今天我们来聊聊 Go 社区备受瞩目的老生常谈的话题,也就是 encoding/json/v2 提案。很多同学可能早就注意到了,社区里关于 JSON v2 的呼声一直很高。
但目前它依然被隐藏在 GOEXPERIMENT=jsonv2 这个实验特性后面,没有作为稳定 API 正式发布。为了推进这个提案,Go 核心团队专门成立了一个 working group(工作组),这在 Go 标准库的演进历史上是非常少见的。
接下来和大家分享目前 Go JSON v2 的最新现状和工作组正在拉扯的痛点。
为什么我们需要 JSON v2?
在日常的 JSON 解析中,无论是做 Web 服务还是跨语言通信,这绝对是避不开的高频操作。
但是现有的 encoding/json (也就是 v1 版本)已经发布了十多年,存在好几个让人头疼的痛点。为了彻底解决这些历史包袱,Joe Tsai 等大佬提出了 Issue #71497 提案。
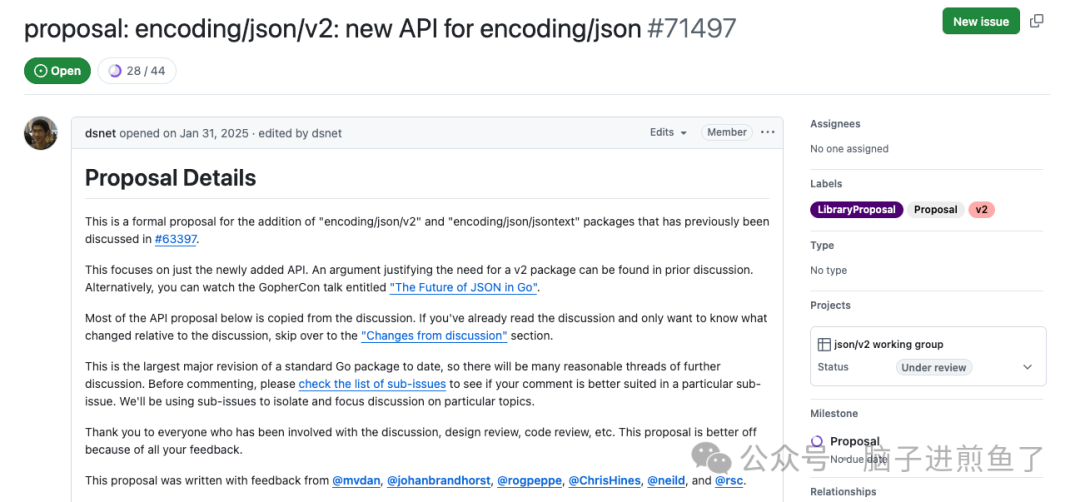
以下列举了几个核心问题:
- 性能不高:相比于
jsoniter 或者 go-json 等第三方高性能库,标准库在处理复杂嵌套结构时的性能一直被大家吐槽。
- 骚操作多:v1 版本有着许多让人迷惑的黑魔法。比如它会默默接受非法的 UTF-8 字符,面对 JSON 里的重复键值也不会报错而是静默覆盖。
- 报错信息少:当你解析一个巨大且多层嵌套的 JSON 字符串时,如果中间某个字段类型不匹配,v1 往往只会抛出一个含糊不清的错误,逼得大家只能靠肉眼去硬核排查。
JSON V2 提案概览
简单来说,这个新提案不是在旧代码上修修补补,而是直接做了一次大重构。
核心引入
核心上,引入了两个全新的标准库包:
encoding/json/jsontext :这是一个纯粹在语法层面处理 JSON 的底层包。它完全不依赖 Go 的反射机制,专注于 Token 的解析和流式处理,性能极高。encoding/json/v2 :这是我们普通开发者在业务中最常打交道的语义层面包。它基于 jsontext 构建,依然保留了大家熟悉的 Marshal 和 Unmarshal 函数,但内部机制焕然一新,带来了真正的零内存分配解码能力。
新旧写法对比
我们可以来看下新旧写法的直观对比。
举个例子,在旧版本中,如果我们想要拒绝带有未知字段的 JSON 报文,需要非常繁琐地去配置 Decoder 对象:
// v1 旧写法:必须实例化 Decoder 才能配置
var val MyStruct
decoder := json.NewDecoder(bytes.NewReader(data))
decoder.DisallowUnknownFields()
err := decoder.Decode(&val)
但是在 v2 的设计中,本质上就是通过高度灵活的 Option 模式来实现配置传递,代码变得非常清爽:
// v2 新写法:直接在 Unmarshal 中传入 Option
var val MyStruct
err := jsonv2.Unmarshal(data, &val, jsonv2.RejectUnknownMembers())
不仅如此,v2 还赋予了 struct tag 极其强大的表达能力。很多以前需要手写几十行自定义解析逻辑的场景,现在一个标签就能搞定:
type User struct {
// 明确指定时间格式和忽略空值的行为
CreatedAt time.Time `json:"created_at,format:RFC3339,omitempty"`
// 甚至可以自定义是否当做未知字段处理
ExtraData map[string]any `json:",unknown"`
}
对于追求极致性能的高级玩家,v2 的 jsontext 开放了 Token 级别的流式读写能力。以前处理几个 GB 大小的 JSON 文件,内存往往会瞬间爆炸。现在你可以像流水线一样,一个 Token 接着一个 Token 地读写,告别一次性加载内存的恐惧。
JSON V2 工作组的纠结在哪?
