
Linux内核的设计哲学充满了精妙与智慧,它不仅是驱动整个系统的引擎,更是众多现代计算技术的基石。从“一切皆文件”的抽象,到确保多任务公平的调度算法,再到为云原生提供支撑的容器技术,每一个核心模块都值得我们深入探究。今天,我们就来一起剖析Linux内核中那些堪称典范的设计:VFS、伙伴系统与SLAB、完全公平调度器(CFS)、RCU锁机制、革命性的eBPF,以及构成容器技术的Namespace与Cgroups。
一、VFS与“一切皆文件”的哲学
对于习惯Windows系统的用户来说,文件、注册表、网络连接和硬件设备是截然不同的概念。但Linux内核通过一层巧妙的抽象,直接抹平了这些资源之间的差异,其核心理念就是:一切皆文件。
这背后的本质,其实是提供了一套统一的接口。无论底层资源究竟是什么,Linux都向用户空间提供标准的系统调用:
open():打开资源。read():读取数据。write():写入数据。close():关闭资源。ioctl():控制设备特有参数。
为了实现“一切皆文件”,Linux引入了VFS(Virtual File System,虚拟文件系统)。VFS是内核中的一个软件层,它位于用户程序与具体文件系统(如Ext4、XFS)之间,扮演着抽象和调度的角色。
整个系统的分层架构如下图所示:
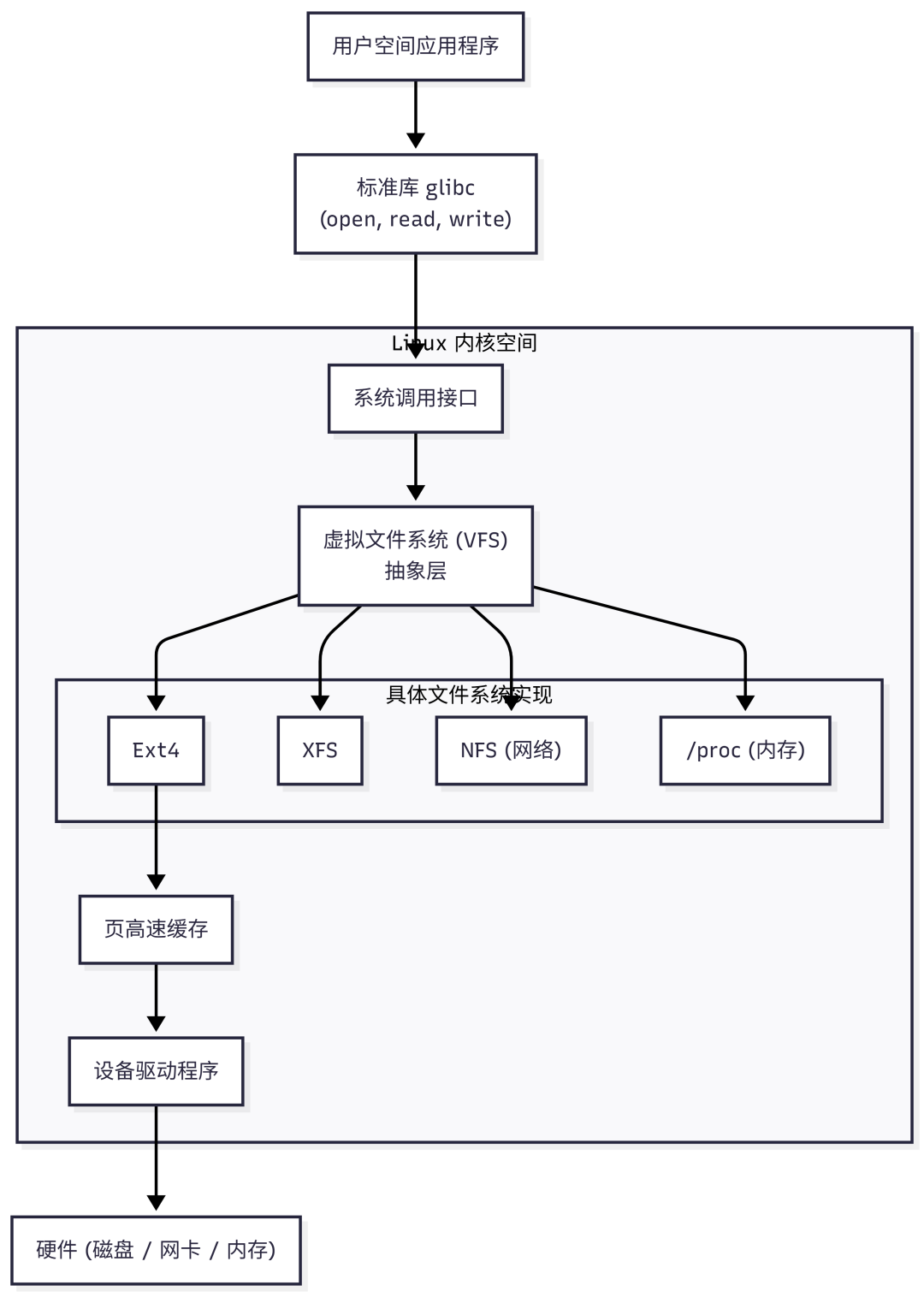
VFS的设计思想非常类似于面向对象编程中的多态。
- VFS定义了一套通用的接口(可以看作是基类)。
- 具体的文件系统(如Ext4、NTFS)必须实现这些接口(相当于子类)。
- 应用程序只需要调用VFS提供的接口,完全无需关心底层是哪个具体的文件系统在工作。
Linux内核虽然用C语言编写,但它通过结构体(struct)巧妙地模拟了面向对象的“类”概念。VFS的核心对象包括:
-
超级块(struct super_block):
- 代表一个已挂载的文件系统。例如,当你将一个U盘挂载到
/mnt 目录时,内核就会创建一个超级块对象。
- 包含信息:文件系统的类型(是FAT32还是Ext4?)、块大小、总大小、根目录的位置等。
- 方法:例如
alloc_inode(创建一个新的inode)、write_inode(将inode写回磁盘)。
-
索引节点(struct inode):
- 代表文件本身(物理上的文件实体)。
- 包含信息:文件的元数据,包括权限、所有者、文件大小、时间戳,以及最重要的——数据块在磁盘上的位置。
- 重要:Inode不包含文件名!它只是一个唯一的数字标识。
- 方法:通过
inode_operations 结构体定义,例如 create(创建文件)、mkdir(创建目录)、lookup(查找目录项)。
-
目录项(struct dentry):
- 代表路径。它充当了文件名与Inode之间的桥梁。
- 包含信息:文件名、指向对应Inode的指针、指向父目录的指针。
- 目的:加速路径查找。Linux维护了一个Dentry Cache(dcache),
dentry 对象常驻内存,可以快速地将路径字符串映射到对应的inode。
-
文件对象(struct file):
- 代表进程打开的一个文件实例。
- 包含信息:当前读写位置(f_pos) 是最关键的。两个进程打开同一个文件,内核会创建两个独立的
file 对象,各自维护自己的读写偏移。此外,还包含指向 dentry 的指针、文件的打开模式(只读/读写)等。
