为什么有些短视频广告总能“刚好”出现?你刚搜完露营装备,立刻刷到户外电源广告——这并非巧合,也不只是简单的关键词匹配。在你看到广告之前,一套高度复杂的AI系统早已在幕后运转。它不再盲目推送素材,而是深入理解商品本身。今天,我们就来拆解快手广告商品智能理解系统,看看那些“懂你”的广告,究竟是如何炼成的。
一、背景
1.1 核心转变:广告平台不再“投广告”,而是“投商品”
当下,广告行业正悄然发生一场颠覆性变革:主流平台的广告推荐核心逻辑,正从传统的“创意召回”(本质是“投广告”),全面升级为“商品召回”(本质是“投商品”)。
这一转变重塑了广告推荐的底层逻辑。我们可以用一个通俗的比喻来理解:旧系统如同选角导演,只专注挑选优质“演员”——即酷炫的广告,试图以素材本身打动用户;新系统则更像电影制片人,优先锁定优质“剧本”——也就是商品本身,因为一个有竞争力的商品,可以匹配多元广告素材。核心焦点已从“表现形式”转向“商业内核”。
这一转变之所以意义重大,核心在于它更贴合生意的本质,同时为广告主与平台带来了双重核心价值:
- 大幅缩短了广告“学习周期”:当推荐系统真正理解了“商品”的特征,它就能跳过对每一条新广告素材的漫长学习过程,直接为商品匹配潜在用户,做到“快速起量”,帮广告主降低投放成本、提升转化效率。
- 优化了整个广告生态:广告主依托重复搭建相同广告计划的“人海战术”将不再奏效,平台转而引导广告主将精力聚焦于“素材多样化供给”,推动创意质量升级,最终形成“优质商品+多元素材+精准匹配”的良性循环,兼顾用户体验与商业价值。
具体案例如下:
-
案例1:落地页中提取的商品信息

-
案例2:视频素材中提取的商品信息

1.2 问题根源:广告数据的结构性失真
要实现“投商品”,AI首先要知道“商品到底是什么”。你或许会疑惑:广告主自己填不就行了?但现实却是一场数据的“灾难”。
