在机器学习项目的迭代中,随着时间推移,已上线的生产模型常会因数据漂移等问题性能衰退,此时模型升级成为必然。然而,一个关键问题摆在面前:我们如何能确信新的候选模型有能力、且安全地替代正在服役的旧模型?
仅凭离线验证集和测试集上的优异指标就做出替换决定,通常是一种冒险行为。因为本地环境很难百分百复刻复杂的线上生产条件,包括真实的用户数据分布、并发请求压力以及下游业务逻辑的耦合。直接替换可能导致意想不到的性能下降或业务风险。

因此,更为可靠的策略是:让候选模型在生产环境中,使用真实流量进行测试。这与软件工程中发布新功能的理念一脉相承。在 机器学习 领域,我们同样可以借助以下几种成熟的在线测试方案来评估模型,确保平稳过渡。
一、A/B测试
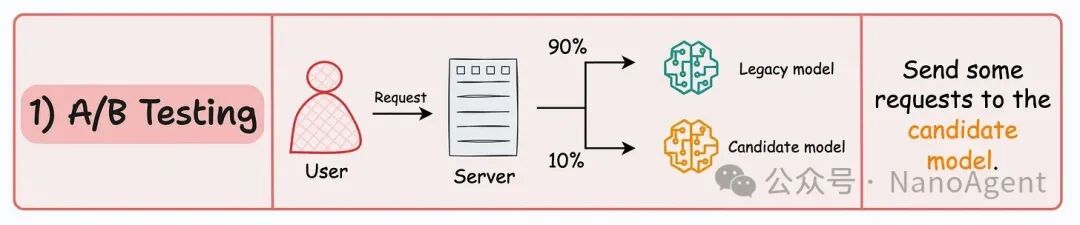
A/B测试是最为常见的在线评估方法。其核心是将传入的用户请求,按照预设的比例(非均匀地)分发给旧模型(Legacy model)和新模型(Candidate model)。例如,你可以配置将10%的流量导向候选模型,剩余的90%仍由旧模型处理。
这样做的好处显而易见:它有效控制了新模型的曝光范围。即使候选模型存在问题,其影响面也被限制在很小一部分流量内,避免了全局性的风险。你可以同时收集两个模型在处理真实请求时的性能指标(如准确率、响应时间)和业务指标(如点击率、转化率),进行直接的对比。
二、金丝雀测试
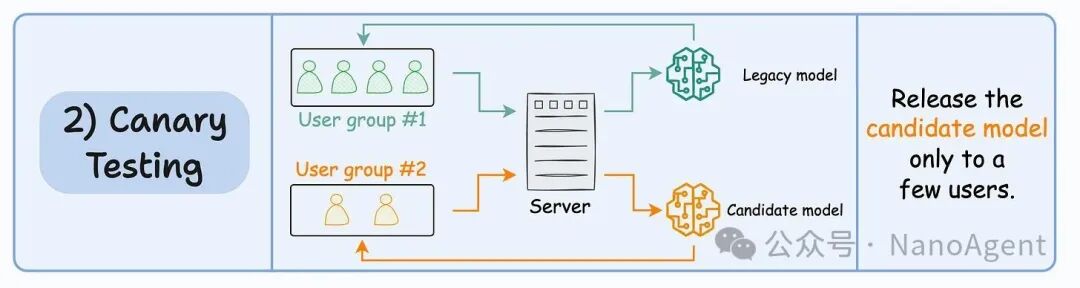
金丝雀测试(Canary Testing)可以看作是A/B测试的一种更精细化、更谨慎的变体。与A/B测试随机分流所有用户不同,金丝雀测试最初只将新模型发布给特定的一小部分用户(例如,内部员工、特定地区的用户或一小部分自愿测试的用户)。
如果在这个小范围的用户群体中,各项监控指标都表现正常,没有出现负面反馈,再逐步扩大新模型的部署范围,直至最终完全替换旧模型。这种方法尤其适用于用户群体敏感或影响面巨大的场景,它提供了一个“安全沙箱”,便于早期发现和修复问题。
三、交错测试
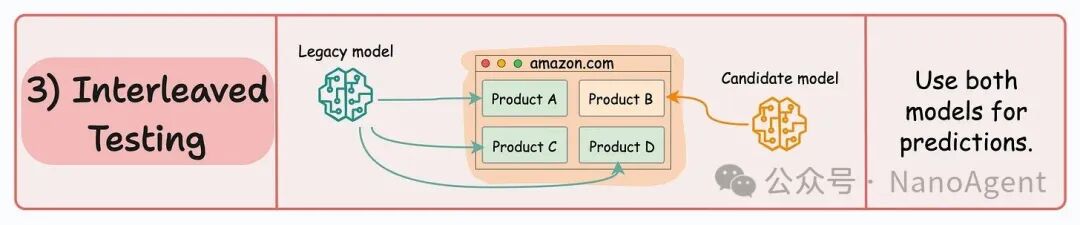
交错测试(Interleaved Testing)的思路略有不同,它侧重于混合多个模型的预测结果。以推荐系统为例,当用户请求一个产品推荐列表时,系统可以同时调用旧模型和新模型来生成推荐项,然后将两者的结果进行交织、排序,最终合并成一个列表返回给用户。
