广度成就多维视角,深度利于快速定位。
— 微微一笑
引言
在分布式系统设计中,确保数据一致性是一个核心挑战。上一篇文章《Redis分布式锁使用及问题解决》从具体场景切入,介绍了Redis分布式锁的基础使用。本文将更进一步,系统地探讨几种常用的分布式锁解决方案,深入原理并对比其应用场景,以拓宽技术视野。
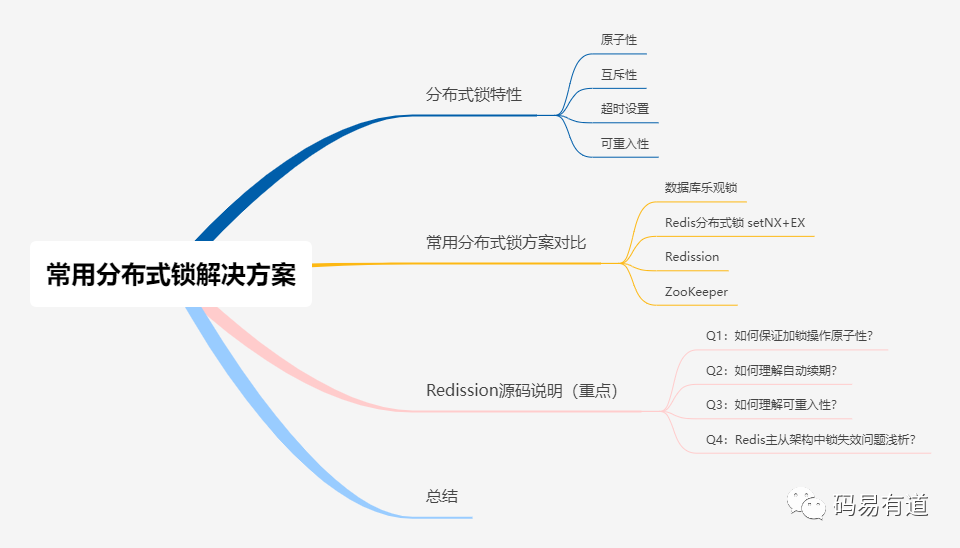
分布式锁特性
一个可靠的分布式锁,需要具备哪些核心特性?
- 原子性(Atomicity): 锁的获取和释放操作必须是原子的,确保在任何时刻只有一个客户端能够成功加锁,从而避免竞态条件。
- 互斥性(Mutual Exclusion): 这是锁最基本的要求,必须保证在同一时间,最多只有一个客户端能持有锁。
- 超时机制(Timeout): 锁应支持自动超时释放,防止持有锁的客户端因宕机或网络问题导致锁无法释放,进而引发系统死锁。
- 可重入性(Reentrancy): 允许同一个线程多次获取同一把锁。这在递归调用或需要重复进入同步代码块的场景中非常有用。
- 可靠性(Reliability): 锁服务本身需要具备高可用性,能够应对网络分区、节点故障等各种异常情况。
常见分布式锁解决方案
面对分布式环境下的并发数据一致性问题,有多种成熟的锁方案可供选择。下面我们将逐一剖析,并通过对比帮助你建立清晰的认知。
分布式锁方案一:数据库乐观锁(CAS思想)
在深入了解乐观锁之前,我们先快速回顾一下悲观锁与乐观锁的核心区别。
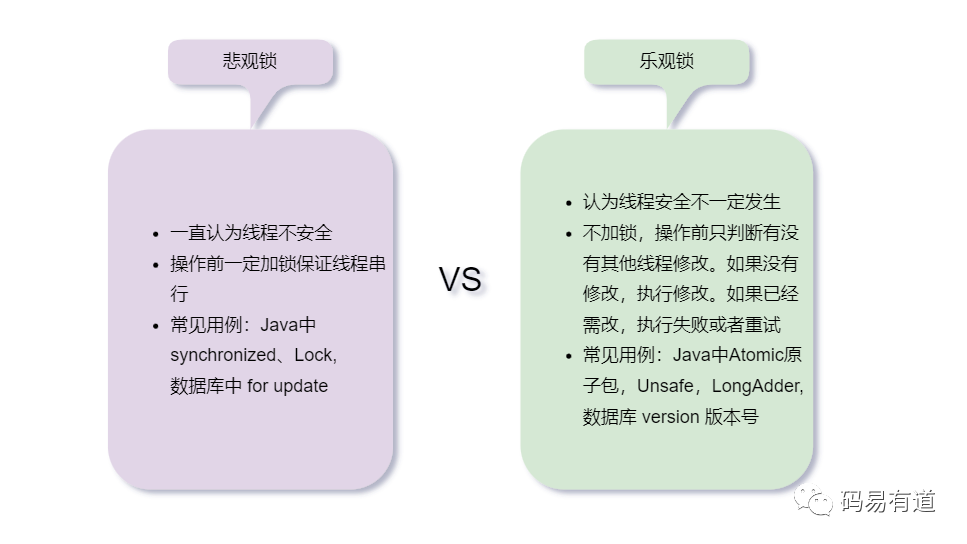
在分布式系统中,悲观锁(如 SELECT ... FOR UPDATE)容易造成严重的性能瓶颈。因此,我们重点讨论基于CAS(Compare-And-Swap)思想的乐观锁实现。以一个商品库存表为例:
mysql> select * from product_stock;
+----+------------+-------+---------+
| id | product_id | stock | version |
+----+------------+-------+---------+
| 1 | 1 | 100 | 1 |
+----+------------+-------+---------+
1 row in set (0.00 sec)