问题的根源在于广告投放后台的系统设计。当前系统仅对商品名、类目等少数字段设为必填,而品牌、核心卖点、目标人群等支撑精准投放的关键信息均为非强制项。这种设计直接导致人工填报数据长期处于低质量状态,难以支撑精准投放。在快手平台的实际情况中,相关问题具体如下:
- 准确率堪忧:由于核心字段主要依赖人工填写,在投放规模较大的中小客户场景中,数据准确性难以得到充分保障。
- 敷衍填写问题突出:在实际填报过程中,部分字段存在误填、错填现象。以课程类广告为例,相关字段的错误率超过七成。
- 概念混淆情况普遍:在人工录入场景下,字段语义易被混淆。例如,“流量卡”与“手机卡”混选、“会员权益”被归入其他增值服务等情况。
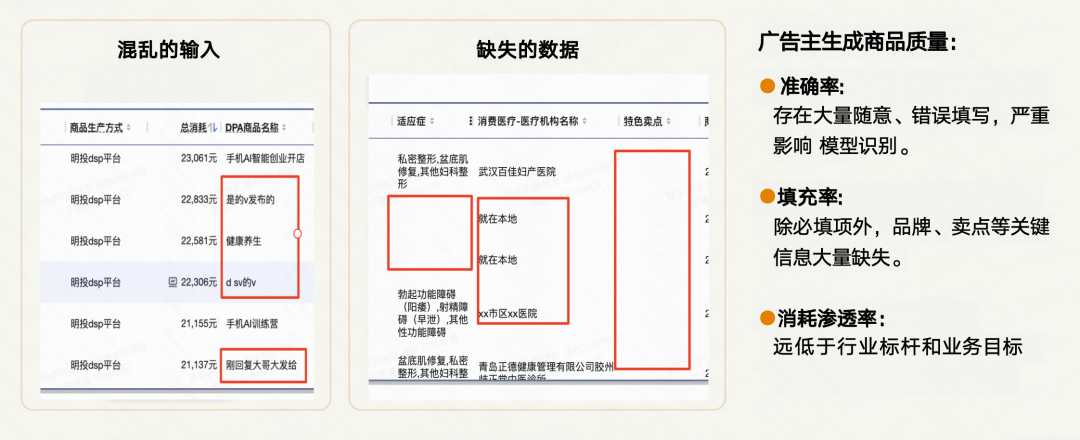
这种低质量的人工数据,已成为制约“商品召回”落地、实现广告精准投放的核心瓶颈。正因如此,通过AI自动、准确地从广告素材中理解商品信息,不再是可有可无的锦上添花,而是支撑广告推荐逻辑升级、提升投放效率的迫在眉睫的关键能力。
二、技术方案
基于上述问题,快手磁力引擎技术团队构建了一套以商品为中心的广告商品智能理解系统,通过两大核心模块实现高效转化:
- “慧眼+外脑”预处理:利用小模型精准提取关键帧过滤噪音;结合RAG检索增强与知识蒸馏,使7B小模型在核心字段准确率对标32B大模型,总体成本降低约60%。
- MoM混合模型协作:摒弃单一模型架构,按任务动态路由——生成式任务用Dense模型,逻辑判别用Thinking模型抑制幻觉;简单样本走小模型、困难样本走大模型,并引入LoRA/SFT微调增强泛化,实现精度与成本的极致平衡。
模块一:给商品理解“慧眼”和“外脑”:预识别、RAG与模型蒸馏
通过预识别过滤噪音、RAG补充外部知识和知识蒸馏降本提效的三层架构,这套系统实现了从信息筛选、知识增强到模型优化的全链路升级。
戴上“聚焦镜”:内容预分类&预识别
广告视频中往往夹杂着大量与商品无关的“噪音”信息,比如花哨的特效、无关的剧情等。如果直接将整个视频丢给大模型分析,不仅计算成本高,还容易被无关信息干扰。