- 方法:通过
file_operations 结构体定义,包含 read、write、fsync、mmap 等操作。
这些内核对象之间的关系,可以通过以下结构和图示清晰地展现:
进程 (Process)
|
文件描述符表 (fd table)
[0: stdin ]
[1: stdout]
[2: stderr]
[3: fd] ----> struct file (文件对象)
|-- f_pos: 1024 (当前读到哪了)
|-- f_op: ext4_file_operations (操作函数表)
|-- f_path.dentry ------------------------+
|
v
struct dentry (目录项)
|-- d_name: "a.txt"
|-- d_inode -----------+
|
v
struct inode (索引节点)
|-- i_ino: 34211 (ID)
|-- i_size: 2048
|-- i_op: ext4_inode_ops
|-- 磁盘块映射: [Block 100, Block 101]
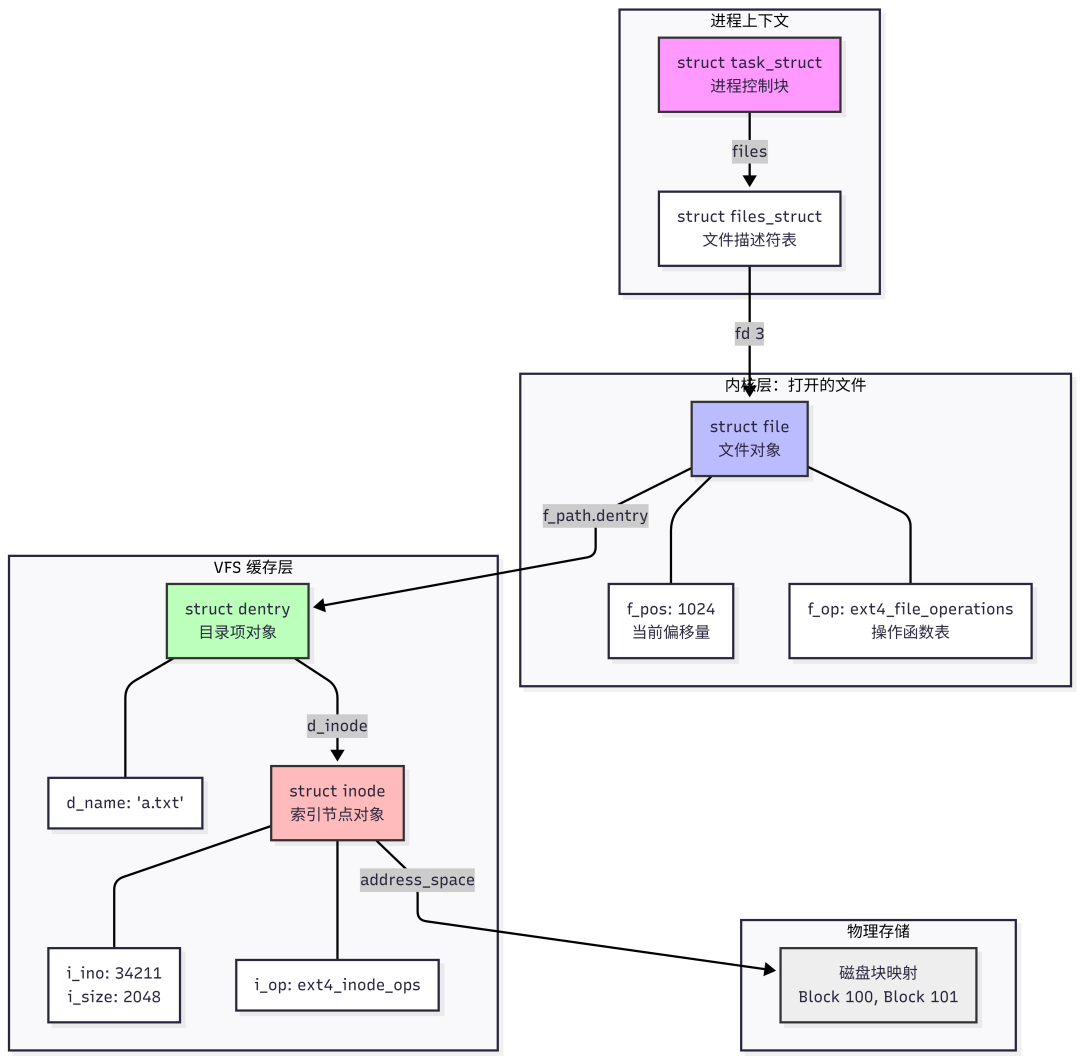
当我们调用 read(fd, buf, 100) 时,内核内部发生了一系列精密的协作:
- CPU触发软中断(即系统调用),从用户态切换到内核态。
- 内核根据传入的文件描述符
fd,在当前进程的“文件描述符表”中找到对应的 struct file 对象。
- VFS检查该文件是否以“读”模式打开。然后,VFS调用
struct file 中的 f_op->read 函数指针。如果底层是Ext4文件系统,就调用 ext4_file_read_iter;如果是Socket,则调用 sock_read_iter。
- 如果是Ext4,驱动会通过
struct file 找到 dentry,再找到 inode。通过 inode 中的磁盘块映射表,计算出文件偏移量对应的物理磁盘块号。
- 内核首先检查这些数据是否已经在页高速缓存(Page Cache)中。如果命中,则直接从内存拷贝到用户提供的
buf,这个过程极快,无需访问磁盘。如果未命中,则发起一个BIO(Block I/O)请求。
- BIO请求会被放入I/O调度队列(进行排序、合并等优化),最终由磁盘驱动程序控制磁头读取物理数据,并通过DMA(直接内存访问)传送到内存中。
二、内存管理:伙伴系统与SLAB/SLUB
高效的内存管理是任何操作系统的核心。Linux内核需要解决两个经典的内存碎片问题:
- 外部碎片:内存还有剩余空间,但都是零散的小块,无法满足大块连续内存的申请。
- 内部碎片:应用程序可能只需要50字节,但系统分配的最小单位是4KB(一页),导致实际浪费了4046字节。
Linux的解决方案是:用伙伴系统(Buddy System)解决外部碎片,用SLAB/SLUB分配器解决内部碎片。
伙伴系统直接管理物理内存页(通常为4KB一页),其主要任务是分配连续的物理页框。它并非按字节管理,而是按“阶”(Order)来管理。内核维护了11个链表(Order 0 ~ Order 10):
- Order 0 链表:存放大小为 2^0 = 1 页(4KB)的空闲块。
- Order 1 链表:存放大小为 2^1 = 2 页(8KB)的空闲块。
- ...
