你是否也经历过这样的场景?明明需求说得清清楚楚:“去这个网站,把这几个字段整理成表格。” 结果每次还是得自己坐下来,打开开发者工具分析DOM、编写选择器、运行脚本、处理报错、粘贴日志、再次修改…… 这似乎成了绕不开的循环。
或许你也尝试过用ChatGPT来“提效”:让它帮你生成一段Playwright代码,拷贝过来运行,报错后再把日志贴回去,让它调整选择器、增加等待时间、处理弹窗。折腾半天后,你可能会发现:自动化的根本不是流程,而是你与AI之间的低效拉扯。这并非真正的自动化,仅仅是将人肉操作替换成了人肉调试。
真正让事情发生质变的,是今年初开始使用OpenClaw与Playwright这套组合之后。
一、我们到底在解决什么问题
让我们先把问题说清楚,避免后面的方案看起来像是在无病呻吟。
传统爬虫的致命弱点,现在做过数据采集的人都懂:用 requests 写得行云流水,发出去的请求却只拿回一个 <div id="app"></div>。面对JavaScript动态渲染和无限滚动,基于HTTP的请求往往无法触及真实内容。
于是你转向了Selenium或Playwright脚本。确实能拿到数据了,但维护成本令人绝望——页面改个类名,你的选择器就失效了;想处理个滑块验证码,又得调用第三方API,写一堆复杂的回调逻辑。
市面上也不是没有其他选择。像n8n这类低代码平台,在处理多标签页切换、特定轨迹滑动等复杂交互时往往力不从心;Apify这类云服务虽然强大,但如果没有现成的Actor脚本,你仍然需要付费定制,或者回归到自己写代码的老路上。
我们真正缺乏的,从来都不是“会不会写脚本”的能力。缺乏的是这样一种方式:你只需要说清楚目标,机器来负责执行,并且结果能直接用于后续工作。这就是“AI辅助你执行”和“AI自己去执行”之间的本质差距——大概相当于“给我一张地图”和“帮我开车到目的地”的区别。
二、OpenClaw 与 Playwright,为什么是这两个?
OpenClaw是今年初在GitHub上兴起的一个开源项目,定位非常清晰:一个基于大语言模型进行决策和任务调度的AI执行框架。它擅长理解自然语言,能够将你的指令如“抓取所有商品并保存”,实时转化为包含 page.goto、page.fill、page.evaluate 的可执行代码。更关键的是,它能在任务出错时,通过对DOM的语义理解自动调整选择器,无需人工重写。
关于Playwright,这里就不赘述了。作为微软在2020年开源的浏览器自动化工具,它已是该领域的事实标准。与Selenium相比,最核心的区别在于自动等待——在执行 click() 或 fill() 之前,它会自动判断元素是否可见、可交互、未被遮挡,完全不需要你手写 time.sleep。这一点对于AI生成的代码尤为重要,因为AI本身无法预知你的网络延迟或某个动画的持续时间。
此外,Playwright的API设计本身就非常接近自然语言:page.goto(url),page.click(selector),page.fill(selector, value)——大语言模型生成这类代码的准确率明显高于生成Selenium代码。其原生支持多标签页操作、网络请求拦截(可直接捕获API响应获取JSON,远比解析HTML稳定)、截图与轨迹录制、文件下载处理等功能,共同构成了这套方案的强大执行底座。
两者的分工非常明确:OpenClaw是指挥官,Playwright是特种部队。一个负责决策,一个负责动手。具体的调用链路如下:
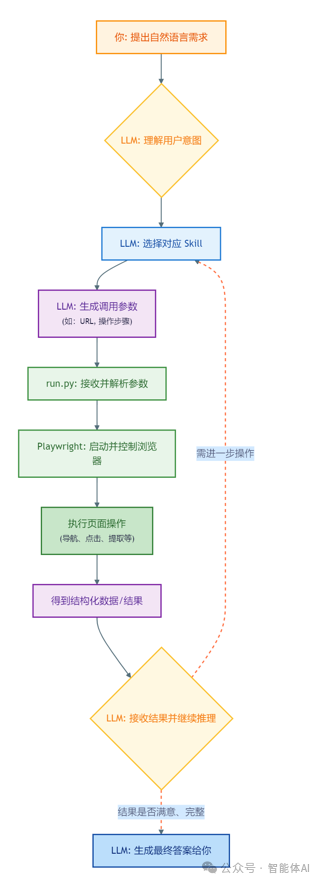
你用自然语言说出需求
↓
LLM 理解意图 → 选择对应 Skill → 生成调用参数
↓
run.py 接收参数 → 启动 Playwright → 执行浏览器操作
↓
结构化结果回传给 LLM → LLM 继续推理 → 最终输出给你
三、Skill 是整套方案的核心,得专门说说
OpenClaw中的 Skill 机制,是整件事能够跑通的关键。你可以将Skill理解为给AI安装的一个标准化工具。文件读写是一个Skill,调用外部API是一个Skill,操作浏览器也是一个Skill——也就是Playwright Skill。