针对这一问题,系统专门增设了预识别模块,它就像AI的“聚焦镜”。在正式识别前,先用成本较低的小模型快速扫描整个视频,过滤掉无关的噪音信息,并智能地提取出包含核心商品信息的关键帧和内容摘要。这确保了后续的大模型能够集中精力处理最有价值的信息。
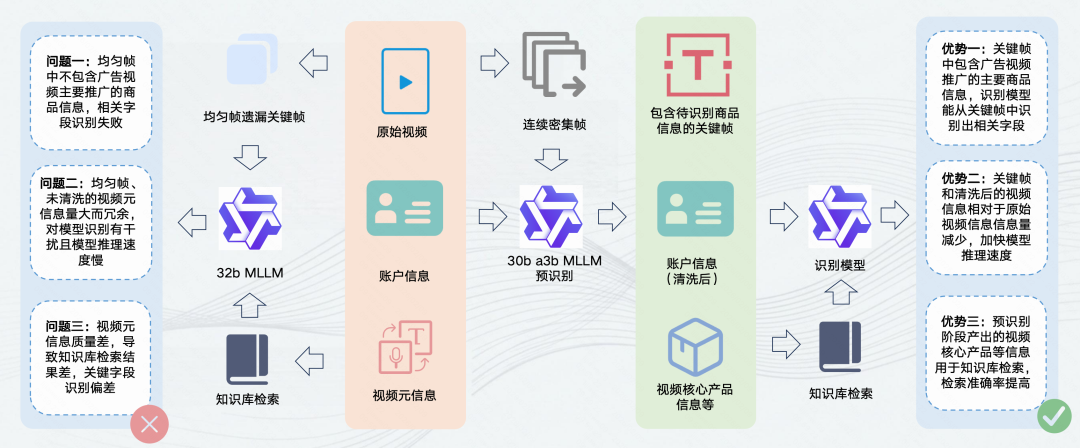
拥有“智能资料库”:RAG检索增强生成
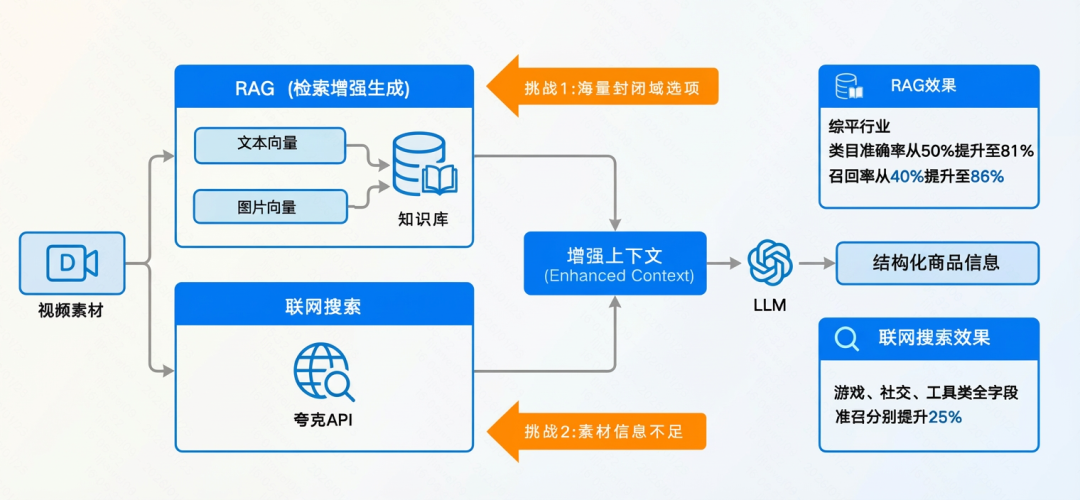
RAG(检索增强生成) 是这套系统的“外脑”,负责提供关键的外部知识。在商品理解任务中,RAG主要在两个方面发挥巨大作用:
- 应对“上下文爆炸”:面对数以万计的商品类目或品牌,无法将所有选项都告诉大模型。RAG依托embedding等语义检索技术,从海量候选中精确召回最相关的几个,将“问答题”变成“选择题”,极大降低了模型的识别难度。
- 联网实时检索:广告视频内的信息往往是有限的。比如,一款新游戏的具体玩法等“世界知识”并不会出现在视频里。此时,系统会通过联网API进行实时检索,将这些缺失的关键信息补充进来。数据显示,这项技术能将游戏、社交等行业的准确率和召回率提升25-41个百分点,效果明显。
“百炼成钢”:模型微调与知识蒸馏的降本增效之道
有了强大的模型和知识库,新的瓶颈随之而来——成本与效率。最初采用的32B级别大模型虽然性能强劲,但其高昂的GPU成本和较慢的推理速度,无法满足每日近百万条视频的处理需求。
为此,团队通过模型微调与知识蒸馏技术,实现了性能、成本与效率的三重优化:
- 解决方案:选用了更小巧的7B模型,并采用知识蒸馏技术进行微调。简单来说,就是让强大的32B模型当“老师”,将它的知识和推理能力“蒸馏”并传授给7B这个“学生”模型。
- 成果实现:经过特训的7B模型不仅成功“出师”,甚至在某些方面“青出于蓝”。在不牺牲甚至提升效果的前提下,实现极致的降本增效。最终,GPU资源消耗减少了约2/3,总体成本降低了约60%。更关键的是,这个轻量级模型在一些复杂的推理任务上表现甚至优于32B模型,整体准确度提升2%~4%。
