在现代医学实践中,临床诊断依赖于对文本和视觉数据的综合分析,医生需要凭借深厚的医学专业知识进行系统性、严谨的推理。近年来,大型视觉-语言模型(VLMs)和基于代理的方法在医学诊断领域展现出巨大潜力,因其能够有效整合多模态患者数据。然而,这些方法往往直接给出答案,依赖经验驱动的结论,而缺乏必要的定量分析,这严重削弱了其可靠性和临床实用性。
一、研究背景:传统AI医学诊断的困境
1.1 临床诊断的真实流程
临床诊断是医学实践的核心,涉及综合各种临床信息以得出结论。医生主要基于医学影像的视觉线索和患者病历的文本信息做出决策。例如,医生通过检查放射影像来评估肿瘤规模,或分析病理图像以筛查潜在癌症。
但真实的临床诊断远非简单的一次性问答。它通常遵循一个标准化的、逐步推进的过程,主要包括两个阶段:
- 确定目标疾病并基于医学指南制定标准化工作流程,其中包含多个用于支持决策的临床指标。
- 逐步分析个性化数据,结合定性和定量评估来评价这些指标。
在整个过程中,每个分析步骤都建立在先前假设的基础上,并得到相关文献或专业工具分析的支持。以青光眼诊断为例,关键的杯盘比指标,就依赖于前一步骤中对视盘和视杯区域的准确定位。
1.2 现有方法的不足
当前的主流方法倾向于将医学诊断视为一个经验性的一次性问答任务,仅依赖VLMs的内部知识做出定性判断。然而,现代医学强调循证诊断,这需要结构化的推理和坚实的临床证据。
现有方法主要存在以下问题:
- VLMs方法:虽然在多项任务中表现出色,但缺乏足够的深度医学知识。像GPT-4o和DeepSeek-R1这类模型虽有推理能力,但其有限的细粒度视觉感知能力制约了定量分析,从而降低了临床应用的可靠性。
- 代理系统方法:现有的医学代理系统更像是一个松散的“工具箱”集成,而非一个临床导向的、端到端的自动化工作流。当被要求提供诊断时,这些系统往往只是调用内部的VLM来回答问题,而非系统地选择并组合适当的专业工具来支持其决策。
如图所示,当面对青光眼和心脏病诊断时,GPT-4o和MMedAgent等现有方法只能给出模糊、定性的回答,无法提供具体的定量分析和循证推理。

二、MedAgent-Pro:创新的层次化诊断框架
为解决上述问题,研究团队提出了MedAgent-Pro。这是一个专门为多模态医学诊断设计的推理型代理工作流。其核心目标是构建一个符合现代医学标准的工作流,提供基于医学指南和定量分析的决策支持。
2.1 核心设计理念
MedAgent-Pro采用层次化结构来模拟现代临床程序,分别在疾病和患者层面进行逐步推理:
- 疾病层面规划:生成标准化的诊断计划。
- 患者层面推理:遵循生成的计划,分析个性化的患者信息。
为确保诊断计划符合临床指南,MedAgent-Pro集成了一个检索增强生成(RAG)代理来检索相关医学知识。同时,与常规临床工作流一致,该系统还整合了专家工具(如视觉模型),以实现对临床指标的准确定量评估。
2.2 系统架构概览
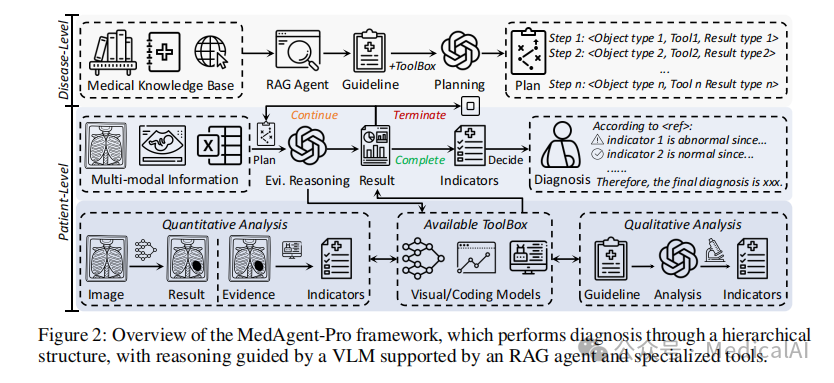
如图所示,MedAgent-Pro通过一个层次化结构进行诊断,其推理过程由VLM指导,并得到RAG代理和专业工具的支持。整个工作流程包含以下关键部分:
