在C++面试中,std::map和std::unordered_map的性能对比是一个高频考点。很多候选人可能会脱口而出“哈希表更快”,但如果你只停留在这一步,很可能就错过了展示技术深度的机会。实际情况要复杂得多,性能优劣与具体的使用场景和数据规模紧密相关。
一、底层实现原理对比
std::map:红黑树的优雅平衡
std::map的底层实现是红黑树,这是一种自平衡的二叉搜索树。红黑树通过以下五条规则维持平衡,确保了操作的稳定效率:
- 每个节点要么是红色,要么是黑色。
- 根节点必须是黑色。
- 所有叶子节点(nil节点)均为黑色。
- 若一个节点是红色,则其两个子节点必须是黑色。
- 从任意节点到其所有后代叶子节点的路径上,黑色节点的数量相同。
正是这些规则,确保了红黑树始终保持近似平衡状态,从而保证树的高度始终在$O(\log N)$级别。每个红黑树节点不仅存储键值对,还需要维护左右子节点指针、父节点指针和颜色标记。
// 红黑树节点结构示例
template<typename Key, typename Value>
struct map_node {
Key key;
Value value;
map_node* left;
map_node* right;
map_node* parent; // 父指针,便于旋转操作
bool is_red; // 颜色标记
};
std::unordered_map:哈希表的高效映射
std::unordered_map的底层实现是哈希表。现代的C++标准库实现(如GCC的libstdc++和Clang的libc++)通常采用“数组+链表/红黑树”的组合结构,这与Java的HashMap优化思路类似。
当单个桶(bucket)中的元素数量超过一个阈值(通常是8个)时,会自动将链表转换为红黑树,以此来优化最坏情况下的性能,防止因哈希冲突严重导致的链表过长问题。
// 哈希表节点结构示例
template<typename Key, typename Value>
struct hash_node {
Key key;
Value value;
hash_node* next; // 指向同桶中的下一个节点
size_t hash; // 缓存哈希值,避免重复计算
};
二、内存布局与性能特性
红黑树内存布局
红黑树的节点在内存中是分散存储的,通过指针链接形成树形结构。每个节点的结构相对紧凑,但为了维护树的平衡(旋转、变色),需要额外的指针(父指针)和状态位。这种设计导致其缓存局部性(Cache Locality)较差,因为相关的节点在物理内存上不一定相邻。
哈希表内存布局
哈希表的核心是一个连续的桶数组,每个数组元素是一个指针,指向一个链表(或红黑树)。这种布局的优点是:计算出的哈希值可以直接映射到数组索引,进行快速定位。然而,其内存占用波动较大,且当负载因子(元素数量/桶数量)超过阈值(如0.75)时,会触发扩容(Rehash),这个过程需要重新分配数组、对所有元素重新哈希并放置,可能导致所有迭代器失效。
为了更直观地理解这两种数据结构的内部逻辑,可以参考下面的示意图:
三、不同数据量下的性能表现
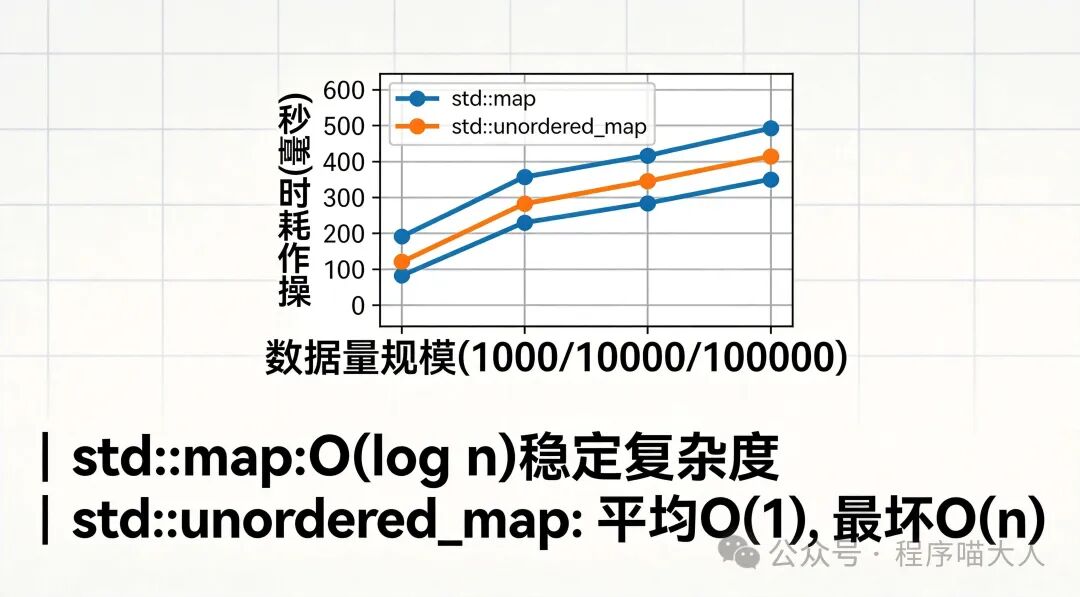
脱离数据规模谈性能都是不准确的。我们来看一个典型的性能对比趋势。
几百~几千条数据
在这个规模下,两者的性能差异几乎可以忽略不计。无论是查找还是插入,单次操作的耗时都在纳秒到微秒级。此时,选择哪一个更多是基于功能需求(是否需要有序)而非性能。
1万~10万条数据
差异开始显现。由于std::map是$O(\log N)$的复杂度,而std::unordered_map在理想情况下是$O(1)$,此时unordered_map的优势会慢慢体现出来。在实测中,其单次操作耗时可能只有map的1/5到1/3。
10万条及以上数据
在这个量级,std::unordered_map的性能优势往往是压倒性的。随着$N$的增大,$\log N$的增长会越来越明显,而设计良好的哈希表依然能维持接近常数的访问时间。两者的性能差距可能达到十倍甚至百倍。
下图展示了一个典型的性能测试结果,可以清晰地看到随着数据量增长,两者耗时曲线的分化趋势:
