近日,英伟达(NVIDIA)发布的世界-动作模型(world-action model) DreamZero,在两项颇具代表性的机器人基准测试 RoboArena 和 MolmoSpaces 上双双登顶,展现了卓越的性能。

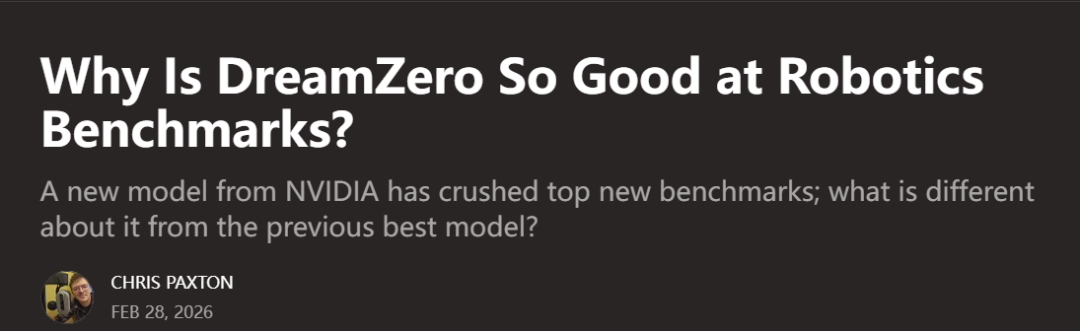
DreamZero的核心思想颇具启发性:在同一个模型中,同时预测未来的视频帧和机器人的动作。这意味着,机器人在执行真实动作前,会先在模型的“脑海”中进行一次“想象”或推演。
但这种设计为何能带来如此显著的性能提升?它究竟比传统的策略模型或纯粹的世界模型强在哪里?这究竟是 模型架构 上的真正范式突破,还是仅仅依靠 数据 与 模型规模 的胜利?
围绕这些问题,一篇近期发布的分析文章《Why Is DreamZero So Good at Robotics?》提供了一个更深入的视角,探讨了在训练一个通用机器人策略时,数据与模型架构需要具备哪些关键特征,并对一些固有认知提出了质疑。
文章地址:https://itcanthink.substack.com/p/why-is-dreamzero-so-good-at-robotics
以下是该文的核心分析与解读。
DreamZero 是什么?
简单来说,DreamZero 是一个 世界—动作模型。它借鉴了世界模型的核心理念,特别是“视频生成对机器人任务有价值”这一观点,但在关键设计上做了重要改动:联合建模动作生成与视频生成。
通常,世界模型可分为两类:
- 动作条件世界模型:学习从当前状态和动作到下一状态的映射,即
x′ = f(x, a)。
- 逆动力学世界模型:先学习状态转移
x′ = f(x),再通过逆动力学模型学习动作 a = g(x, x′)。
相比之下,DreamZero 更像一个传统的机器人策略,但它会同时预测未来视频。因此,它学习的是 (x′, a) = f(x),即在同一个模型中同步预测未来状态和对应动作。
与传统的视觉-语言-动作模型(VLA)相比,DreamZero 不仅预测“做什么”(动作),还预测“世界会变成什么样”(视频)。这为模型提供了更丰富的监督信号,帮助它更好地理解和学习环境演化的物理规律。