- Order 10 链表:存放大小为 2^10 = 1024 页(4MB)的空闲块。
分配流程示例:假设需要申请 3页 内存。
- 系统会向上取整到2的幂,即申请 4页(对应Order 2)。
- 系统检查 Order 2 链表,如果有空闲块,直接分配。
- 如果没有,则向上一级 Order 3(8页)链表寻找。
- 如果在Order 3找到空闲块,内核会将其一分为二,切成两个4页的块。其中一个分配给请求者使用,另一个4页块(称为“伙伴”)则插入回 Order 2 链表。
释放流程:当释放这4页内存时:
- 内核会计算这块内存的“伙伴”块的地址。
- 检查“伙伴”块是否也处于空闲状态。
- 如果是,则将这两块4页内存合并成一个8页的大块,放入 Order 3 链表。
- 这个过程会递归向上进行,直到无法继续合并为止。
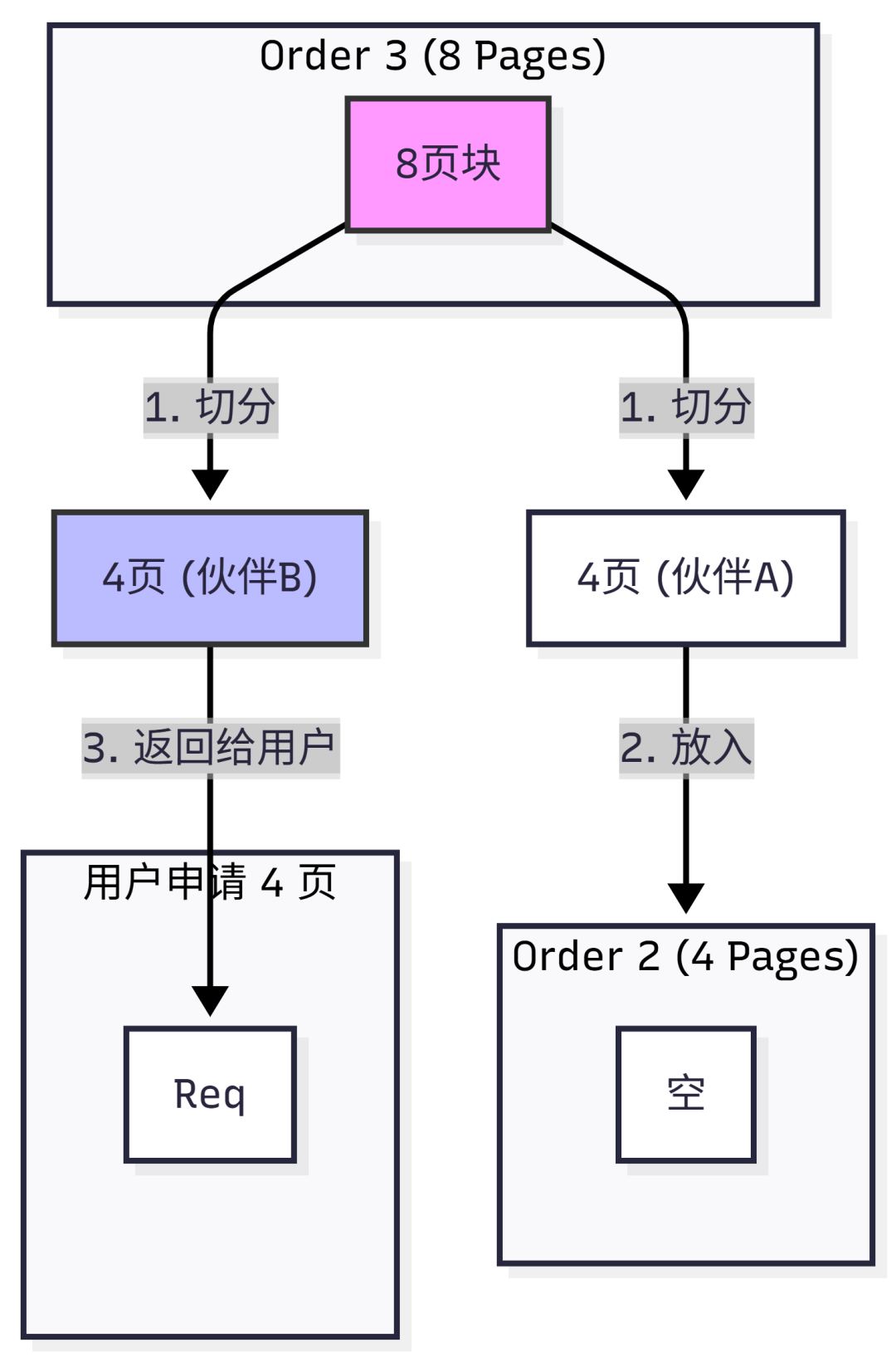
然而,伙伴系统的最小单位是4KB一页。内核中存在着大量微小的对象,例如 task_struct、inode 等,它们的大小往往只有几百字节。如果直接使用伙伴系统为每个小对象分配一页,将造成巨大的内部碎片浪费。
SLAB/SLUB正是专门针对小对象的“对象池”技术。SLAB分配器包含三个层级:
- Cache(高速缓存):每种特定类型的对象都有一个专属的Cache。例如,存在一个专门存放
task_struct 的Cache,另一个专门存放 inode 的Cache。
- Slab(内存块):每个Cache包含多个Slab。一个Slab由连续的几个物理页组成(这些页是从伙伴系统申请来的)。
- Object(对象):Slab被切分成无数个固定大小的小格子,每个格子就是一个Object,用于存放具体的对象实例。
每个Cache维护三个链表,对应Slab的三种状态:
- Slabs Full:所有Object都已被使用,没有空位。
- Slabs Partial:部分Object被使用,还有空位。(分配时优先从这里选择!)
- Slabs Empty:所有Object都空闲。(当系统内存紧张时,这些Slab可能会被整体返还给伙伴系统)。
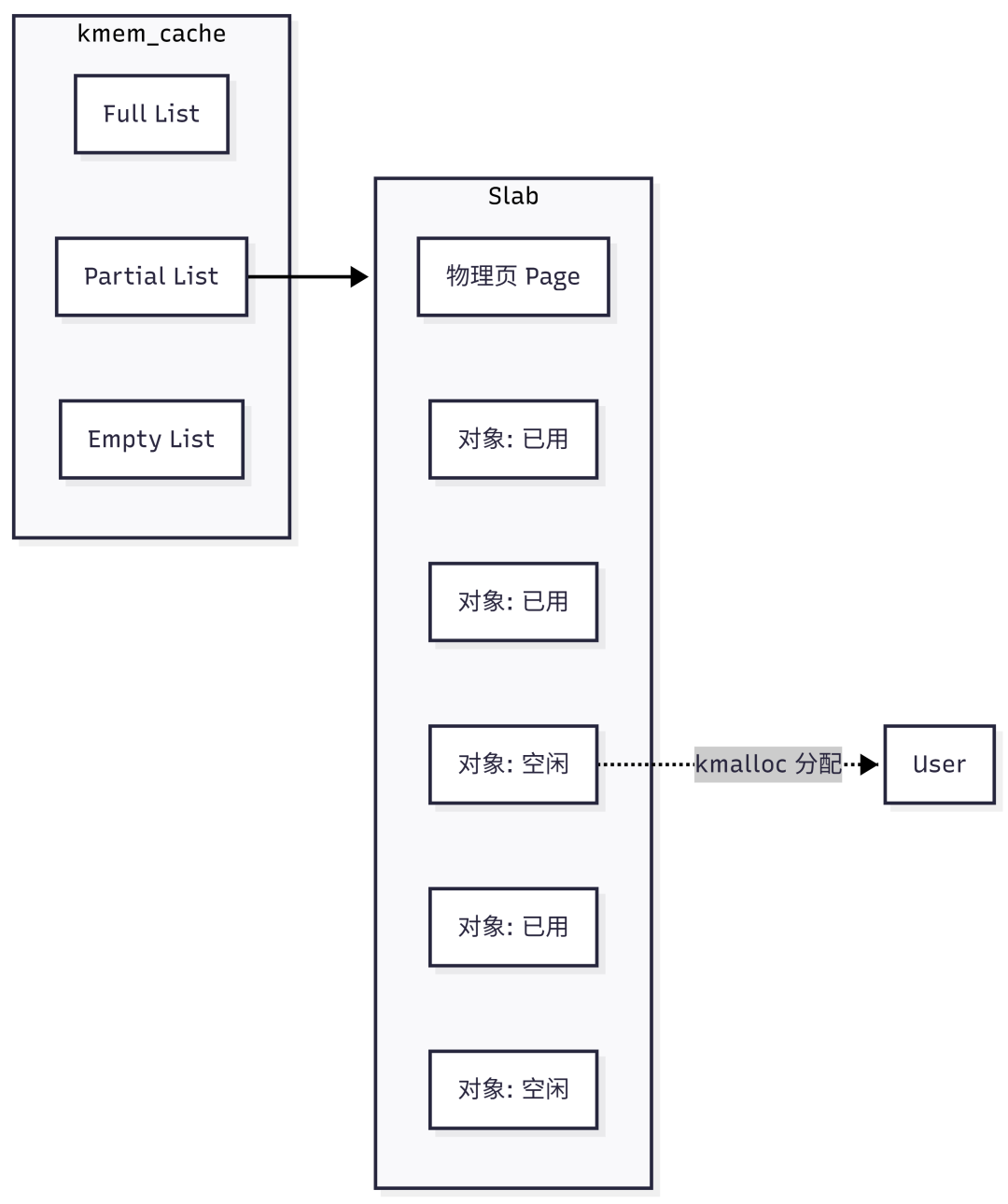
SLAB、SLUB、SLOB是同一套逻辑的不同实现版本:
- SLAB:最早的经典设计。结构相对复杂,元数据存放在Slab内部,内存开销稍大,对CPU缓存队列的管理也较复杂。
- SLUB (Unqueued SLAB):目前绝大多数Linux发行版的默认选择。它是SLAB的简化版,去除了复杂的队列,将元数据直接嵌入
struct page 结构体中(复用了页描述符的字段),显著节省了内存,并且对多核CPU更加友好。
- SLOB:极度简化的版本,专门为内存极小的嵌入式系统设计。
三、进程调度:从O(1)到完全公平调度器(CFS)
进程调度器是操作系统的核心组件,它决定了CPU时间如何在众多进程间分配。Linux 2.4时代的调度器是O(n)算法,随着进程数量增多,调度器需要遍历所有进程来选择下一个运行者,效率低下。
Ingo Molnar设计的O(1)调度器完美解决了这个问题。无论系统中有多少个进程,它都能在恒定时间内找到下一个该运行的进程。