在多线程(或多进程)环境下,利用 version 版本号机制执行扣减库存操作,其核心流程如下:
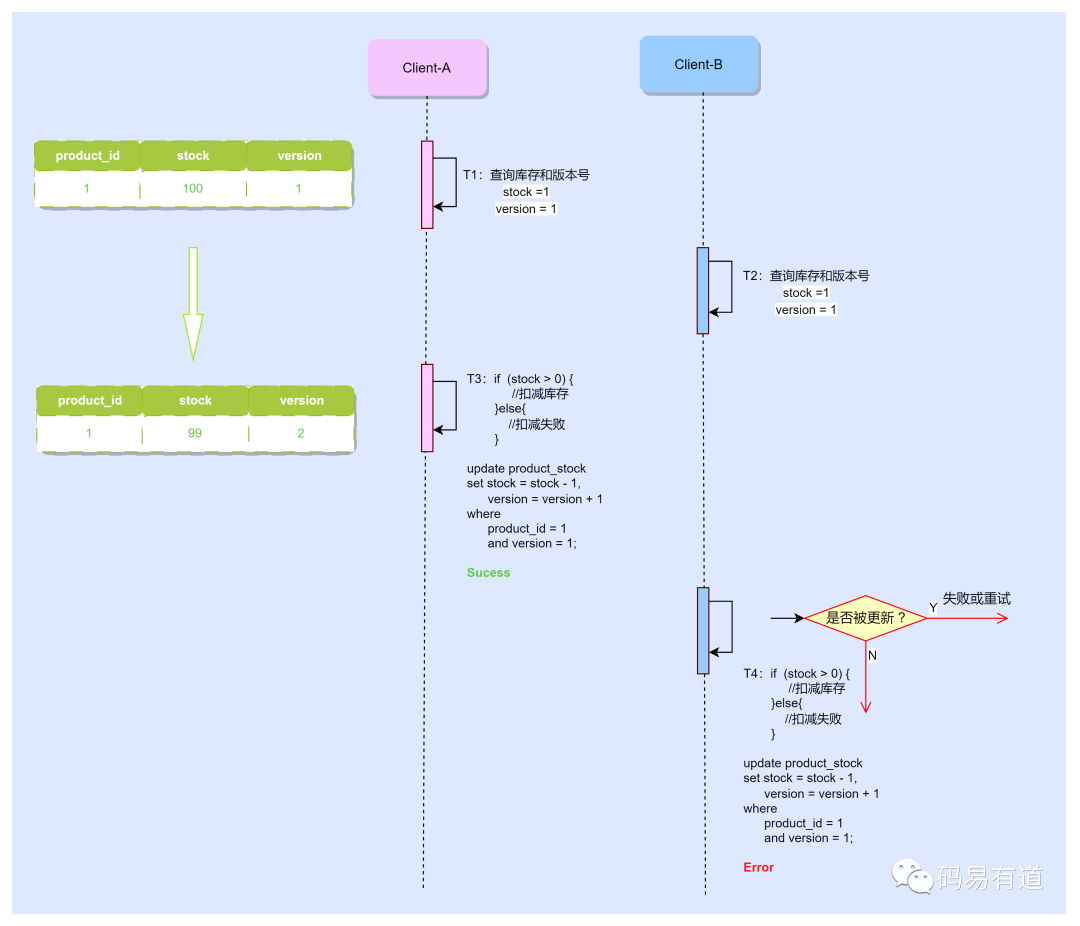
流程描述:
-- 查询当前版本号:1
SELECT version FROM product_stock WHERE product_id = 1;
-- 执行操作,更新版本号
UPDATE product_stock SET stock = stock - 1, version = version + 1 WHERE product_id = 1 AND version = <当前查询到的版本号>;
-- 提交事务
COMMIT;
* **事务B执行**
```sql
START TRANSACTION;
-- 查询当前版本号:1
SELECT version FROM product_stock WHERE product_id = 1;
-- 执行操作,更新版本号,此处A执行完version=2,更新失败
UPDATE product_stock SET stock = stock - 1, version = version + 1 WHERE product_id = 1 AND version = <当前查询到的版本号>;
-- 提交事务
COMMIT;
由此可见,乐观锁能有效解决并发安全问题。它适用于读多写少、对短事务容忍性较好的场景,能够显著提升系统的并发能力。然而,在高并发写入场景下,会导致大量的 UPDATE 失败和重试,需要业务层做好处理。
分布式锁方案二:RedisTemplate: setNX + expire
关于使用 setNX 和 expire 命令实现Redis分布式锁的细节及常见问题(如原子性、锁续期等),在上一篇文章中已有详细介绍。当时我们留下了一个思考:锁的过期时间如何科学设置?接下来,我们将通过分析 Redission 框架的原理来回答这个问题。
分布式锁方案三:Redission框架
我们继续使用扣减库存的案例,但这次升级为使用Redission框架。首先搭建一个简易的单机环境。
详细步骤:
-
添加 Maven 依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.17.5</version> <!-- 最新版本请参考官方文档 -->
</dependency>
-
配置RedissonClient:
@Configuration
public class RedisConfig {
@Value("${config.redis.host}")
private String host;
@Value("${config.redis.port}")
private String port;
@Value("${config.redis.password}")
private String password;
@Bean
public RedissonClient redisson() {
// 此为单机模式
Config config = new Config();
config.useSingleServer()
.setAddress("redis://"+host+":"+port)
.setPassword(password)
.setDatabase(1);
return Redisson.create(config);
}
}
-
业务逻辑实现:
@RequestMapping("/redissonLock/reduceStock")
public String reduceStock() {
String lockKey = "product_01";
RLock lock = redisson.getLock(lockKey);
String msg = "";
try {
//加锁
lock.lock();
int stock = Integer.parseInt(redisTemplate.opsForValue().get("stock"));
if (stock > 0) {
int realStock = stock - 1;
redisTemplate.opsForValue().set("stock", realStock + "");
msg = "减库存成功,剩余:" + realStock;
System.out.println(msg);
} else {
msg = "减库存失败,库存不足";
System.out.println(msg);
}
} finally {
//释放锁
lock.unlock();
}
return msg;
}
-
测试结果
Pod:8080
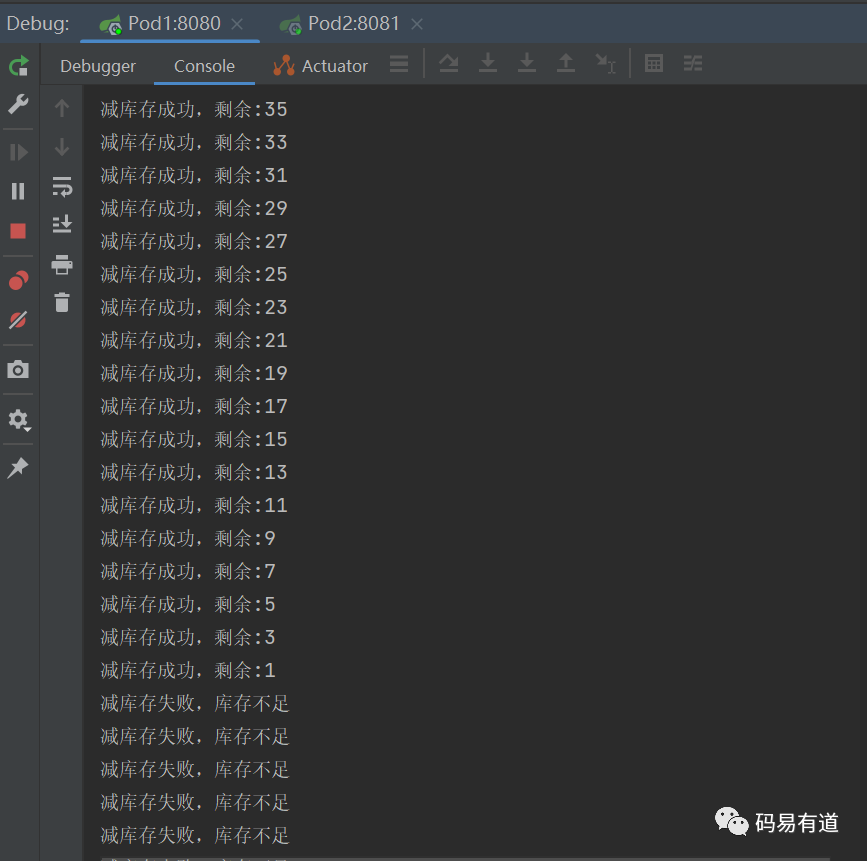
Pod:8081
