Pigsty v4.2 正式发布,紧随 PostgreSQL 紧急号外小版本更新。
本次更新同时交付了三款全新 PG 内核 —— 图数据库 AgensGraph、多写分布式 pgEdge、MPP 数仓 Cloudberry —— 并重建了 Babelfish、OrioleDB、OpenHalo 三款既有内核。至此,Pigsty 支持的内核总数达到了 12 个。

你可以用一份配置文件,把所有这些不同风味的 PostgreSQL 部署为自带监控、高可用、时间点恢复与 IaC 的企业级数据库服务。这就是 “Meta PG 发行版” 的含义。
内核大观园
PostgreSQL 以极致的可扩展性闻名。生态中有超过 1000 个扩展,Pigsty 则提供了其中 461 个开箱即用。
但有些能力是扩展做不到的 —— 比如定制语法。如果你想在 PostgreSQL 里原生使用 Oracle 的 PL/SQL、SQL Server 的 T-SQL、MongoDB 的 BSON 协议、或者 Cypher 图查询语法,而不是通过函数调用来模拟,那你就需要修改内核。这也是为什么 Pigsty 不仅提供生态中数量最多的扩展,还要支持不同的内核分支。
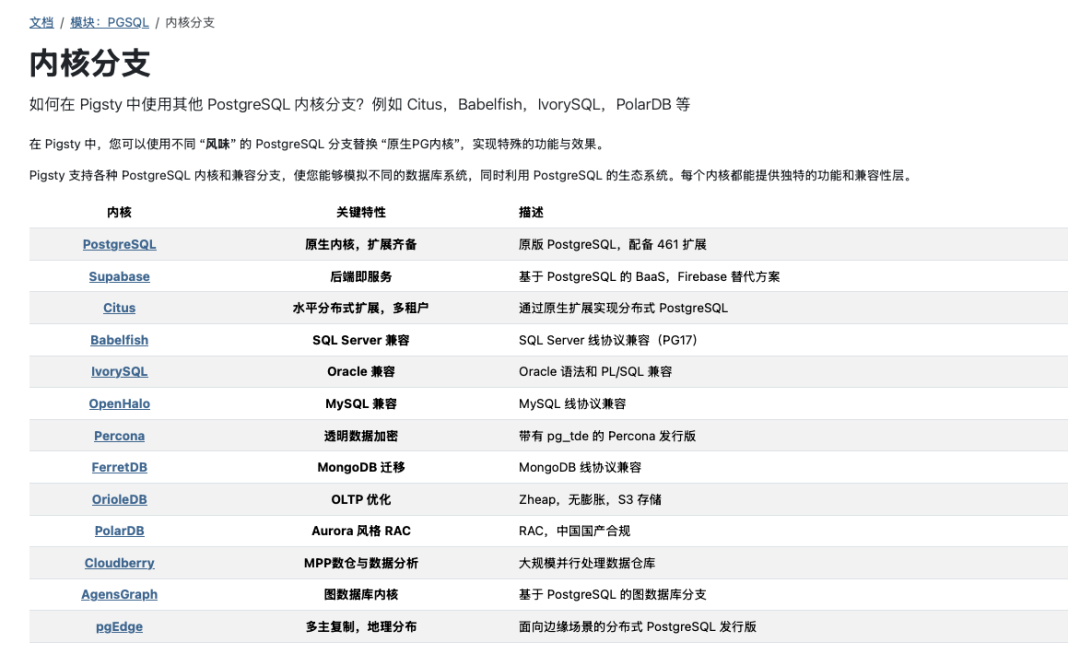

在 Pigsty 里使用这些内核,和使用原版 PostgreSQL 几乎没有区别 —— 同样的部署流程、同样的监控面板、同样的高可用机制、同样的备份恢复。区别只是配置文件里改一个 pg_mode 的值。一行配置的差异,工程上的大一统。
十二内核,一份配置。下面逐个展开。
原生 PostgreSQL
这次 PostgreSQL 的小版本更新值得单独提一下。
18.2 系列引入了 substring 与 WAL 回放相关的回归问题 —— 修漏洞的时候带进了新 bug。社区反应很快,两周后紧急发布了 18.3 / 17.9 / 16.13 / 15.17 / 14.22 补丁版本。Pigsty 的做法还是老规矩 —— 新版本发布次日,离线安装包就绪、所有扩展重新编译验证、文档同步更新。你要做的就是一行命令的事。
扩展总数也顺势推到了 461 个。
如果你追求极致的可扩展性和最佳的稳定性,原生 PostgreSQL 始终是最佳默认选择。Pigsty 支持处于生命周期内的 PG 14 到 PG 18。值得一提的是,本版本是最后一个支持 PG 13 的版本,后续最低版本将升至 PG 14。
pgEdge:原生多主复制
pgEdge 是本次新增的重量级选手。
传统 PostgreSQL 高可用是一主多从 —— 写操作只能发往主节点。pgEdge 的核心扩展 Spock 打破了这个限制:集群中的每个节点都可以读写,数据通过逻辑复制在节点间异步同步,冲突通过可配置策略自动解决。