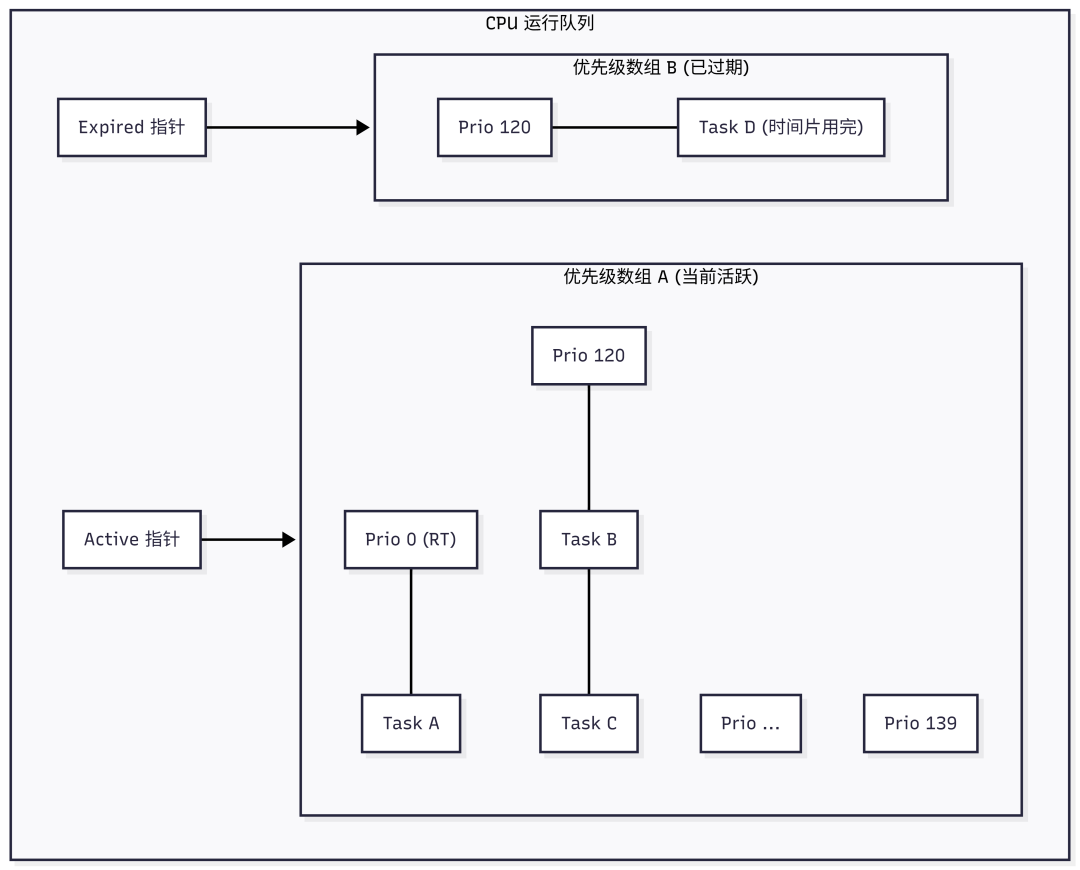
O(1)调度器为每个CPU维护一个运行队列,队列中包含两个关键数据结构:
- Active数组:存放仍有剩余时间片、等待运行的进程。
- Expired数组:存放时间片已用完、等待下一轮调度的进程。
每个数组本质上是一个包含140个链表的数组(对应0-139共140个优先级)。
- 优先级0-99:分配给实时进程。
- 优先级100-139:分配给普通进程。
此外,还有一个位图(Bitmap),每一位对应一个优先级链表。如果某个优先级的链表非空,对应的位就被置为1。
调度流程:
- 查找进程:调度器无需遍历链表。它使用CPU的硬件指令快速扫描位图,直接找到第一个非空的优先级链表(即当前最高优先级的待运行进程)。
- 执行:取出该链表头的进程投入运行。
- 时间片耗尽:进程用完时间片后,内核会重新计算其优先级,然后将其放入 Expired数组 中。
- 数组交换:当 Active数组 中的所有进程都执行完毕(变为空)时,调度器只需简单地交换 Active 和 Expired 两个数组的指针。这样一来,刚才所有过期的进程又变成了活跃进程,开始新一轮调度。
O(1)调度器在服务器(追求吞吐量)场景下表现优异,但在桌面(追求交互响应)场景下则不尽如人意。为了确保视频播放、鼠标移动等交互进程流畅,调度器需要“猜测”哪些进程是交互式的,并动态提升其优先级。但问题在于,像编译器这类后台进程的某些行为模式与交互进程相似,导致调度器的猜测逻辑变得极其复杂且难以维护,还经常出错。
于是,Ingo Molnar(同一位大神,革了自己的命)在Linux 2.6.23中引入了完全公平调度器(CFS)。
CFS基于一个理想化的模型:一台可以无限细分的CPU。如果有N个进程,那么在任意时刻,每个进程都应该获得1/N的CPU处理能力。当然,现实中的CPU一次只能运行一个进程。因此,CFS的目标就是模拟这种“完美公平”。
CFS引入了一个核心概念:vruntime(虚拟运行时间)。
- 定义:进程在CPU上已经运行的、经过权重调整后的“虚拟”时间。
- 计算公式:
vruntime += 实际运行时间 * (NICE_0_WEIGHT / 进程权重)
- 对于普通进程(权重为1),
vruntime 的增加值等于实际运行时间。
- 对于高优先级进程(权重较大),运行100ms,
vruntime 可能只增加50ms(虚拟时间过得慢,在调度队列中向右移动得慢,从而能获得更多实际CPU时间)。
- 对于低优先级进程(权重较小),运行100ms,
vruntime 可能增加200ms(虚拟时间过得快,更快地让出CPU)。
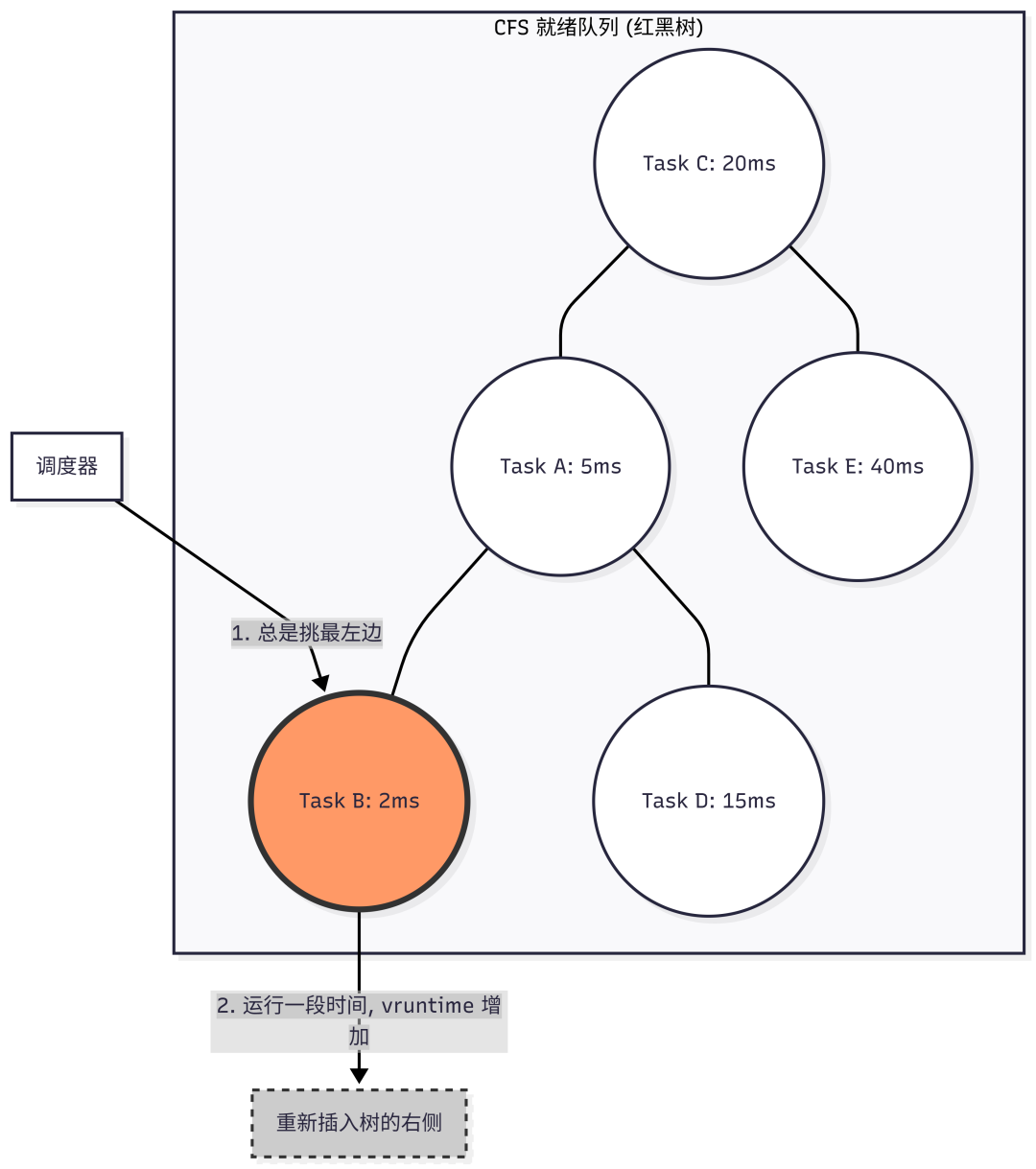
CFS的调度准则非常简单:永远选择 vruntime 最小的进程来运行。
CFS不再使用优先级数组,而是用一棵按 vruntime 排序的红黑树来组织所有可运行的进程。
- 树的左侧:
vruntime 较小的进程(更“饥饿”,更缺CPU)。
- 树的右侧:
vruntime 较大的进程(刚运行过,不太缺CPU)。
调度流程:
- 调度器总是选择红黑树最左侧的节点(即