一个典型的Skill目录结构是这样的:
skills/playwright-skill/
├── SKILL.md # 给 AI 看的说明书
├── spec.yaml # 输入参数和输出结构的定义
├── template.md # AI 组织调用的 Prompt 模板
└── run.py # 真正干活的执行引擎
SKILL.md 是给LLM的“工具手册”,让它明白在什么情况下调用这个Skill、传递什么参数、能获得什么结果。而 run.py 才是真正启动浏览器执行操作的地方。
这种拆分至关重要:AI负责决策,Python负责执行,两者完全解耦,可以独立进行维护和升级。
很多人会问,Playwright脚本我自己也会写,为什么要多这一层封装?因为裸脚本的问题不在于“不能用”,而在于“不能持续用”。你写了一个300行的爬虫脚本,三个月后可能自己都看不懂当初的选择器为何那样写。网站一旦改版,又需要花费半天时间重新调试。有新人加入项目,还需要花数小时为其讲解上下文。
Skill化之后则完全不同:spec.yaml 定义了标准化的接口,调用方无需关心内部实现;错误处理和重试机制在框架层面统一管理,而不是每个脚本各自实现一套try-catch;多个Skill可以被LLM按需自由组合,例如 LoginSkill + ExtractSkill + ExportSkill,就像搭乐高积木一样,每一块都是独立、可测试、可替换的。
四、实战一遍:抓取招投标网站的中标公告
说原理容易,我们来看一个真实的案例。
任务背景:需要从某省招投标官网,抓取近一个月所有中标公告的详细信息,包括:项目名称、招标单位、中标单位、中标金额、预算金额。
难点:页面是单页应用(SPA),由JavaScript动态渲染,直接使用requests只能拿到空壳HTML;公告列表需要按日期Tab切换,每个Tab下还有多页分页;每条记录的详情需要单独点击进入,数据分布在页面不同区域;网站还存在简单的登录态校验。
以往完成此类任务,仅分析页面结构、编写初版脚本就需要大半天时间,加上调试和处理各种边界情况,总耗时可能超过一天。
现在的做法:
第一步,部署和配置。在服务器上启动OpenClaw,启用Playwright Skill。配置文件的核心项如下:
browser:
headless: true
timeout: 30000
viewport:
width: 1920
height: 1080
concurrency:
max_tabs: 3
request_delay: 1500 # 每次操作至少间隔 1.5 秒
output:
screenshot_on_error: true
headless: true 表示在无界面模式下后台运行,以节省资源。request_delay 用于模拟人工操作节奏,降低被识别为爬虫的概率,这一点后面还会详谈。
第二步,下达指令。这是最省事的一步,无需编写任何代码,直接在OpenClaw的对话框中输入自然语言指令:
请访问 [网站URL],先用账号 [账号] 密码 [密码] 登录,然后点击“中标公告”Tab,从今天往前数30天,对每一天的Tab逐一点进去,翻页直到加载完全部公告,对每条公告点进详情页提取项目名称、招标单位、中标单位、中标金额(万元)、预算金额(万元),最后整理成Markdown表格保存到 output.md,遇到金额缺失的记录用“未披露”填充。
第三步,AI拆解任务,多Skill协作执行。
LLM收到指令后,会将任务自动拆解为几个子步骤:LoginSkill处理登录,并保存Cookie供后续复用;NavigateAndFilterSkill循环处理每一天的日期Tab,点击进入、翻页、收集所有公告链接,输出一个URL列表;DetailExtractSkill逐一打开详情页,等待动态内容渲染完成后再读取数据,避免因“元素未出现”而报错;ExportSkill进行数据清洗,统一金额格式,最终写入Markdown表格。
整个过程大约持续4-8分钟,具体时长取决于网络状况和公告数量。
我们来对比一下前后差异:
| 指标 |
以前(纯脚本) |