严格来说,pgEdge 不是一个全新的内核,而是基于标准 PostgreSQL + Spock 扩展的多主方案。但由于多主复制的一些底层能力需要内核补丁(这些 Patch 尚未合并到 PostgreSQL 主干),它目前不得不以“Patch 内核 + 扩展”的方式发布。这一点和 OrioleDB、Percona TDE 类似 —— 如果 PostgreSQL 主干未来合并了这些 Patch,它们都可以转变为纯扩展形态工作,这是非常值得期待的趋势。
我很看好这个项目。pgEdge 团队有几位 PostgreSQL 社区的内核老将,技术功底很扎实。关于它的开源历程也值得一说:之前它使用的是类似 Confluent 风格的 Source Available 协议(pgEdge Community License),严格来说不算开源。但 2025 年 9 月,它全面转向了 PostgreSQL License。
不过有个细节需要注意:源代码遵循 PostgreSQL 协议,但官方提供的二进制包依然受商业许可约束。具体来说,开发环境可以免费使用,但生产环境必须付费订阅。
老冯直接基于 PostgreSQL 协议的源码自行打包 —— 制作了带 Patch 的 PostgreSQL 内核包,并在 Pigsty 支持的全部主流操作系统上完成适配。没有外部依赖,从 Pigsty 仓库直接装就行,不存在生产环境的许可问题。当然,如果你想用他们的云服务和商业支持,也欢迎去打钱支持一下。
pgEdge 由三个核心扩展组成:
- Spock 5.0.5:多主逻辑复制引擎,每个节点同时处理读写
- Lolor 1.2.2:大对象逻辑复制
- Snowflake 2.4:分布式序列号生成
冲突解决方面,pgEdge 提供了多种策略:最简单的“最后写入获胜”(LWW)、专门的 CRDT 方案、冲突日志表、以及用户自定义策略。如果你有全球地理分布的需求 —— 比如北京、法兰克福、弗吉尼亚各放一个节点,用户就近读写 —— 这种多主模式非常合适。它相当于在 PostgreSQL 生态里原生提供了类似 CockroachDB / TiDB 的多写能力,只不过底座还是那个你熟悉的 PostgreSQL。
在 Pigsty 中使用只需要:configure -c pgedge。
AgensGraph:图数据库
AgensGraph 的定位是基于 PostgreSQL 的多模型图数据库 —— 在一个引擎内同时原生支持关系模型和属性图模型,而不是像 Neo4j 那样另起炉灶。这是由韩国 Bitnine 团队发起主导的项目。
有人会问:PostgreSQL 生态里不是有 Apache AGE 这个图扩展吗?为什么还要做 fork 内核?