- 医学知识库:基于MedlinePlus构建,包含1000多种疾病条目和4000多篇专家评审文章。
- RAG代理:执行两步检索过程,先通过关键词搜索过滤,再进行向量检索。
- 诊断计划生成:VLM基于检索到的指南,总结疾病特异性临床指标并生成可执行的计划。
- 工具箱集成:包括分割模型、定位模型和基于LLM的编码工具。
三、疾病层面的知识驱动规划
在临床实践中,医生会根据专业知识和经验为特定疾病制定标准化的诊疗流程。遵循这一惯例,MedAgent-Pro引入了检索增强生成(RAG)代理,在规划阶段融入医学指南来指导诊断计划的生成。
3.1 知识库构建
MedAgent-Pro配备了特定领域的知识库 K,该知识库首先被索引到向量数据库中,每个文档被分割成块。为加速检索,系统会为每个文档预生成一句话摘要,并以此作为索引。
3.2 RAG检索流程
收到关于疾病的查询后,RAG代理 R 首先通过关键词搜索这些摘要来过滤不相关的条目,然后在剩余文档中进行向量检索以提取前5个最相关的文档块。基于检索到的内容,VLM总结其要点并生成一份程序性指南 G,该指南反映了该疾病在真实临床实践中的诊疗路径。
生成过程可表述为:G = V(R(K))

3.3 诊断计划生成
VLM首先从指南 G 中总结出一组疾病特异性的临床指标 I = {I₁, I₂, ..., Iₘ}。为了支持对 I 的分析,MedAgent-Pro配备了一个工具集 T。为了构建可执行的计划,VLM将 G 与一个预定义的操作描述集 A 进行整合,其中每个元素 a ∈ A 都与一个工具 t ∈ T 一一对应。
基于 G 和 A,VLM生成一个包含多个推理步骤的疾病特异性诊断计划 P = {P₁, P₂, ..., Pₙ}。每个步骤 Pᵢ ∈ P 可以表示为:
Pᵢ : rᵢ = ⟨krᵢ, vrᵢ⟩ = ⟨krᵢ, t(voᵢ)⟩, t ∈ T
在实践中,P 被存储为JSON文件,包含操作键 t、预定义的Python函数,以及两个数据字段 ko 和 kr,分别用于指定工具 t 的预期输入和输出数据属性。

四、患者层面的循证推理
对于患有该疾病的每一位患者病例,MedAgent-Pro遵循生成的疾病特异性诊断计划 P 来分析临床指标 I。
4.1 编排过程
针对每位患者的个性化多模态数据 D,VLM执行一个编排过程,根据数据的可用性从 P 中选择可执行的步骤,过滤掉那些需要当前不可用输入数据的步骤:
P' = V(P, D) 使得 ∀Pᵢ = ⟨krᵢ, vrᵢ⟩ = ⟨krᵢ, t(voᵢ)⟩, koᵢ ∈ D
如图4所示的青光眼诊断案例中,当只提供眼底图像时,编排过程会选择相关的步骤,并跳过那些需要OCT图像或视野检查等不可用数据的步骤。
4.2 定量分析
为了实现定量分析,系统会调用专业工具代理来执行专业评估,从而弥合AI与临床实践之间的差距。工具集 T 包括各种视觉模型,例如分割工具(如Medical SAM Adapter、MedSAM、Cellpose)、定位模型(如Maira-2)和基于LLM的编码工具(如Copilot)。
在青光眼诊断示例中:
- 专业分割工具用于提取视杯和视盘的掩码。
- 随后,编码工具基于分割结果计算杯盘比——这是青光眼诊断的一个关键定量指标。