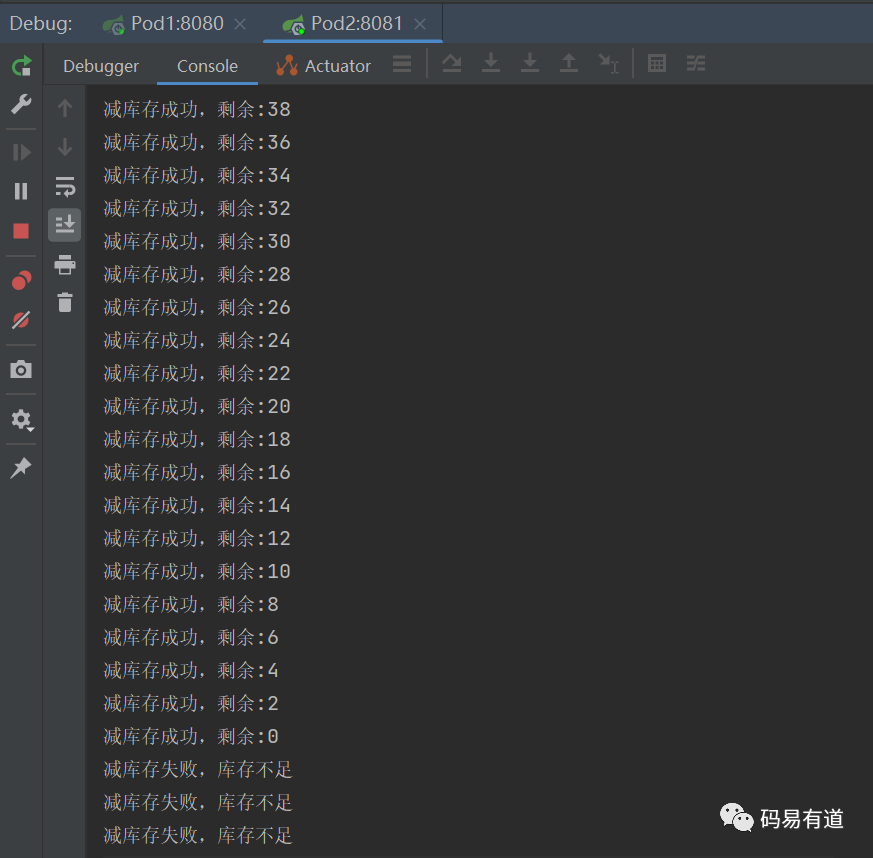
- 结果分析
测试结果表明,Redission框架确实有效解决了分布式并发导致的数据不一致问题。我们将核心使用逻辑提炼如下:
// 创建分布式锁
RLock lock = redisson.getLock("myLock");
try {
// 尝试获取锁
lock.lock();
// 业务逻辑
System.out.println("Business logic inside the lock.");
} finally {
// 释放锁
lock.unlock();
}
使用起来非常简单。但正如那句老话:哪有什么岁月静好,不过是有人替你负重前行。如此简洁的API背后,隐藏着怎样的复杂机制呢?
我们先通过一个简化的流程图来理解其整体工作流程,再深入源码探究原理。
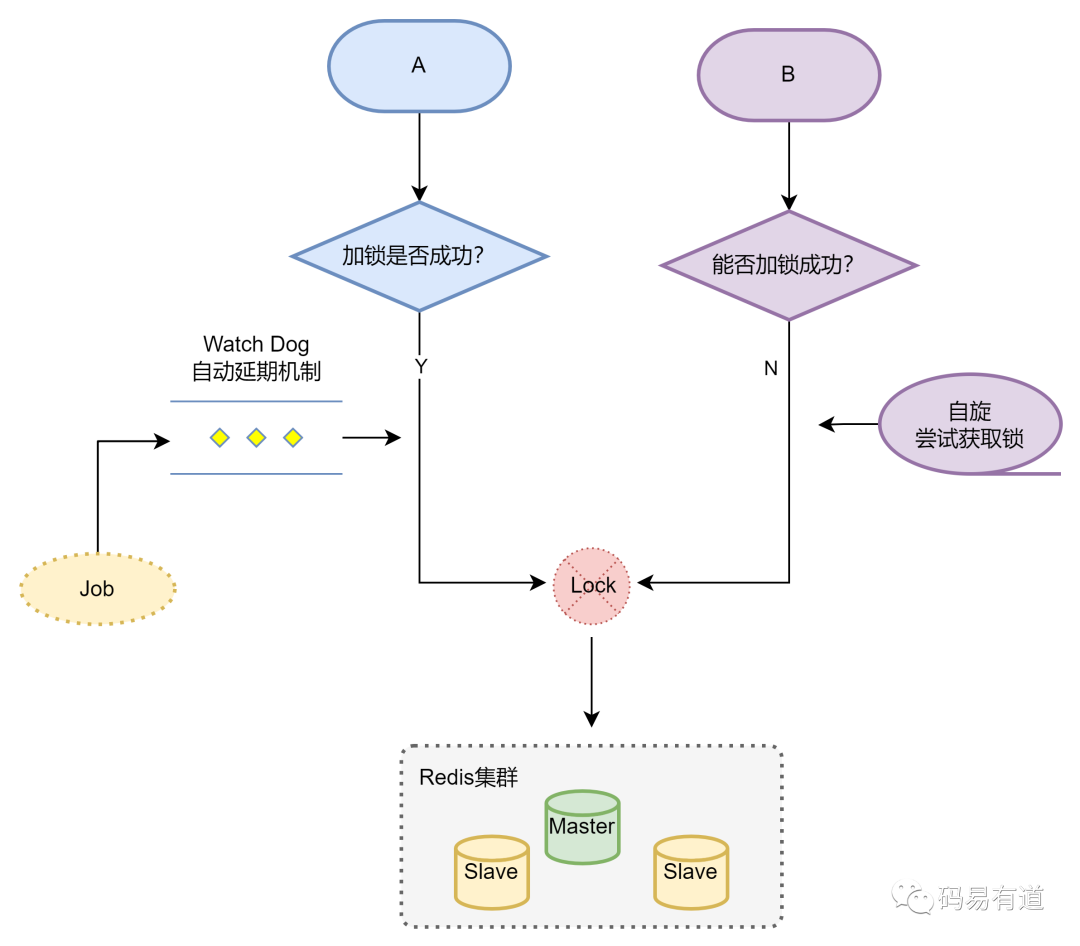
流程描述:
-
客户端A
- 成功获取锁。
- 判断是否指定了锁的租约时间。如果未指定,则使用框架内部默认的持续时间(默认30秒)。
- fork一个后台线程(看门狗),定时执行锁续期任务(默认每10秒一次)。
- 业务逻辑执行完毕,释放锁。
-
客户端B
- 尝试获取锁失败(因为锁被A持有)。
- 进入一个while循环,以自旋方式不断重试获取锁。
- 等待客户端A释放锁。一旦锁被释放,客户端B成功获取;否则继续步骤2。
下面,我们通过剖析核心源码来详细理解上述流程,并思考几个关键问题。
这段代码是Redisson尝试获取分布式锁的核心逻辑:
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
RFuture<Long> ttlRemainingFuture;
//如果指定了加锁时间,加锁使用指定时间
if (leaseTime != -1) {
ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
// 如果未指定锁的持续时间,则使用内部默认的持续时间
ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
}
// 异步回调,处理锁获取结果
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
//省略部分代码...