这里有个有意思的渊源:AGE 和 AgensGraph 其实是同一个团队做的。最初他们做的是 AgensGraph 这个内核 fork,大概 1000 多个 Star。后来他们尝试以扩展形式实现类似功能,做了 AGE 并捐献给 Apache。结果扩展形式反而更受欢迎,拿到了 4000 多个 Star。AGE 虽然去年经历了一阵维护风波,但最近已恢复更新,发布了针对 PG 17/18 的 1.7.0 版本。
那 fork 版本还有什么存在价值?至少四个方面:
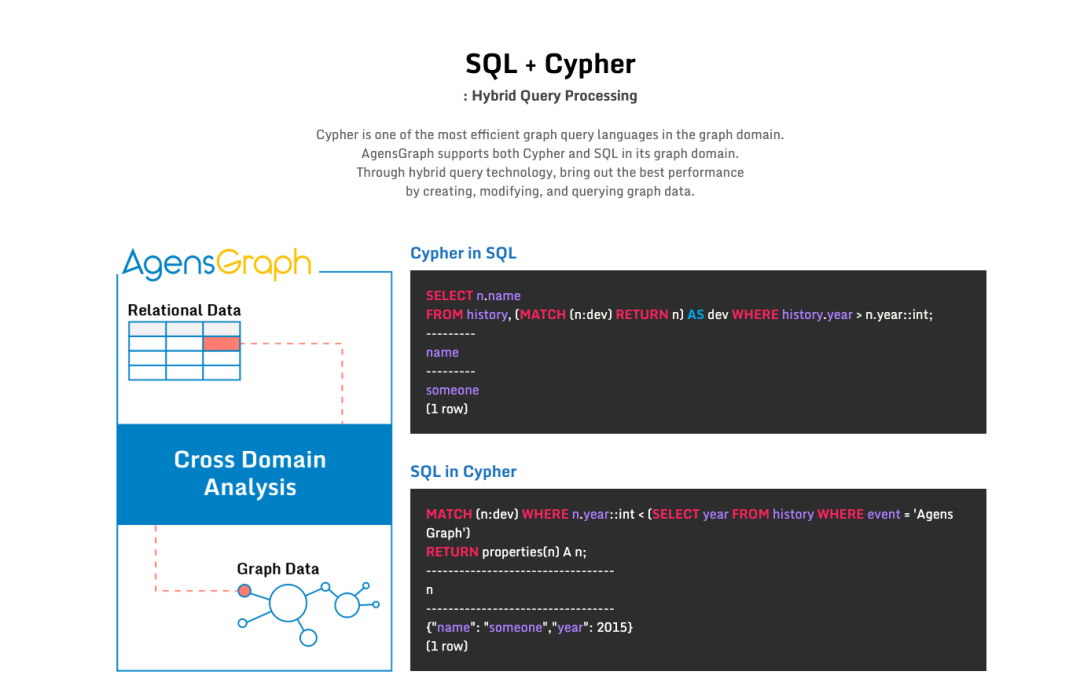
一是原生语法。在 AGE 里,你需要用函数调用来执行 Cypher 查询(把查询字符串传进去);而在 AgensGraph 里,你可以直接写 CREATE GRAPH,Cypher 是一等公民语法。
二是存储优化。它的存储引擎针对图属性做了专门优化,理论上性能更好(虽然我还没实际 bench 过)。
三是查询优化统一。Cypher、JSON、SQL 三种查询语言在优化器层面是统一处理的,这种原生实现方式很有意思。
四是向量兼容。AgensGraph 最近宣称支持了 pgvector 兼容,意味着可以在同一个库里做 Graph RAG —— 图 + 向量的组合检索。这是当下非常火的前沿方向。这个专门的 vector 插件我还没打包进来,后面可能会补上。
当然,fork 路径的代价也很明显:版本跟进 PG 主线的难度很高。目前 PG 已经到 18 了,AgensGraph 还是基于 PG 16。这始终是 fork 方案的宿命,要落后一两个大版本。
在 Pigsty 中使用:configure -c agens。
Cloudberry:MPP 数仓
Cloudberry 是本次新增的第三款内核。它是一个 Apache 项目,由 HashData 团队主导,本质上是 Greenplum 7 的 fork —— 但做了不少改进,比如内核从 Greenplum 的 PG 12 升级到了 PG 14,补上了不少好用的新特性。
