在移动应用与网站的业务场景中,我们经常需要处理这样的需求:一个键(Key)关联一个数据集合,并对该集合进行高效的统计或排序。这听起来简单,但当数据量达到百万、千万甚至亿级时,选择合适的数据结构与方法就至关重要。
常见的应用场景包括:
- 判断用户登录状态(给定userId)
- 统计两亿用户最近7天的签到情况,找出连续签到的用户
- 计算每日新增用户数与次日的留存率
- 统计网站的独立访客(Unique Visitor,UV)量
- 维护最新评论列表
- 根据播放量生成实时音乐榜单
面对如此巨大的用户量与访问量,我们必须选择能够高效处理海量数据的集合类型。要做出明智的选择,首先需要理解常见的统计模式。
一般来说,统计需求可以分为四种类型:
- 二值状态统计
- 聚合统计
- 排序统计
- 基数统计
本文将重点探讨后三种统计类型,并展示如何运用Redis的Set、Sorted Set等数据结构以及HyperLogLog、Bitmap等拓展类型来实现它们。
关于二值状态统计(巧用Bitmap),可参阅相关历史文章,本文不再赘述。
文章涉及到的Redis指令可以通过在线客户端运行调试,地址:https://try.redis.io/ ,方便随时验证。
基数统计
基数统计:统计一个集合中不重复元素的个数,典型应用就是计算独立用户数(UV)。
最直观的实现方式是使用集合(Set)结构。当一个新元素出现时,就将其加入集合;若已存在,则集合保持不变。然而,当页面访问量极大时,使用一个超大Set来统计会消耗大量内存。而且,UV统计通常并不要求100%精确。有没有更好的方案呢?
答案是肯定的,Redis提供的HyperLogLog数据结构就是为此类场景而生的。HyperLogLog采用概率算法进行基数估算,标准误差仅为0.81%,这个精度对于UV统计来说已经完全足够,同时它能极大地节省存储空间。
网站UV统计方案对比
方案一:使用Set实现
为每个页面维护一个Set,用户访问时,将其IDSADD到对应集合中。Set的自动去重特性确保了同一用户ID不会被重复记录。
统计UV时,使用SCARD命令获取集合元素总数即可。
SADD Redis为什么这么快:uv 89757
SCARD Redis为什么这么快:uv
方案二:使用Hash实现
将用户ID作为Hash的字段(field),访问时执行HSET将值设为1。即使用户重复访问,对应字段的值也始终是1。
最后,使用HLEN命令统计Hash中的字段数量,即为UV。
HSET redis集群:uv userId:89757 1
HLEN redis集群:uv
方案三:HyperLogLog(推荐)
无论是Set还是Hash,在数据量极大时都会占用可观的内存。HyperLogLog则是专门为基数统计设计的,它最大的优势是空间占用固定。每个HyperLogLog键最多只需约12KB内存,就能计算接近2^64个元素的基数!Redis在内部还会进行优化,在计数较小时采用更紧凑的存储方式。
基本操作:
进阶操作:PFMERGE
PFMERGE用于将多个HyperLogLog合并为一个,合并后的基数接近于所有输入集合的并集。这在需要合并多个页面或时间段的数据时非常有用。
例如,需要合并“Redis”和“MySQL”两个页面的独立访客数据:
PFADD Redis数据 user1 user2 user3
PFADD MySQL数据 user1 user2 user4
PFMERGE 数据库 Redis数据 MySQL数据
PFCOUNT 数据库 // 返回值 ≈ 4 (user1, user2, user3, user4)
注意,user1和user2同时访问了两个页面,但在合并后的统计中只计算一次。
排序统计
在Redis的集合类型中,List和Sorted Set是有序的。
- List:依据元素插入顺序排序。适用于消息队列、最新列表(如最新评论)。
- Sorted Set:依据每个元素关联的
score权重值排序。适用于各类排行榜(如播放量、点赞数榜单)。
最新评论列表的实现与陷阱
我们可以利用List的LPUSH(左插入)和LRANGE(范围查询)命令来实现一个最新评论列表。
LPUSH 码哥字节 1 2 3 4 5 6
LRANGE 码哥字节 0 4
然而,对于需要分页且频繁更新的列表,List类型可能导致元素重复或遗漏。假设当前列表为{A, B, C, D}(A最新,D最早)。
LPUSH 码哥字节 D C B A
获取第一页(最新两条):LRANGE 码哥字节 0 1,返回 A, B。
计划获取第二页:LRANGE 码哥字节 2 3,期望返回 C, D。
如果在获取第二页前,有新评论E插入:LPUSH 码哥字节 E,列表变为{E, A, B, C, D}。
此时再执行LRANGE 码哥字节 2 3,返回的将是 B, C,而不是预期的 C, D。因为所有旧元素的位置都后移了一位。
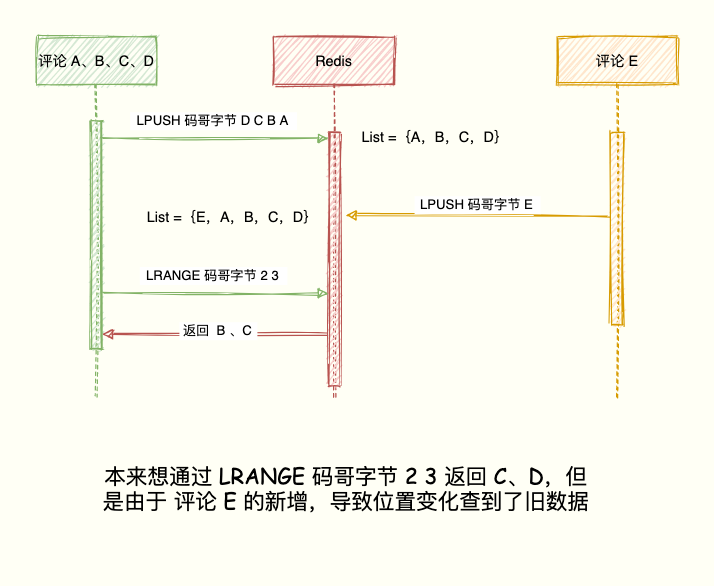
小结:List仅适用于无需分页(如每次只取前5条)或更新频率极低的列表场景。对于需要分页且频繁更新的最新列表,应使用Sorted Set。
音乐播放排行榜
对于像“一周音乐榜”这类需要根据动态分数(播放量)排序并支持分页的场景,List无法满足,Sorted Set是最佳选择。
可以将音乐ID作为成员(member),播放量作为分数(score)。每播放一次,使用ZINCRBY命令为其分数增加1。
基本操作:
ZADD:初始化或添加歌曲及其播放量。
ZADD musicTop 100000000 青花瓷 8999999 花田错
ZINCRBY:为指定歌曲的播放量+1。
ZINCRBY musicTop 1 青花瓷
- 获取榜单:要获取前十名,需要先知道最高分N。可以用
ZREVRANGE获取第一名信息。
ZREVRANGE musicTop 0 0 WITHSCORES
假设最高分N为100000001,则前十名范围为[N-9, N]。