4.3 循证推理范式
现代医学的核心原则是循证实践,强调审慎、明智地使用当前最佳的临床证据,结合个人临床专业知识,来指导患者护理决策。遵循这一原则,系统在顺序推理过程中会评估每个步骤 Pᵢ‘ 的输出 rᵢ = <krᵢ, vrᵢ>,以确定一个状态 sᵢ ∈ {Continue, Terminate, Complete},从而指导推理过程是否应该继续。
状态评估函数 φ 由VLM实现,它基于输入数据 voᵢ 的质量和结果数据 vrᵢ 的合理性来评估 vrᵢ 的可靠性:
- 如果
sᵢ = Continue,输出 rᵢ 被视为证据 e,并作为下一个推理步骤的输入 oᵢ₊₁。
- 如果
sᵢ = Terminate,过程停止,因为 rᵢ 被认为不可靠,可能阻碍后续推理并导致错误诊断。
- 该过程迭代进行,直到
sᵢ = Complete。
4.4 决策制定
最终的输出是一组被标记为 Complete 的指标的推理结果:R_final = {rᵢ | sᵢ = Complete}。随后,VLM在临床指南 G 的指导下,为 R_final 中的结果分配基于风险的权重 W,以平衡不同指标的影响。最终的风险评分 ρ 计算为加权和:
ρ = Σ wᵢ * vrᵢ,其中 wᵢ ∈ W, rᵢ ∈ R_final
通过将评分 ρ 与一个预设的风险阈值 θ 进行比较,得出最终诊断。这种循证推理的方式,使MedAgent-Pro能够将可靠的外部证据与专家知识相结合,从而改善诊断决策,推动了符合现代标准的诊断工作流程。
五、实验验证与性能评估
研究团队在四个难度递增的数据集上进行了全面的实验。
5.1 数据集介绍
- REFUGE2数据集:用于青光眼诊断。
- MITEA数据集:用于心脏病诊断(如扩张型心肌病、淀粉样变性)。
- MIMIC数据集:从100名患者中抽取442例胸部X光病例,每例涉及多达12种潜在胸腔疾病或异常的识别。
- NEJM数据库:编制了992个真实诊断病例,涵盖10多个解剖区域、10种成像模式和50种疾病。
5.2 与通用VLMs的比较
研究团队将MedAgent-Pro与先进的VLMs进行了比较,包括BioMedClip、GPT-4o、LLaVA-Med、Janus、Qwen和InternVL。实验结果显示:
- 青光眼诊断:与GPT-4o相比,平衡准确率(bAcc)提升34.0%,F1分数提升55.3%。
- 心脏病诊断:与GPT-4o相比,bAcc提升21.0%,F1分数提升44.2%。
- NEJM数据库:在有视觉工具支持的领域(如细胞成像、胸部X光、CT/MRI、眼科)表现出显著性能提升,整体改进7.9%。
5.3 与医学代理系统的比较
MedAgent-Pro还与先进的医学代理框架(如MedAgents、MMedAgent和MDAgent)进行了比较。如表1所示,MedAgent-Pro在所有疾病和领域上持续优于这些方法。
这种性能优势源于先前的方法主要被设计用于基础问答或作为模块化工具箱,缺乏处理复杂多模态临床场景的能力。相比之下,MedAgent-Pro将基于检索的诊断步骤纳入其推理过程,并无缝集成了视觉工具,实现了临床应用中所需要的有效且全面的决策支持。
5.4 与任务特定模型的比较