现在(OpenClaw) |
| 初次开发耗时 |
6-12 小时 |
5 分钟(下达指令) |
| 调试和迭代 |
每次页面改版几乎需重写 |
修改自然语言描述,AI重新适配 |
| 所需技能 |
Python + Playwright + 页面分析 |
会打字、能描述需求 |
| 可复用性 |
脚本绑定特定网站 |
Skill通用,换网站只需修改指令 |
五、几个让效果翻倍的实用技巧
六、能做什么?几个真实的落地场景
除了数据抓取,这套组合在实际项目中还有几个值得关注的应用方向:
- 自动化回归测试:告诉AI“遍历我们产品的主要功能流程,记录每一步截图,如果出现500报错或UI元素对不上,生成Bug报告”。本质上就是让AI扮演测试工程师,自动执行测试用例。
- 竞品价格监控:设定定时任务,让AI每天早上自动打开竞品定价页面,截图并提取价格信息,与前一天数据进行对比,如有变动则自动推送通知到飞书或钉钉群。无需维护一套独立的监控服务,一个Skill组合即可搞定。
- 批量后台操作(RPA):例如,管理后台中有200个历史订单需要逐条核对状态后关闭。这种高重复性、低创造性的操作交给AI,比让人点击两小时鼠标更快、更准确。每次操作可自动截图留证,出错时自动暂停并等待人工处理。
- 内容生成流水线:抓取行业新闻 → 调用大模型生成摘要 → 格式化并写入Notion数据库。Playwright Skill负责获取原材料,后续的加工处理由LLM自身完成,整条流水线可自动运行。
七、该说的坑,一个都不省
- 验证码是真正的硬关卡:Cloudflare的5秒盾、复杂的图像识别验证码、行为验证(如拖拽滑块)——这些是Playwright直接无法解决的。需要结合代理IP池以降低被识别概率、设置合理的随机延迟模拟人工节奏,必要时接入第三方打码服务。配置文件中的
request_delay 别设太短,这个参数比想象中更重要。
- 内存消耗比你想象的大:启动一个Chromium实例大约需要200-400MB内存。三个Tab并发,基础内存消耗就可能达到1GB。在本地测试没问题,但在生产环境中,
max_tabs 参数不要设置过高。建议使用具有独立、充足内存的云服务器,并配合任务队列进行合理调度。
- Selector写法决定脚本寿命:即使是AI生成的代码,也需要人工审查这一点:优先使用
data-testid、aria-label、role 等属性来定位元素;其次考虑使用文本内容定位(例如:“点击包含‘提交’字样的按钮”);尽量避免使用类似 .container > div:nth-child(3) > span 这种依赖HTML结构的CSS路径。结构路径一旦改版就会失效,而基于语义的描述,在网站版本迭代后通常依然有效。
- 账号安全别图省事:涉及登录操作的Skill,绝不能将账号密码明文写在指令中。应使用OpenClaw提供的凭证管理机制,通过环境变量或加密存储的方式传入敏感信息。
- 最后,注意访问礼节:并非所有网站都欢迎自动化访问。请遵守网站的
robots.txt协议,设置合理的访问频率,不要在一秒内发送几十个请求。这既是技术实践,也是基本的职业素养。
八、总结
我并非在宣扬“以后再也不用写代码了”——这种绝对化的观点既不现实,也无必要。
但确实有一类工作正在快速发生变化:那就是那种“你知道该做什么,只是没时间或不愿重复去做”的自动化任务。浏览器操作正是其中最典型的例子,因为浏览器是现代软件世界最通用的交互接口。
OpenClaw + Playwright Skill这套组合,其本质是将“编写程序来控制计算机”这件事的门槛,降低到了“用自然语言指挥一个懂工具的AI”这个层级。Skill体系是其中的关键——它将一次性的、脆弱的脚本,转变成了可复用、可组合的标准化能力。这让AI不仅会思考,还会执行,并能将结构化的执行结果反馈回来,以驱动下一步的推理和决策。对于开发者社区如云栈社区的成员来说,掌握这类工具意味着能更高效地将想法落地,将精力聚焦于更具创造性的问题上。
 发表于 2026-3-9 06:32:52
|
查看: 979|
回复: 0
发表于 2026-3-9 06:32:52
|
查看: 979|
回复: 0
