随着生成式人工智能与大语言模型的快速发展,企业数据基础设施正面临根本性变革。核心挑战已从管理结构化数据,转向如何高效、低成本地存储与检索海量的高维向量嵌入。这些嵌入是构建检索增强生成系统(RAG)的基石,也是现代语义搜索与推荐系统的核心。
本报告将深入剖析AWS、Google Cloud与Azure在“存储原生向量搜索”领域的技术演进,重点探讨“S3 Vector”这一利用对象存储进行向量数据持久化与检索的新范式,旨在应对十亿级规模下内存数据库的成本与扩展性瓶颈。
研究发现,三大云厂商基于各自的技术基因选择了不同的路径:
- AWS 采用激进的Serverless存储抽象,通过Amazon S3 Vectors将索引内嵌于对象存储,优先考虑极致成本与运维简便性。
- Google Cloud 依托其搜索技术积累,通过Vertex AI Vector Search提供基于ScaNN算法的高性能计算集群,将GCS作为数据持久化层。
- Azure 强调管道集成,Azure AI Search通过“索引器”与Blob Storage深度耦合,实现从文档到向量的自动化流水线与混合检索。
向量搜索的架构演进与理论基础
在分析具体实现前,需建立对大规模向量搜索系统架构原理的统一认知。
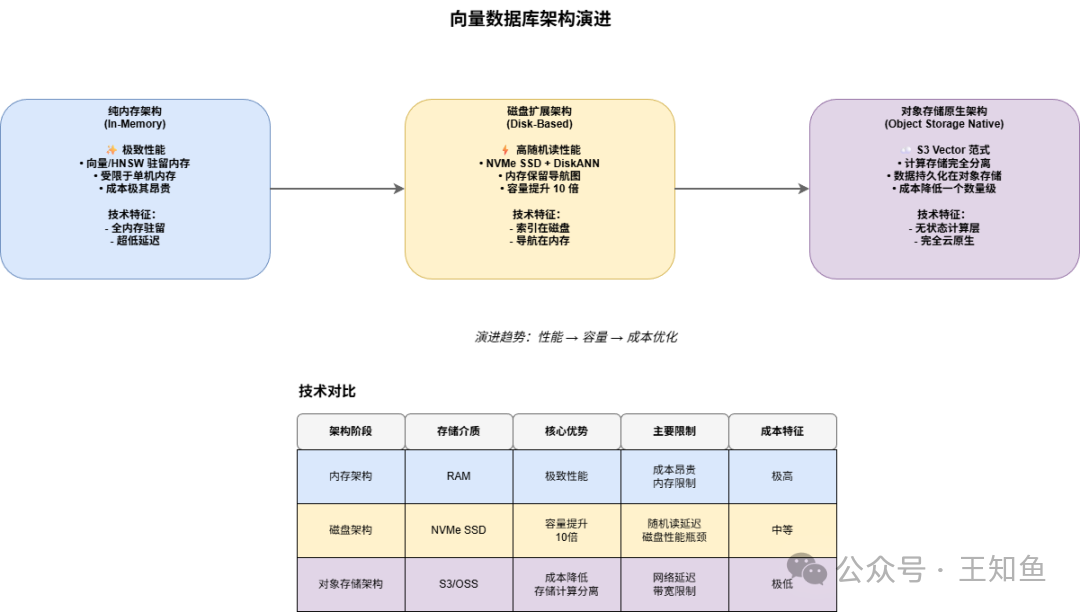
从内存到磁盘再到对象存储:“存储墙”的挑战
传统向量数据库依赖内存保证性能,但面对高维、海量数据时,内存成本成为瓶颈。架构演进主要分为三个阶段:
- 纯内存架构:性能极致,但成本昂贵且受单机内存限制。
- 磁盘扩展架构:利用NVMe SSD存储主体索引,内存仅保留导航结构,单机容量显著提升。
- 对象存储原生架构:即“S3 Vector”范式。计算无状态,数据与索引完全持久化于对象存储,按需拉取计算,实现了真正的存储计算分离,成本降低一个数量级。
核心索引算法及其存储友好性
底层算法对存储介质的依赖程度影响了云厂商的架构选择:
- HNSW:流行的图算法,依赖随机访问,对高延迟存储(如对象存储)不友好,通常需索引常驻内存。
- IVF:倒排文件索引,访问模式相对连续,易于批量读取,更适合适配磁盘或对象存储。
- ScaNN:Google自研算法,通过各向异性矢量量化在高压缩率下保持高召回,减少对底层存储的I/O压力。
存储-计算分离的物理约束
在“S3 Vector”架构中,核心矛盾在于延迟与吞吐。对象存储具有高吞吐但首字节延迟较高(10ms-100ms量级)。因此,架构需引入预取、本地缓存或列式存储格式来优化。AWS S3 Vectors的设计正是接受较高基础延迟(100ms+),以换取极致的吞吐扩展性与成本优势。
Amazon Web Services (AWS):Serverless 存储范式的先驱
AWS的Amazon S3 Vectors代表了一种架构哲学的转变:将向量搜索能力下沉到存储层,使其成为对象存储的原生属性。
Amazon S3 Vectors 架构深度解析
其核心是消除“向量数据库税”——为查询S3中的数据而购买专用数据库资源的现状。
- 向量桶与原生索引抽象:引入专为向量优化的Vector Bucket类型。索引管理完全黑盒化,由AWS后台服务自动构建与管理。存储格式可能经过优化(如列式存储),使得查询引擎能精准读取所需索引分片。写入路径支持高吞吐流式更新。
- 检索链路与性能权衡:查询请求由AWS无服务器计算层处理,从S3并行拉取索引分片计算。查询延迟通常在100ms到500ms之间,虽不适用于实时推荐,但对RAG等场景影响甚微,以此换取了高达90%的成本节约。
Amazon OpenSearch Service:高性能分层架构
作为高性能补充,OpenSearch Service通过k-NN插件集成Faiss等库,允许在段级别构建向量索引,并支持GPU加速索引构建。其自身的UltraWarm与冷存储分层架构,与S3 Vectors形成了互补的数据生命周期管理策略。
成本与应用场景分析
S3 Vectors采用Serverless计费(存储费+查询费),无需为闲置资源付费。
- 企业知识库:数亿文档但每日查询仅数千次时,成本接近纯存储费,比预置型数据库节省显著。
