type)
.with_embedding(embedding);
// 3. 根据类型选择存储位置
match memory_type {
MemoryType::ShortTerm => {
self.short_term.push(entry.clone());
Ok(entry.id)
}
_ => {
if self.config.enable_long_term {
self.store.add(entry).await // 持久化存储
} else {
self.short_term.push(entry.clone());
Ok(entry.id)
}
}
}
}
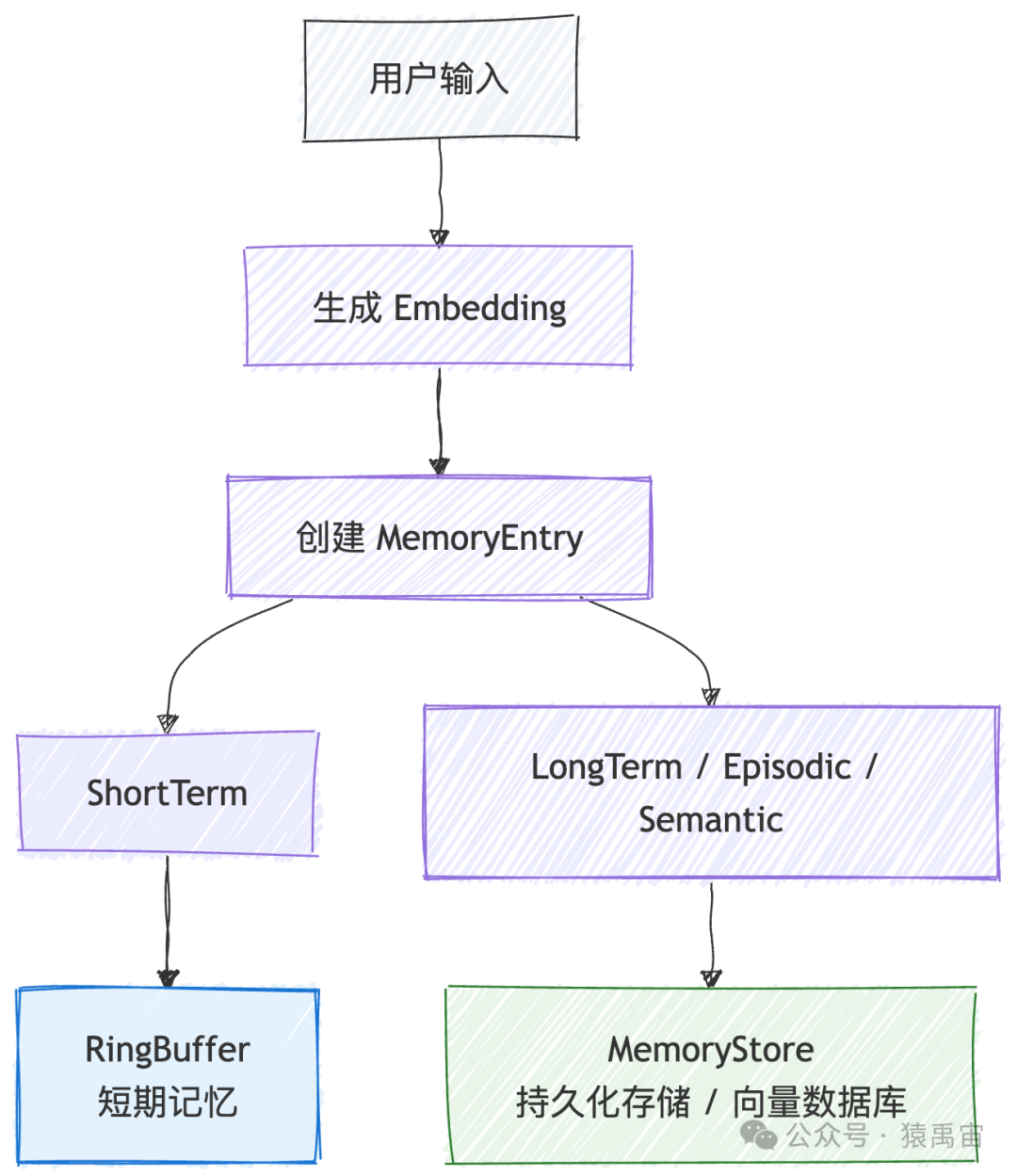
记忆检索流程(Recall)
当Agent需要回想与当前对话相关的信息时,触发检索流程。
pub async fn recall(&self, query: &str) -> Result<Vec<MemoryEntry>> {
// 1. 将查询文本向量化
let query_embedding = self.embedder.embed(query).await?;
// 2. 并行从长期记忆存储中检索
let mut memories = self.store
.search_by_embedding(&query_embedding, limit, threshold)
.await?;
// 3. 从短期记忆缓冲区中检索
for entry in self.short_term.iter_recent() {
if let Some(ref embedding) = entry.embedding {
let similarity = cosine_similarity(&query_embedding, embedding);
if similarity >= threshold {
memories.push(entry.clone());
}
}
}
// 4. 对所有候选记忆按综合相关性排序
memories.sort_by(|a, b| b.relevance_score().partial_cmp(&a.relevance_score()).unwrap());
// 5. 限制返回数量
memories.truncate(self.config.retrieval_limit);
Ok(memories)
}
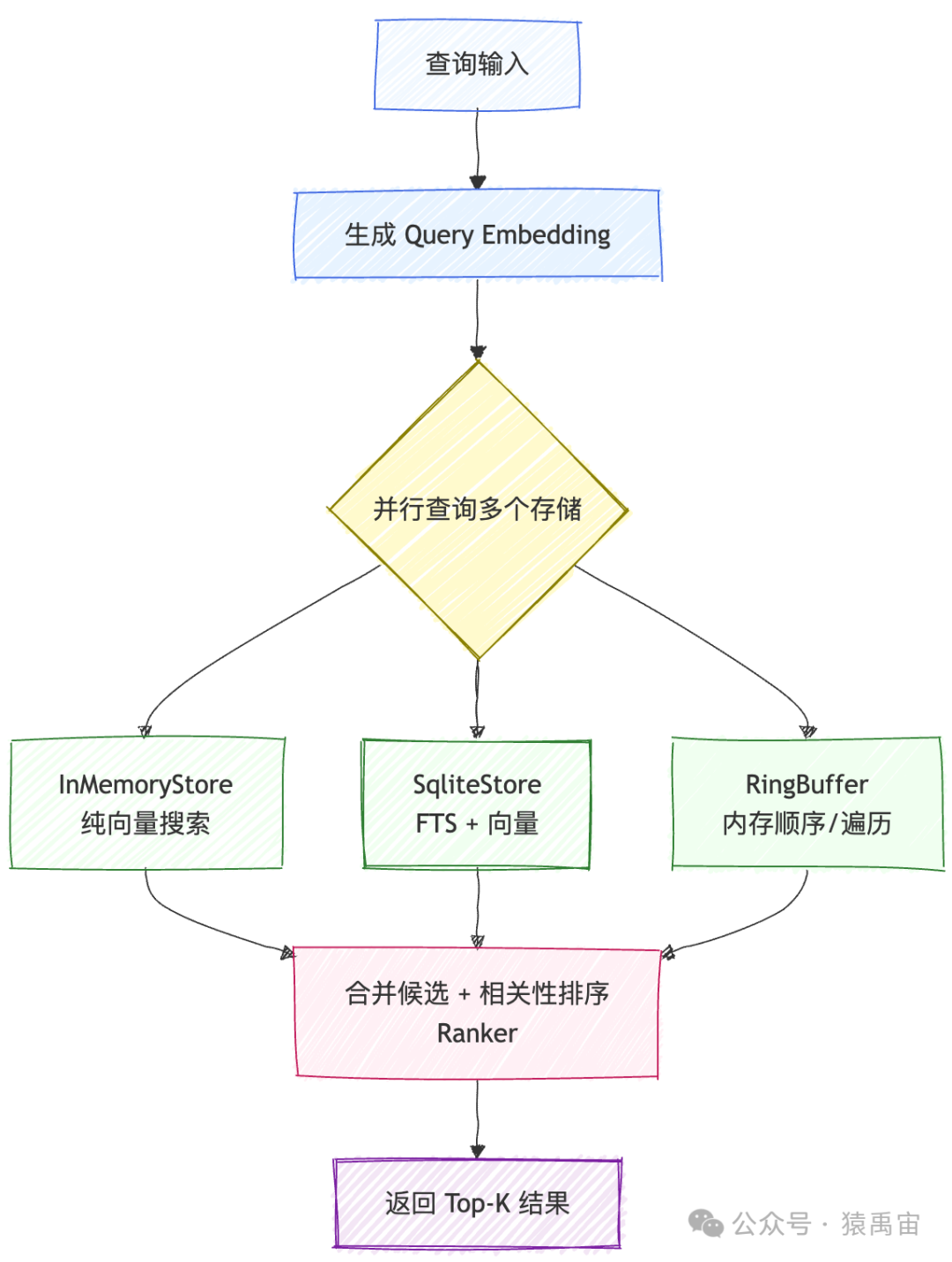
实战示例
基本使用
下面是一个完整的示例,展示如何初始化记忆管理器并执行记忆的存储与检索。
use agent_io::memory::{