评估基准:RoboArena 与 MolmoSpaces
RoboArena 是一个基于 Droid 数据构建的分布式真实世界基准测试。全球评测者在相似的设置下,根据自然语言指令运行开放式任务。
从数据分布看,这对 DreamZero 有一定优势,因为其训练数据 Droid 包含了非常相似的环境和任务。但这仍是一个充满现实复杂性的真实评估,且任务由评测者自行选择,构成了一个类似 Chatbot Arena 的“头对头”比较平台。
MolmoSpaces 则是一个新的高保真物理模拟基准测试平台,提供多样化、程序化生成的环境。其 MolmoSpaces-Bench 重点测试在多种变化条件下(如抓取、放置、开合及其组合)的任务表现。
这是一个尚未饱和的新基准,模型间仍有明显差距。DreamZero 在此类测试中的优异表现,证明了其强大的泛化能力。
性能提升的关键因素分析
通过与当前排名第二的模型 π-0.5 进行对比,我们可以从几个维度剖析 DreamZero 的优势。
1. 训练数据:分布比规模更重要
π-0.5 使用了超过 1万小时 的真实机器人数据、VLM 数据以及 Droid 数据进行训练。而 DreamZero 主要使用 DROID 或 AgiBot 数据。
数据分布的匹配度可能起了关键作用。在 DreamZero 的论文中,它在 AgiBot 数据集(π-0.5 未训练过)上的表现显著优于后者;但在双方都使用的 DROID-Franka 设置下,差距则小得多。
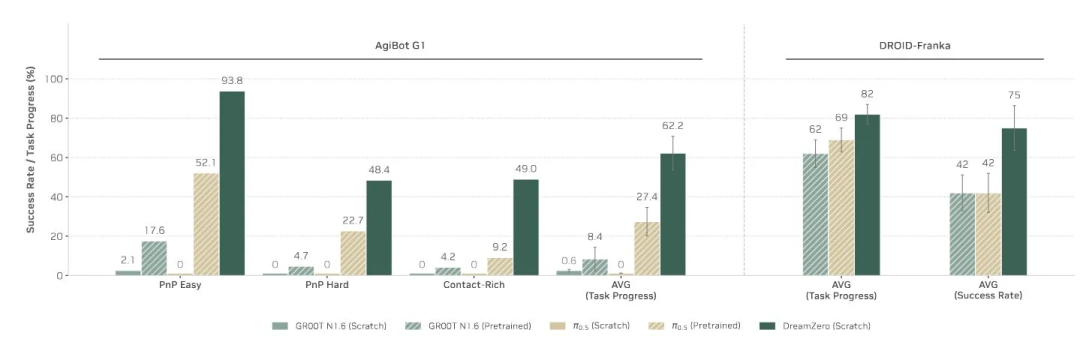
这暗示了一个重要观点:额外的海量机器人数据,其效果可能被高估了。更关键的因素或许在于,是否在与目标任务分布高度一致的数据上进行预训练。
例如,Physical Intelligence 的博客曾展示,当模型在与目标任务高度一致的数据上预训练时,性能会出现飞跃。
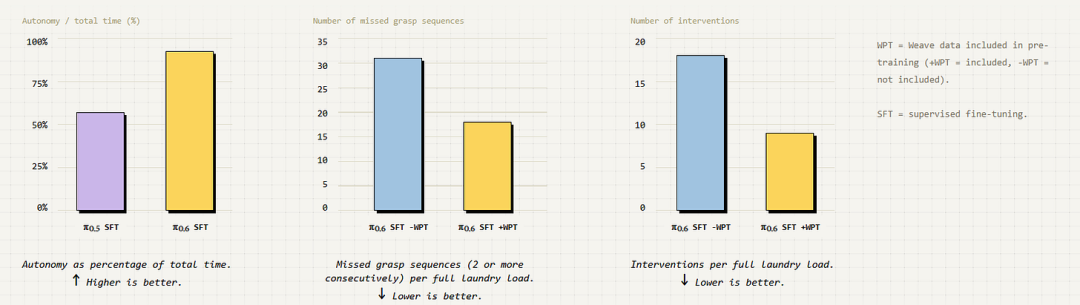
因此,从不同机器人形态收集海量数据所带来的收益,可能并不比使用充足、廉价的第一视角视频数据更多。这对于希望训练跨机体通用模型的开发者来说,是一个需要重新思考的方向。