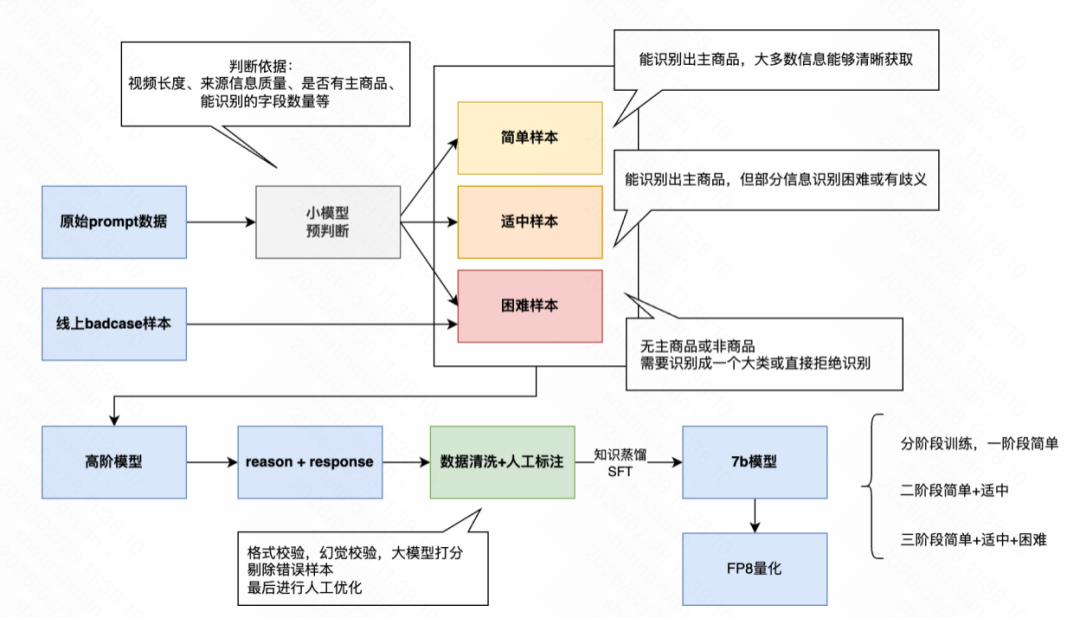
整个训练过程采用由易到难的渐进式微调策略,主要分为四步:
- 样本分级:用轻量模型对原始数据和线上badcase进行难度评估,分为简单、适中、困难三类。
- 生成训练数据:利用大模型对分级后的样本生成推理和答案,再经过自动校验 + 人工修正,确保数据的高质量,重点优化“拒识”和错误处理逻辑。
- 分阶段微调:在目标7B模型上分三轮训练,第一轮仅训练简单样本,帮助模型夯实基础;第二轮加入适中样本,提升模型的泛化能力;第三轮融入困难样本,增强鲁棒性。
- 量化部署:微调完成后,对模型做FP8量化,降低资源消耗,便于高效上线。
这种渐进式训练方法不仅提升了模型在各类复杂场景下的准确性,更重要的是增强了对未知、模糊、错误输入的鲁棒性,使模型在真实世界的应用中更加可靠和安全。这正是构建健壮的人工智能系统的关键一步,更多关于模型训练和AI应用的探讨可以在云栈社区找到。
模块二:多模态大模型的“团队作战”:各司其职的混合模型策略
在实际的生产环境中发现,仅依赖单一多模态大模型直接处理广告视频理解任务,往往面临准确率瓶颈、幻觉风险高、成本不可控三大核心挑战。广告视频具有信息密度高、营销逻辑强、模态复杂的特点。面对海量、多样化的广告,如果所有任务都交给单一模型处理,难以同时兼顾“泛化能力”与“垂直精度”。
为此,团队设计了一套兼顾成本与效果的优化方案——MoM(Mixture-of-Models)混合模型策略。其核心思想可简洁概括为:“分而治之”。它将复杂的商品识别任务拆解成不同类型,再将各类任务分配给最擅长处理该领域的“专家模型”,实现优势互补、高效协同。
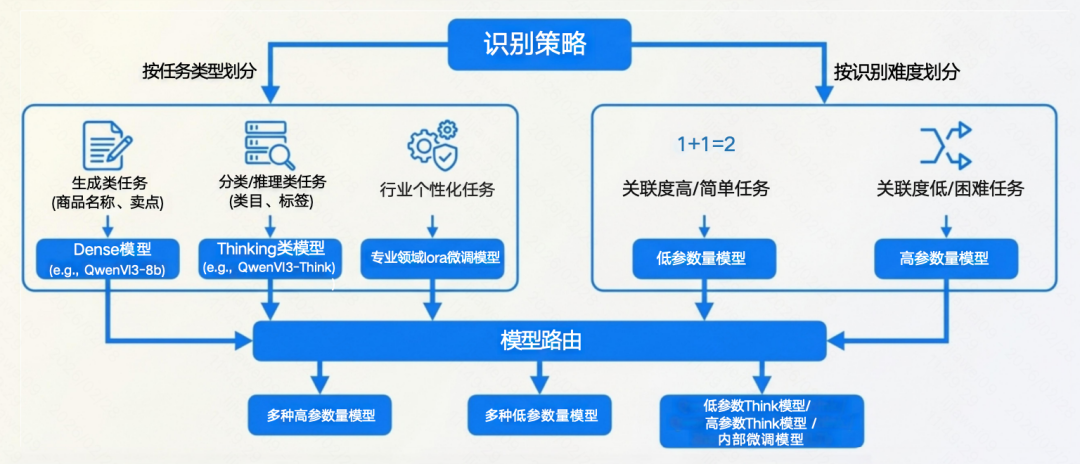
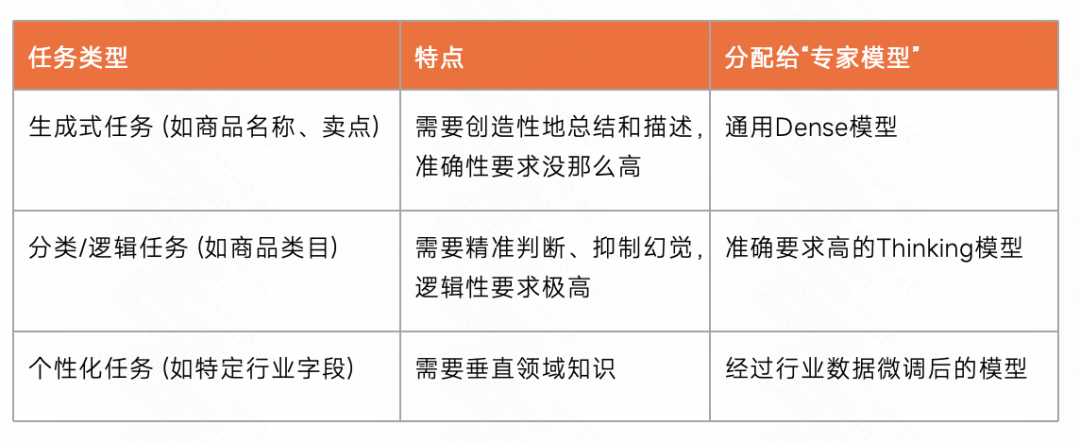