Cloudberry 2.0 发布后就不再提供官方二进制包了 —— 之前 1.18 和 1.19 还有 RPM,现在也没了。我等了几个月没见到官方有计划解决这个问题,就决定在 Claude 的帮助下自己动手。打包过程整体顺利,只是在个别较新的操作系统上需要改些代码、打几个补丁。之前只有 RPM,现在 DEB 也有了,Pigsty 支持的 14 个 Linux 发行版上全部可用。
关于 Cloudberry/Greenplum 的部署脚本和监控方案,其实早在 Pigsty v1.4 就做过,后来因为用户太少就去掉了。毕竟上 MPP 数仓的体量不是一般公司能达到的。所以我们思忖再三,先将其作为 Beta 模块按需提供 —— 包已经打好放在仓库里了,你可以直接下载使用;完整的部署剧本会在后续版本中择机提供。
Babelfish:SQL Server 兼容
说完三个新增内核,再来聊三个重建的内核。
Babelfish 是 AWS 开源的 SQL Server 兼容层 —— 让 PostgreSQL 理解 T-SQL 语法和 TDS 协议,你的 SQL Server 应用不改驱动、不改大部分查询,就能连上 PostgreSQL 跑起来。好项目,但打包构建实在是复杂,复杂到专门有一个开源项目 WiltonDB 就是干这件事的。
老冯之前偷懒,直接用了 WiltonDB 打的包。说实话,那个包的质量一直让我不太舒服:不支持 Debian 全系列和 EL10,依赖体系跟标准 PG 不一样,而且版本还停留在 PG15 —— 但 Babelfish 上游都已经支持 PG17 了。

这次一不做二不休,自己打。有了前面几个内核的打包经验,这个反而简单了 —— 把 Babelfish 的四个核心扩展打成一个包,配合一个 Patch 内核包,开箱即用。现在不再依赖外部 WiltonDB 仓库,直接从 Pigsty 仓库安装即可。版本升级到了 Babelfish 5.5 + PG17。