在这个过程中,系统会精心记录哪些结果来自哪个模型。通过后续追踪用户的交互行为(例如,点击了列表中的哪个产品、观看了多久),我们就可以分析出哪个模型产生的推荐更有效。这种方法能获得非常直接的、基于真实用户反馈的对比数据,但实现起来相对复杂,需要改造现有的服务逻辑来支持结果融合与打标。
四、影子测试
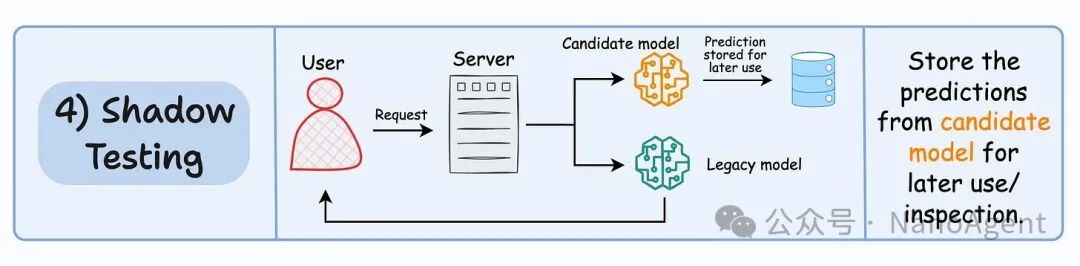
前面三种方法都会直接或间接地影响到一部分终端用户的体验。而影子测试(Shadow Testing)则提供了一种 生产环境 下完全无风险的测试方式。
在影子测试中,候选模型会与旧模型并行部署。每一个到达服务的用户请求,都会被同时发送给旧模型和候选模型进行处理。旧模型的输出会照常返回给用户,驱动实际的业务;而候选模型的输出则会被静默地记录存储起来,不会对用户产生任何影响。
特点:它的最大优势是“零风险”。你可以用完全真实的线上流量和场景来“滋养”新模型,并事后将它的预测结果与旧模型的进行详尽对比,包括准确性、延迟等所有技术指标。
缺点:由于候选模型的预测从未真正展示给用户,你无法收集到基于用户互动的业务指标,例如点击率、购买转化率等。这些指标往往对模型价值的最终评判至关重要。
性能与综合指标考量
无论采用上述哪种测试策略,评估都不应只局限于预测准确性。在 生产环境 中,模型的服务质量是一个多维度的综合体现,必须全面衡量:
- 服务性能:候选模型的推理延迟、吞吐量是否达标?资源使用率(CPU/GPU/内存)是否在可接受范围内?
- 业务影响:模型输出的改变对下游成功指标(如营收、用户留存)产生了何种影响?
- 用户体验:一个准确率提升2%但响应速度慢3倍的模型,很可能会损害用户体验,从而导致业务损失,这样的“升级”通常是不被接受的。
将这四种方法结合使用,可以构建一个从低风险到全量上线的完整验证管道。例如,可以先从影子测试开始,验证模型的基础性能和稳定性;然后进行小范围的金丝雀测试,观察真实用户反馈;最后通过A/B测试与旧模型展开公平竞赛,用数据决定最终的胜出者。
在云栈社区的 软件测试 板块,你可以找到更多关于复杂系统测试策略的深度讨论和实践案例,帮助你在模型迭代的道路上走得更稳。
 发表于 2026-3-8 02:25:23
|
查看: 127|
回复: 0
发表于 2026-3-8 02:25:23
|
查看: 127|
回复: 0