MemoryManager, MemoryConfig, MemoryType,
InMemoryStore, MockEmbedding
};
#[tokio::main]
async fn main() -> Result<()> {
// 1. 创建存储和向量化服务
let store = Arc::new(InMemoryStore::new());
let embedder = Arc::new(MockEmbedding::new(384));
// 2. 创建记忆管理器
let config = MemoryConfig {
short_term_size: 20,
enable_long_term: true,
retrieval_limit: 5,
relevance_threshold: 0.7,
..Default::default()
};
let mut manager = MemoryManager::new(config, store, embedder);
// 3. 存储记忆
manager.remember("用户喜欢 Rust 编程语言", MemoryType::LongTerm).await?;
manager.remember("用户是软件工程师", MemoryType::Semantic).await?;
manager.remember("上次讨论了异步编程", MemoryType::Episodic).await?;
// 4. 检索相关记忆
let memories = manager.recall("编程").await?;
for memory in memories {
println!("相关记忆: {}", memory.content);
}
// 5. 构建上下文
let context = manager.recall_context("用户的技术背景").await?;
println!("上下文: {}", context);
Ok(())
}
使用SQLite持久化
切换到持久化存储非常简单。
use agent_io::memory::SqliteStore;
// 创建文件数据库
let store = Arc::new(SqliteStore::open("./data/memories.db")?);
// 或使用内存数据库(测试用)
let store = Arc::new(SqliteStore::new()?);
自定义排序权重
你可以根据应用场景调整排序策略的侧重点。
use agent_io::memory::{MemoryRanker, RankingWeights};
let weights = RankingWeights {
similarity: 0.5, // 更重视语义相似度