在 Pigsty 中使用:configure -c mssql。
OrioleDB:新存储引擎
OrioleDB 是被 Supabase 收购的新一代 PostgreSQL 存储引擎项目,目标是从根本上解决 MVCC 膨胀问题 —— 用 Undo Log 替代传统的 Dead Tuple + VACUUM 机制。
本次重建升级到了 OrioleDB Beta14,基于 OriolePG 17.16 构建。新版本的一个重要进展是支持了 PITR 增量备份恢复能力。仍处于 Beta 阶段,不建议关键生产环境使用。但作为 PostgreSQL 存储引擎的未来演进方向之一,值得持续关注和实验。
在 Pigsty 中使用:configure -c oriole。
OpenHalo:MySQL 协议兼容
OpenHalo 是重建的第三个内核。它提供了 MySQL 线缆协议兼容 —— 你可以同时用 MySQL 客户端和 PG 客户端读写同一个数据库,这个能力非常有意思。
由易景羲和团队开发,是少数几家踏踏实实做事、并且愿意把成果开源出来的国产数据库公司,很难得。这次更新的变化:
- 版本从 PG 14.10 升级到 PG 14.18
- 版本号正式更新为 1.0,按照 Pigsty 打包规范重新调整了命名
虽然基线版本是 PG14,稍显陈旧,但在 MySQL 迁移场景下确实是一个值得考虑的选择。
在 Pigsty 中使用:configure -c mysql。
其余六位常驻选手
除了本次新增和重建的六款内核,Pigsty 还有六位一直在的“常驻选手”:
IvorySQL(pg_mode: ivory)—— 瀚高出品的 Oracle PL/SQL 兼容内核,目前基于 PG 18.1。