// 锁获取成功
if (ttlRemaining == null) {
if (leaseTime != -1) {
// 更新内部锁持续时间
internalLockLeaseTime = unit.toMillis(leaseTime);
} else {
// 启动定时任务,定期续约锁的过期时间
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
1)加锁逻辑详解 (tryLockInnerAsync)
真正的加锁操作封装在Lua脚本中,通过 evalWriteAsync 方法原子性地执行。
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,
// 使用 Lua 脚本执行原子性操作获取锁
"if (redis.call('exists', KEYS[1]) == 0) then " + // 如果锁不存在
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " + // 将线程ID作为哈希字段,并递增其值
"redis.call('pexpire', KEYS[1], ARGV[1]); " + // 设置锁的过期时间
"return nil; " + // 返回 nil 表示锁获取成功
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " + // 如果线程ID已存在
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " + // 递增线程ID的值
"redis.call('pexpire', KEYS[1], ARGV[1]); " + // 设置锁的过期时间
"return nil; " + // 返回 nil 表示锁获取成功
"end; " +
"return redis.call('pttl', KEYS[1]);", // 返回锁的剩余过期时间
Collections.singletonList(getRawName()), unit.toMillis(leaseTime), getLockName(threadId));
}
参数说明:
在这段Lua脚本中:
KEYS[1]: 对应 Collections.singletonList(getRawName()),即Redis中锁的Key。ARGV[1]: 对应 unit.toMillis(leaseTime),即锁的租约时间(毫秒)。ARGV[2]: 对应 getLockName(threadId),即获取锁的线程唯一标识(格式通常为 UUID:threadId)。
2)锁续期机制:scheduleExpirationRenewal(threadId)
该方法最终会调用 renewExpiration()。以下是简化后的续期逻辑:
//开启一个定时任务执行续期逻辑
private void renewExpiration() {
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//省略部分代码...
// 异步执行续约操作
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
//省略部分代码...
if (res) {
// 如果续约成功,重新调自身执行续约操作
renewExpiration();
} else {
cancelExpirationRenewal(null);
}
});
}
// 注意:这里定时任务以 lockWatchdogTimeout 的1/3(即10秒)为周期执行
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
3)几个关键细节
- 线程标识:
getLockName(threadId) 生成的标识符格式为 UUID:threadId,确保了不同JVM、不同线程的唯一性。
- 看门狗时间:默认
lockWatchdogTimeout = 30 * 1000;(30秒)。续期定时任务以 internalLockLeaseTime / 3 = 10秒 的间隔执行。
- 异步思想:通过
Future 进行异步回调。主线程专注于执行业务逻辑,而后台线程(看门狗)负责锁的续期,减少了主线程的阻塞。
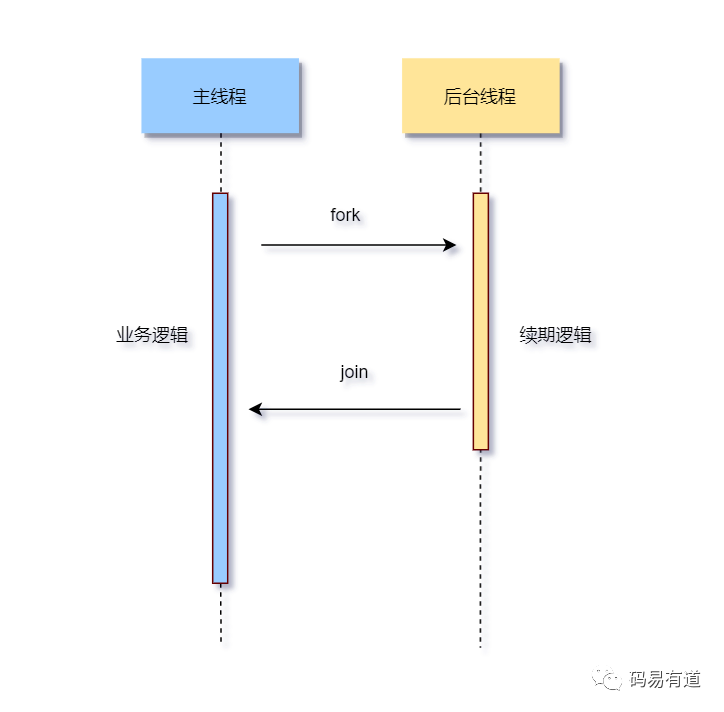
基于以上流程和源码分析,我们可以清晰地回答几个核心问题。
Q1:如何保证加锁操作的原子性?