JSON V2 有这么多的好处,为什么迟迟不能发版?口号也喊了很多年了。
目前来看,是因为这个改动实在是太大了,Go 核心团队专门拉上了 @aclements ,@neild ,@prattmic 等几位核心成员成立工作组,还开周会来推动这个事项。
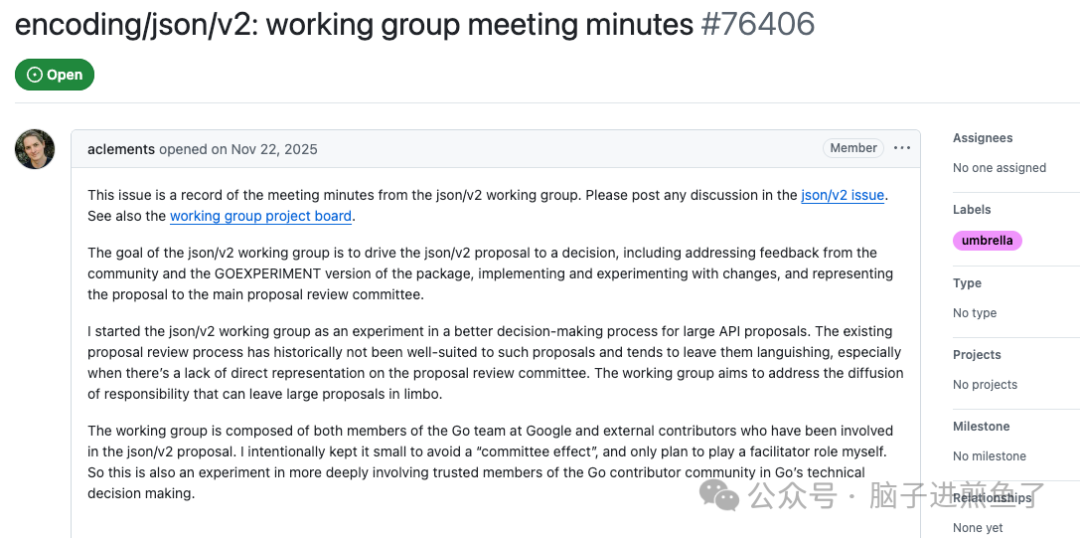
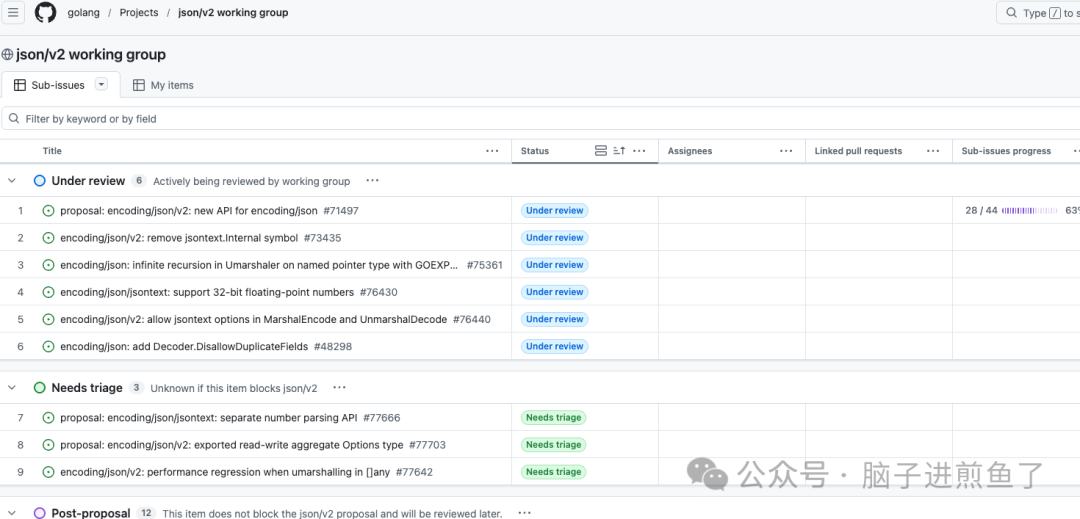
现阶段推进极其困难。核心的卡点是:
内存回归问题
例如,在 issues #75026 中,社区爆出了一个严重的问题。
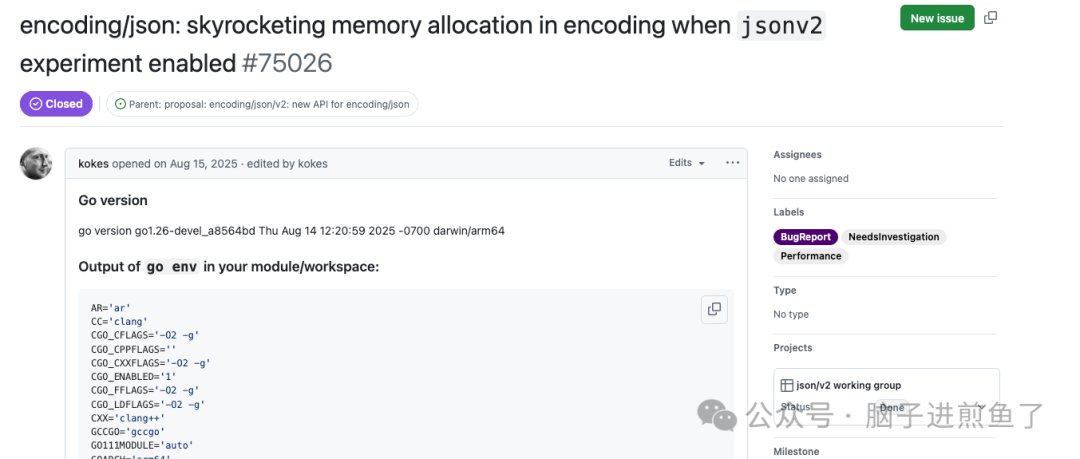
在开启 jsonv2 实验特性后,当程序对 map[string]string 等类型进行编码时,出现了内存分配异常飙升的现象。
这个问题其实挺常见,本质上是因为 v2 想修复 v1 中无法正确调用指针接收者方法的 BUG。我们来看一段示例代码:
// 假设自定义了一个字符串类型,并实现了指针接收者的序列化方法
type MyString string
func (m *MyString) MarshalText() ([]byte, error) {
return []byte("custom_" + *m), nil
}
func main() {
// map 中的 value 是不可寻址的 (unaddressable)
myMap := map[string]MyString{"key": "jianyu"}
// v1 版本会直接忽略指针方法,报错或者按默认走。
// v2 为了严谨,强制在反射层分配内存让其变得可寻址,从而能调到 MarshalText。
