从开发Demo到构建日活千万级的系统,对技术细节的要求是天壤之别。一个看似不起眼的疏忽,在生产环境中就可能引发严重的稳定性问题。许多开发者在项目初期可能会觉得抠细节是“偏执”,但事实是,随着用户规模的增长,这份“偏执”带来的回报是指数级的。今天,我们就来探讨六个在构建稳固的软件基础设施时,值得你反复推敲的关键点。
1. 健康检测不等于端口能连上
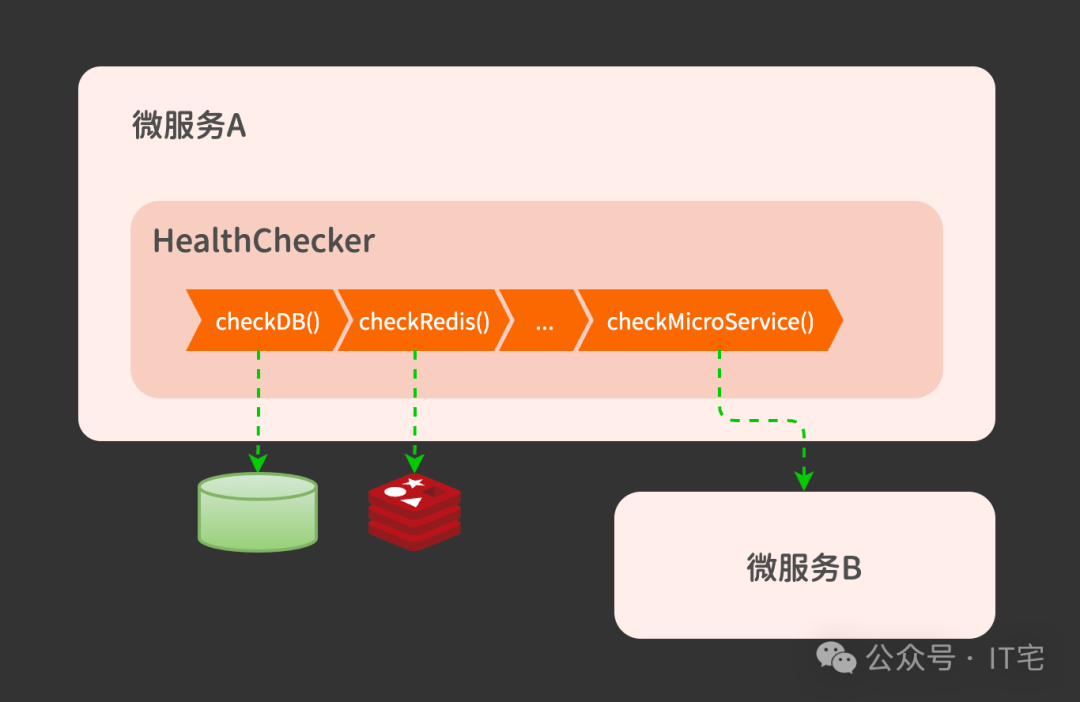
千万不要简单地认为 localhost:8080 能通就算服务健康。我就遇到过 Redis 实例早已挂掉,但 /health 接口却依然返回正常,导致故障未能及时报警的情况。表面平静,内部早已瘫痪。
一个健壮的健康检查思路其实很简单:别只探测端口,要主动去“摸一摸”关键的上下游依赖。比如,数据库能否执行一条轻量查询?缓存读写是否通畅?消息队列能否正常投递和消费?最好再为这些依赖检查设置一个整体的超时预算。以下是一个简化的线上实践示例(出于隐私考虑,代码已做简化):
@RestController
public class HealthController {
@Autowired
private DataSource orderDb; // 订单库
@Autowired
private StringRedisTemplate inventoryCache; // 库存缓存
@GetMapping("/health")
public ResponseEntity<String> healthCheck() {
if (!checkDb()) {
return ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE)
.body(“order-db down at “ + System.currentTimeMillis());
}
if (!checkRedis()) {
return ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE)
.body(“inventory-cache unreachable”);
}
return ResponseEntity.ok(“ok | ” + System.currentTimeMillis());
}
}
2. 请为日志添加上下文
在不少项目中,我们经常看到价值极低的日志,例如:
log.info(“Order processed”);
这条日志仅仅告诉我们“订单被处理了”,至于哪个订单、什么状态、在哪个业务节点触发,一概不知。这种日志除了占用磁盘空间,在排查问题时几乎毫无用处。
要让日志真正发挥作用,必须为其添加上下文信息:
log.info(“Order processed | orderId={} | userId={} | source={}”,
orderId, userId, sourceSystem);
这样,当你在日志平台搜索时,才能准确定位到具体的业务实体。更进一步,一个优秀的实践是:将那些贯穿始终的字段(如 traceId、userId、clientIp 等)放入日志上下文中,让日志框架自动将其附加到每一条日志记录里,这会让问题排查事半功倍。
你可以使用 SLF4J 的 MDC(Mapped Diagnostic Context)或 Log4j2 的 ThreadContext 来实现这一机制。

这里整理了一个使用 MDC 为日志添加上下文的示例,包含源码,感兴趣的开发者可以参考:为日志添加上下文.md
3. 别信系统时间,请使用单调时间
相信不少人都写过类似下面这样的代码来统计任务耗时:
long start = System.currentTimeMillis();
Thread.sleep(2000);
long elapsed = System.currentTimeMillis() - start;
System.out.println(“耗时: ” + elapsed + ” ms”);
问题在于,System.currentTimeMillis() 返回的数值会受到系统时间调整的影响。如果在这 2 秒内,运维人员将系统时间向前调了 5 秒,那么 elapsed 的计算结果就会变成负数,这样的耗时数据完全失去了意义。
针对时间间隔的测量,正确的做法是使用单调时间。单调时间的特点是只增不减,它不会因为 NTP 校时、手动修改系统时间或闰秒等原因发生回拨。它本质上是一个从系统启动开始计时的计数器,与真实的时间戳是两套不同的体系。
因此,应该改用以下方式:
long start = System.nanoTime();
doSomething();
long elapsed = System.nanoTime() - start;
System.out.println(“耗时(ms): ” + elapsed / 1_000_000);
如果你使用的是 Apache Commons Lang 中的 StopWatch 或 Spring 框架的 StopWatch,它们内部已经使用了单调时间,可以放心使用。
注意:单调时间不能当作时间戳使用,因为它没有固定的基准点,其数值在不同机器、不同 JVM 实例乃至每次重启后都会有不同的起始值。
4. 别靠肉眼盯仪表盘,一定要加上告警
永远不要指望有人能 24 小时盯着监控仪表盘。我曾有过切身经历:中午出去吃饭,回来后发现磁盘 iowait 已经飙升至 35%,服务开始变得不稳定。Grafana 的仪表盘再酷炫,如果你不去看它,就无法及时感知到业务已经出现问题。
一个有效且简单的策略是:先设置几条最关键的告警规则,再逐步细化。例如,可以这样配置(以 Prometheus + Grafana Alerting 为例):
- alert: MemoryLow
expr: node_memory_MemAvailable_bytes < 1073741824
for: 2m
labels:
severity: warning
annotations:
summary: “Memory available is low”
description: “Available memory on {{ $labels.instance }} is less than 1 GB (current value: {{ $value | humanize }}).”