具体的分工合作模式可以参考下表:
MoM架构不仅实现了按任务类型的分工,还会根据模块一中预识别的难度分数进行智能调度。对于信息明确、识别难度低的简单广告,会分配给计算成本较低的“低参数模型”(如7B模型)处理;而对于信息模糊、特征不明显、识别难度大的复杂广告,才会启用算力更强、识别精度更高的“高参数模型”(如32B/72B模型)。这种精细化的任务路由策略,真正实现了商品识别效果与算力成本的最优平衡(Trade-off)。
三、业务应用
为直观展示落地效果,下面以一则电商广告为案例,简要说明该系统的工作逻辑。该广告含商品无关的引流剧情,传统方法难以精准识别商品,而系统通过多技术协同轻松破解这一难题。
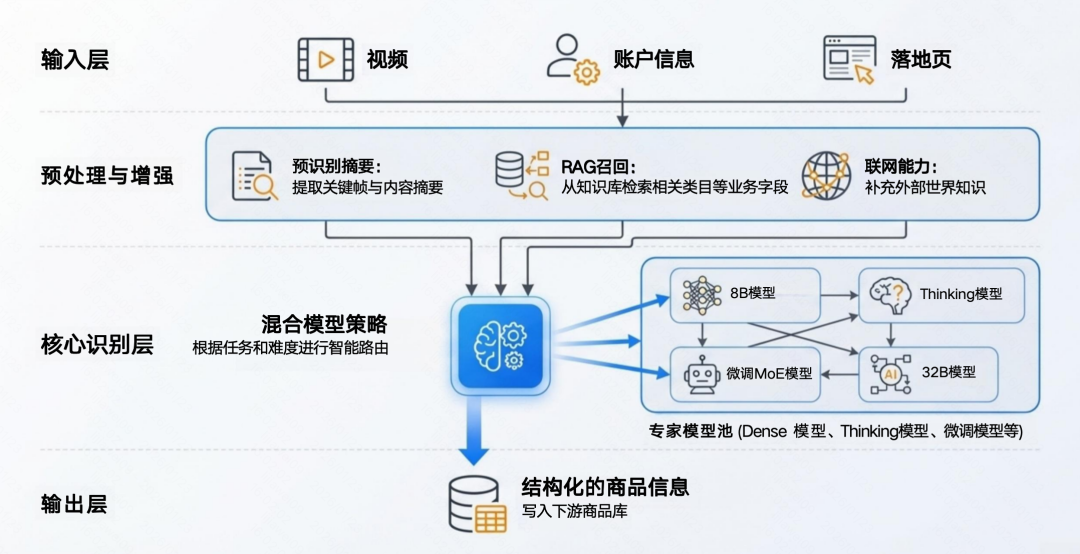
本系统采用“预识别-精准识别”二阶段架构,结合分治策略高效完成整个识别过程,具体如下:
- 预识别模块快速过滤剧情噪音,聚焦商品核心信息并提取关键帧。
- RAG模块依托提取的信息,从电商知识库中召回高度相关的商品类目候选集。
- 多模态大模型混合决策,结合场景难度选用轻量模型高效推理。
- 最终每个识别模块分别输出商品不同维度的识别信息(品牌、类目、卖点等),并快速合并成完整的识别结果。
广告的视频结构
| 时间 |
内容 |
截图 |
| 0s-40s |
剧情演绎 |
 |
| 40s-45s |
钩子商品展示 |
 |
| 45s-50s |
活动展示 |
 |
根据上方内容,内容预识别结果如下:
- 视频关键帧:精确找出需要重点识别的钩子品关键帧。

- 视频核心商品:淘宝新人特惠购活动,主要商品包括心相印抽纸(品牌:心相印,价格:0.01元,特点:柔软亲肤、加大加厚、湿水不破、官方发货、包邮),以及其他日用百货、食品生鲜等商品,价格均为0.01元。活动仅限一年内未在淘宝APP购物的用户参与。可以看到整体内容包含钩子品的关键信息以及相关活动信息,为下游更精准的结构化识别任务过滤了很多非必要信息。