- 生成式AI代理记忆:将长期交互历史存入S3 Vectors,实现按需低成本检索,无需维护昂贵实时数据库。
Google Cloud的Vertex AI Vector Search代表了对极致性能的追求,旨在十亿级规模下保持毫秒级响应。
Vertex AI Vector Search 架构原理
其设计是显式的计算密集型,将GCS视为数据源而非直接查询层。
- 索引端点与分片:用户需创建预置计算资源的“索引端点”。系统采用分片策略与“Scatter-Gather”架构保证水平扩展性。
- ScaNN算法的核心优势:通过各向异性矢量量化,在高压缩率下保持高召回,使得相同内存下能提供更高精度,间接降低总拥有成本。
- 批处理与流式更新的双模架构:支持离线批量重建与实时流式更新,适应不同业务场景。
GCS 的角色与 RAG 管道
在Google架构中,GCS充当数据湖。典型的RAG流程是文档存入GCS,经处理生成向量后,再加载到Vector Search索引。这种设计保证了查询性能,但也意味着需为计算资源持续付费。
Microsoft Azure:管道集成与混合检索
Azure的战略重点是将向量能力无缝集成到现有搜索与存储生态中,Azure AI Search是核心。
Azure AI Search 架构剖析
其架构可描述为“PaaS化的ETL + 检索引擎”。
- 索引器与集成向量化:最具差异化的特性。用户配置指向Blob容器的索引器后,系统可自动化完成文档解析、调用Azure OpenAI生成向量并建索引的全流程,极大降低ETL复杂度。
- 内存与磁盘的权衡:提供两种检索路径。HNSW模式需索引全加载到内存以保证高性能;Exhaustive KNN(暴力搜索)模式则利用磁盘,突破内存限制,支持海量向量但延迟较高。
混合检索的王者
Azure AI Search 的核心优势是原生混合检索支持。其引擎能同时执行关键词搜索(BM25)与语义搜索(HNSW),并通过RRF算法融合结果,在RAG场景下提供更佳的相关性体验。
厂商架构深度对比与 TCO 分析
架构特征横向对比
| 维度 |
AWS (S3 Vectors) |
Google (Vertex AI) |
Azure (AI Search) |
| 核心定位 |
存储层原生能力,极低成本 |
高性能计算集群,极高吞吐 |
搜索管道集成,混合检索 |
| 底层存储 |
S3(数据与索引全托管) |
GCS(仅作为数据源) |
Blob(源) + SSD/RAM |
| 索引驻留 |
磁盘/S3 (按需加载) |
内存/SSD (常驻) |
内存 (HNSW) / 磁盘 (KNN) |
| 检索延迟 |
100ms - 500ms |
< 10ms (P99) |
< 20ms (RAM模式) |
TCO (总拥有成本) 模型分析
基于千万级向量场景:
- 冷数据/低频查询场景:AWS S3 Vectors 成本优势巨大,可能比其他预置节点方案低两个数量级。
- 高频/低延迟场景:GCP Vertex AI 等在高压QPS下摊薄成本低,且能提供S3 Vectors无法实现的亚毫秒级延迟。Azure AI Search 为容纳大规模HNSW索引可能需要较高成本。
结论与建议
云原生向量搜索市场已形成三条清晰技术路线:
- Serverless 存储路线 (AWS S3 Vectors): 降低RAG准入门槛,适用于对延迟不敏感(<1秒)的内部知识库、归档检索等场景。
- 高性能计算路线 (GCP Vertex AI): 追求极致性能,适用于推荐系统、实时广告等核心业务。
- 融合管道路线 (Azure AI Search): 强调自动化与多模态分析,适用于需要复杂ETL、混合检索的企业级应用。
给架构师的建议:
- 实施冷热分离:切勿为休眠的冷数据支付热存储价格。
- 优先考虑混合检索:在实际业务中,结合关键词与语义搜索能显著提升RAG等应用的效果。
- 减少数据搬运:尽量选择能与现有对象存储直接集成的服务,以简化架构并降低ETL维护成本。
未来,“存储-计算分离”有望成为向量产品的标准配置,推动整个行业向更高效、更经济的方向演进。
 发表于 2025-12-8 03:02:42
|
查看: 250|
回复: 0
发表于 2025-12-8 03:02:42
|
查看: 250|
回复: 0