Percona TDE(pg_mode: tde)—— 透明数据加密,满足合规场景中“落盘加密”的刚需。更新节奏稍慢于 PG 主线,后续会跟进到最新版本。
PolarDB(pg_mode: polar)—— 阿里开源的共享存储架构 PG 内核,更新了小版本。
Citus(pg_mode: citus)—— 微软出品的分布式扩展,正式发布 14.0.0 版本,支持 PG 18。
Ferret / DocumentDB(pg_mode: mongo)—— MongoDB 协议兼容方案,让你用 MongoDB 驱动直连 PostgreSQL。
Supabase 自建模板也例行升级到了最新版本。
一份配置,十核齐飞
说了这么多内核,最好玩的事情其实是这个:
我们做了一个 demo/kernel.yml 配置文件,可以用这个模板一键拉起 10 个不同的 PG 内核。
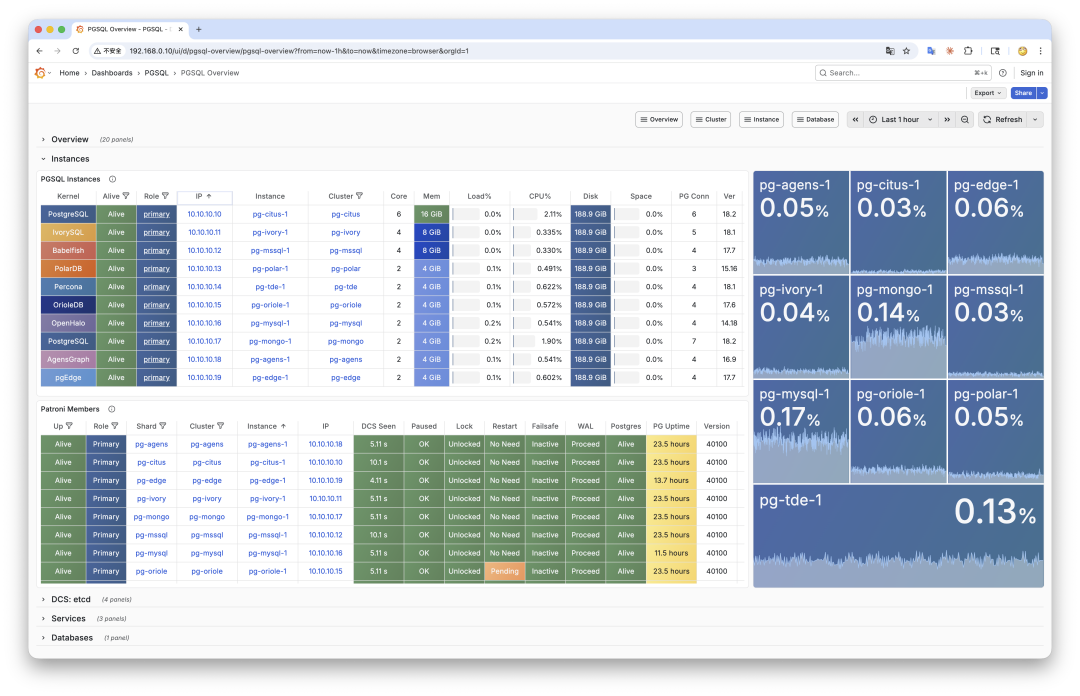
每个集群都有独立的监控面板、高可用、备份恢复,就像管理 10 个标准 PostgreSQL 一样。纯属炫耀—— 看,俺能一键同时拉起这么多风味的内核。
不过这也是一个很好的参考模板:如果你想在一套 Pigsty 部署里混合使用多种内核,具体该怎么配置,看这个就对了。
企业级 PG 发行版
眼尖的朋友可能已经发现,网站首页的 Slogan 换了。
以前叫 “Battery-Included, Local-First FLOSS RDS”,现在改成了:“开箱即用的企业级开源 PostgreSQL 发行版,自带高可用、PITR、IaC 监控与 461 个扩展”。
老冯之前一直不喜欢 “企业级” 这三个字,感觉似乎是比 “云” 还要狠的 “杀猪盘” —— 但奈何很多客户就吃这一套。实际上老冯在《PostgreSQL 高可用到底怎么搞?》里面也提到了,有些标着企业级高可用的方案其实底下就是 “patroni”,企业级备份底下就是个 pgbackrest,甚至参数都没优化过。既然如此,实力到位,该戴的帽子就应该理直气壮的戴上。
