在操作系统中,CPU通过一种称为“上下文切换”的机制,实现了在单核上“同时”运行多个进程的魔法。当我们惊叹于系统能流畅处理多任务时,背后是上下文切换在毫秒间完成的精密接力——它保存当前任务的运行现场,并加载下一个任务的执行环境。然而,对其认知若仅停留在“进程切换”的概念层面,便忽略了从硬件触发到内核调度执行的完整链条。
深入理解上下文切换,远不止记忆定义。从原理看,它是寄存器与内存数据的精准搬运;从内核视角,则涉及进程控制块(PCB)的更新与调度算法的决策。无论是用户态与内核态的切换损耗,还是中断与进程上下文的差异,都隐藏着系统性能优化的关键线索。本文将打破理论与实现的壁垒,从CPU硬件逻辑出发,沿着Linux内核的调度路径,完整拆解上下文切换的触发条件、执行步骤与成本构成。
一、什么是 CPU 上下文?
简单来说,CPU上下文就是CPU执行任务时所必需的运行环境。它主要由以下两部分核心硬件组件构成:
- CPU寄存器:集成在CPU内部的高速存储单元,用于暂存指令、数据和地址,访问速度远超内存,是CPU进行快速计算的“工作台”。
- 程序计数器(PC):存储下一条待执行指令的内存地址,像“书签”一样指引CPU按顺序执行程序。
当CPU运行一个任务时,寄存器和程序计数器会被设置为特定值,这些值的集合就构成了该任务的CPU上下文。它记录了任务当前的精确状态,是任务得以恢复执行的基础。上下文一旦损坏或丢失,任务就无法继续,如同正在写作时丢失了所有草稿和思路。

二、CPU 上下文切换的核心步骤
上下文切换是一个标准化的过程,主要包含以下三个步骤:
2.1 保存当前上下文
当操作系统决定切换任务时,首先会将当前正在运行任务的CPU上下文保存到内存中。具体来说,这些信息(寄存器值、PC值等)被写入该任务对应的进程控制块(PCB)或线程控制块(TCB)中。这就好比暂停一项工作前,需要记录下当前的进度、使用的工具和数据摆放位置。
2.2 调度器选择新任务
随后,操作系统的调度器开始工作。它会根据预设的调度算法(如时间片轮转、优先级调度等),从就绪队列中选择下一个获得CPU执行权的任务。
2.3 加载并执行新上下文
调度器做出选择后,操作系统会从内存中读取新任务的PCB,将其保存的上下文信息加载到CPU的物理寄存器中。最后,CPU根据恢复的程序计数器地址,开始执行新任务的指令流。
以下是一个简化的C++模拟代码,直观展示了“保存-恢复”的核心流程:
#include <iostream>
#include <string>
#include <vector>
#include <cstdint>
// 模拟CPU寄存器
struct CPUContext {
uint64_t rax, rbx; // 通用寄存器
uint64_t pc; // 程序计数器
uint64_t rsp; // 栈指针
};
// 进程控制块 (PCB)
struct PCB {
int pid;
std::string name;
CPUContext context;
bool is_running;
// ... 初始化代码
};
// 调度器类
class Scheduler {
private:
std::vector<PCB> processes;
PCB* current_running = nullptr;
public:
void save_context() {
if (!current_running) return;
// 模拟:将CPU当前寄存器值保存到当前进程的PCB中
std::cout << "保存进程[" << current_running->pid << "]的上下文..." << std::endl;
current_running->context.rax = 0x12345678; // 模拟的实时值
current_running->context.pc = 0x00401000; // 下一条指令地址
// ... 保存其他寄存器
current_running->is_running = false;
}
void restore_context(int target_pid) {
// 查找目标进程
PCB* target_proc = nullptr;
for (auto& proc : processes) {
if (proc.pid == target_pid) {
target_proc = &proc;
break;
}
}
if (!target_proc) return;
std::cout << "恢复进程[" << target_proc->pid << "]的上下文..." << std::endl;
// 模拟:将PCB中保存的值加载回CPU寄存器
// cpu.regs.rax = target_proc->context.rax; // 实际操作
// cpu.regs.pc = target_proc->context.pc;
current_running = target_proc;
current_running->is_running = true;
}
void context_switch(int target_pid) {
std::cout << "\n--- 开始上下文切换 ---" << std::endl;
save_context(); // 第一步:保存旧
restore_context(target_pid); // 第二步:恢复新
std::cout << "切换完成!\n" << std::endl;
}
};
int main() {
Scheduler os_scheduler;
// 添加并模拟切换过程...