四、自定义类型作为键的踩坑指南
当你需要使用自定义结构体或类作为std::unordered_map的键时,必须提供两个东西:哈希函数和相等比较函数。这里是最容易出问题的地方。
常见问题
- 哈希冲突严重:自定义的哈希函数分布不均匀,导致大量不同的键被映射到同一个桶里,性能退化为$O(N)$的链表查找。
- 逻辑不一致:哈希函数和
operator==(或自定义的相等比较谓词)的逻辑不一致。例如,两个在operator==看来相等的对象,却计算出了不同的哈希值,这会导致无法在map中找到已插入的元素,引发严重bug。
- 哈希计算成本过高:对于字符串、复杂对象等,如果哈希函数计算耗时很长,可能会抵消掉$O(1)$查找带来的优势。
解决方案示例
一个良好实践是组合各成员的标准哈希值,并使用异或、移位等操作减少碰撞。
// 正确的自定义哈希函数示例
struct Person {
std::string name;
int age;
// 必须定义相等运算符
bool operator==(const Person& other) const {
return name == other.name && age == other.age;
}
};
namespace std {
template<>
struct hash<Person> {
size_t operator()(const Person& p) const {
size_t h1 = std::hash<std::string>{}(p.name);
size_t h2 = std::hash<int>{}(p.age);
// 异或结合位移,减少碰撞概率
return h1 ^ (h2 << 1);
}
};
}
// 之后就可以直接使用 std::unordered_map<Person, ValueType> 了
五、实际场景如何选择?
理解了原理和性能特征后,选择就变得清晰了。
选择 std::map 的场景
- 需要有序遍历:
std::map中的元素始终按照键升序排列(默认使用std::less),这对于需要按顺序输出的场景至关重要。
- 需要进行范围查询:例如,查找所有键在
[100, 200)区间内的元素,map的lower_bound和upper_bound方法可以高效完成。
- 对性能稳定性要求极高,无法接受最坏情况:
std::map保证最坏情况下也是$O(\log N)$,而unordered_map在最坏情况下(全部哈希冲突)会退化到$O(N)$。
- 内存占用相对可预测且通常更小:
map没有大数组和负载因子的概念,节点内存占用相对稳定。
选择 std::unordered_map 的场景
- 业务逻辑不关心顺序:这是使用
unordered_map的最大前提。
- 预期数据量会非常大,且以查找为主:在数据量巨大时,其平均$O(1)$的查找性能优势巨大。
- 可以提供高质量的、快速的哈希函数:确保键的类型有良好的
std::hash特化,或者可以自定义一个分布均匀的哈希函数。
- 能够接受扩容带来的迭代器失效和短暂性能抖动。
总结
回到最初的面试问题:std::map和std::unordered_map谁更快?一个专业的回答应该是:“看情况。”
- 如果需要元素有序、进行范围查询,或者追求绝对稳定的性能上限,
std::map(红黑树)是更可靠的选择。
- 如果对顺序没有要求,数据量较大或可能增长,并且能保证良好的哈希函数,那么
std::unordered_map在平均情况下会有显著的性能优势。
在面试中,清晰地阐述这种权衡,并展示你对底层数据结构和复杂度的理解,远比单纯回答“哈希表快”要加分得多。在真实的项目开发中,理解这些容器的特性也是进行性能优化和做出正确技术选型的基础。如果你正在准备 C++ 相关的技术面试,深入理解 STL 容器的特性是必不可少的环节,更多相关的深度讨论和实战经验,欢迎在 云栈社区 与广大开发者一起交流。
 发表于 2026-3-5 16:37:05
|
查看: 105|
回复: 0
发表于 2026-3-5 16:37:05
|
查看: 105|
回复: 0