另一个变化是去掉了“RDS 替代”的说法。以前叫自己“开源 RDS 替代”,是一种借力定位——用人们熟悉的品类锚点(云数据库)来解释 “Pigsty 是什么”。但到了今天,老冯有信心说:不需要用别人的东西来定义自己。Pigsty 就是 Pigsty,它应该自己开创自己的品类,而不是借用别人的定义。
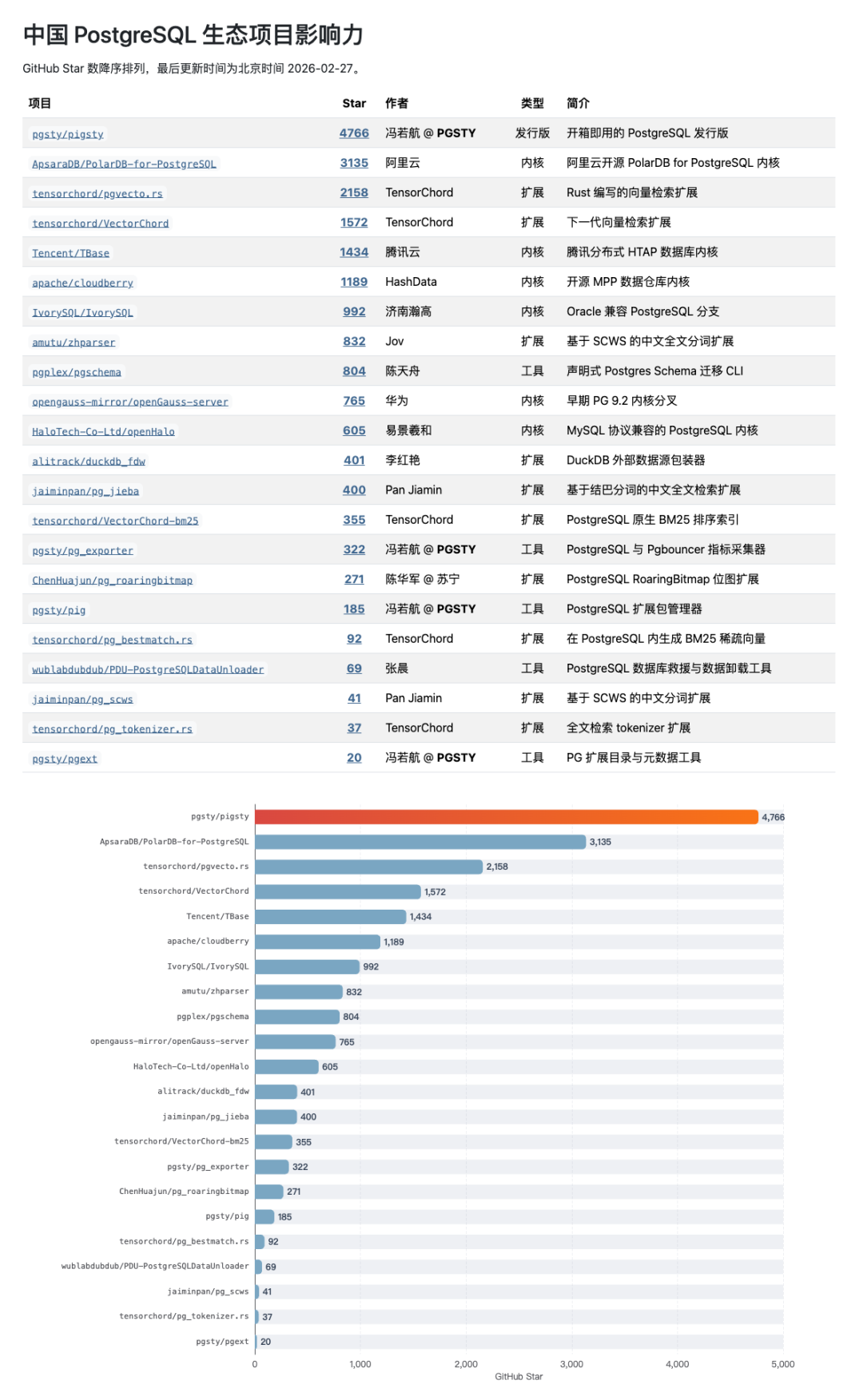
从 GitHub Star 上看,Pigsty 已经是 Linux 原生赛道的 No.1,增长速度也开始重新与 EDB 老大哥的 K8S 云原生赛道 CloudNativePG 看齐。
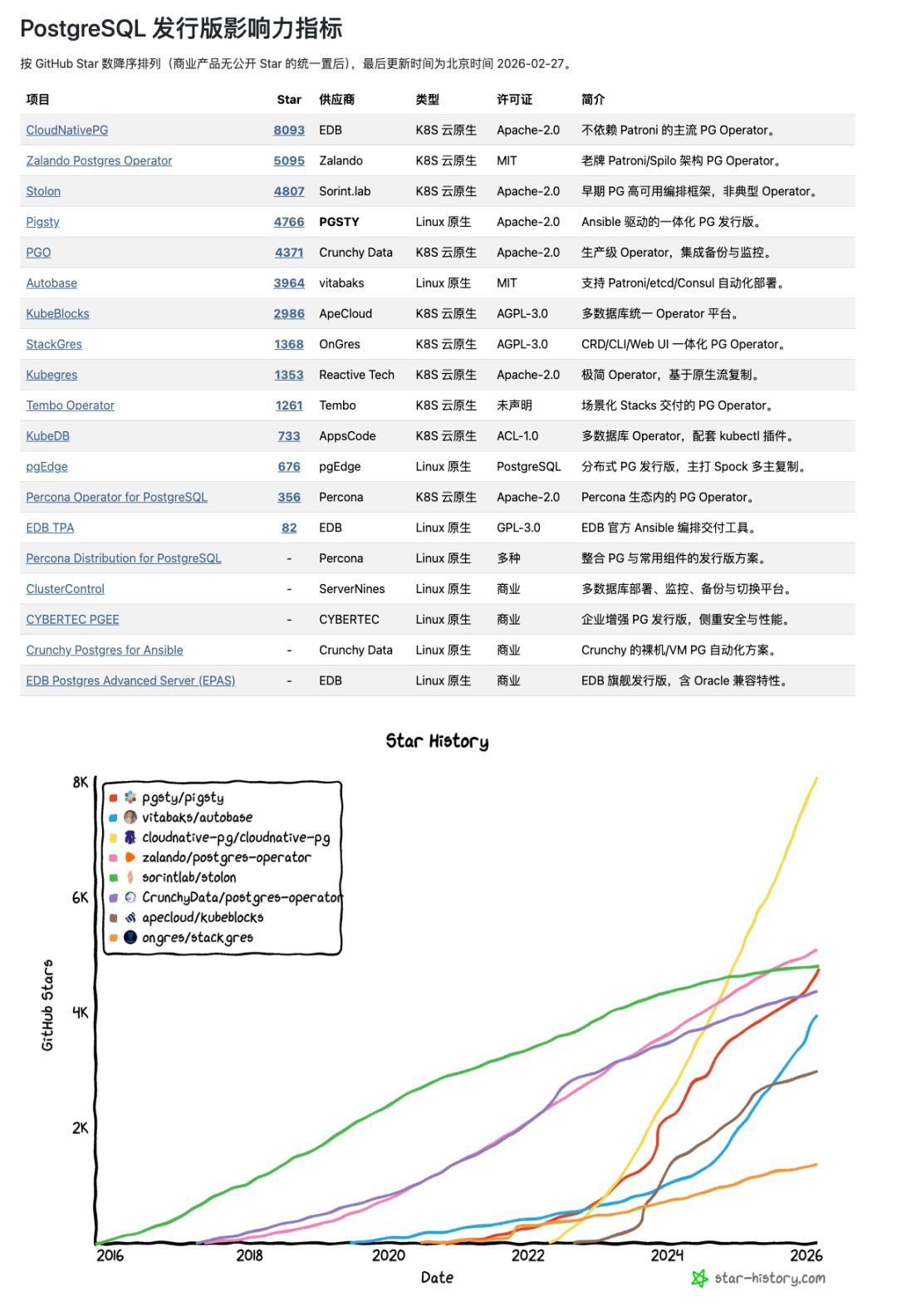
顺便一提,Pigsty 目前也算是中国开发者/厂商在 PostgreSQL 生态中最有影响力的开源项目了。
其他改进
除了内核大戏,v4.2 还有一些值得注意的工程改进:
Redis 目录规范化:默认目录从 /data 调整为 /data/redis。存量配置如果还用 /data,需要先改过来再升级,部署阶段会阻止旧路径继续使用。
Configure 脚本优化:支持 -o 绝对路径输出并自动建目录;区域探测改为三态(境内/境外/离线回退),修复了 behind_gfw() 卡住的问题。
pgBackRest 初始化容错:stanza-create 增加重试(2 次、间隔 5 秒),缓解与 archive-push 的锁竞争。踩过这个坑的人知道它有多烦。
Supabase 应用栈升级:PostgREST 14.5、Vector 0.53.0,S3 访问密钥变量补齐。
Vibe 模板更新:内置 @anthropic-ai/claude-code、@openai/codex、happy-coder 等工具,AI 编码沙箱开箱即用。