importance: 0.3,
recency: 0.1,
frequency: 0.1,
};
let ranker = MemoryRanker::with_weights(weights)
.with_recency_half_life(24.0 * 3.0); // 设置半衰期为3天
设计亮点与可扩展性
架构设计总结
| 特性 |
实现方式 |
| 存储抽象 |
Trait + 多后端实现,轻松切换 |
| 短期/长期分离 |
RingBuffer + Store 双层架构,符合认知模型 |
| 语义搜索 |
Embedding 向量化 + 余弦相似度计算 |
| 混合检索 |
FTS全文搜索 + 向量语义搜索,双管齐下 |
| 相关性排序 |
多因子(相似度、重要性、时效性、频率)加权评分 |
性能与扩展
- 异步设计:所有I/O操作为
async,支持高并发场景。
- 批量处理:
embed_batch支持批量文本向量化,显著减少API调用次数。
- 易于扩展:实现
MemoryStore或EmbeddingProvider trait即可接入自定义的存储后端或嵌入服务。
// 自定义存储后端
impl MemoryStore for MyCustomStore { ... }
// 自定义嵌入服务
impl EmbeddingProvider for MyEmbeddingService { ... }
未来展望
当前系统已具备生产可用性,但仍有进化空间:
- 集成专业向量数据库:对于超大规模记忆库,可接入Qdrant、Milvus等,获得更优的检索性能与管理功能。
- 记忆压缩与摘要:使用LLM对陈旧或冗余的记忆进行总结压缩,释放存储空间。
- 自动化遗忘机制:基于
DecayConfig,自动清理重要性低于阈值的历史记忆。
- 支持多模态记忆:扩展系统以支持图像、音频等非文本记忆的存储与检索。
- 记忆推理与联想:不局限于检索,还能基于已有记忆进行推理,生成新的洞察或知识。
结语
这套记忆系统的设计,是认知科学原理与现代软件工程的一次有趣结合。它通过分层的架构、清晰的抽象、以及多因子权衡的算法,为AI Agent赋予了既灵活又高效的记忆能力。希望本文的解析和代码实践,能为你在构建更智能的AI应用时提供扎实的参考。
完整代码请访问GitHub仓库:https://github.com/lispking/agent-io
对AI Agent开发、Rust系统编程或相关架构设计感兴趣的朋友,欢迎在技术社区进行更深入的交流与探讨,例如在云栈社区的相关板块分享你的见解与实践。
 发表于 2026-3-2 01:58:31
|
查看: 161|
回复: 0
发表于 2026-3-2 01:58:31
|
查看: 161|
回复: 0