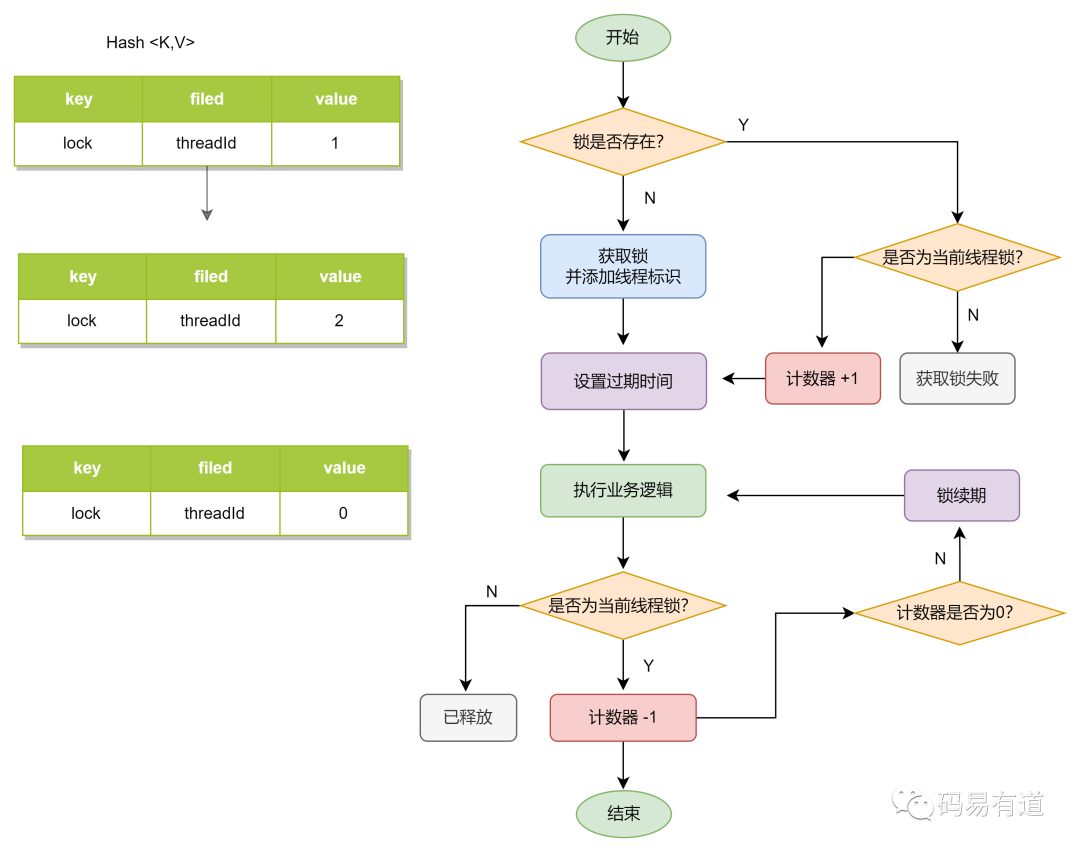
Redisson通过执行Lua脚本来保证原子性。Lua脚本在Redis服务器端会被当作一个整体命令执行,中间不会被其他命令插入。上面的 tryLockInnerAsync 方法中的脚本,将“判断锁是否存在/是否为本线程持有”、“设置哈希值(实现可重入计数)”、“设置过期时间”这三个步骤原子性地完成。
Q2:如何理解自动续期(看门狗机制)?
当获取锁时未显式指定 leaseTime(租约时间),Redisson会启动一个看门狗(WatchDog)线程。这个线程在锁被持有期间,会定期(默认每10秒)检查业务是否还在执行(即锁是否仍被持有)。如果是,则通过执行Lua脚本将锁的过期时间重新设置为30秒(默认值)。这样就实现了锁的“自动续期”,避免了业务执行时间过长导致锁意外过期的问题。
Q3:如何理解可重入性?