2. 模型主干:规模与时间上下文
- 模型规模:DreamZero 基于 140亿参数 的视频生成模型 Wan2.1 构建。而 π-0.5 基于30亿参数的视觉语言模型 PaliGemma,参数规模相差近5倍。
- 时间上下文:DreamZero 最多可接收 8帧 历史视频作为上下文输入。π-0.5 则仅能输入单帧图像。
真实世界的机器人任务具有部分可观测、依赖物理动态和时间连续性的特点。单帧图像无法判断物体运动状态、无法推断动作后果、难以理解惯性等物理效应。而多帧历史信息(如8帧)能让模型捕捉运动趋势和状态变化,从而做出更稳定、准确的决策。
3. 视频生成作为强大的辅助监督
DreamZero 是一个巨大的模型,其论文的消融实验表明,模型规模对性能至关重要。但同时,引入长上下文和大规模模型在 模型训练 的低数据环境下容易导致过拟合。
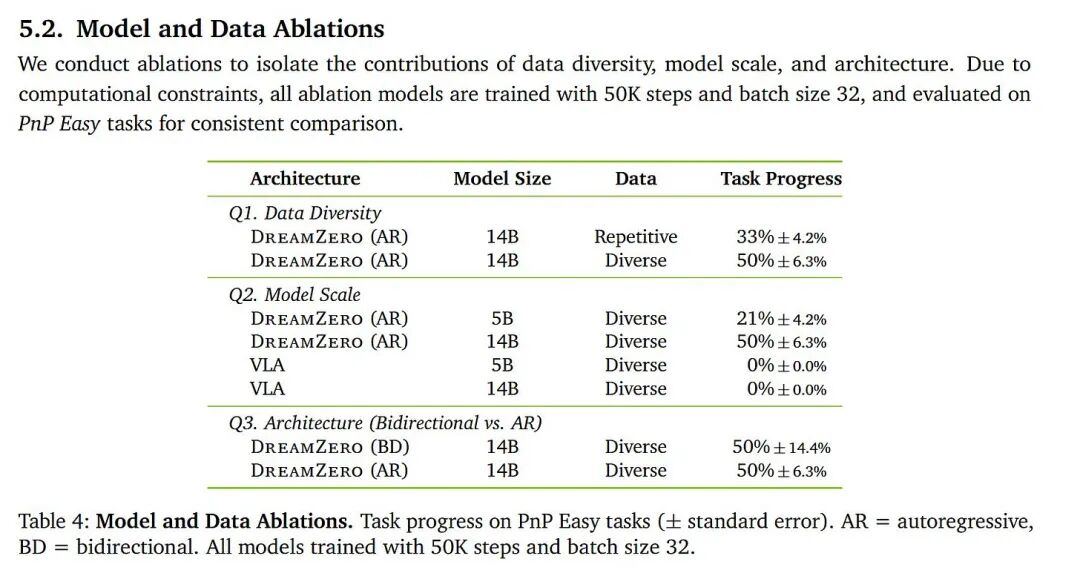
这里有一个关键猜想:视频生成目标充当了一种强大的辅助损失。与稀疏的机器人动作奖励信号相比,视频预测提供了更强、更密集的监督信号,迫使模型学习内部的物理世界模型。这可能正是 DreamZero 能良好泛化到未训练过的、多样化的 MolmoSpaces 环境的重要原因。
总结与思考
仅凭现有论文,我们无法获得全部答案。例如,我们无法知晓 Physical Intelligence 使用的全部数据细节,英伟达用于推理的GB200设备也尚未普及。但对于广大研究者和工程师而言,DreamZero 的成功传递出一个积极信号:我们或许并不需要此前认为的那么海量的专属机器人数据,就能在真实世界任务中取得强劲表现。
其成功可归纳为几个关键点:与任务匹配的高质量数据分布、足够庞大的模型容量、利用多帧视频理解时间动态,以及通过视频预测任务提供的密集物理监督。这为下一代 机器人策略 的 模型训练 提供了新的设计思路。对这类前沿 人工智能 话题感兴趣的开发者,欢迎在 云栈社区 的 智能&数据&云 板块进行更深入的交流与探讨。
 发表于 2026-3-4 08:26:06
|
查看: 283|
回复: 0
发表于 2026-3-4 08:26:06
|
查看: 283|
回复: 0