ZRANGEBYSCORE musicTop 99999992 100000001 WITHSCORES
小结:Sorted Set能精准处理元素分数频繁更新的排序需求,无论是最新列表还是排行榜,在需要分页或动态排序时都应优先考虑它。更多关于算法与数据结构的应用可以深入探索。
聚合统计
聚合统计指的是对多个集合进行交、并、差等计算,例如:
- 交集:统计多个集合的共有元素(如共同好友)。
- 差集:统计属于一个集合但不属于另一个集合的元素(如每日新增用户)。
- 并集:统计多个集合的所有元素(如总新增用户)。
Redis的Set类型不仅支持单集合的增删改查(O(1)时间复杂度),还原生支持多个集合间的交集(SINTER/SINTERSTORE)、并集(SUNION/SUNIONSTORE)、差集(SDIFF/SDIFFSTORE)操作。
交集应用:QQ共同好友
将用户账号作为Key,其好友ID列表作为Set的value。
SADD user:码哥字节 R大 Linux大神 PHP之父
SADD user:大佬 Linux大神 Python大神 C++菜鸡
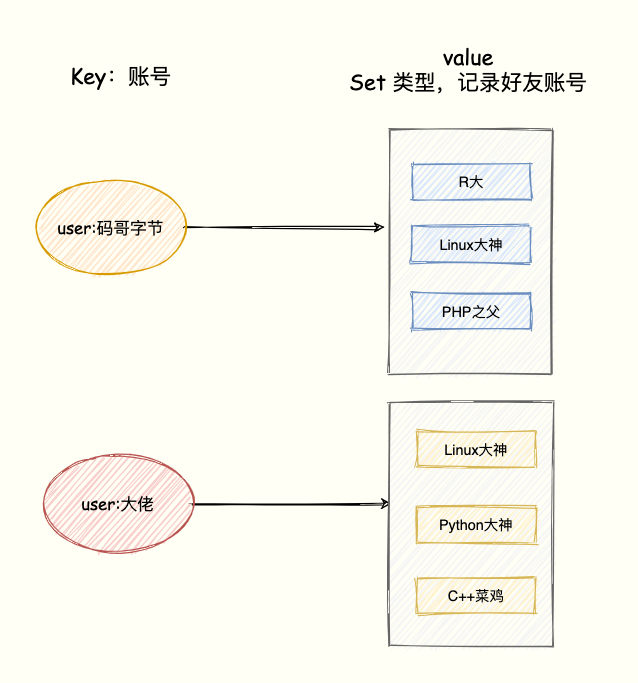
计算共同好友并存储结果:
SINTERSTORE user:共同好友 user:码哥字节 user:大佬
执行后,user:共同好友这个集合中即保存了两个用户的共同好友(本例中为“Linux大神”)。
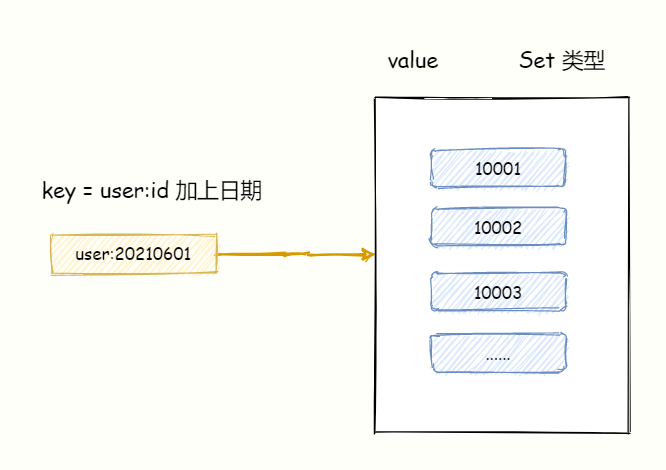
差集应用:每日新增用户数
统计App的每日新增注册用户,只需计算当日总用户集与昨日总用户集的差集。
SDIFFSTORE user:new user:20210602 user:20210601
执行后,user:new集合中就是2021年6月2日的新增用户。
“可能认识的人”功能也可用差集实现:用“朋友的好友集”减去“我们的共同好友集”。
并集应用:总共新增好友
如果需要统计两天的总共新增用户(去重),则应对两个集合取并集。
SUNIONSTORE userid:new user:20210602 user:20210601
此时userid:new集合包含了这两日内所有新增的唯一用户。
重要注意事项
Set的交、并、差计算复杂度较高。当参与计算的集合数据量极大时,直接执行这些命令可能导致Redis实例阻塞,影响其他服务。
建议:
- 为聚合统计任务单独部署一个Redis从实例或集群,专门负责这类重计算。
- 或者,将待计算的数据从Redis读取到业务应用(客户端),在应用内存中完成聚合计算,再将结果写回Redis。
选择哪种方案,需要根据实际的数据规模、实时性要求以及系统架构资源来权衡。云栈社区的很多开发者都分享过他们在处理海量数据统计时的架构设计经验,值得参考。
 发表于 2026-3-3 13:01:50
|
查看: 148|
回复: 0
发表于 2026-3-3 13:01:50
|
查看: 148|
回复: 0