可重入锁允许同一个线程多次获取同一把锁。在Java中,synchronized 关键字和 ReentrantLock 都支持可重入。
一个简单的 synchronized 可重入示例:
public class ReentrantLockDemo {
public static void main(String[] args) {
// 创建一个示例对象
ReentrantObject reentrantObject = new ReentrantObject();
// 启动一个线程
new Thread(() -> {
try {
reentrantObject.performTask();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
class ReentrantObject {
// 定义一个可重入锁
private final Object lock = new Object();
public void performTask() throws InterruptedException {
// 第一次获取锁
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + " 第一次获取锁");
// 在持有锁的情况下再次获取锁
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + " 第二次获取锁");
// 执行任务,模拟工作
Thread.sleep(1000);
}
}
// 释放第一次获取的锁
System.out.println(Thread.currentThread().getName() + " 第一次释放锁");
}
}
运行结果:
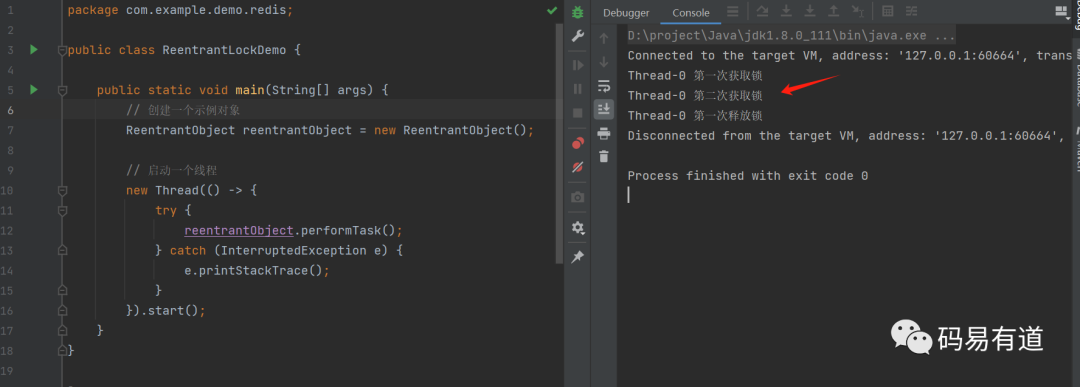
其原理是维护一个持有计数器(Hold Count)。线程首次获取锁时,计数器为1;每次重入,计数器加1;释放锁时,计数器减1。只有当计数器归零时,锁才被真正释放。
在Redisson的分布式锁中,可重入性是通过Redis的Hash结构实现的。Hash的key是锁名称,field是线程唯一标识(UUID:threadId),value就是该线程的重入次数。前面Lua脚本中的 redis.call('hincrby', KEYS[1], ARGV[2], 1) 正是完成计数器的递增操作。
Q4:Redis主从架构中锁失效问题浅析?
这是Redis分布式锁一个著名的缺陷。考虑以下场景:
- 客户端A在Master节点成功获取锁。
- 在锁信息同步到Slave节点之前,Master节点宕机。
- 某个Slave节点被选举为新的Master。
- 此时,新的Master节点上没有客户端A的锁数据。
- 客户端B向新的Master节点申请同一把锁,成功获取。这就违反了分布式锁的互斥性原则。
为了解决这种因主从切换导致的数据不一致问题,业界提出了RedLock算法,或直接选用 ZooKeeper 这类保证强一致性的协调服务来实现分布式锁。
分布式锁方案四:ZooKeeper + Curator实现
注:Curator是ZooKeeper的高级客户端库,类似于Redisson之于Redis的关系。
ZooKeeper实现分布式锁,主要利用其临时顺序节点(Ephemeral Sequential Node) 的特性。其核心原理如下图所示:
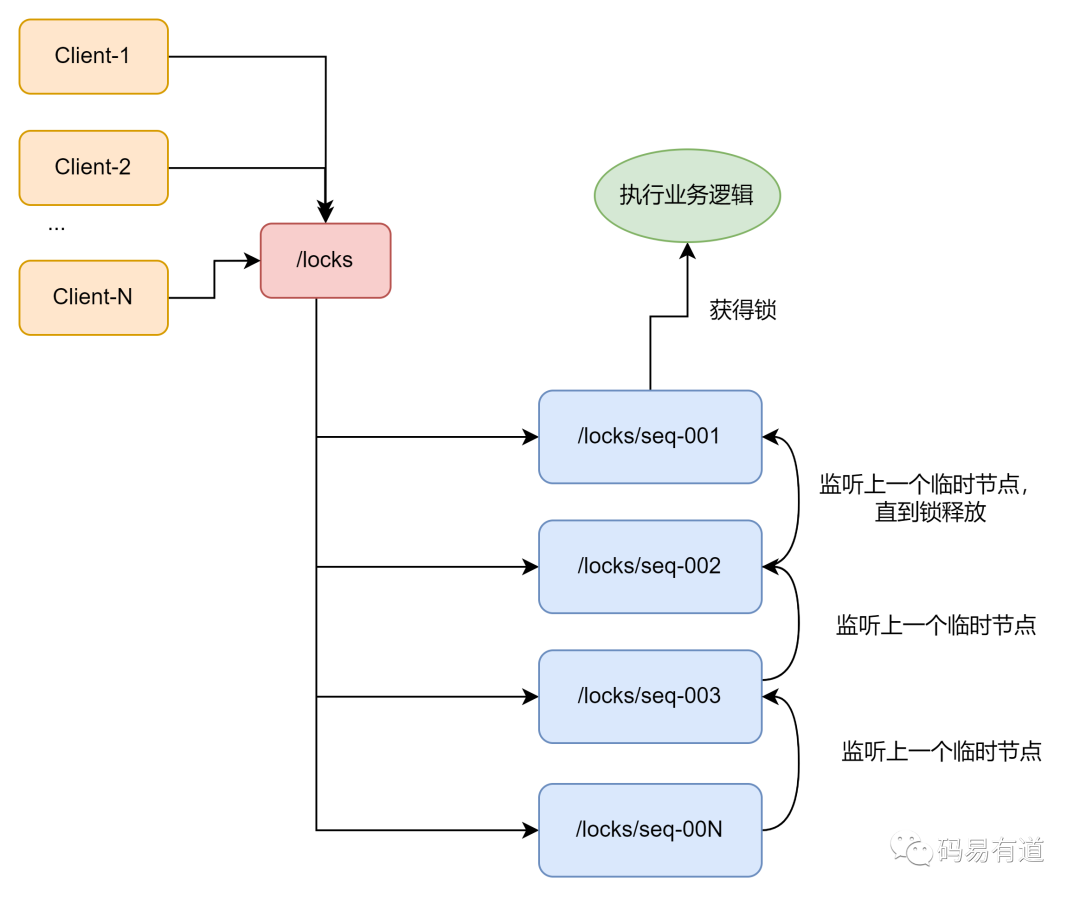
详细描述:
- 所有客户端都在预先定义的锁节点下(例如
/locks/my_lock)创建临时顺序节点。
- 客户端获取
/locks/my_lock 下所有子节点,并判断自己创建的节点是否为序号最小的一个。
- 如果是,则视为获取到锁。
- 如果不是,则监听(Watch)自己前一个序号节点的删除事件。