vruntime 最小的进程)来运行。
- 进程运行期间,时钟中断会不断更新并增加其
vruntime。
- 随着
vruntime 增大,该进程在红黑树中的逻辑位置会逐渐向右移动。一旦内核发现树中存在比当前运行进程 vruntime 更小的节点,当前进程就会被抢占。
- 被抢占的进程会根据其新的
vruntime 值,被重新插入红黑树中的正确位置。
| 特性 |
O(1) 调度器 |
CFS (完全公平调度器) |
| 核心结构 |
两个优先级数组 (Active/Expired) |
红黑树 (Red-Black Tree) |
| 时间复杂度 |
O(1) (常数级,极快) |
O(log N) (对数级,稍慢但可忽略) |
| 调度依据 |
优先级 + 时间片 |
虚拟运行时间 (vruntime) |
| 交互性处理 |
靠猜测 (启发式算法,动态奖励) |
交互进程常睡眠,vruntime增长慢,唤醒后自然排到左侧 |
| 公平性 |
粗粒度的公平 |
纳秒级的精确公平 |
| 代码逻辑 |
复杂,包含大量启发式代码 |
简洁,基于清晰的数学模型 |
四、同步机制:RCU(读-拷贝-更新)
RCU(Read-Copy-Update)是一种巧妙的同步机制,主要为了解决读写锁在多核CPU环境下的性能瓶颈。
读写锁的逻辑是:允许多个读者同时进入临界区,但写者必须独占访问。虽然读者之间不互相阻塞,但它们必须修改同一个锁的引用计数器。这在多核CPU上会引发严重的缓存行颠簸问题:当一个CPU核心修改了锁状态,其他所有核心上对应的缓存行都会失效,需要从内存重新加载。结果就是,即使没有写者,大量并发的读者也会因为争抢这个共享的计数器而导致性能随着CPU核心数增加而断崖式下跌。
RCU的精妙之处在于,它让读者完全没有任何同步开销——不拿锁、没有原子操作、甚至不需要内存屏障。
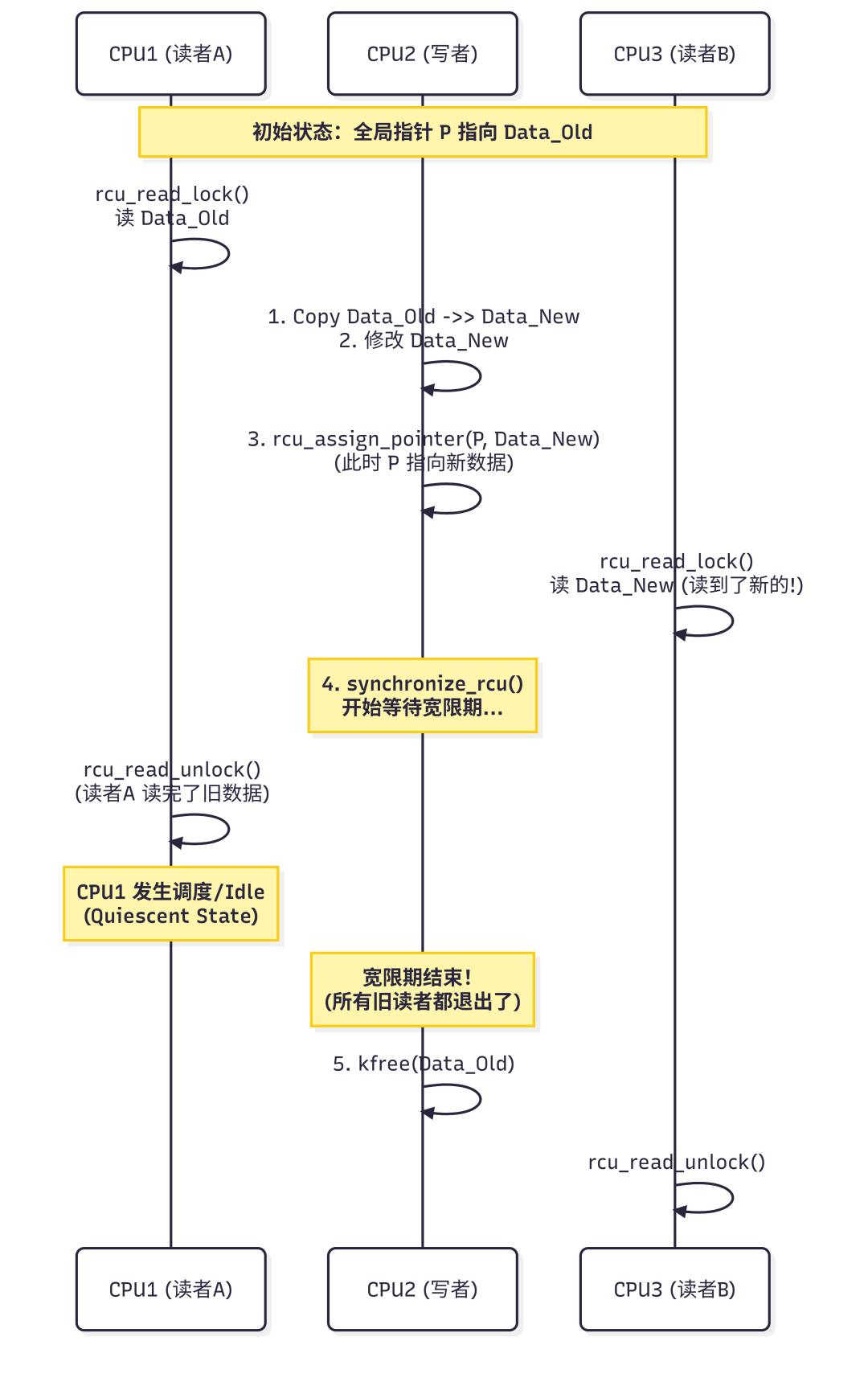
RCU的名称概括了其三个核心步骤:
- Read(读):读者直接读取数据,不做任何加锁动作。
- Copy(拷贝):写者需要修改数据时,并不直接修改原数据,而是先拷贝一份副本。
- Update(更新):写者在副本上完成修改后,通过一个原子性的指针操作,将全局指针指向新的副本。
听起来简单,但最大的挑战是:旧的数据什么时候才能安全删除? 因为在新指针替换后,可能还有读者正在读取旧数据(它们进入读侧临界区时指针尚未更新)。如果写者立刻释放旧内存,这些读者就会访问到已释放的内存,导致崩溃。
RCU通过“延迟释放”和“宽限期(Grace Period)”机制来解决这个问题。
读者的代码非常简单:
rcu_read_lock(); // 1. 标记进入读临界区
p = rcu_dereference(global_ptr); // 2. 安全地获取指针
if (p != NULL) {
do_something(p->data); // 3. 读取数据
}
rcu_read_unlock(); // 4. 标记退出读临界区
注意:在 rcu_read_lock() 和 rcu_read_unlock() 构成的读临界区内,进程不能发生上下文切换(不能睡眠)。
写者的实现逻辑如下:
// 1. 分配新内存
new_p = kmalloc(...);
// 2. Copy:拷贝旧数据到新内存
memcpy(new_p, old_p, ...);
// 3. Modify:修改新内存中的数据
new_p->field = new_value;
// 4. Update:原子地替换全局指针,新读者将看到新数据
rcu_assign_pointer(global_ptr, new_p);
此时,写者不能立即 kfree(old_p),必须等待。
// 5. 等待宽限期结束
synchronize_rcu();
// 6. 此时,绝对没有读者还在引用old_p了,安全释放
kfree(old_p);
宽限期是指:从指针被替换的那一刻起,到所有在替换前就已经开始的读操作全部结束为止的这段时间。
RCU依赖于一个关键事实:读者在 rcu_read_lock() 和 unlock() 之间禁止被调度,但在这个区域之外,进程一定会发生上下文切换(例如系统调用、时钟中断)。因此,内核只需要检测到所有CPU核心都至少经历了一次上下文切换(或进入了一次Idle状态),就可以断定:所有CPU上旧的读临界区肯定都已经结束了。此时,宽限期结束,旧数据可以安全回收。
synchronize_rcu() 是阻塞调用,写者需要等待。为了不阻塞写者,Linux提供了异步接口 call_rcu()。写者可以将释放旧内存的操作封装成一个回调函数,将其挂入一个链表后立即返回。内核在检测到宽限期结束后,会通过软中断或内核线程批量执行这些回调函数,从而实现内存的异步回收。
五、eBPF:内核的可编程性革命
eBPF(Extended Berkeley Packet Filter) 被认为是Linux内核过去十年最具革命性的技术之一。在eBPF之前,想要修改或扩展内核行为,只有两种高风险途径:1) 修改内核源码并重新编译;2) 编写内核模块(容易导致系统崩溃或安全漏洞)。
eBPF的核心价值在于,它允许用户在不修改内核源码、不重启系统的前提下,安全地向内核注入自定义的执行逻辑。
eBPF本质上是一个运行在Linux内核中的寄存器式虚拟机。一个eBPF程序从开发到运行,需要经历以下步骤:
- 编写:使用C语言编写eBPF程序代码。
- 编译:使用LLVM/Clang编译器,将C代码编译成eBPF字节码。
- 加载:通过
bpf() 系统调用,将字节码传递给内核。
- 验证:内核中的验证器(Verifier) 会对字节码进行极其严格的安全检查,包括:确保程序无无限循环、无非法内存访问、无未初始化变量读取等,从根源上保证内核安全。
- JIT编译:通过验证后,内核的JIT(Just-In-Time)编译器会将eBPF字节码实时编译成本地机器码,以获得近乎原生代码的执行性能。
- 挂载:将编译好的程序挂载到指定的钩子点(Hook) 上,例如网络数据包路径、系统调用入口、内核跟踪点等。
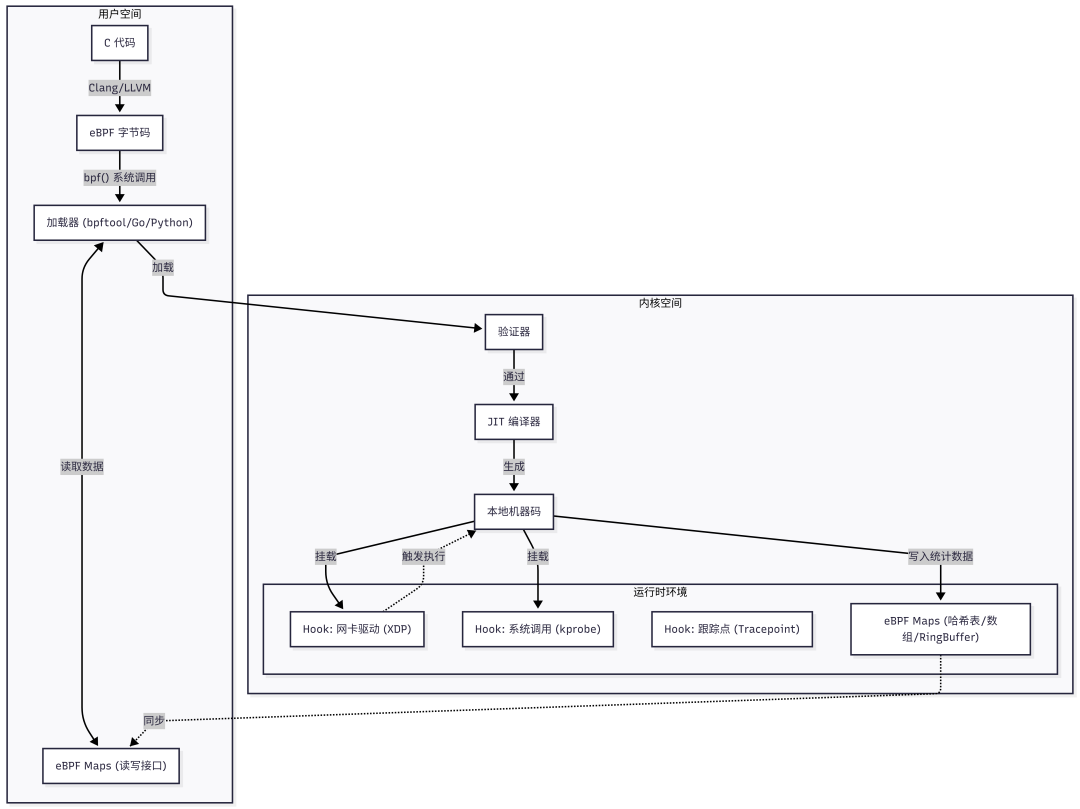
eBPF程序运行在内核态,而控制程序或需要获取数据的应用运行在用户态,它们之间如何通信?答案是 eBPF Maps。Maps是一种内核提供的、可被用户态和内核态eBPF程序共同访问的键值对存储结构,用于双向数据交换。