return 0;
}
这段代码清晰地模拟了上下文切换的两大核心动作:save_context(保存当前状态到内存)和 restore_context(从内存加载新状态到CPU)。
三、CPU 上下文切换的三种类型
3.1 进程上下文切换
这是开销最大的一种切换。进程在Linux中运行于用户态和内核态两种空间。用户态权限受限,访问硬件或特权资源需通过系统调用陷入内核态。
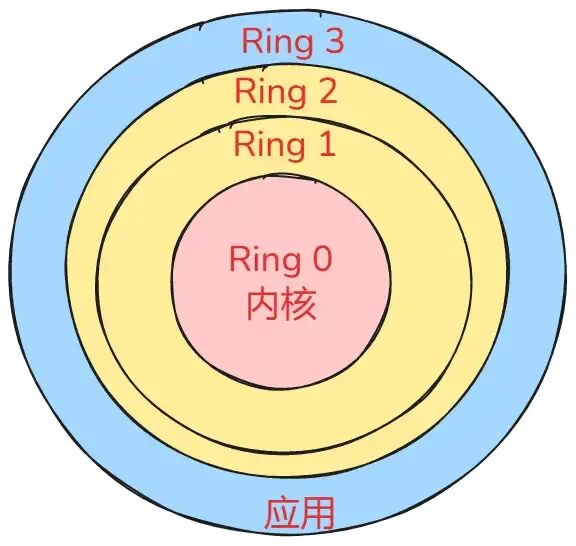
一次系统调用会发生两次CPU上下文切换(用户态->内核态->用户态),但进程并未改变。真正的进程上下文切换发生时,需要切换整个虚拟地址空间、内核栈和硬件上下文,通常在以下场景触发:
- 时间片耗尽:CPU时间片用完,被系统强制调度。
- 系统资源不足:如内存不足时,进程可能被挂起换出。
- 进程主动休眠:如调用
sleep()。
- 更高优先级进程就绪:被更高优先级的进程抢占。
- 硬件中断响应:CPU处理完中断后,可能调度另一个进程。
3.2 线程上下文切换
线程是CPU调度的基本单位,共享进程的内存空间。因此,同一进程内的线程切换开销远小于进程切换,因为虚拟内存等共享资源无需切换,只需保存和恢复线程私有的栈、寄存器等数据。
而不同进程间的线程切换,则与进程切换开销相当,因为需要同时切换内存映射表等进程级资源。
3.3 中断上下文切换
当硬件设备(如磁盘、网卡)完成操作时,会向CPU发送中断信号。CPU会暂停当前进程,转去执行内核中的中断服务程序(ISR)。
中断上下文仅包含内核态执行ISR所需的信息(如寄存器、内核栈),不涉及用户态资源。因此其切换速度极快,目的是快速响应硬件事件。中断处理完毕,CPU会恢复被中断进程的上下文。中断上下文切换的优先级最高。
四、上下文切换的开销与优化策略
4.1 开销来源
- 直接时间开销:保存和恢复大量寄存器、内存访问操作本身消耗CPU周期。
- 间接性能开销:
- 缓存失效:切换后,新任务的数据很可能不在CPU缓存中,导致缓存命中率下降,增加内存访问延迟。
- TLB失效:如果切换了内存地址空间(如进程切换),TLB(快表)需要刷新或部分失效,影响地址翻译速度。
- 调度决策开销:调度器自身选择下一个任务的计算开销。
4.2 优化策略
- 减少不必要的切换:
- 调整调度策略:针对I/O密集型任务使用优先级调度,针对计算密集型任务使用更公平的调度算法,避免因策略不当导致的频繁抢占。
- 优化程序设计:避免在高并发服务中创建过多线程,使用连接池、异步I/O(如Python的asyncio)等技术减少阻塞。
- 降低单次切换成本:
- 使用轻量级并发:采用协程(Coroutine),其切换在用户态完成,无需陷入内核,开销极小。
- 绑定CPU核心:对性能关键的线程或进程,可以将其绑定到特定的CPU核心,减少因在多个核心间迁移导致的缓存失效。
- 硬件辅助:使用更多CPU核心,让任务真正并行,从根本上减少为共享核心而进行的切换。
五、实战:如何监控与分析上下文切换?