- 视频分数:5分。该分数是对视频内容质量和相关性的综合打分,表示视频中的钩子品信息展示清楚,且识别内容与所需要识别的电商行业密切相关。依据该分数,推测后续进一步识别的难度会比较低,因此系统会决策在后续链路中使用更轻量的模型进行识别。反之,系统则会采用更高参数量且更复杂的拆分识别对视频进行全面识别,保证成本与效果的平衡。
接下来系统会通过提炼的“核心商品内容”和“关键帧”进行语义检索,召回对应商品的类目。通过RAG模块精准召回TopN相关类目,其中首位命中率高,即为目标类目。该设计将开放域类目判断转化为封闭集选择问题,大幅缩小决策空间,有效提升识别准确率与推理效率。
由于视频的质量分数为5分,后续系统会用参数量相对更小的模型进行后续结构化字段的识别动作,保证效果和成本的平衡。部分识别结果如下:
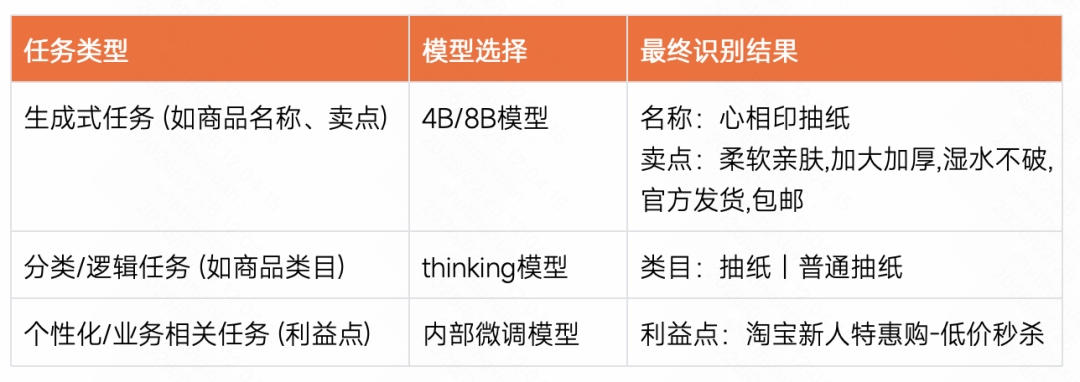
这个案例充分展现了系统的核心优势,即便在信息稀疏、干扰众多的复杂场景下,系统仍能通过预识别、RAG与多模态模型的协同机制,高效、精准地完成商品理解,为“商品召回”式精准投放提供坚实支撑。
四、总结
通过引入AI系统,广告商品信息的质量与数量均实现根本性提升,并转化为切实的商业价值。核心字段准确率提升至90%以上,整体信息填充率达到82%,商品渗透率更是突破至93.3%。
该体系不仅显著提升广告效率,通过精准的“人货匹配”让广告投放更加高效,为用户提供更符合兴趣的内容,并带动下游业务消耗增长14%;也推动了行业范式演进,验证了广告系统从“投创意”向“投商品”模式转型的技术可行性。
从读懂一则广告开始,AI正在重塑信息理解与分发的每一个环节。这不仅是技术能力的进化,更预示着一个更加智能、高效、个性化的数字世界的到来。
 发表于 2026-3-4 07:39:07
|
查看: 236|
回复: 0
发表于 2026-3-4 07:39:07
|
查看: 236|
回复: 0