出于安全考虑,eBPF程序不能随意调用任何内核函数。内核提供了一份安全的辅助函数(Helper Functions) 白名单,例如:
bpf_ktime_get_ns():获取当前时间戳。bpf_trace_printk():打印调试信息(输出到trace_pipe)。bpf_map_lookup_elem():在Map中查找键值对。
六、容器基石:Namespace与Cgroups
Namespace的本质是一种“视错觉”机制。它通过修改进程的“视图”,让一组进程“以为”自己独占了整个操作系统的资源。
如果没有隔离,所有进程共享全局资源:都能看到所有其他进程(PID)、共享同一个网络栈(IP和端口)、共享相同的文件系统挂载点。这极易引发冲突。Namespace就是为了解决这一问题而生的。
Linux内核提供了六种核心的Namespace类型:
| Namespace 类型 |
隔离资源 |
效果描述 |
| PID |
进程ID |
容器内的进程认为自己PID是1(init进程),但在宿主机上其真实PID可能很大。 |
| NET |
网络栈 |
容器拥有独立的虚拟网卡、IP地址、路由表、防火墙规则等。 |
| MNT |
文件系统挂载点 |
容器内看到的文件目录树是独立的,挂载操作不影响宿主机。 |
| UTS |
主机名与域名 |
容器可以设置自己的主机名(hostname)。 |
| IPC |
进程间通信 |
容器内的进程无法通过System V IPC或POSIX消息队列与宿主机进程通信。 |
| USER |
用户和组ID |
容器内的root用户(UID 0),在宿主机上可能只是一个普通用户(UID 1000),增强了安全。 |
其中,PID Namespace是最具代表性的。它为进程创建了独立的PID编号体系,内核维护着宿主机PID与容器内虚拟PID的映射关系。
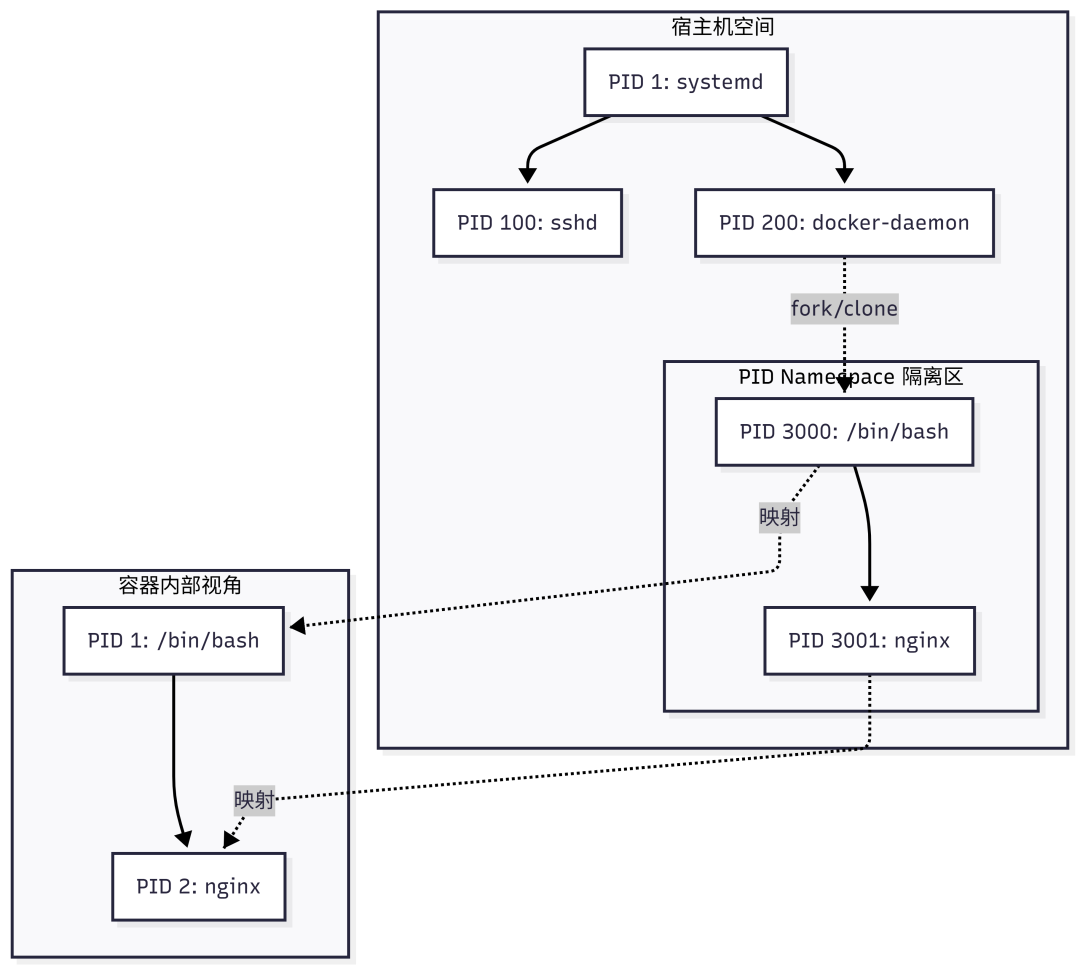
仅有隔离还不够。如果一个容器内的进程疯狂消耗宿主机内存或CPU,仍然会导致整个系统不稳定。Cgroups(Control Groups) 正是用来进行资源限制和核算的机制。
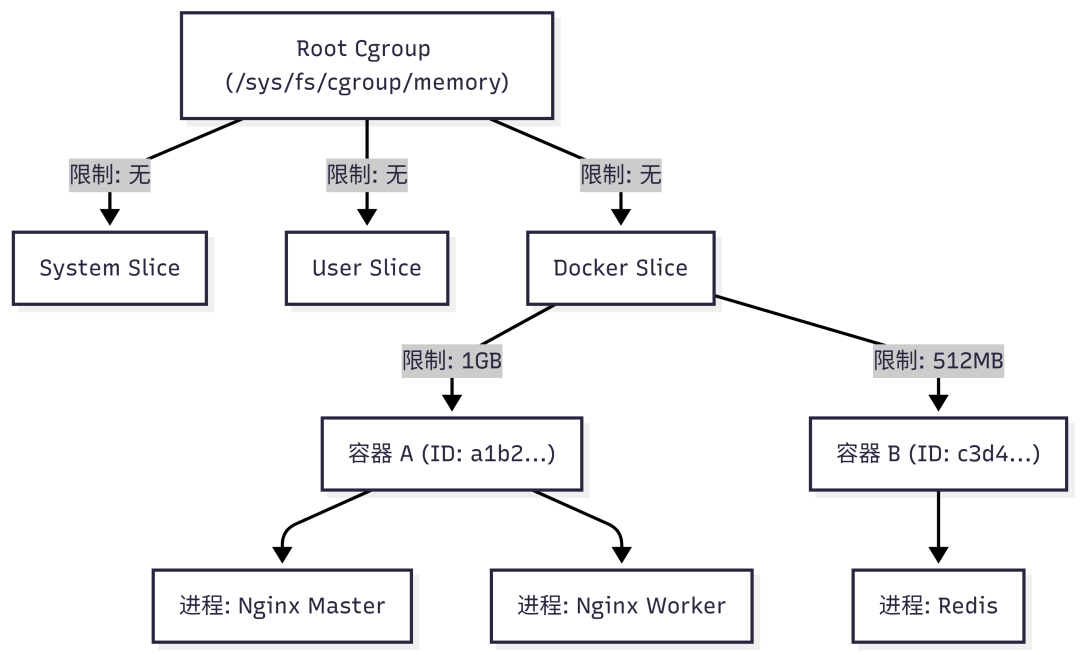
Cgroups允许将一组进程组织成层次化的结构,并对树中的每个节点(控制组)施加资源限制。它以文件系统的形式暴露给用户,通常挂载在 /sys/fs/cgroup 下。其主要子系统包括:
- cpu:限制CPU使用率。例如通过
cpu.cfs_quota_us 设定在周期内能使用的CPU时间微秒数。
- memory:限制内存使用量。通过
memory.limit_in_bytes 设定上限,超出限制的进程可能会被OOM Killer终止。
- blkio:限制块设备I/O。可以控制读写速率(IOPS或带宽),防止某个容器拖垮整个磁盘I/O。
- pids:限制进程数量。有效防止“Fork Bomb”攻击(进程无限自我复制耗尽PID资源)。
Cgroups的结构是一个树状目录,从根Cgroup向下可以创建子Cgroup,资源限制可以继承和叠加。
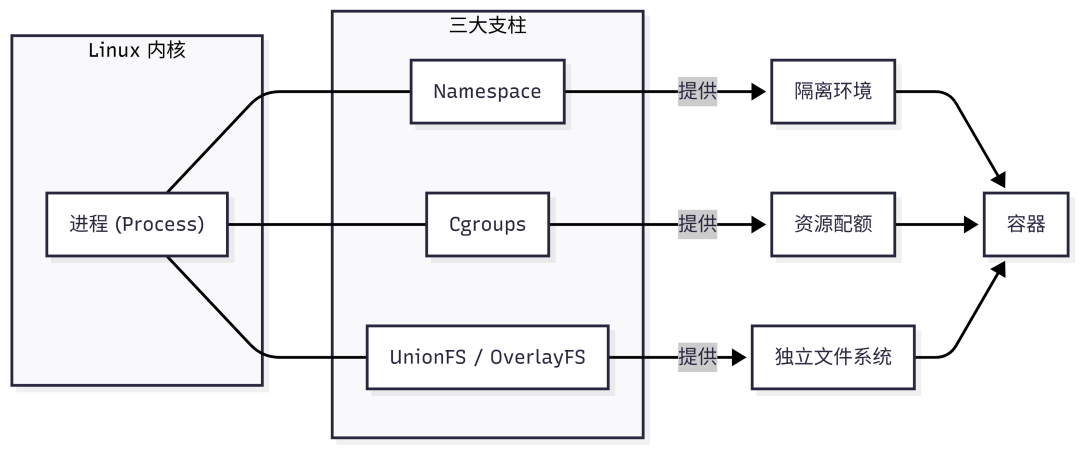