研究团队还将MedAgent-Pro与特定任务的SOTA方法进行了比较,例如专门用于青光眼诊断和胸部X光分析的模型。结果显示:
- 青光眼诊断:AUC指标提升6.8%,bAcc和F1分数分别提升4.6%和3.3%。
- 胸部X光分析:平均性能提升13.7%。
值得注意的是,MedAgent-Pro在零样本设置下仍然优于这些任务特定模型,这进一步证明了将专业工具与通用VLMs相结合,可以达到与领域特定模型相媲美的性能。
六、消融研究与深入分析
6.1 关键组件有效性验证
研究团队在青光眼和心脏病诊断上进行了消融研究,以评估三个关键模块(规划、定量分析和循证推理)的有效性。结果表明:
- 引入规划模块显著提高了整体性能。
- 整合视觉工具进行定量分析带来了进一步的提升,F1分数分别提高了34.5%和20.7%。
- 添加循证推理进一步增强了计划执行的一致性和分析的可靠性,达到了最佳性能。
这些结果验证了所提出组件的有效性,并证明了它们在共同实现真正循证医学推理中的互补作用。
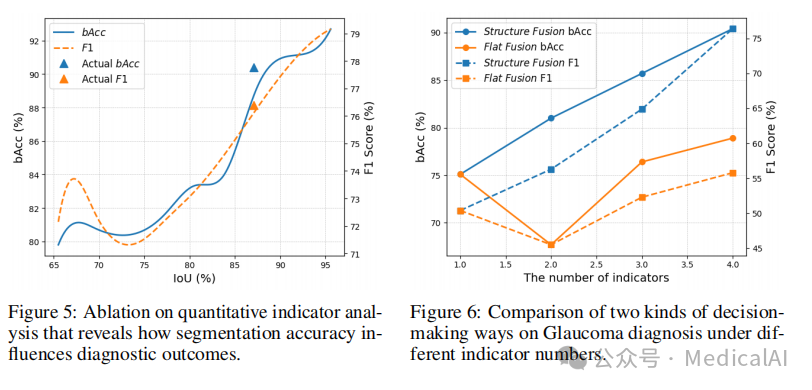
6.2 指标准确性影响分析
为了评估定性和定量分析对最终诊断准确性的各自影响,研究团队进行了消融研究:
- 定性分析:使用眼科专用模型VisionUnite代替GPT-4o进行定性分析,结果仅显示微小改进。这表明在医学指南的指导下,通用VLMs足以胜任定性分析任务。
- 定量分析:通过模拟带噪声的分割掩码进行实验,观察到更高的分割准确性持续带来更好的诊断性能。
这些发现表明,在多模态诊断中,循证的定量分析比经验驱动的定性评估起着更为关键的作用。
6.3 决策策略分析
研究团队探索了整合临床指标的替代决策策略:
- 结构化融合(MedAgent-Pro采用):为临床指标分配基于风险的权重。
- 扁平融合:将所有原始指标直接输入VLM进行最终决策。
如图所示,结构化融合通过为不同指标分配明确权重,在不同指标数量的情况下持续优于扁平融合,从而做出更平衡、更全面的决策,而VLM在扁平融合中往往只关注部分线索。
七、临床专家人工评估
7.1 与真实临床工作流程的一致性
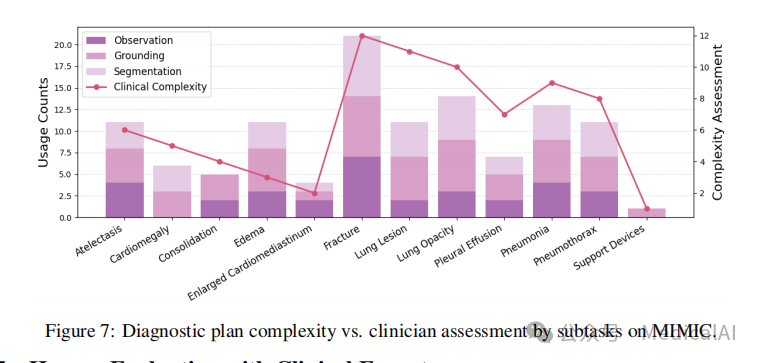
为了评估MedAgent-Pro对真实临床工作流程的反映程度,研究团队量化了其在12项胸部X光诊断任务中执行的步骤数量,并与胸科临床医生对这些任务复杂性的排名进行了比较。如图7所示:
- 大多数任务在总步骤数和医生评估的复杂性之间显示出明显的正相关。
- 例如,骨折诊断最为复杂且涉及最多步骤,而识别支持设备需要最少步骤且被评为最不复杂。
- 诸如胸腔积液和心脏肥大等依赖定量指标的疾病,因受益于视觉工具的整合,其工作流程步骤得以显著优化。
这些发现证明了MedAgent-Pro所采用的结构化、循证工作流程的有效性,以及与真实临床诊断过程的实用兼容性。
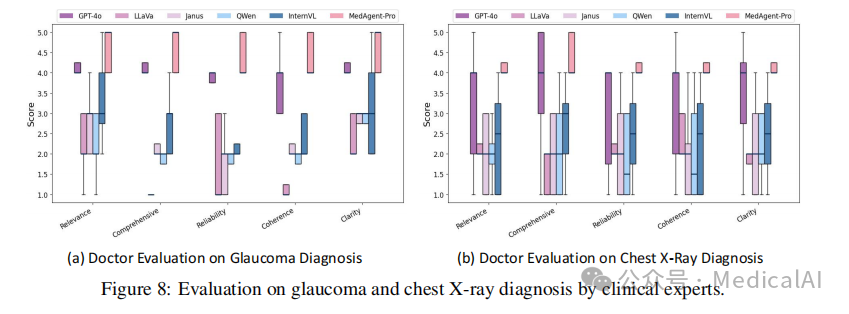
7.2 诊断内容质量评估
为了进一步评估诊断输出的质量,研究团队邀请了临床专家对青光眼和胸部X光诊断的结果进行盲评。临床医生按照1到5分的量表,对VLMs和MedAgent-Pro的诊断输出在五个维度上进行评分:相关性、全面性、临床可靠性、推理连贯性和语言清晰度。