基础设施例行升级:Grafana 12.4、Prometheus 3.10、VictoriaMetrics 1.136、etcd 3.6.8、Kafka 4.2 等。注意 Grafana 12.4 有 data link 合并行为变化,自定义面板需检查。
首页改版:之前用 Claude Code 糊了一版,有人反映太丑了,批评得很有道理。这次让 Codex 重新优化了一轮,好看不少。后面有空会继续打磨。
后续展望
Pigsty 作为开源项目,我觉得已经达到了相当完善的程度。后续的工作重心会逐渐转向子项目:
Pig CLI 最近更新了很多强大功能 —— 把 PostgreSQL、Patroni、PgBouncer、pgBackRest 的管理全部封装成了命令行工具,方便 Claude Code 这样的 DBA Agent 调用。这种同时为人类 DBA 和 AI Agent 设计的命令行工具,我称之为 Agent-Native CLI。
DBA Agent 方面,最近写了一些 Claude Skills 和提示词模板,让 Pigsty 环境可以被 AI 工具感知。这样你就可以把 Claude Code 放进 Pigsty 环境里,让它帮你干活。
Pigsty 本身会继续跟着 PG 小版本的节奏走。下个版本可能会正式补上 Cloudberry 的部署剧本,加上本地 SMTP 服务器支持(maddy / stalwart)。大的新功能暂时不急 —— 当前这个架构持续稳定地跑下去,就挺好。

以上是关于 Pigsty v4.2 版本更新的全部内容。如果你对如何高效地管理和部署多样化的数据库内核感兴趣,欢迎在 云栈社区 的技术板块参与更多讨论。
 发表于 2026-3-2 02:56:37
|
查看: 149|
回复: 0
发表于 2026-3-2 02:56:37
|
查看: 149|
回复: 0