- 持有锁的客户端完成业务后,删除自己创建的临时节点。
- 后一个序号的客户端监听到前序节点被删除的事件,被唤醒,并重复步骤2的判断。
使用ZooKeeper和Curator实现分布式锁的基本步骤:
-
引入Curator依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.1.0</version> <!-- 请检查最新版本 -->
</dependency>
-
创建Curator客户端
CuratorFramework client = CuratorFrameworkFactory.newClient("your_zookeeper_connection_string", new ExponentialBackoffRetry(1000, 3));
client.start();
-
使用分布式锁
Curator提供了 InterProcessMutex 类,它封装了上述复杂的监听和排队逻辑。
InterProcessMutex lock = new InterProcessMutex(client, "/locks/my_resource");
try {
// 获取锁
lock.acquire();
// 执行受保护的业务逻辑
// ...
} catch (Exception e) {
// 处理异常
} finally {
// 释放锁
lock.release();
}
4. **处理锁超时**
```java
// 尝试获取锁,最多等待5秒
if (lock.acquire(5, TimeUnit.SECONDS)) {
try {
// 执行业务逻辑
} finally {
// 释放锁
lock.release();
}
} else {
// 获取锁超时的处理逻辑
}
- 关闭客户端
client.close();
总结与选型建议
综合对比以上几种分布式锁方案,我们可以得出如下选型参考:
-
数据库乐观锁
- 优点:实现简单,无需引入额外中间件;支持跨进程/分布式环境。
- 缺点:并发量高时,大量更新失败会带来重试开销,对数据库压力大;需要小心处理行锁和死锁问题。适用于并发冲突不高、业务逻辑简单的场景。
-
Redis (setNX+EXPIRE)
- 优点:基于内存,性能极高;实现相对简单。
- 缺点:在单节点或主从架构下存在锁失效风险(如上述主从切换问题);需要自行处理锁续期、原子性等问题。
-
Redisson
- 优点:作为Redis的客户端,封装完善,提供了可重入锁、公平锁、联锁、红锁等多种锁类型;内置看门狗机制,解决了锁续期难题;社区活跃,文档丰富。
- 缺点:依然无法彻底解决Redis主从架构下的数据一致性问题(红锁RedLock算法存在争议且复杂)。这是目前大多数对一致性要求不是极端严苛的互联网项目的首选方案。
-
ZooKeeper
- 优点:基于ZAB协议,提供强一致性保证,锁模型天然可靠,无Redis的主从失效问题;通过临时节点和Watch机制,能有效避免死锁。
- 缺点:性能相比Redis有数量级差距;部署和维护ZK集群的复杂度较高。适用于对锁的强一致性有极高要求,且并发压力不是首要矛盾的场景,如配置管理、领导选举等。
值得注意的是,所有分布式锁方案都需要关注一个共性问题:死锁的预防与处理。无论哪种实现,都要确保锁最终能被释放,通常通过设置合理的超时时间来实现。
关于这期时间的考虑,我们希望有一种程序能实现锁的监控和自动续期。后边还会总结一篇《常用经典分布式锁方案》,敬请期待。
(笑脸)

技术的选择没有银弹,关键在于理解其原理和适用边界。希望本文对分布式锁的剖析,能帮助你在实际 系统架构 设计中做出更合适的选择。在云栈社区,我们持续分享此类后端技术深度解析,欢迎交流探讨,共同进步。
 发表于 2026-3-3 19:03:36
|
查看: 202|
回复: 0
发表于 2026-3-3 19:03:36
|
查看: 202|
回复: 0