// 结果就是:处理大 map 时,每个元素都在堆上疯狂分配内存,性能直接爆炸。
jsonv2.Marshal(myMap)
}
这就很尴尬了,这个修复差点让 v2 引以为傲的性能神话翻车,也是目前被列为头号阻塞项的难题。当然,这个问题在几周前已经被解决:
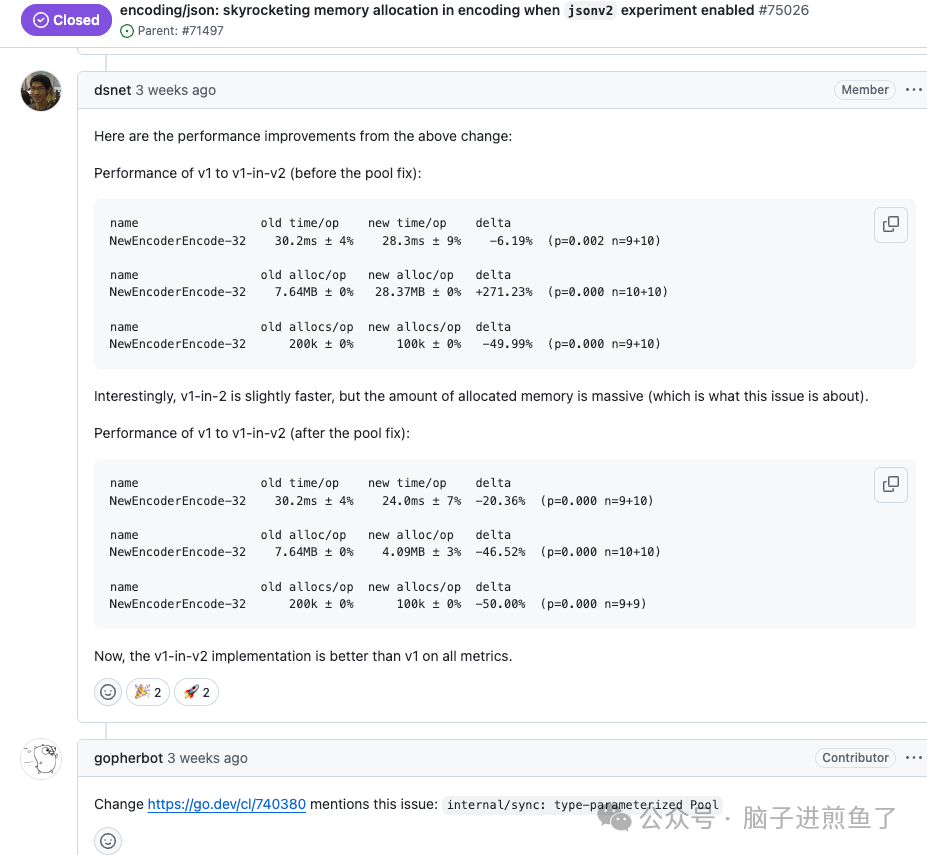
向下兼容性问题
新老版本的交替,最怕的就是无声无息地搞坏存量代码。一个最典型的例子就是 time.Duration 类型。
在 v1 版本中,标准库会非常随意地把它当成一个没有单位的纳秒整数直接序列化掉:
type Config struct {
Timeout time.Duration `json:"timeout"`
}
// 假设 Timeout = 5 * time.Second
// v1 序列化结果:{"timeout": 5000000000}
微服务之间互相调用时,经常因为不知道这个 5000000000 到底是秒还是纳秒而引发线上事故。
V2 本想借此机会彻底修正它,提出了新的规范要求:
type ConfigV2 struct {
// v2 构想:强制要求开发者指定 format,比如以秒为单位,否则报错
Timeout time.Duration `json:"timeout,format:sec"`
}
// 期望序列化结果:{"timeout": 5}
但这样一来,海量的老项目只要一切换到 v2,代码就会各种报错。如何平滑迁移?社区里也是谁都不服谁。
API 洁癖与细节拉扯
大佬们对于新 API 的设计有着近乎苛刻的要求。例如他们反复争论时间戳 format:unix 到底是应该输出带有小数点的浮点数,还是老老实实输出整数?