现在,我们可以理解一个“容器”在Linux内核眼中的真相了:它根本不是一个特殊的魔法对象!
内核中并没有一个叫做 struct container 的数据结构。一个Docker容器,本质上只是一个(或一组)普通的Linux进程。只不过这个进程:
- 被Namespace隔离了视野(独立的PID、网络、文件系统视图)。
- 被Cgroups限制了资源使用(CPU、内存配额)。
- 通过OverlayFS这类联合文件系统,拥有一个独立的、分层的根文件系统。
这三者结合,就构成了我们熟知的“容器”。
这也就是为什么Linux容器比虚拟机(VM)轻量得多的根本原因:没有虚拟硬件开销,没有运行一个完整的Guest OS内核,它仅仅是宿主机上一个被精心隔离和限制的普通进程而已。
七、统一设备模型与Sysfs
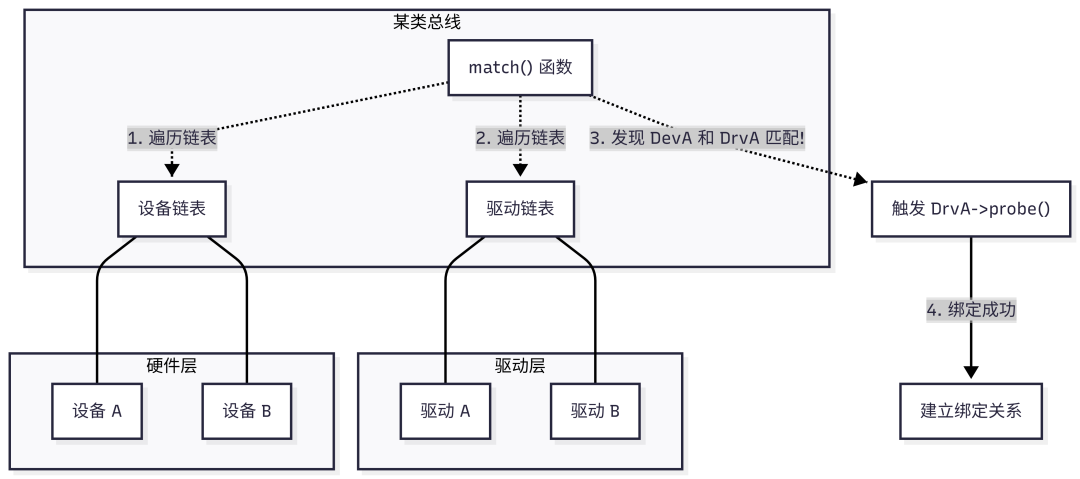
为了管理日益复杂的硬件,Linux内核设计了统一设备模型,将硬件抽象为三个核心实体:Bus(总线)、Device(设备)、Driver(驱动)。
总线是CPU与设备之间通信的通道。内核中的总线对象也是一个容器,它维护两个链表:
- 设备链表:挂载在该总线上的所有物理设备。
- 驱动链表:所有向该总线注册的驱动程序。
当有新设备插入(如热插拔USB)或新驱动加载时,总线核心会遍历这两个链表,调用驱动的 match() 函数,尝试为设备找到匹配的驱动。
- 设备:代表物理存在的硬件实体。
- 驱动:代表控制该硬件的软件逻辑。
为了实现这套模型,内核引入了一个基础对象——Kobject。可以将其理解为面向对象语言中的基类 Object。Kobject提供了:
- 引用计数:跟踪对象被引用的次数,确保无人使用时才释放内存。
- 层次结构:通过
parent 指针形成树状结构,直观反映设备、总线间的归属关系。
- Sysfs接口:每个Kobject都在sysfs文件系统中对应一个目录。
Sysfs是一个基于内存的虚拟文件系统,通常挂载在 /sys 目录下。它不存储实际的文件数据,而是作为内核数据结构面向用户空间的“窗口”。
/sys 目录下的文件和目录,实际上是内核变量和对象关系的接口。
- 读文件:会触发内核对象对应的
show() 函数,将内核变量的值格式化成字符串返回给用户。
- 写文件:会触发
store() 函数,将用户传入的字符串解析为参数,用于修改内核状态或配置。
通过sysfs,系统管理员和开发者可以直观地查看系统设备拓扑、驱动状态,甚至动态调整某些内核参数(如电源管理策略),这为系统管理和调试提供了极大的便利。
从VFS的统一抽象,到CFS的公平调度,再到eBPF带来的内核可编程性飞跃,Linux内核的每一个核心设计都体现了简洁、高效和可扩展的哲学。理解这些底层机制,不仅能帮助我们更好地使用Linux系统,更能深刻领悟计算机系统设计的精髓。希望这篇剖析能为你打开一扇深入理解Linux内核的窗口。如果你对某个技术点有更深的兴趣,欢迎在云栈社区继续交流探讨。
 发表于 2026-3-5 16:33:06
|
查看: 145|
回复: 0
发表于 2026-3-5 16:33:06
|
查看: 145|
回复: 0