根据我的经验,以下几个原则能让你事半功倍:
- 优先监控用户可感知的指标:接口 P99 延迟、错误率、消息队列积压量。磁盘快满了用户可能没感觉,但页面加载变慢他们会立刻找你。
- 告警分级:只有最核心的 3-5 条告警发送短信或电话通知;其他次要告警推送到办公 IM(如企业微信)中记录即可。否则,你很快就会对源源不断的告警短信感到麻木。
- 告警信息要能直接指导行动:在告警通知中附上定位链接和应急操作手册。否则半夜被叫醒,面对一条不知所云的告警信息只会徒增烦恼。
5. 代码能跑,绝不意味着可以交差了
就在我构思这一节内容时,客服群恰好抛来一个线上问题让我排查。花了半天时间,发现原因在于当初编码时漏掉了一些场景的考虑。代码在测试环境跑得挺好,可一到生产环境,各种“惊喜”就来了。相信很多开发者都有过类似的经历。
导致“测试通过,生产翻车”的原因多种多样,下面列举几个常见的:
- 环境不一致:生产与测试环境的数据库索引不同、中间件部署模式不同、数据量级差异导致慢查询被触发。
- 并发场景考虑不足:单用户操作一切正常,但在特定业务场景下,多个接口或任务并发执行时出现竞态条件或死锁。
- 外部依赖行为差异:测试环境调用的是稳定的 Mock 服务,生产环境对接的真实第三方接口可能存在超时、限流或返回不规范数据。
- 异步流程的连锁反应:依赖消息队列、缓存、定时任务时,未充分考虑消息积压、缓存击穿/雪崩、任务执行乱序带来的影响。
- 生产数据复杂性:生产环境中存在的脏数据或历史遗留数据,可能会触发测试环境从未覆盖到的逻辑分支。
- 边界条件缺失:分页参数传入极大值、上传超大文件、某些字段为空字符串等边界情况在测试阶段未被验证。
6. 为系统设计边界保护措施
产品经理可能会提出一些听起来很“美好”的需求,比如“这个商品列表最好能无限滚动展示”。然而,作为系统架构的设计者,你必须为系统设置明确的安全阈值。缺少这层保护,系统极其脆弱。我们就曾吃过亏:因为没有对单个货架的商品数量设限,被恶意用户利用,疯狂添加商品,最终一条失控的慢查询在某个周末引发了服务的 OOM(内存溢出)。
在系统中,你需要主动考虑并实施以下保护措施:
- 业务上限保护:为列表查询、批量导入/导出等操作设置硬性的数量上限。
- 接口限流:针对用户、租户或接口维度实施 QPS 限制,抵御突发流量或恶意攻击。
- 下游降级与熔断:当依赖的外部服务不可用时,快速失败或返回预设的兜底数据,避免线程池被拖垮。
- 资源隔离:对线程池、数据库连接池、缓存区域进行隔离,确保局部故障不会扩散成全局雪崩。
总结:在构建与运维中积累经验
构建一个高可用的系统,目标并非追求“永不犯错”,这几乎是不可能的。真正的目标,是让系统在出错时能够快速被发现、快速被定位、快速被恢复。本文探讨的这些要点,都是我们在保障系统稳定性的实践中,最容易踩坑也最值得投入的地方。缺少了这些机制,往往意味着我们需要投入数倍的时间进行故障排查。
谁也不希望美好的周末被报警电话打断,更不希望因为日志缺少关键信息而像个侦探一样猜上半天。每完善一个细节,系统就多一分稳健,你的睡眠也就多一分保障。如果你能从今天的内容中有所收获,避免掉一个潜在的坑,那么你已经比昨天的自己更进了一步。
技术之路漫长,持续学习和实践是最好的成长方式。也欢迎你到 云栈社区 与更多同行交流,分享你在系统架构与稳定性保障方面的经验和见解。
 发表于 2026-3-2 03:32:46
|
查看: 187|
回复: 0
发表于 2026-3-2 03:32:46
|
查看: 187|
回复: 0