如图8所示,MedAgent-Pro在全部五个维度上均显著优于其他VLMs,并在不同病例中表现出强大的稳定性。这突显了其结构化、循证方法与现代医学诊断标准的高度一致性。
八、创新贡献与临床意义
8.1 核心创新点
MedAgent-Pro的主要贡献包括:
- 首个系统化、循证推理的代理范式:通过使其与现代医学工作流程原则保持一致,将先前方法的经验性、直接输出转化为更严格的逻辑推理和有据可依的结论。
- 层次化结构设计:包含疾病层面和患者层面的推理。基于RAG的方法确保了疾病层面规划符合医学指南,而患者层面的定量分析和循证推理则保证了逐步分析的专业性和可靠性。
- 全面验证:在涵盖10多种成像模式、20多个解剖部位和50多种疾病的广泛设置下进行了验证,其性能超越了主流VLMs、医学代理系统甚至特定任务模型。在青光眼和心脏病诊断上分别优于GPT-4o达34%和22%。临床医生的评估进一步突显了其诊断输出的高质量和可靠性。
8.2 临床应用价值
MedAgent-Pro代表了向循证医学核心原则迈进的重要一步,推动了人工智能在医疗保健中的实际应用:
- 标准化诊断流程:通过疾病层面规划,确保每种疾病都有基于医学指南的标准化工作流。
- 个性化患者分析:患者层面推理实现对每位患者数据的精准定量评估。
- 可解释性增强:逐步的推理过程和证据验证提供了透明的决策路径。
- 临床可信度提升:专业工具的整合和循证推理显著提高了诊断结论的可靠性。
九、局限性与未来展望
9.1 当前局限性
尽管在自动化临床诊断方面取得了进展,但该工作仍存在若干局限性:
- 工具依赖性:所提出的框架依赖于视觉工具的可用性,而这些工具在某些小众或新兴的医学领域中仍然有限或尚未开发。
- 定性分析局限:系统的定性分析仍依赖通用VLMs,因此容易受到VLMs固有的不一致性和“幻觉”问题的影响。
解决这些局限性对于进一步提高计算机辅助诊断的可靠性和临床影响力至关重要。
9.2 未来研究方向
基于当前成果,未来的研究可以朝以下方向发展:
- 开发更多医学领域专用的视觉分析工具。
- 提升VLMs在医学定性分析中的稳定性和准确性。
- 将框架扩展到更多疾病类型和成像模态。
- 探索与医院临床信息系统的深度集成。
- 开展多中心、大规模的前瞻性临床试验进行验证。
十、结论
MedAgent-Pro通过其创新的层次化推理框架,成功地将AI医学诊断从一项经验性任务转变为一个循证、系统化的过程。该系统整合医学指南进行规划,融合定量分析,并验证每个推理步骤的可靠性,从而有效地弥合了当前AI系统与严谨临床程序之间的差距。
广泛的实验验证和临床专家评估均证明,MedAgent-Pro不仅在诊断准确性上显著超越了现有方法,更重要的是,其诊断过程符合现代医学实践标准,为AI辅助医学诊断的临床应用提供了一个切实可行的解决方案。这标志着向实现真正循证医学AI助手迈出了重要一步,为人工智能在医疗保健领域的深入应用开辟了新的可能性。对于关注前沿AI医疗动态的开发者,欢迎在云栈社区交流探讨。
 发表于 2026-3-5 03:45:34
|
查看: 145|
回复: 0
发表于 2026-3-5 03:45:34
|
查看: 145|
回复: 0