过高的上下文切换频率(特别是非自愿切换)是系统性能瓶颈的常见信号。我们可以使用以下工具进行监控:
5.1 使用 vmstat 查看系统整体情况
$ vmstat 5 # 每5秒输出一次报告
 重点关注:
重点关注:
- cs:每秒上下文切换次数。数值突然或持续增高需警惕。
- in:每秒中断次数。
- r:就绪队列长度。若持续大于CPU核数,说明进程在等待调度。
5.2 使用 pidstat 定位具体进程
vmstat看到问题后,用pidstat深挖:
$ pidstat -w -t 5 # 每5秒输出一次,并显示线程信息
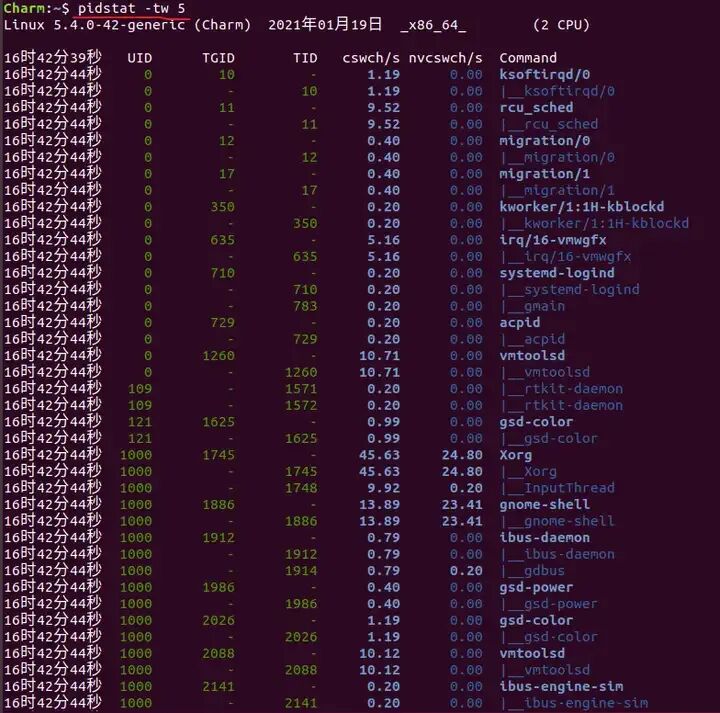 关键指标:
关键指标:
- cswch/s:自愿上下文切换。通常因等待资源(如I/O)主动让出CPU。
- nvcswch/s:非自愿上下文切换。因时间片用尽被系统强制调度。该值过高通常意味着CPU竞争激烈。
案例分析:若发现某Java应用线程的nvcswch/s异常高,可能原因是:
- 线程过多,远超CPU核心数。
- 存在“死循环”或过重的计算任务,长时间占用CPU。
- 锁竞争激烈,线程频繁挂起和唤醒。
解决思路包括:优化线程池大小、拆分计算任务、检查并优化锁粒度等。
总结
CPU上下文切换是操作系统实现多任务并发的基石,但其本身并非零成本。深入理解其从硬件寄存器到内核调度器的完整链路,以及进程、线程、中断三种切换类型的差异,是进行系统级性能调优的关键前提。通过监控工具定位切换热点,并结合减少不必要切换、采用轻量级并发等优化策略,可以有效提升系统的整体吞吐量和响应能力。
 发表于 2025-12-8 02:05:50
|
查看: 216|
回复: 0
发表于 2025-12-8 02:05:50
|
查看: 216|
回复: 0