还有一个经典的分歧点,在于 nil 切片和 map 的序列化行为。我们来看下对比:
type Response struct {
Items []string `json:"items"`
}
func main() {
var resp Response // 此时 resp.Items 未初始化,是 nil
// v1 的做法:老老实实输出 null
// 结果:{"items": null} => 前端同学拿到后直接 .length 报错,引发屏幕白屏
json.Marshal(resp)
// v2 社区倾向的做法:将其默认视为空集合
// 结果:{"items": []} => 前后端皆大欢喜,不用写防御性代码
jsonv2.Marshal(resp)
}
虽然 v2 的思路很符合直觉,但任何一处默认行为的改变,都可能引发下游业务逻辑的蝴蝶效应。官方既不想重蹈 v1 设计上的覆辙,又怕 v2 步子迈得太大,这种进退两难的局面导致了审查进度异常缓慢。
总结
可以看到 encoding/json/v2 面临的难关,是因为它背负了 Go 语言十多年来积累的巨大历史包袱。Go 核心团队宁愿被社区催更,把战线拉长到好几个版本,也要把内存泄漏和 API 兼容性打磨到 “完美”。
如果你手头有项目想提前测试,依然可以通过在编译时加上 GOEXPERIMENT=jsonv2 环境变量来尝鲜。希望 JSON V2 工作组也早日结束他们的 backlog 待办清单。(现阶段来看,还是很有戏的)
对于 Go 语言中此类重大的演进和技术讨论,我们也会持续在 云栈社区 上关注和分享,欢迎加入讨论。
 发表于 2026-3-6 04:48:58
|
查看: 154|
回复: 0
发表于 2026-3-6 04:48:58
|
查看: 154|
回复: 0
